|
Boy, this is fun!
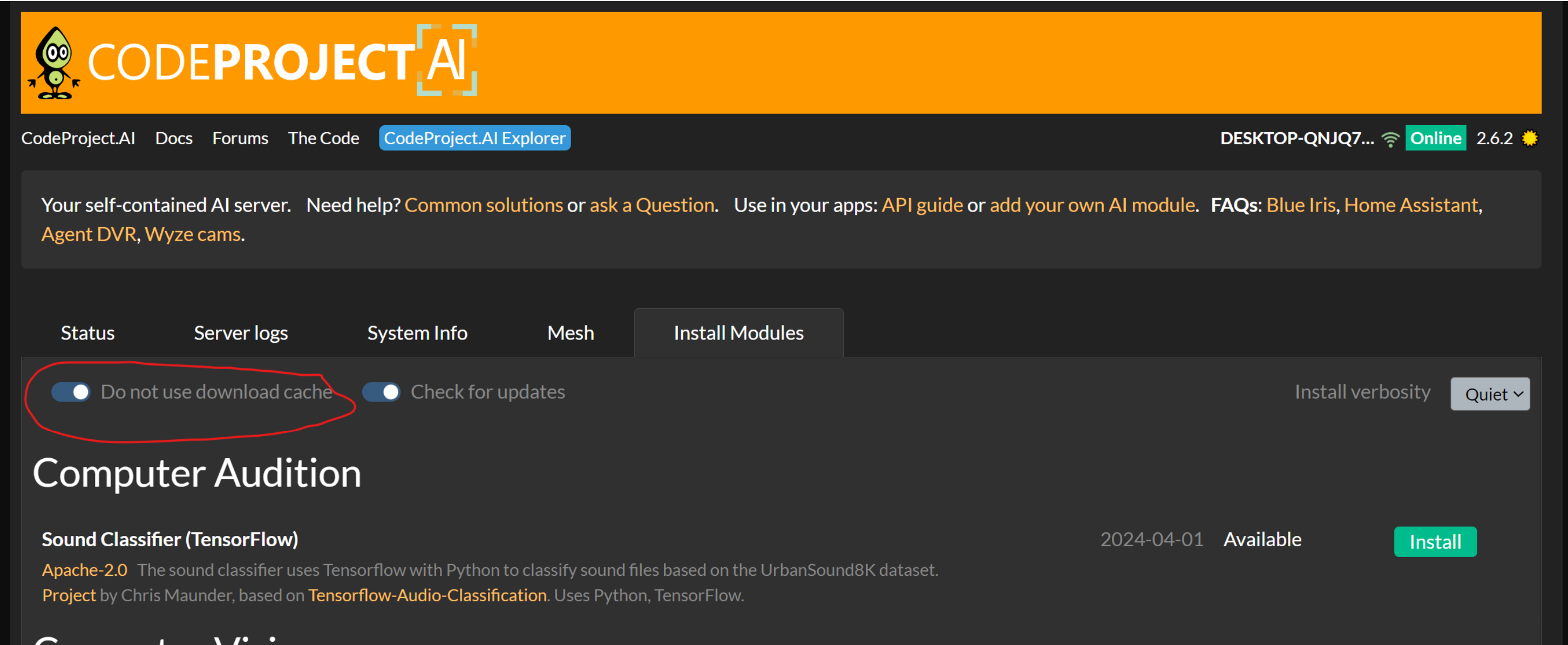
1. Somehow, CPAI is using the old port 5000. Frigate will not start, since it also uses port 5000. So, go to serversettings .json and change the use port 5000 to false. (Sorry don't remember the name). But /etc/codeproject/serversettings.json is an empty file.
So check where is the actual serversettings.json file.
Server version: 2.6.2
System: Linux
Operating System: Linux (Ubuntu 22.04)
CPUs: Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz (Intel)
1 CPU x 4 cores. 4 logical processors (x64)
GPU (Primary): HD Graphics 530 (rev 06) (Intel Corporation)
System RAM: 8 GiB
Platform: Linux
BuildConfig: Release
Execution Env: Native
Runtime Env: Production
Runtimes installed:
.NET runtime: 7.0.17
.NET SDK: Not found
Default Python: 3.10.12
Go: Not found
NodeJS: Not found
Rust: Not found
Video adapter info:
HD Graphics 530 (rev 06):
Driver Version
Video Processor
System GPU info:
GPU 3D Usage 0%
GPU RAM Usage 0
Global Environment variables:
CPAI_APPROOTPATH = <root>
CPAI_PORT = 32168
Module 'Object Detection (YOLOv5 6.2)' 1.9.1 (ID: ObjectDetectionYOLOv5-6.2)
Valid: True
Module Path: <root>/modules/ObjectDetectionYOLOv5-6.2
AutoStart: True
Queue: objectdetection_queue
Runtime: python3.8
Runtime Loc: Shared
FilePath: detect_adapter.py
Start pause: 1 sec
Parallelism: 0
LogVerbosity:
Platforms: all,!raspberrypi,!jetson
GPU Libraries: installed if available
GPU Enabled: enabled
Accelerator:
Half Precis.: enable
Environment Variables
APPDIR = <root>/modules/ObjectDetectionYOLOv5-6.2
CUSTOM_MODELS_DIR = <root>/modules/ObjectDetectionYOLOv5-6.2/custom-models
MODELS_DIR = <root>/modules/ObjectDetectionYOLOv5-6.2/assets
MODEL_SIZE = Medium
USE_CUDA = True
YOLOv5_AUTOINSTALL = false
YOLOv5_VERBOSE = false
Status Data:
Started: 16 Apr 2024 8:26:38 AM Central Standard Time
LastSeen: Not seen
Status: Started
Requests: 0 (includes status calls)
Installation Log
2024-04-16 07:51:04: Setting verbosity to quiet
2024-04-16 07:51:05: Installing CodeProject.AI Analysis Module
2024-04-16 07:51:05: ======================================================================
2024-04-16 07:51:05: CodeProject.AI Installer
2024-04-16 07:51:05: ======================================================================
2024-04-16 07:51:05: 514.00 GiB of 843.02 GiB available on linux
2024-04-16 07:51:05: Installing xz-utils...
2024-04-16 07:51:05: WARNING: WARNING: aptapt does not have a stable CLI interface. does not have a stable CLI interface. Use with caution in scripts.Use with caution in scripts.
2024-04-16 07:51:06: stty: 'standard input': Inappropriate ioctl for device
2024-04-16 07:51:06: General CodeProject.AI setup
2024-04-16 07:51:06: Setting permissions on downloads folder...done
2024-04-16 07:51:06: Setting permissions on modules download folder...done
2024-04-16 07:51:06: Setting permissions on models download folder...done
2024-04-16 07:51:06: Setting permissions on runtimes folder...done
2024-04-16 07:51:06: Setting permissions on persisted data folder...done
2024-04-16 07:51:06: GPU support
2024-04-16 07:51:06: CUDA (NVIDIA) Present: No
2024-04-16 07:51:06: ROCm (AMD) Present: No
2024-04-16 07:51:06: MPS (Apple) Present: No
2024-04-16 07:51:06: Reading module settings.......done
2024-04-16 07:51:06: Processing module ObjectDetectionYOLOv5-6.2 1.9.1
2024-04-16 07:51:06: Installing Python 3.8
2024-04-16 07:51:06: Python 3.8 is already installed
2024-04-16 07:51:10: W: https:
2024-04-16 07:51:15: Ensuring PIP in base python install... done
2024-04-16 07:51:16: Upgrading PIP in base python install... done
2024-04-16 07:51:16: Installing Virtual Environment tools for Linux...
2024-04-16 07:51:17: Searching for python3-pip python3-setuptools python3.8...All good.
2024-04-16 07:51:17: stty: 'standard input': Inappropriate ioctl for device
2024-04-16 07:51:21: Creating Virtual Environment (Shared)... done
2024-04-16 07:51:21: Checking for Python 3.8...(Found Python 3.8.19) All good
2024-04-16 07:51:24: Upgrading PIP in virtual environment... done
2024-04-16 07:51:26: Installing updated setuptools in venv... done
2024-04-16 07:51:51: Downloading Standard YOLO models...Expanding... done.
2024-04-16 07:51:51: Moving contents of models-yolo5-pt.zip to assets...done.
2. And like others are seeing, the server keeps going offline. I cannot even use the explorer to test with an image from the TestData.
I will run Find to see if I can find the actual <root> directory (CPAI_APPROOTPATH) on my machine. (Is that a variable in the machine path?)
I have checked to verify that this is not the Docker image that is running. It is not.
|
|
|
|
|
Port 5000: in /server/appsettings.json there's an entry "DisableLegacyPort". Set this to "true" to stop CodeProject.AI trying to use port 5000.
Stop/start. A suggested fix is:
Try editing /etc/systemd/system/codeproject.ai-server.service to replace "Type=notify" with "Type=simple", then run 'systemctl daemon-reload' followed by 'systemctl restart codeproject.ai-server'
cheers
Chris Maunder
|
|
|
|
|
Well; I must be getting confused in my old age.
I had appsettings.json open in VSC with the change, but I didn't save it??? Duh!
Also changing type to simple from notify seems to have corrected the restarting.
I did have to uninstall and reinstall the YOLOv5 6.2 module to get it to work, but both YOLOv5 6.2 and YOLOv5.NET seem to be working now. (at least with testing with the explorer).
I might take a chance and point Blue Iris to it and see what happens.
Thanks for the help with my confusion.
|
|
|
|
|
The latest 2.6.4 Ubuntu now includes that fix
cheers
Chris Maunder
|
|
|
|
|
Well the only serversettings.json file is the empty one that is in /etc/codeproject. Checking for an enviornment variable called CPAI_APPROOT yields nothing. Root directory has nothing of interest.
root@Ubuntu:/# find / -name serversettings.json
/etc/codeproject/ai/serversettings.json
find: ‘/proc/2879/task/2879/net’: Invalid argument
find: ‘/proc/2879/net’: Invalid argument
find: ‘/proc/20008’: No such file or directory
find: ‘/proc/20009’: No such file or directory
find: ‘/proc/20015’: No such file or directory
find: ‘/run/user/1000/gvfs’: Permission denied
find: ‘/run/user/1000/doc’: Permission denied
Taking a break. Done for now.
|
|
|
|
|
We don't display root dir in settings because we ask people to paste them here, which is a bit of a privacy issue if we're inadvertently publishing things others aren't meant to see.
root will be /usr/bin/codeproject.ai-server-x.y.z (version)
cheers
Chris Maunder
|
|
|
|
|
|
Hey,
Platform: Windows
Server Version: 2.6.2
When making a call to "/v1/vision/custom/list" I'm only getting back a 404 result. The reason why I've looked inti it is that AgentDVR uses this endpoint to list available models in it's "Object Detection" dialog.
Is it intentional that this endpoint does no longer exist?
Nils
modified 16-Apr-24 11:59am.
|
|
|
|
|
Which object detection module are you using?
|
|
|
|
|
I'm using "Object Detection (Coral)"
Nils
|
|
|
|
|
Thanks for letting us know. This will be corrected in the next release of this module (very soon)
cheers
Chris Maunder
|
|
|
|
|
it works again with the latest version (2.2.2) - thank you!
|
|
|
|
|
Hi, I recently started using the Face Processing function with AgentDVR and I'm curious if there's a way to train the face processing AI with many similar faces to increase accuracy. Could you also tell me where the data is saved after I register a face? I'm planning to build a database/face recognition system using CodeProject AI and Agent DVR, but I need a better understanding of how it works.
Previously, I built a database for License Plate Recognition (LPR) with AgentDVR. In this setup, ALPR identifies the plate and plate number, then sends the detected plate data back to AgentDVR. The process is straightforward: once AgentDVR receives the plate data from CPAI, it extracts the data along with additional information in a specific format and passes it to a Python script (via a .bat file). This script processes the data and inserts it into a database (.db file). In the database, entries like "my own car" or "my friend's car" are tagged, and it runs its own checks (by Flask and JavaScript) so that on the client side, users can access a Flask-based webpage that retrieves data from the database, allowing them to review the results. This setup forms the basic framework of how AgentDVR, CPAI, Python, the database, and Flask work together.
However, I'm trying to build something similar for Face Processing, but it seems to be embedded within CodeProject AI, so it's not the same as the ALPR concept I mentioned above, which presents a bit more of a challenge.
I can create a system for my own use, but if I want to share it with my friend, I need to make it more user-friendly. He might face some challenges as he would need to use CPAI's Explorer to delete faces one by one and then add them individually. Additionally, if he forgets which person's face was registered, he won't be able to see it in the explorer, which can be challenging at times.
I'm new to this area and still exploring possibilities and ways to do this, so some questions might not make sense to those more experienced.
With that said, any ideas or assistance would be appreciated. Thank you in advance. Note: I'm doing this for non-profit purposes.
|
|
|
|
|
From what I understand, face processing is not currently a core competency of CPAI, but I’d love for that to change. Look through the existing module and either improve it or greenfield something better. 
|
|
|
|
|
Yea, I think some love needs to be given for Face Processing. My main goal with BI and CPAI was to have the alerts setup, have it capture the alert for person vehicle and send to our phones, but if it detects my roommate or me, it still alerts, just not send to phones. The work around I have currently is to use the geofence and have it not alert in certain areas based on if someone is home. That is not ideal, but it keeps alerts from gong to the phone in most cases when someone is at home. The downdrop is if there is someone else in those zones, say the back porch, it will not alert us by phone. I have tried everything configuration possible on the faces from 5 pictures of each to 100 pictures of each of us and CPAI is just very very spotty at best. There can be a different pic of each of us and 1 time cpai will detect the pic as me, but the next time it will detect it as my roommate. I really hope some love is giving to this module instead of adding all these other models that have nothing to do with detection.
|
|
|
|
|
The ALPR module uses plate detection to find a plate then OCR to extract the digits and text which it then sends back. The Face module uses a face detector (just a YOLOv5 model) and then extracts embeddings which it then stores in a database.
I think what you're after is for the module to return the embeddings, which you can then do with as you please (including building a database you can share).
That's an easy fix if that's what you're after.
cheers
Chris Maunder
|
|
|
|
|
Thank you, Chris. I did a bit of homework on this. That sounds good, to return the embeddings. I see a few possibilities here:
1. Make CPAI's Face Processing registered face database available so it can be managed by the user. I don't know if that is possible or not. But with that, I will be able to simply use the result of the Face Processing for my database.
Also, I have a question if I can train the face processing with multiple faces of the same person? My thought would be the same name but several different embeddings in the database.
Or,
2. The face processing returns the embeddings to the AgentDVR, and then AgentDVR sends it to a Python script so whatever the user wants can be done. However, I don't know if AgentDVR is able to accept the embedding or not. I know with ALPR, the plate number result falls under "{AI}". Here are the strings that AgentDVR supports on export: "{ID}, {OT}, {FILENAME}, {CURRENT_RECORDING}, {MSG}, {NAME}, {GROUPS}, {LOCATION}, {AI} (AI-detected objects), {AIJSON}, {BASE64IMAGE}, {ZONE}", and I don't know which one embedding will fall under.
Overall, I feel option 1 might be easier for me (because I will have less work). Option 2 seems to be more complicated.
Which one can you do or prefer?
|
|
|
|
|
Either works for me, Embeddings are vectors so not sure if it would fit in any of the recognised data types.
You set the DATA_DIR environment variable to tell the module where to store the database. This can be set in the modulesettings.json file:
"EnvironmentVariables": {
...
"DATA_DIR": "C:\MyFaceDatabase",
...
},
cheers
Chris Maunder
|
|
|
|
|
Thank you Chris. That is very valuable information! I tried it, and it definitely makes it easier for the user to manage the registered face database. With that, I can now focus on working with the other end (AgentDVR) to determine how the information will be processed after it passes through AgentDVR.
|
|
|
|
|
I deleted the original post because I thought I fixed it. Turns out that the docker version does the same thing.
I don't know why it was working for weeks, I'm lucky I have Windows, Linux, and CPAI and Deepstack on both. Just a matter of changing the IP address and port in Blue Iris and AI Tool and I'm good again.
Thanks for the tip. I'm getting pretty tired, so I will try to find that setting tomorrow morning. It's been a long day. Thanks again.
|
|
|
|
|
Probably because I had the settings in a folder that was over written.
|
|
|
|
|
I recently picked up a Rockpi 5b and wanted to experiment with Object Detection (YOLOv5 RKNN). I've tried on two different versions of Ubuntu server and can not get it to run. I went down a rabbit hole and updated the module to py 3.10 from 3.9 to get Python dependencies to install successfully but still can not get a successful self-test or image analysis. I gave up on that, removed, reformatted and started over and the current output is below; python 3.9 missing Pillow.
15:28:57:objectdetection_fd_rknn_adapter.py: Traceback (most recent call last):
15:28:57:objectdetection_fd_rknn_adapter.py: File "/usr/bin/codeproject.ai-server-2.6.2/modules/ObjectDetectionYoloRKNN/objectdetection_fd_rknn_adapter.py", line 9, in
15:28:57:objectdetection_fd_rknn_adapter.py: from request_data import RequestData
15:28:57:objectdetection_fd_rknn_adapter.py: File "/usr/bin/codeproject.ai-server-2.6.2/modules/ObjectDetectionYoloRKNN/../../SDK/Python/request_data.py", line 8, in
15:28:57:objectdetection_fd_rknn_adapter.py: from PIL import Image
15:28:57:objectdetection_fd_rknn_adapter.py: ModuleNotFoundError: No module named 'PIL'
15:28:57:Module ObjectDetectionYoloRKNN has shutdown
I'm running it natively (no docker) as I would ideally like to use custom models. Object Detection (YOLOv5 .NET) works just fine although speeds are in the ~500ms range.
modified 16-Apr-24 12:11pm.
|
|
|
|
|
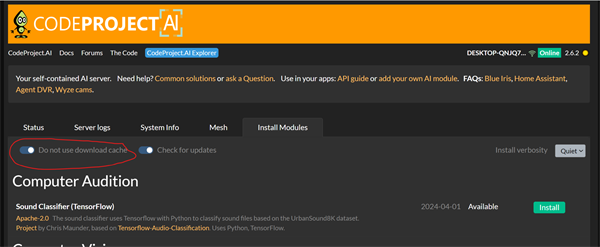
It looks like the module did not get fully install. Try uninstall then reinstall using Do not use download cache
|
|
|
|
|

<pre>20:06:58:System: Orange Pi
20:06:58:Operating System: Linux (Ubuntu 22.04)
20:06:58:CPUs: 1 CPU. (Arm64)
20:06:58:System RAM: 16 GiB
20:06:58:Platform: OrangePi
20:06:58:BuildConfig: Release
20:06:58:Execution Env: Native (SSH)
20:06:58:Runtime Env: Production
20:06:58:Runtimes installed:
20:06:58: .NET runtime: 7.0.17
20:06:58: .NET SDK: 7.0.117
20:06:58: Default Python: 3.10.12
20:06:58: Go: Not found
20:06:58: NodeJS: Not found
20:06:58: Rust: Not found
20:06:58:App DataDir: /etc/codeproject/ai
20:06:58:Video adapter info:
20:06:58:STARTING CODEPROJECT.AI SERVER
20:06:58:RUNTIMES_PATH = /usr/bin/codeproject.ai-server-2.6.2/runtimes
20:06:58:PREINSTALLED_MODULES_PATH = /usr/bin/codeproject.ai-server-2.6.2/preinstalled-modules
20:06:58:DEMO_MODULES_PATH = /usr/bin/codeproject.ai-server-2.6.2/demos/modules
20:06:58:MODULES_PATH = /usr/bin/codeproject.ai-server-2.6.2/modules
20:06:58:PYTHON_PATH = /bin/linux/%PYTHON_NAME%/venv/bin/python3
20:06:58:Data Dir = /etc/codeproject/ai
20:06:58:Server version: 2.6.2
20:07:03:Server: This is the latest version
20:07:34:Preparing to install module 'ObjectDetectionYoloRKNN'
20:07:34:Downloading module 'ObjectDetectionYoloRKNN'
20:07:34:Installing module 'ObjectDetectionYoloRKNN'
20:07:34:ObjectDetectionYoloRKNN: Setting verbosity to quiet
20:07:34:ObjectDetectionYoloRKNN: No schemas installed
20:07:34:ObjectDetectionYoloRKNN: (No schemas means: we can't detect if you're in light or dark mode)
20:07:34:ObjectDetectionYoloRKNN: Installing CodeProject.AI Analysis Module
20:07:34:ObjectDetectionYoloRKNN: ======================================================================
20:07:34:ObjectDetectionYoloRKNN: CodeProject.AI Installer
20:07:34:ObjectDetectionYoloRKNN: ======================================================================
20:07:34:ObjectDetectionYoloRKNN: 224.00 GiB of 231.07 GiB available on Orange Pi
20:07:34:ObjectDetectionYoloRKNN: Installing xz-utils...
20:08:04:Response timeout. Try increasing the timeout value
20:09:14:ObjectDetectionYoloRKNN: WARNING: apt does not have a stable CLI interface. Use with caution in scripts.
20:09:14:ObjectDetectionYoloRKNN: WARNING: apt does not have a stable CLI interface. Use with caution in scripts.
20:09:16:ObjectDetectionYoloRKNN: stty: 'standard input': Inappropriate ioctl for device
20:09:16:ObjectDetectionYoloRKNN: General CodeProject.AI setup
20:09:16:ObjectDetectionYoloRKNN: Setting permissions on downloads folder...done
20:09:16:ObjectDetectionYoloRKNN: Setting permissions on modules download folder...done
20:09:16:ObjectDetectionYoloRKNN: Setting permissions on models download folder...done
20:09:16:ObjectDetectionYoloRKNN: Setting permissions on runtimes folder...done
20:09:16:ObjectDetectionYoloRKNN: Setting permissions on persisted data folder...done
20:09:16:ObjectDetectionYoloRKNN: GPU support
20:09:16:ObjectDetectionYoloRKNN: CUDA (NVIDIA) Present: No
20:09:16:ObjectDetectionYoloRKNN: ROCm (AMD) Present: No
20:09:16:ObjectDetectionYoloRKNN: MPS (Apple) Present: No
20:09:17:ObjectDetectionYoloRKNN: Reading module settings.......done
20:09:17:ObjectDetectionYoloRKNN: Processing module ObjectDetectionYoloRKNN 1.6.1
20:09:17:ObjectDetectionYoloRKNN: Installing Python 3.9
20:09:17:ObjectDetectionYoloRKNN: Python 3.9 is already installed
20:09:22:ObjectDetectionYoloRKNN: Ensuring PIP in base python install... done
20:09:23:ObjectDetectionYoloRKNN: W: https:
20:09:31:ObjectDetectionYoloRKNN: Upgrading PIP in base python install... done
20:09:31:ObjectDetectionYoloRKNN: Installing Virtual Environment tools for Linux...
20:09:39:ObjectDetectionYoloRKNN: Searching for python3-pip python3-setuptools python3.9...installing... done
20:09:39:ObjectDetectionYoloRKNN: stty: 'standard input': Inappropriate ioctl for device
20:09:44:ObjectDetectionYoloRKNN: Creating Virtual Environment (Local)... done
20:09:44:ObjectDetectionYoloRKNN: Checking for Python 3.9...(Found Python 3.9.18) All good
20:09:53:ObjectDetectionYoloRKNN: Upgrading PIP in virtual environment... done
20:10:02:ObjectDetectionYoloRKNN: Installing updated setuptools in venv... done
20:10:02:ObjectDetectionYoloRKNN: checkdir: cannot create extraction directory: assets
20:10:02:ObjectDetectionYoloRKNN: Permission denied
20:10:02:ObjectDetectionYoloRKNN: Downloading Standard YOLOv5 RKNN models... already exists...Expanding... done.
20:10:02:ObjectDetectionYoloRKNN: checkdir: cannot create extraction directory: custom-models
20:10:02:ObjectDetectionYoloRKNN: Permission denied
20:10:03:ObjectDetectionYoloRKNN: Downloading Custom YOLOv5 RKNN models... already exists...Expanding... done.
20:10:03:ObjectDetectionYoloRKNN: Installing Python packages for Object Detection (YOLOv5 RKNN)
20:10:03:ObjectDetectionYoloRKNN: Installing GPU-enabled libraries: If available
20:10:04:ObjectDetectionYoloRKNN: Searching for python3-pip...All good.
20:10:04:ObjectDetectionYoloRKNN: stty: 'standard input': Inappropriate ioctl for device
20:10:07:ObjectDetectionYoloRKNN: Ensuring PIP compatibility... done
20:10:07:ObjectDetectionYoloRKNN: No suitable requirements.txt file found.
20:10:07:ObjectDetectionYoloRKNN: Installing Python packages for the CodeProject.AI Server SDK
20:10:08:ObjectDetectionYoloRKNN: Searching for python3-pip...All good.
20:10:08:ObjectDetectionYoloRKNN: stty: 'standard input': Inappropriate ioctl for device
20:10:11:ObjectDetectionYoloRKNN: Ensuring PIP compatibility... done
20:10:11:ObjectDetectionYoloRKNN: Python packages will be specified by requirements.txt
20:10:21:ObjectDetectionYoloRKNN: - Installing Pillow, a Python Image Library... (❌ failed check) done
20:10:30:ObjectDetectionYoloRKNN: - Installing Charset normalizer... (❌ failed check) done
20:10:40:ObjectDetectionYoloRKNN: - Installing aiohttp, the Async IO HTTP library... (❌ failed check) done
20:10:49:ObjectDetectionYoloRKNN: - Installing aiofiles, the Async IO Files library... (❌ failed check) done
20:10:59:ObjectDetectionYoloRKNN: - Installing py-cpuinfo to allow us to query CPU info... (❌ failed check) done
20:11:08:ObjectDetectionYoloRKNN: - Installing Requests, the HTTP library... (❌ failed check) done
20:11:08:ObjectDetectionYoloRKNN: Scanning modulesettings for downloadable models...No models specified
20:11:08:ObjectDetectionYoloRKNN: Traceback (most recent call last):
20:11:08:ObjectDetectionYoloRKNN: File "/usr/bin/codeproject.ai-server-2.6.2/modules/ObjectDetectionYoloRKNN/objectdetection_fd_rknn_adapter.py", line 9, in
20:11:08:ObjectDetectionYoloRKNN: from request_data import RequestData
20:11:08:ObjectDetectionYoloRKNN: File "/usr/bin/codeproject.ai-server-2.6.2/modules/ObjectDetectionYoloRKNN/../../SDK/Python/request_data.py", line 8, in
20:11:08:ObjectDetectionYoloRKNN: from PIL import Image
20:11:08:ObjectDetectionYoloRKNN: ModuleNotFoundError: No module named 'PIL'
20:11:08:ObjectDetectionYoloRKNN: Self test: Self-test failed
20:11:08:ObjectDetectionYoloRKNN: Module setup time 00:01:52
20:11:08:ObjectDetectionYoloRKNN: Setup complete
20:11:08:ObjectDetectionYoloRKNN: Total setup time 00:03:34
20:11:08:Module ObjectDetectionYoloRKNN installed successfully.
20:11:08:Installer exited with code 0
20:11:08:
20:11:08:Module 'Object Detection (YOLOv5 RKNN)' 1.6.1 (ID: ObjectDetectionYoloRKNN)
20:11:08:Valid: True
20:11:08:Module Path: <root>/modules/ObjectDetectionYoloRKNN
20:11:08:AutoStart: True
20:11:08:Queue: objectdetection_queue
20:11:08:Runtime: python3.9
20:11:08:Runtime Loc: Local
20:11:08:FilePath: objectdetection_fd_rknn_adapter.py
20:11:08:Start pause: 1 sec
20:11:08:Parallelism: 1
20:11:08:LogVerbosity:
20:11:08:Platforms: orangepi
20:11:08:GPU Libraries: installed if available
20:11:08:GPU Enabled: enabled
20:11:08:Accelerator:
20:11:08:Half Precis.: enable
20:11:08:Environment Variables
20:11:08:CUSTOM_MODELS_DIR = <root>/modules/ObjectDetectionYoloRKNN/custom-models
20:11:08:MODELS_DIR = <root>/modules/ObjectDetectionYoloRKNN/assets
20:11:08:MODEL_SIZE = Small
20:11:08:
20:11:08:Started Object Detection (YOLOv5 RKNN) module
20:11:08:objectdetection_fd_rknn_adapter.py: Traceback (most recent call last):
20:11:08:objectdetection_fd_rknn_adapter.py: File "/usr/bin/codeproject.ai-server-2.6.2/modules/ObjectDetectionYoloRKNN/objectdetection_fd_rknn_adapter.py", line 9, in
20:11:08:objectdetection_fd_rknn_adapter.py: from request_data import RequestData
20:11:08:objectdetection_fd_rknn_adapter.py: File "/usr/bin/codeproject.ai-server-2.6.2/modules/ObjectDetectionYoloRKNN/../../SDK/Python/request_data.py", line 8, in
20:11:08:objectdetection_fd_rknn_adapter.py: from PIL import Image
20:11:08:objectdetection_fd_rknn_adapter.py: ModuleNotFoundError: No module named 'PIL'
20:11:08:objectdetection_fd_rknn_adapter.py: has exited
20:11:08:Module ObjectDetectionYoloRKNN has shutdown
20:11:09:Module ObjectDetectionYoloRKNN started successfully.
|
|
|
|
|
It looks like you're installing the Ubuntu installer (all good) but you are missing some permissions.
When you installed the .deb CodeProject.AI Server package did you install under sudo or your local account? When you start up the server, are you starting up under sudo or local?
cheers
Chris Maunder
|
|
|
|
|


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin