|
requirements.windows.cuda12.txt specifies paddlepaddle-gpu==2.6.0.post120
When i try to manually install this, i get an error that it is not found:
c:\> pip install paddlepaddle-gpu--2.6.0.post120
ERROR: Could not find a version that satisfies the requirement paddlepaddle-gpu--2.6.0.post120 (from versions: none)
ERROR: No matching distribution found for paddlepaddle-gpu--2.6.0.post120
Also the file states Python 3.7 - with 3.7, i can only install paddlepaddle-gpu 2.5.2. With Python 3.9 i get 2.6.1
|
|
|
|
|
Thanks very much for the additional info. I'm assuming you have similar info to OP, but could you please share your System Info tab from your CodeProject.AI Server dashboard? Also could you please share your installation log for the License Plate Reader module?
Thanks,
Sean Ewington
CodeProject
|
|
|
|
|
RESOLVED: The issue is that network connections to China were blocked on my network, so it could not download the component. I allowed access and the install worked.
|
|
|
|
|
Warning: unknown mime-type for "http://192.168.1.205:32168" -- using "application/octet-stream"
|
|
|
|
|
Error: no such file "http://192.168.1.205:32168"
this is another error that i get after it
|
|
|
|
|
Thanks very much for your report. Could you please share your System Info tab from your CodeProject.AI Server dashboard, and what you are trying to do when you get this error?
Thanks,
Sean Ewington
CodeProject
|
|
|
|
|
I would like to train a text module with transcribed videos (including their URL) and be able to ask the AI server some questions about the content of the video's. Would this be possible with this server? And if so please provide some suggestions.
thanks Murray D.
|
|
|
|
|
Thanks very much for your inquiry. Currently CodeProject.AI Server can only train on images, so not yet.
Thanks,
Sean Ewington
CodeProject
|
|
|
|
|
First of all, nice work. Makes code writing a bit easier. It's kinda fun too, having a personal assistant. My plugin for Homeseer leverages it's built in speech engine.
Initially, on Win7, Python 3.9 is a no go. Until I figured out the missing dll.
Also, it took a bit to figure out the API, as the API docs have not been updated. Once I figured out what the return endpoint is, the rest was easy.
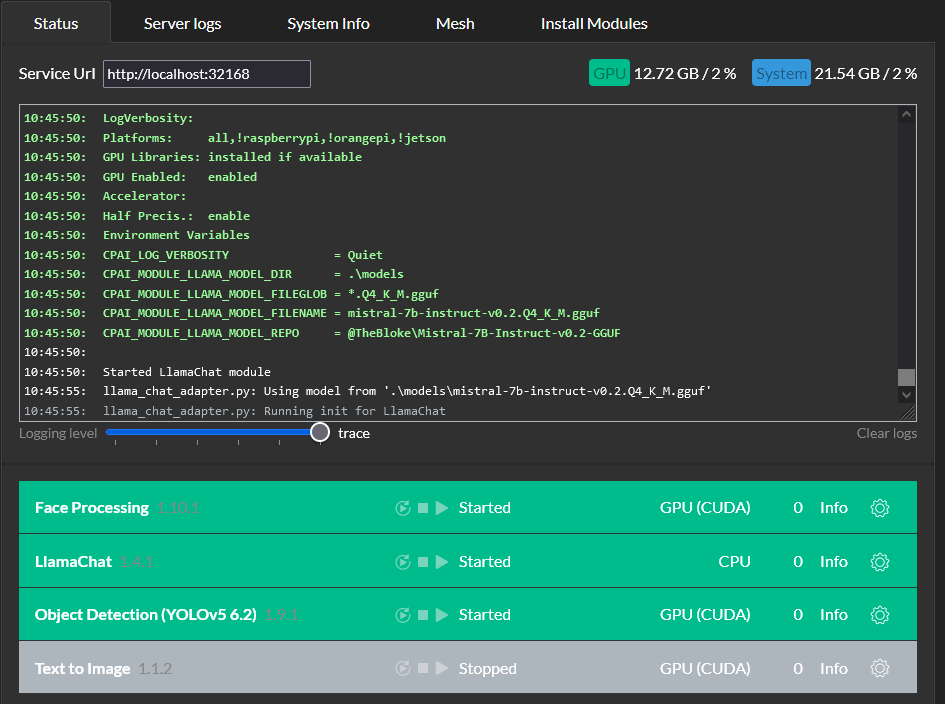
The only issue I see is the Llama chat module shows CPU and it looks like it is using GPU. UPDATE: It looks like it is not using the GPU.
4/11/2024 11:17:18 AM ~ Prompt Return {"success":true,"message":"Command is running in the background","commandId":"38ec745d-789f-4f73-b78b-b4be1faba3e1","commandStatus":"running","moduleId":"LlamaChat","moduleName":"LlamaChat","code":200,"command":"prompt","requestId":"38ec745d-789f-4f73-b78b-b4be1faba3e1","inferenceDevice":"CPU","analysisRoundTripMs":6,"processedBy":"localhost","timestampUTC":"Thu, 11 Apr 2024 18:17:23 GMT"}
10:23:41:Module 'LlamaChat' 1.4.1 (ID: LlamaChat)
10:23:41:Valid: True
10:23:41:
10:23:41:Attempting to start LlamaChat with C:\Program Files\CodeProject\AI\modules\LlamaChat\bin\windows\python39\venv\Scripts\python "C:\Program Files\CodeProject\AI\modules\LlamaChat\llama_chat_adapter.py"
10:23:41:Module Path: <root>\modules\LlamaChat
10:23:41:AutoStart: True
10:23:41:Queue: llamachat_queue
10:23:41:Runtime: python3.9
10:23:41:Runtime Loc: Local
10:23:41:FilePath: llama_chat_adapter.py
10:23:41:Start pause: 0 sec
10:23:41:Parallelism: 1
10:23:41:LogVerbosity:
10:23:41:Platforms: all,!raspberrypi,!orangepi,!jetson
10:23:41:GPU Libraries: installed if available
10:23:41:GPU Enabled: enabled
10:23:41:Accelerator:
10:23:41:Half Precis.: enable
10:23:41:Environment Variables
10:23:41:CPAI_LOG_VERBOSITY = Quiet
10:23:41:CPAI_MODULE_LLAMA_MODEL_DIR = .\models
10:23:41:CPAI_MODULE_LLAMA_MODEL_FILEGLOB = *.Q4_K_M.gguf
10:23:41:CPAI_MODULE_LLAMA_MODEL_FILENAME = mistral-7b-instruct-v0.2.Q4_K_M.gguf
10:23:41:CPAI_MODULE_LLAMA_MODEL_REPO = @TheBloke\Mistral-7B-Instruct-v0.2-GGUF
10:23:41:
10:23:41:Started LlamaChat module
10:23:47:llama_chat_adapter.py: Running init for LlamaChat
10:23:47:llama_chat_adapter.py: Using model from '.\models\mistral-7b-instruct-v0.2.Q4_K_M.gguf'
modified 19-Apr-24 11:48am.
|
|
|
|
|
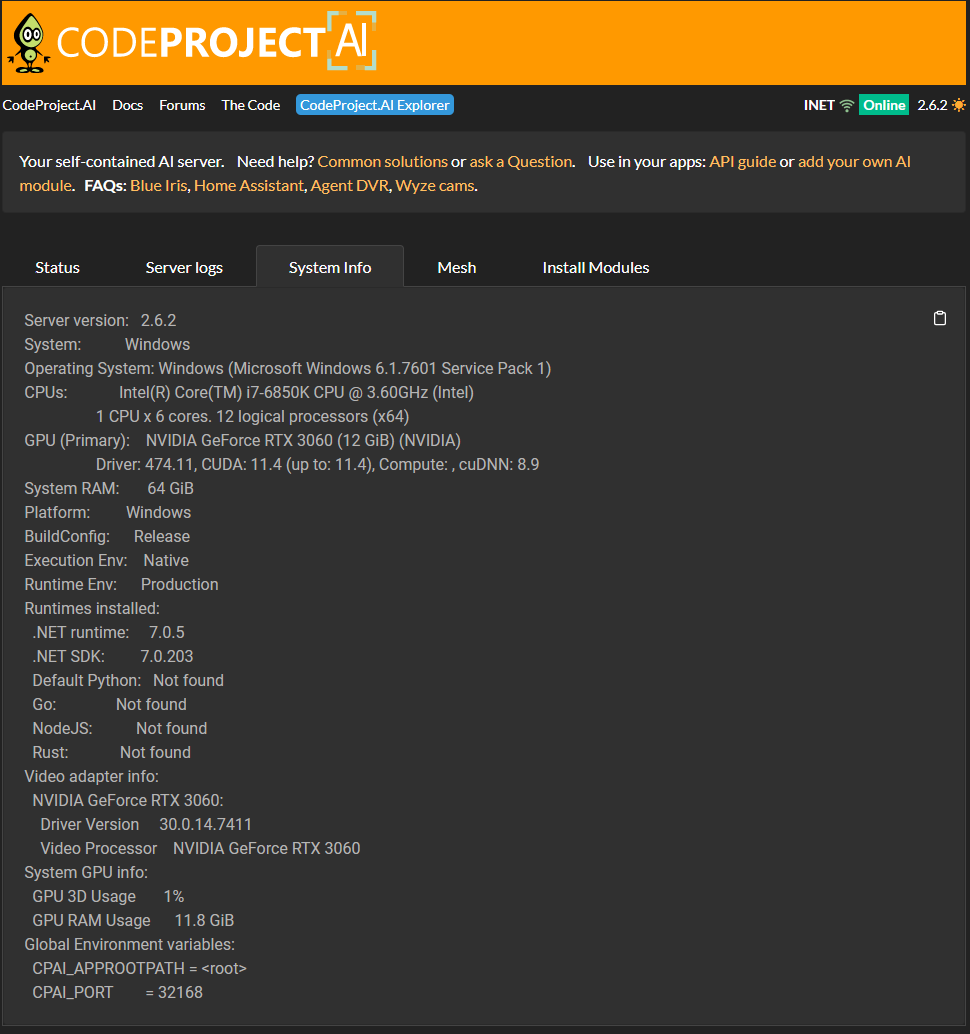
Thanks very much for your report. Could you please share your System Info tab from your CodeProject.AI Server dashboard?
Thanks,
Sean Ewington
CodeProject
|
|
|
|
|
It appears that the module is not reporting the usage of the GPU correctly.
Open the Task Manager, go to the performance tab and select the GPU.
Then when you run the Llama Chat, you should see a spike in the GPU usage.
"Mistakes are prevented by Experience. Experience is gained by making mistakes."
|
|
|
|
|
I did some digging and everytime I run ..\..\setup --verbose, I see it gets the wheel package everytime. Not sure if some libs are not compatible with older win. I aquired the dll workaround for Win7 and Python 3.9. The TextToImage module works fine with it's 3.9 virtual environment and uses cuda. In GPU Shark core and mem usage spikes when making a Llama chat request. I have three modules loaded and GPU Shark shows I have three python instances running. Request return from Llama chat shows "inferenceDevice":"CPU"

|
|
|
|
|
There was a bug in the detection of the GPU, which I have fixed.
The module is using the GPU, just not displaying that fact.
When we release the next set up Module updates, you will see the GPU displayed correctly.
No need to worry though, the correction does not change the operation or performance of the module.
"Mistakes are prevented by Experience. Experience is gained by making mistakes."
|
|
|
|
|
Does anyone have any idea on how to get YOLOv8 to perform segmentation? I'm using AgentDVR with CodeProject AI, and so far, what I see in the CodeProject AI's log is saying "detect". But I think if segmentation were performed, it would say "segment".
Is there any specific requirement to make YOLOv8 to perform segmentation?
I have Tesla P4 and YOLOv8 is running on GPU (CUDA).
modified 15-Apr-24 11:34am.
|
|
|
|
|
You can do it in the CodeProject.AI Server Explorer, if you're using the YOLOv8 module and check the box "Perform segmentation"
Thanks,
Sean Ewington
CodeProject
|
|
|
|
|
Understood that. But my question is, when it works with the AgentDVR, is there a way to make it perform/use "segmentation" automatically instead of standard detection?
|
|
|
|
|
I think this might have to be an AgentDVR support question. I know the creator is very responsive on the AgentDVR subreddit[^].
Because the default API call goes to v1/vision/detection, and you can actually change this in the Object Detection camera settings in AgentDVR (for image segmentation its v1/vision/segmentation), but the default behaviour for AgentDVR is to draw bounding boxes around the objects on display. I don't think it even shows bounding boxes on the screengrabs or videos that get taken. So I think you'd be asking for a feature request to do this.
Thanks,
Sean Ewington
CodeProject
modified 12-Apr-24 11:23am.
|
|
|
|
|
Hi Sean, thank you for your answer. It helped! Because in AgentDVR, you can adjust the API call for the Object Detection, so I was able to change "v1/vision/detection" to "v1/vision/segmentation". After I changed it, it is now using "segment" command per the CPAI's log!
Thanks a million!
|
|
|
|
|
Hello together,
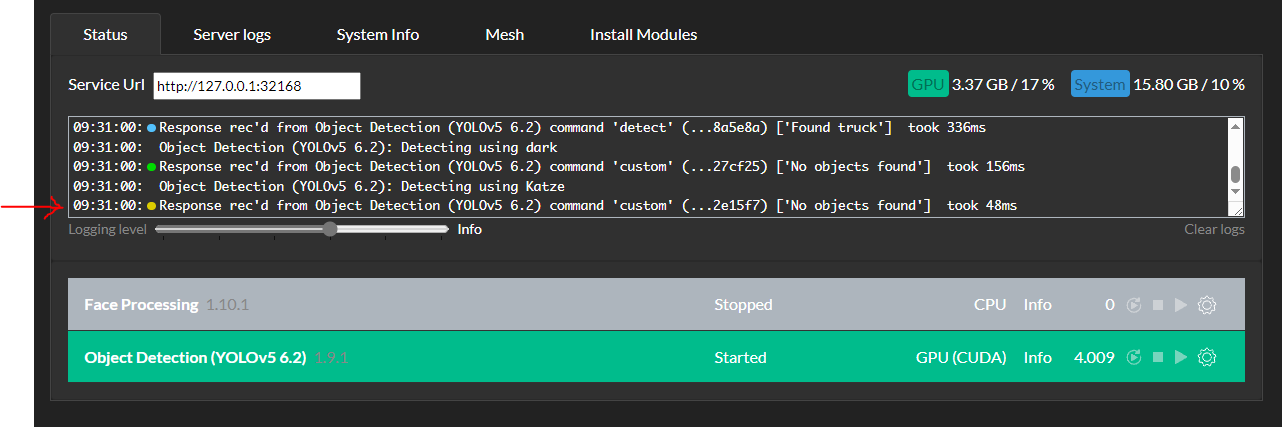
since update to 2.6.2 logging stopped now the 2nd time by random. Detection seems to work normal.
Only Yolo V5.6.2 activated in GPU mode, Face Processing installed but stopped, because of too much false negatives, detected myself instead of an real intruder.
Logging with 2.5.6 worked without problems.
EDIT: Only restarting Yolo doesn't help. The entire service must be restarted.
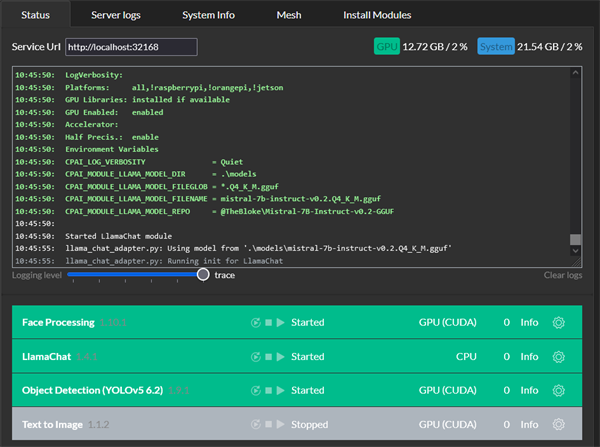
Server version: 2.6.2
System: Windows
Operating System: Windows (Microsoft Windows 10.0.14393)
CPUs: Intel(R) Core(TM) i9-10850K CPU @ 3.60GHz (Intel)
1 CPU x 10 cores. 20 logical processors (x64)
GPU (Primary): NVIDIA T600 (4 GiB) (NVIDIA)
Driver: 527.41, CUDA: 12.0 (up to: 12.0), Compute: 7.5, cuDNN:
System RAM: 64 GiB
Platform: Windows
BuildConfig: Release
Execution Env: Native
Runtime Env: Production
Runtimes installed:
.NET runtime: 7.0.16
.NET SDK: Not found
Default Python: Not found
Go: Not found
NodeJS: Not found
Rust: Not found
Video adapter info:
NVIDIA T600:
Driver Version 31.0.15.2741
Video Processor NVIDIA T600
System GPU info:
GPU 3D Usage 19%
GPU RAM Usage 3,1 GiB
Global Environment variables:
CPAI_APPROOTPATH = <root>
CPAI_PORT = 32168
|
|
|
|
|
Thanks very much for the report. Is anything showing in the logs when (or just before) this happens, or does the service suddenly go offline?
Thanks,
Sean Ewington
CodeProject
|
|
|
|
|
The last entry was a detection request sent by BlueIris. Thereafter it suddenly stops without any additional message.
I'll post a screenshot if it happens again.
|
|
|
|
|
It's 3:49 PM now.
EDIT: It was the web service only. Refreshing the webpage restarted it.
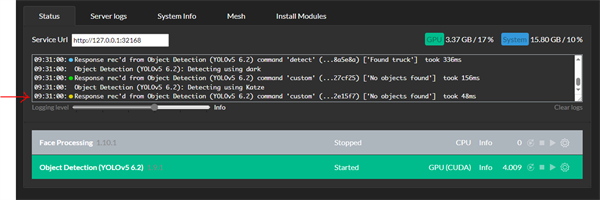
modified 13-Apr-24 1:16am.
|
|
|
|
|
Next time that happens can you please open the Developer Tools for the webpage (F12 on Chrome) and let us know if there are any errors reported in the console? The webpage never starts/stops the server (just modules) so it sounds like a webpage error.
cheers
Chris Maunder
|
|
|
|
|
Since the last update there is an option to download models. This confuses me a bit. What does the green models mean, are they available? or supported?
For me it would be easier if the download section would be hidden. And if I select a model and that model is not available, it would automatically download that model.
Maybe I'm seeing this wrong. But I would like to have some clarification about how to use this.
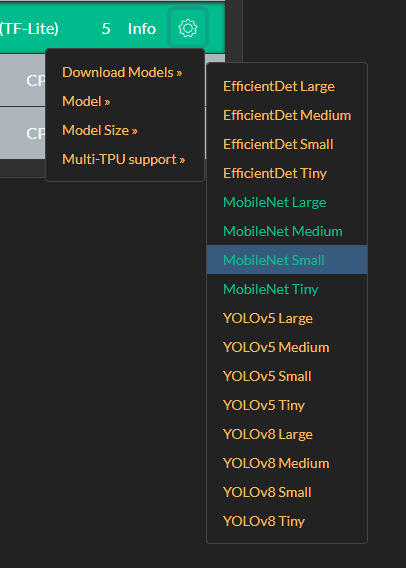
modified 16-Apr-24 12:00pm.
|
|
|
|
|
Green means it's cached (and in theory installed), orange means ready to download. There are tooltips on the options.
cheers
Chris Maunder
|
|
|
|


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin