
All About MFC Serialization
Describes all aspects of MFC serialization mechanism
Table of Contents
- Background
- What is Serialization
- How does it work
- Word of Caution
- Why can’t I call ar.GetObjectSchema() multiple times?
- Serializing Base and Derived Classes
- 1st Solution: Do all serialization in the derived class
- 2nd Solution: Pop the schema back into the CArchive
- 3rd Solution: Consider Overhaul of Serialize function with Don’t Call Us, We Will Call You design pattern
- 4th Solution: Store your base class schema as the 1st member of your class
- Serializing Pure Base Class
- Serializing with Document/View
- Serializing without Document/View
- Serializing plain old data types
- Serializing CArray template collection
- Serializing to and from the process memory
- Serializing to and from the shared process memory
- Serializing to and from the sockets
- Serializing arbitrary byte stream
- Serializing Windows SDK data structures
- Serializing STL collections
- Serializing STL data types
- Serializing flat C style arrays
- Serializing enumerated types
- Serialization versioning for CObject derived classes
- Serialization versioning for non CObject classes
- Caveats
- Using the code
- History
Introduction
The world of data structures is a vast one. And when we need to write and read those enormous blobs of data to or from the disk, memory, or sockets, MFC serialization is a powerful tool in every programmer’s tool box.
Background
Serialization was part of the MFC (Microsoft Foundation Classes) library since its very first introduction, but I felt it has never received its proper dues because it was largely undocumented. SDK samples that demonstrated the serialization were very limited and covered serialization of the plain old data and CObject derived classes and collections. However with the right extensions we can serialize any data structure in existence, STL collections, user defined collections, any collections (including flat C style arrays). It is undoubtedly is the most powerful, efficient, and blazingly fast way to store and retrieve hierarchical data to and from the disk, memory, or sockets. MFC Serialization supports read write to the disk, memory, and sockets. Writing to the memory is very useful for inter process communications such as clipboard cut/copy/paste operations and writing to sockets is useful when networking with remote machines. I will cover in this article plain old MFC serialization with MFC provided classes, how to serialize STL collections, how to serialize plain Windows SDK data structures, how to serialize C style arrays, how to serialize to process and shared memory and how to serialize to and from sockets. Also I will demonstrate how to use MFC Serialization with or without Document/View architecture such as inside the console applications and TCP/IP servers.
What is Serialization
MSDN documentation gives us the best description:
Serialization is the process of converting an object into a stream of bytes in order to store the object or transmit it to memory, a database, or a file. Its main purpose is to save the state of an object in order to be able to recreate it when needed. The reverse process is called deserialization.
MFC serialization implements binary and text serializations. Binary handled via shift operators (<<, >>) and WriteObject / ReadObject functions. Text serialization is handled with ReadString / WriteString functions.
MFC serialization provides serialization of C++ CObject derived classes with versioning. With the right extensions it can provide serialization for non CObject derived classes. However the versioning in those cases need to be handled manually.
How does it work
In the heart of the MFC serialization lays the CArchive object. CArchive has no base class and it is tightly coupled to work with CFile and CFile derived classes, such as CSocketFile, CSharedFile, or CMemFile. CArchive internally encapsulates an array of bytes that are dynamically grown as needed and are written or read to or from the CFile or CFile derived object.
CFile– provides serialization to or from diskCMemFile– provides serialization to or from process memoryCSharedFile– provides serialization to or from processes shared memory which is accessible by the other processesCSocketFile– provides serialization to or fromCSocketfor network communications- You can also serialize over Named pipes, RPC and other Windows inter process communication mechanisms
CArchive provides serialization of plain old data and C++ CObject derived classes with versioning. To make a CObject class serializable all you need is to add a macro:
// In the class declaration DECLARE_SERIAL(CRoot) // In the class implementation IMPLEMENT_SERIAL(CRoot, CObject, VERSIONABLE_SCHEMA | 1)
Those two macros are adding global extraction operator >> (which calls to CArchive::ReadObject), static function CreateObject, and CRuntimeClass member variable to your class. CRuntimeClass structure has m_lpszClassName member which stores the text representation of your class name. CRuntimeClass also has m_wSchema that holds version information of your class.
These macros internally expand to the following code
//
// DECLARE_SERIAL(CRoot) expands to
//
public:
static CRuntimeClass classCRoot;
virtual CRuntimeClass* GetRuntimeClass() const;
static CObject* PASCAL CreateObject();
AFX_API friend CArchive& AFXAPI operator >> (CArchive& ar, CRoot* &pOb);
//
// IMLEMENT_SERIAL(CRoot, CObject, VERSIONABLE_SCHEMA | 1) expands to
//
CObject* PASCAL CRoot::CreateObject()
{
return new CRoot;
}
extern AFX_CLASSINIT _init_CRoot;
AFX_CLASSINIT _init_CRoot (RUNTIME_CLASS(CRoot));
CArchive& AFXAPI operator >> (CArchive& ar, CRoot * &pOb)
{
pOb = (CRoot *)ar.ReadObject(RUNTIME_CLASS(CRoot));
return ar;
}
AFX_COMDAT CRuntimeClass CRoot::classCRoot =
{
"CRoot", // Name of the class
sizeof(class CRoot), // size
VERSIONABLE_SCHEMA | 1, // schema
CRoot::CreateObject, // pointer to CreateObject function used to intantiate object
RUNTIME_CLASS(CObject), // Base class runtime information
NULL, // linked list of the next class always NULL
&_init_CRoot // pointer to AFX_CLASSINIT structure
};
CRuntimeClass* CRoot::GetRuntimeClass() const
{
return RUNTIME_CLASS(CRoot);
}
There is no insertion operator << because CArchive stores CObject derived class through the base class pointer declared in the global namespace.
CArchive& AFXAPI operator<<(CArchive& ar, const CObject* pOb);
Plain old data is handled rather straightforward. Here is an example of reading and writing float data type:
//
// Storing
//
CArchive& CArchive::operator<<(float f)
{
if(!IsStoring())
AfxThrowArchiveException(CArchiveException::readOnly,m_strFileName);
if (m_lpBufCur + sizeof(float) > m_lpBufMax)
Flush();
*(UNALIGNED float*)m_lpBufCur = f; // Write float into the byte array
m_lpBufCur += sizeof(float); // Increment buffer pointer by the size of the float
return *this;
}
Following code is loading code for the float data type
//
// Loading
//
CArchive& CArchive::operator>>(float& f)
{
if(!IsLoading())
AfxThrowArchiveException(CArchiveException::writeOnly,m_strFileName);
if (m_lpBufCur + sizeof(float) > m_lpBufMax)
FillBuffer(UINT(sizeof(float) - (m_lpBufMax - m_lpBufCur)));
f = *(UNALIGNED float*)m_lpBufCur; // Assign byte array to float size of the float
m_lpBufCur += sizeof(float); // Increment buffer pointer by the size of the float
return *this;
}
Reading and writing CObject derived classes a bit bore complex. And it will be covered in the next sections.
Word of Caution
Because all data is stored in a continuous byte buffer it must be read in the exact same order as it was stored. Failure to do so will result in CArchiveException thrown during load.
Why can’t I call ar.GetObjectSchema() multiple times?
To simply put it you cannot call GetObjectSchema more than once per object load for the following reason.
//
// GetObjectSchema
//
UINT CArchive::GetObjectSchema()
{
UINT nResult = m_nObjectSchema;
m_nObjectSchema = (UINT)-1; // can only be called once per Serialize
return nResult;
}
As to why this is so? My best guess a legacy issues. Member variable CArchive::m_nObjectSchema is very different from CRuntimeClass::m_wSchema in a way that the CArchive object schema is read from the file which can potentially contain many objects with many schemas. It holds schema of an object which is currently being read from a file. Think about it. When you de serialize object such as in the following example (Hypothetically m_nObjectSchema left alone):
void CMyClass::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{
// omitted storing code …
}
else
{
// Loading
UINT nSchema = ar.GetObjectSchema();
switch(nSchema)
{
case 1:
ar >> m_pObject1; // Version schema 10. Serialize may call GetObjectSchema
ar >> m_pObject2; // Version schema 1. Serialize may call GetObjectSchema
ar >> m_pObject3; // Version schema 2. Serialize may call GetObjectSchema
ar >> m_pObject4; // Version schema 15. Serialize may call GetObjectSchema
}
}
// For whatever reason
if(ar.IsLoading())
{
UINT nSchema = ar.GetObjectSchema(); // schema of this class?
}
}
The object schema in the above example has been changed 4 times by the time you finished the loading section of the code. My guess is to eliminate subtle erroneous behavior the MFC framework decided to cut it short at the very source instead of programmers scratching their head as to why their precious data was hosed away.
The GetObjectSchema can only be called once per object load because framework forcefully resets it to (UINT)-1 after each call to the CArchive::GetObjectSchema.
Even the above example in today’s MFC library is fool proof. Listing from the CArchive::ReadObject has following code
//
// CObject* CArchive::ReadObject(const CRuntimeClass* pClassRefRequested)
//
//... omitted code
TRY
{
// allocate a new object based on the class just acquired
pOb = pClassRef->CreateObject();
//... omitted code
// Serialize the object with the schema number set in the archive
UINT nSchemaSave = m_nObjectSchema; // Save current schema
m_nObjectSchema = nSchema; // put new schema into the CArchive::m_nObjectSchema
pOb->Serialize(*this); // Call virtual Serialize
m_nObjectSchema = nSchemaSave; // Pop the saved schema back
}
As you can see it saves current m_nObjectSchema into the nSchemaSave. Assigns current object schema to the m_nObjectSchema. Call Serialize. Pop saved schema back into the m_nObjectSchema. Thus the object schema will never go astray.
Serializing Base and Derived Classes
There are four ways to go around of serialization of the derived and base classes in MFC.
But first let’s look first at the subtle problem. Back in a day of the 16 bit MFC implementation the disk space was a precious commodity, as were the RAM. Thus no matter how many derived classes you have in the class hierarchy, their object schema will be always equal to the final child class schema and will be written only once!
//
//
//
class CBase : public CObject
{
DECLARE_SERIAL(CBase)
public:
int m_i;
float m_f;
double m_d;
virtual void Serialize(CArchive& ar);
};
class CDerived : public CBase
{
DECLARE_SERIAL(CDerived)
public:
long m_l;
unsigned short m_us;
long long m_ll;
virtual void Serialize(CArchive& ar);
};
// Base class version
IMPLEMENT_SERIAL(CBase, CObject, VERSIONABLE_SCHEMA | 1) // Useless schema number. Never written to the file!
void CBase::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code omitted
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
// oh no! nSchema = 2
switch (nSchema)
{
case 1:
ar >> m_i;
ar >> m_f;
ar >> m_d;
break;
}
}
}
// Derived class version
IMPLEMENT_SERIAL(CDerived, CBase, VERSIONABLE_SCHEMA | 2) // actual schema that is written to the file
void CDerived::Serialize(CArchive& ar)
{
CBase::Serialize(ar);
if (ar.IsStoring())
{ // storing code omitted
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
// oh no! nSchema = (UINT)-1 because of 2<sup>nd</sup> call to GetObjectSchema
switch (nSchema)
{
case 1:
case 2:
ar >> m_l;
ar >> m_us;
ar >> m_ll;
break;
}
}
}
Why is that? Quick look at the binary file dump reveals that for the CSerializableDerived class the schema is written only once and it is always equals to the instantiated object schema. In this case it is equal CSerializableDerived class schema even if the base class schema equals to something else.

Tracing into the CArchive::WriteObject reveals to us this code:
// // void CArchive::WriteObject(const CObject* pOb) // // … omitted code // write class of object first CRuntimeClass* pClassRef = pOb->GetRuntimeClass(); // Contains m_wSchema of the CSerializableDerived which = 2 WriteClass(pClassRef); // … omitted code
Tracing into the CArchive::WriteClass framework first writes wNewClassTag WORD value which is equal to 0xFFFF. Then it calls CRuntimeClass::Store function
// // void CArchive::WriteClass(const CRuntimeClass* pClassRef) // // … omitted code // store new class *this << wNewClassTag; // New class tag = 0xFFFF pClassRef->Store(*this); // … omitted code
The CRuntimeClass::Store function obtains the length of the class name and writes object schema followed by the length of the class name and the class name itself. Herein lies the answer to the queston why the object schema written only once for the derived most class.
//
//
//
void CRuntimeClass::Store(CArchive& ar) const
// stores a runtime class description
{
WORD nLen = (WORD)AtlStrLen(m_lpszClassName); // Get the length of the class name
ar << (WORD)m_wSchema << nLen; // Write schema followed by length of the class name into the file. Written only once!!!
ar.Write(m_lpszClassName, nLen*sizeof(char)); // Write class name into the file
}
After CRuntimeClass information was written to the file the framework finally calls virtual Serialize function of our object:
// // void CArchive::WriteObject(const CObject* pOb) // // … omitted code // cause the object to serialize itself ((CObject*)pOb)->Serialize(*this); // … omitted code
Exact opposite happens during object load. First the extraction operator is called. This operator is provided by the IMPLEMENT_SERIAL macro.
//
// Global extraction operator call provided by the IMPLEMENT_SERIAL macro
//
CArchive& AFXAPI operator >> (CArchive& ar, CSerializableDerived* &pOb)
{
pOb = (CSerializableDerived*)ar.ReadObject(RUNTIME_CLASS(CSerializableDerived));
return ar;
}
Tracing into the CArchive::ReadObject reveals us following code
// // CObject* CArchive::ReadObject(const CRuntimeClass* pClassRefRequested) // // ... omitted code // attempt to load next stream as CRuntimeClass UINT nSchema; DWORD obTag; CRuntimeClass* pClassRef = ReadClass(pClassRefRequested, &nSchema, &obTag); // ... omitted code
CArchive::ReadClass function first reads the object tag
//
// CRuntimeClass* CArchive::ReadClass(const CRuntimeClass* pClassRefRequested,
// UINT* pSchema, DWORD* pObTag)
//
// ... omitted code
// read object tag - if prefixed by wBigObjectTag then DWORD tag follows
DWORD obTag;
WORD wTag;
*this >> wTag; // Read the object tag
if (wTag == wBigObjectTag)
*this >> obTag;
else
obTag = ((wTag & wClassTag) << 16) | (wTag & ~wClassTag);
// ... omitted code
CRuntimeClass* pClassRef;
UINT nSchema;
if (wTag == wNewClassTag)
{
// defined as follows
// #define wNewClassTag ((WORD)0xFFFF) // special tag indicating new CRuntimeClass
// new object follows a new class id
if ((pClassRef = CRuntimeClass::Load(*this, &nSchema)) == NULL) // Read CRuntimeClass information from the file
AfxThrowArchiveException(CArchiveException::badClass, m_strFileName);
// ... omitted code
}
// ... omitted code
Following is the listing of the CRuntimeClass::Load function. Please note that the class name cannot exceed 64 characters. If the length of the class name is greater or equal to 64 characters or the CArchive::Read failed to read the class name from the file then function returns NULL. If the class name successfully read from a file the szClassName is NULL terminated at the nLen length value and is looked up in the CRuntimeClass::FromName
//
//
//
CRuntimeClass* PASCAL CRuntimeClass::Load(CArchive& ar, UINT* pwSchemaNum)
// loads a runtime class description
{
if(pwSchemaNum == NULL)
{
return NULL;
}
WORD nLen;
char szClassName[64];
WORD wTemp;
ar >> wTemp; *pwSchemaNum = wTemp; // Read the schema
ar >> nLen; // Read the length of the class name
// load the class name
if (nLen >= _countof(szClassName) ||
ar.Read(szClassName, nLen*sizeof(char)) != nLen*sizeof(char))
{
return NULL;
}
szClassName[nLen] = '\0';
// match the string against an actual CRuntimeClass
CRuntimeClass* pClass = FromName(szClassName);
if (pClass == NULL)
{
// not found, trace a warning for diagnostic purposes
TRACE(traceAppMsg, 0, "Warning: Cannot load %hs from archive. Class not defined.\n",
szClassName);
}
return pClass;
}
CRuntimeClass::FromName simply iterates through the AFX_MODULE_STATE::m_classList and does a comparison by name. If the class found CRuntimeClass pointer is returned. AFX_MODULE_STATE CRuntimeClass discovery is whole another topic that deserves its own article. But suffice it to say that this feature was implemented prior to RTTI (Run Time Type Information) compiler support and it allows runtime type discovery of the MFC classes with RTTI compiler switch turned off. As a matter of fact default setting for the Visual C++ 6.0 RTTI switch was off.
//
//
//
CRuntimeClass* PASCAL CRuntimeClass::FromName(LPCSTR lpszClassName)
{
CRuntimeClass* pClass=NULL;
ENSURE(lpszClassName);
// search app specific classes
AFX_MODULE_STATE* pModuleState = AfxGetModuleState();
AfxLockGlobals(CRIT_RUNTIMECLASSLIST);
for (pClass = pModuleState->m_classList; pClass != NULL;
pClass = pClass->m_pNextClass)
{
if (lstrcmpA(lpszClassName, pClass->m_lpszClassName) == 0)
{
AfxUnlockGlobals(CRIT_RUNTIMECLASSLIST);
return pClass;
}
}
AfxUnlockGlobals(CRIT_RUNTIMECLASSLIST);
#ifdef _AFXDLL
// search classes in shared DLLs
AfxLockGlobals(CRIT_DYNLINKLIST);
for (CDynLinkLibrary* pDLL = pModuleState->m_libraryList; pDLL != NULL;
pDLL = pDLL->m_pNextDLL)
{
for (pClass = pDLL->m_classList; pClass != NULL;
pClass = pClass->m_pNextClass)
{
if (lstrcmpA(lpszClassName, pClass->m_lpszClassName) == 0)
{
AfxUnlockGlobals(CRIT_DYNLINKLIST);
return pClass;
}
}
}
AfxUnlockGlobals(CRIT_DYNLINKLIST);
#endif
return NULL; // not found
}
Back into the CArchive::ReadClass it returns back CRuntimeClass, pSchema, and pObTag pointers.
//
//
//CRuntimeClass* CArchive::ReadClass(const CRuntimeClass* pClassRefRequested,
// UINT* pSchema, DWORD* pObTag)
//... omitted code
// store nSchema for later examination
if (pSchema != NULL)
*pSchema = nSchema;
else
m_nObjectSchema = nSchema;
// store obTag for later examination
if (pObTag != NULL)
*pObTag = obTag;
// return the resulting CRuntimeClass*
return pClassRef;
After CRuntimeClass pointer were successfully obtained the framework calls CreateObject which is provided by the DECLARE_SERIAL and IMPLEMENT_SERIAL macros.
- stores current
CArchive::m_nObjectScemainto thenSchemaSave - Assigns current
CRuntimeClassschema to theCArchive::m_nObjectSchema - Calls virtual Serialize function
- Pops the
nSchemaSaveback into theCArchive::m_nObjectSchema
//
// CObject* CArchive::ReadObject(const CRuntimeClass* pClassRefRequested)
//
//... omitted code
TRY
{
// allocate a new object based on the class just acquired
pOb = pClassRef->CreateObject();
//... omitted code
// Serialize the object with the schema number set in the archive
UINT nSchemaSave = m_nObjectSchema; // Save current schema
m_nObjectSchema = nSchema; // put new schema into the CArchive::m_nObjectSchema
pOb->Serialize(*this); // Call virtual Serialize
m_nObjectSchema = nSchemaSave; // Pop the saved schema back
ASSERT_VALID(pOb);
}
So now you know why your class will only have one schema regardless of how many classes you have in your class hierarchy.
How do we address this issue? There are four ways to go around it. Some are more elegant then the others. Let us look at all of those. Of course this applies only to the cases when you must maintain versions throughout all of your classes. The easiest way is not to version anything however in the real life if your application life expectancy measured in decades it is absolutely imperative to maintain versioning right from the start.
1st Solution: Do all serialization in the derived class
This is less elegant solution but it works and eliminates all surprises. For our above example this code will look like this:
// Derived class version
IMPLEMENT_SERIAL(CDerived, CBase, VERSIONABLE_SCHEMA | 2)
void CDerived::Serialize(CArchive& ar)
{
// Do not call base class
// CBase::Serialize(ar);
if (ar.IsStoring())
{ // storing code
// serialize base members
ar << m_i;
ar << m_f;
ar << m_d;
// serialize this class members
ar << m_l;
ar << m_us;
ar << m_ll;
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
case 2:
// deserialize base members
ar >> m_i;
ar >> m_f;
ar >> m_d;
// deserialize this class members
ar >> m_l;
ar >> m_us;
ar >> m_ll;
break;
}
}
}
This solution is not very pretty. And if your base class has too many members your Serialize function can potentially be enormous.
2nd Solution: Pop the schema back into the CArchive
This solution a bit more elegant however you would still need to increment schemas in all of base classes when schema changes.
// Base class version
IMPLEMENT_SERIAL(CBase, CObject, VERSIONABLE_SCHEMA | 1) // Useless schema number
void CBase::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code omitted
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
// oh no, nSchema = 2
switch (nSchema)
{
case 1:
case 2: // THIS IS REQUIRED!!!
ar >> m_i;
ar >> m_f;
ar >> m_d;
break;
}
// Pop the schema back into the CArchive for derived class to use
ar.SetObjectSchema(nSchema);
}
}
// Derived class version
IMPLEMENT_SERIAL(CDerived, CBase, VERSIONABLE_SCHEMA | 2)
void CDerived::Serialize(CArchive& ar)
{
// Call base class
CBase::Serialize(ar);
if (ar.IsStoring())
{ // storing code omitted
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
case 2:
ar >> m_l;
ar >> m_us;
ar >> m_ll;
break;
}
}
}
3rd Solution: Consider Overhaul of Serialize function with Don’t Call Us, We Will Call You design pattern
Adding private virtual function SerializeImpl(CArchive& ar, UINT nSchema) will eliminate need to call CArchive::GetObjectSchema more than once.
//
//
//
class CBase : public CObject
{
DECLARE_SERIAL(CBase)
public:
int m_i;
float m_f;
double m_d;
virtual void Serialize(CArchive& ar);
private:
virtual void SerializeImpl(CArchive& ar, UINT nSchema);
};
class CDerived : public CBase
{
DECLARE_SERIAL(CDerived)
public:
long m_l;
unsigned short m_us;
long long m_ll;
private:
virtual void SerializeImpl(CArchive& ar, UINT nSchema);
};
// Base class version
IMPLEMENT_SERIAL(CBase, CObject, VERSIONABLE_SCHEMA | 1) // Useless schema number
void CBase::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code omitted
// CDerived::SerializeImpl version will be called
SerializeImpl(ar, (UINT)-1);
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
case 2: // THIS IS STILL REQUIRED!!!
ar >> m_i;
ar >> m_f;
ar >> m_d;
break;
}
// CDerived::SerializeImpl version will be called
SerializeImpl(ar, nSchema);
}
}
void CBase::SerializImpl(CArchive& ar, UINT nSchema)
{
// Not implemented
}
// Derived class version
IMPLEMENT_SERIAL(CDerived, CBase, VERSIONABLE_SCHEMA | 2)
// Eliminates calling to ar.GetObjectSchema() alltogether
void CDerived::SerializImpl(CArchive& ar, UINT nSchema)
{
// call base if you have more than 2 parent classes
// so the parent’s class serialization routine utilized
CBase::SerializImpl(ar, nShema);
if (ar.IsStoring())
{ // storing code omitted
}
else
{ // loading code
switch (nSchema)
{
case 1:
case 2:
ar >> m_l;
ar >> m_us;
ar >> m_ll;
break;
}
}
}
This is somewhat more elegant but it will still require us to increment version number in the all of the base classes when schema changes.
And here comes the most elegant solution.
4th Solution: Store your base class schema as the 1st member of your class
Now this solution addresses the shortcomings of the MFC serialization mechanism. You have access to your base class schema via member variable static classCBase::m_wSchema in our example.
// Base class version
IMPLEMENT_SERIAL(CBase, CObject, VERSIONABLE_SCHEMA | 1) // Not so useless schema number
void CBase::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code
// store the classCBase.m_wSchema; Added by the DECLARE_SERIAL macro and populated by the IMPLEMENT_SERIAL macro
// as the very 1st member
WORD wSchema = (WORD)classCBase.m_wSchema; // Strips VERSIONABLE_SCHEMA and Equals 1 as declared above
ar << wSchema;
ar << m_i;
ar << m_f;
ar << m_d;
}
else
{ // loading code
// Do not call CArchive::GetObjectSchema!
//UINT nSchema = ar.GetObjectSchema();
// Read base object schema
WORD wSchema = 0;
ar >> wSchema;
switch (wSchema) // Equals 1
{
case 1:
ar >> m_i;
ar >> m_f;
ar >> m_d;
break;
}
}
}
// Derived class version
IMPLEMENT_SERIAL(CDerived, CBase, VERSIONABLE_SCHEMA | 2)
void CDerived:: Serialize(CArchive& ar)
{
CBase::Serialize(ar);
if (ar.IsStoring())
{ // storing code omitted
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema(); // equals 2
switch (nSchema)
{
case 1:
case 2:
ar >> m_l;
ar >> m_us;
ar >> m_ll;
break;
}
}
}
This is the most elegant solution because it frees you from the maintenance of the base classes at the cost of adding a sizeof(WORD) to you file per every parent class.
Serializing Pure Base Class
Suppose you have a CObject derived class with pure virtual functons.
//
// CObject derived class with pure virtual functions
//
class CPureBase : public CObject
{
DECLARE_SERIAL(CPureBase)
public:
CPureBase();
virtual ~CPureBase();
virtual void Serialize(CArchive& ar);
virtual CString CanSerialize() const = 0;
virtual CString GetObjectSchema() const = 0;
virtual CString GetObjectRunTimeName() const = 0;
};
Under normal circumstances this will not work because IMPLEMENT_SERIAL macro will add the following function to your code:
//
// Function added by IMPLEMENT_SERIAL macro
//
CObject* PASCAL CPureBase::CreateObject()
{
return new CPureBase; // Compiler error! Cannot instantiate class due to pure virtual functions
}
To work around this issue we would need to create our own version of the IMPLEMENT_SERIAL macro that will return nullptr from the CreateObject function.
//
// Helper macro for Pure base serializable classes
// Removes instancing of the new class in CreateObject()
#define IMPLEMENT_SERIAL_PURE_BASE(class_name, base_class_name, wSchema)\
CObject* PASCAL class_name::CreateObject() \
{ return nullptr; } \
extern AFX_CLASSINIT _init_##class_name; \
_IMPLEMENT_RUNTIMECLASS(class_name, base_class_name, wSchema, \
class_name::CreateObject, &_init_##class_name) \
AFX_CLASSINIT _init_##class_name(RUNTIME_CLASS(class_name)); \
CArchive& AFXAPI operator>>(CArchive& ar, class_name* &pOb) \
{ pOb = (class_name*) ar.ReadObject(RUNTIME_CLASS(class_name)); \
return ar; }
Now you can declare your pure base class serializable.
//
// This code compiles
//
IMPLEMENT_SERIAL_PURE_BASE(CPureBase, CObject, VERSIONABLE_SCHEMA | 1)
// CPureBase
CPureBase::CPureBase()
{
}
CPureBase::~CPureBase()
{
}
// CPureBase member functions
void CPureBase::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code
}
else
{ // loading code
}
}
Serializing with Document/View
This type of serialization is the most covered in MFC literature. If you have application with the document view architecture, serialization is already part of the CDocument derived class. Serialize override provides necessary code. Typical structure of the code looks like this:
void CSerializeDemoDoc::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{
// Storing
ar << m_pRoot;
}
else
{
// Loading
ar >> m_pRoot;
}
}
Serializing without Document/View
To serialize without the Document / View say in the console application you would need to add following code to write to the file
//
// Writing to the file
//
CFile file; // Create CFile object
// Open CFile object
if (!file.Open(_T("Test.my_ext"), CFile::modeCreate | CFile::modeReadWrite | CFile::shareExclusive))
return false;
// Create CArchive object pass a pointer to CFile and , CArchive::store enumeration
CArchive ar(&file, CArchive::store | CArchive::bNoFlushOnDelete);
// write your value
ar << val;
// Close CArchive object
ar.Close();
// Close CFile object
file.Close();
To de serialize or read without the Document / View use following code
//
// Reading from a file
//
CFile file;
if (!file.Open(_T("Test.my_ext"), CFile::modeRead | CFile::shareExclusive))
return false;
CArchive ar(&file, CArchive::load);
ar >> val;
ar.Close();
file.Close();
Just in a few lines of code you have harnessed the power of the CArchive object.
Serializing plain old data types
CArchive provides following insertion and extraction operators to handle the plain old data storage and retrieval.
//
// CArchive operators
//
// insertion operations
CArchive& operator<<(BYTE by);
CArchive& operator<<(WORD w);
CArchive& operator<<(LONG l);
CArchive& operator<<(DWORD dw);
CArchive& operator<<(float f);
CArchive& operator<<(double d);
CArchive& operator<<(LONGLONG dwdw);
CArchive& operator<<(ULONGLONG dwdw);
CArchive& operator<<(int i);
CArchive& operator<<(short w);
CArchive& operator<<(char ch);
#ifdef _NATIVE_WCHAR_T_DEFINED
CArchive& operator<<(wchar_t ch);
#endif
CArchive& operator<<(unsigned u);
template < typename BaseType , bool t_bMFCDLL>
CArchive& operator<<(const ATL::CSimpleStringT<BaseType, t_bMFCDLL>& str);
template< typename BaseType, class StringTraits >
CArchive& operator<<(const ATL::CStringT<BaseType, StringTraits>& str);
template < typename BaseType , bool t_bMFCDLL>
CArchive& operator>>(ATL::CSimpleStringT<BaseType, t_bMFCDLL>& str);
template< typename BaseType, class StringTraits >
CArchive& operator>>(ATL::CStringT<BaseType, StringTraits>& str);
CArchive& operator<<(bool b);
// extraction operations
CArchive& operator>>(BYTE& by);
CArchive& operator>>(WORD& w);
CArchive& operator>>(DWORD& dw);
CArchive& operator>>(LONG& l);
CArchive& operator>>(float& f);
CArchive& operator>>(double& d);
CArchive& operator>>(LONGLONG& dwdw);
CArchive& operator>>(ULONGLONG& dwdw);
CArchive& operator>>(int& i);
CArchive& operator>>(short& w);
CArchive& operator>>(char& ch);
#ifdef _NATIVE_WCHAR_T_DEFINED
CArchive& operator>>(wchar_t& ch);
#endif
CArchive& operator>>(unsigned& u);
CArchive& operator>>(bool& b);
...
If you need to serialize data types which are not declared in the CArchive object, you would need to write your own implementation. We will look at this a bit later when I cover serializing Windows SDK structures.
Serializing CArray template collection
MFC provides serialization support for nearly all of its collection and in order to serialize MFC collections all you need to do is to call collection’s version of Serialize(CArchive& ar). CArray is different because it is a template and the template type isn’t known ahead. And the type potentially may or may not be derived from CObject. Default implementation of the CArray::Serialize function is listed below. All it does is writes size of the CArray during write operation and reads size of the CArray from disk and resizes CArray during read operation. It then kindly forwards the call to SerializeElements<TYPE>() function.
//
// Serialize function forwards call to the SerializeElements<TYPE>()
//
template<class TYPE, class ARG_TYPE>
void CArray<TYPE, ARG_TYPE>::Serialize(CArchive& ar)
{
ASSERT_VALID(this);
CObject::Serialize(ar);
if (ar.IsStoring())
{
// Just writes the collection size
ar.WriteCount(m_nSize);
}
else
{
// Just reads the collection size and resizes the CArray
DWORD_PTR nOldSize = ar.ReadCount();
SetSize(nOldSize, -1);
}
SerializeElements<TYPE>(ar, m_pData, m_nSize);
}
The user must provide appropriate implementation of the SerializeElements<TYPE>() for the type being stored or retrieved from the archive. Following listing demonstrates SerializeElements<TYPE> implementation for CAge class. Please refer to the SerializeDemo project for the implementation details.
//
//
//
class CAge : public CObject
{
DECLARE_SERIAL(CAge)
public:
CAge();
CAge(int nAge);
virtual ~CAge();
virtual void Serialize(CArchive& ar);
UINT m_nAge;
};
// CArray serialization helper specialized for the CAge class
template<> inline void AFXAPI SerializeElements(CArchive& ar, CAge** pAge, INT_PTR nCount)
{
for (INT_PTR i = 0; i < nCount; i++, pAge++)
{
if (ar.IsStoring())
{
ar << *pAge; // Calls CArchive::WriteObject
}
else
{
CAge* p = nullptr;
ar >> p; // Calls CArchive::ReadObject
*pAge = p;
}
}
}
Serializing to and from the process memory
Serialization to and from memory is supported via CMemFile. CMemFile does not require a file name.
// // Write to the memory // CMemFile file; CArchive ar(&file, CArchive::store); ar << val; ar.Close();
Serialization from the memory done in the following manner
// // Read from the memory // CMemFile file; // CByteArray aBytes declared and populated elsewhere file.Attach(m_aBytes.GetData(), m_aBytes.GetSize()); CArchive ar(&file, CArchive::load); ar >> val; ar.Close();
Serializing to and from the shared process memory
Serialization to and from memory is supported via CSharedFile. This is very useful if you want to transfer your serialized object to the clipboard for pasting into another instance of your application or for passing it to another application.
//
// Write to the shared memory to do a clipboard copy operation
//
UINT m_nClipboardFormat = RegisterClipboardFormat(_T("MY_APP_DATA"));
CSharedFile file(GMEM_MOVEABLE | GMEM_SHARE | GMEM_ZEROINIT);
CArchive ar(&file, CArchive::store | CArchive::bNoFlushOnDelete);
// CView derived class
GetDocument()->Serialize(ar);
EmptyClipboard();
SetClipboardData(m_nClipboardFormat, file.Detach());
CloseClipboard();
ar.Close();
file.Close();
Serialization from the shared memory paste operation from the clipboard:
//
// Read from the shared memory clipboard paste
//
UINT m_nClipboardFormat = RegisterClipboardFormat(_T("MY_APP_DATA"));
if (!OpenClipboard())
return;
CSharedFile file(GMEM_MOVEABLE | GMEM_SHARE | GMEM_ZEROINIT);
HGLOBAL hMem = GetClipboardData(m_nClipboardFormat);
if (hMem == nullptr)
{
CloseClipboard();
return;
}
file.SetHandle(hMem);
CArchive ar(&file, CArchive::load);
// CView derived class
GetDocument()->DeleteContents();
GetDocument()->Serialize(ar);
CloseClipboard();
ar.Close();
file.Close();
Serializing to and from the sockets
Serialization to and from sockets is done via the CSocketFile class. You can serialize CArchive into the CSocket only if the CSocket is of the type SOCK_STREAM. This topic is a bit more complex than it is described in the MSDN documentation. Official documentation describes that you can write and read to the CSocket with the CSocketFile. This is true for the write operation but for the read operation this is not necessarily true. If your transmitted data size is a few bytes only then yes you can use CSocketFile for the receiving the data. However if you data size is in megabytes (or any size greater than the reading buffer) then you will likely to receive the data in several reads and you will have to accumulate all of it into the CByteArray structure first and only after all the data has been received you can attach it to the CMemFile rather than CSocketFile and de serialize. Trying to read partial data from the CSocketFile usually results in CArchiveException.
//
// Write to the socket. In this case using CSocketFile is fine
//
CSocket sock;
if (!sock.Create()) // Defaults to the SOCK_STREAM
return;
// Assuming there is a server running on the local host port 1011
if (!sock.Connect(_T("127.0.0.1"), 1011))
return;
CSocketFile file(&sock);
CArchive ar(&file, CArchive::store | CArchive::bNoFlushOnDelete);
// Write value to the socket
ar << m_pRoot;
ar.Close();
file.Close();
sock.Close();
Serialization from the socket is a bit more complicated. I am giving the full listing of the class to demonstrate how to properly read large binary data set from the socket. For the full source code listing please refer to the example project SerializeTcpServer.
//
// Read from the socket. In this case using CSocketFile will not work
// if the transmitted data is greater that the receiving buffer size
//
// CSocket derived class declaration
class CSockThread;
// CRecvSocket command target
class CRecvSocket : public CSocket
{
public:
CRecvSocket();
virtual ~CRecvSocket();
virtual void OnReceive(int nErrorCode);
CSockThread* m_pThread; // Parent thread to ensure our server handles multiple connections simultaneously
CByteArray m_aBytes; // Array of received bytes
private:
DWORD m_dwReads; // Number of reads
void Display(CRoot* pRoot);
};
// Implementation
#define INCOMING_BUFFER_SIZE 65536
// CRecvSocket
CRecvSocket::CRecvSocket(): m_pThread(nullptr)
, m_dwReads(0)
{
}
CRecvSocket::~CRecvSocket()
{
}
// CRecvSocket member functions
void CRecvSocket::OnReceive(int nErrorCode)
{
// yield 10 msec
Sleep(10);
// Our reading buffer
BYTE btBuffer[INCOMING_BUFFER_SIZE] = { 0 };
// Read from the socket size of our buffer size or less
int nRead = Receive(btBuffer, INCOMING_BUFFER_SIZE);
switch (nRead)
{
case 0:
// No data - Quit
m_pThread->PostThreadMessage(WM_QUIT, 0, 0);
break;
case SOCKET_ERROR:
if (GetLastError() != WSAEWOULDBLOCK)
{
// Socket error - Quit
m_pThread->PostThreadMessage(WM_QUIT, 0, 0);
}
break;
default:
// Increment read counter
m_dwReads++;
// Read into the byte array
CByteArray aBytes;
// Resize our byte array to the size of the received data
aBytes.SetSize(nRead);
// Copy received data into the CByteArray
CopyMemory(aBytes.GetData(), btBuffer, nRead);
// Append received data to m_aBytes member
m_aBytes.Append(aBytes);
DWORD dwReceived = 0;
// Look ahead for more incoming data
if (IOCtl(FIONREAD, &dwReceived))
{
// No more incoming data
if (dwReceived == 0)
{
// We have received all of the incoming data
// Instead of CSocketFile use CMemFile
CMemFile file;
file.Attach(m_aBytes.GetData(), m_aBytes.GetSize());
CArchive ar(&file, CArchive::load);
CRoot* pRoot = nullptr;
TRY
{
ar >> pRoot;
}
CATCH(CArchiveException, e)
{
std::cout << "Error reading data " << std::endl;
}
END_CATCH
if (pRoot)
{
// Use our de serialized CRoot class
Display(pRoot);
delete pRoot;
}
ar.Close();
file.Close();
// finally quit
m_pThread->PostThreadMessage(WM_QUIT, 0, 0);
}
}
}
CSocket::OnReceive(nErrorCode);
}
In today’s applications you will rarely receive all transmission of the binary or text data in just one OnReceive call. Thus you need to accumulate all of the data into the array of bytes. And only then you can successfully de serialize it by attaching the accumulated CByteArray to the CMemFile. The above example calls IOCtl(FIONREAD, &dwReceived) to determine if more data is inbound. The rule of thumb is this: because our reading buffer is equal to the 65536 bytes any data transmitted greater than the reading buffer will result in more than one read.
The CSockThread* m_pThread; implementation is provided in the example project SerializeTcpServer.
Serializing arbitrary byte stream
Arbitrary byte stream is basically any binary file that you do not know or do not care about its internal structure. An example is that you want to store a JPEG images or mpeg 4 movies files inside of your class data without any knowledge of the underlying data structure. You may de serialize it later and use it with the appropriate application. The MFC serialization allows you to easily store such data.
In the following code we will store the byte stream of four JPEG pictures
//
// Declare class to hold an array of JPEG images
//
class CMyPicture : public CObject
{
DECLARE_SERIAL(CMyPicture)
public:
CMyPicture();
virtual ~CMyPicture();
virtual void Serialize(CArchive& ar);
CString GetHeader() const;
CString m_strName; // Original image file name
CString m_strNewName; // New image file
CByteArray m_bytes; // Image binary data array
};
typedef CTypedPtrArray<CObArray, CMyPicture*> CMyPictureArray;
Following listing is the body of the class
//
// Class to store JPEG images
//
IMPLEMENT_SERIAL(CMyPicture, CObject, VERSIONABLE_SCHEMA | 1)
// CMyPicture
CMyPicture::CMyPicture()
{
}
CMyPicture::~CMyPicture()
{
}
// CMyPicture member functions
void CMyPicture::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code
ar << m_strName;
ar << m_strNewName;
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
ar >> m_strName;
ar >> m_strNewName;
break;
}
}
// Serialize arbitrary byte stream into or from the file
m_bytes.Serialize(ar);
}
To populate such a class with the JPEG image data all you need to do is following
//
// CMyPictureArray m_aPictures declared in the class header as a member
//
m_aPictures.Add(InitPicture("Water lilies.jpg", "Water lilies Output.jpg"));
m_aPictures.Add(InitPicture("Blue hills.jpg", "Blue hills Output.jpg"));
m_aPictures.Add(InitPicture("Sunset.jpg", "Sunset Output.jpg"));
m_aPictures.Add(InitPicture("Winter.jpg", "Winter Output.jpg"));
UpdateAllViews(nullptr, HINT_GENERATED_DATA);
SetModifiedFlag();
}
// Read binary stream from an unknown file
std::vector<BYTE> CSerializeDemoDoc::ReadBinaryFile(const char* filename)
{
std::basic_ifstream<BYTE> file(filename, std::ios::binary);
return std::vector<BYTE>((std::istreambuf_iterator<BYTE>(file)), std::istreambuf_iterator<BYTE>());
}
CMyPicture* CSerializeDemoDoc::InitPicture(const char* sFileName, const char* sOutFileName)
{
std::vector<BYTE> vJPG = ReadBinaryFile(sFileName);
CMyPicture* pPicture = new CMyPicture;
pPicture->m_strName = sFileName;
pPicture->m_strNewName = sOutFileName;
pPicture->m_bytes.SetSize(vJPG.size());
CopyMemory(pPicture->m_bytes.GetData(), (void*)&vJPG[0], vJPG.size() * sizeof(BYTE));
return pPicture;
}
// Writes JPEG images back to the hard drive
void CSerializeDemoDoc::OnTestdataWriteimagedatatodisk()
{
for (INT_PTR i = 0; i < m_pRoot->m_aPictures.GetSize(); i++)
{
CMyPicture* pPic = m_pRoot->m_aPictures.GetAt(i);
std::ofstream fout(pPic->m_strNewName, std::ios::out | std::ios::binary);
fout.write((char*)pPic->m_bytes.GetData(), pPic->m_bytes.GetSize());
fout.close();
}
AfxMessageBox(_T("Finished writing images back to disk"), MB_ICONINFORMATION);
}
Serializing Windows SDK data structures
Serialization of the Windows SDK structures is not provided by the CArchive class. However it is nearly effortless to add a support for such serialization. Following is the code demonstrates how to serialize LOGFONT SDK structure.
//
// LOGFONT SDK structure serialization code
//
// LOGFONT write
inline CArchive& AFXAPI operator <<(CArchive& ar, const LOGFONT& lf)
{
CString strFace(lf.lfFaceName);
ar << lf.lfHeight;
ar << lf.lfWidth;
ar << lf.lfEscapement;
ar << lf.lfOrientation;
ar << lf.lfWeight;
ar << lf.lfItalic;
ar << lf.lfUnderline;
ar << lf.lfStrikeOut;
ar << lf.lfCharSet;
ar << lf.lfOutPrecision;
ar << lf.lfClipPrecision;
ar << lf.lfQuality;
ar << lf.lfPitchAndFamily;
ar << strFace;
return ar;
}
// LOGFONT read
inline CArchive& AFXAPI operator >> (CArchive& ar, LOGFONT& lf)
{
CString strFace;
ar >> lf.lfHeight;
ar >> lf.lfWidth;
ar >> lf.lfEscapement;
ar >> lf.lfOrientation;
ar >> lf.lfWeight;
ar >> lf.lfItalic;
ar >> lf.lfUnderline;
ar >> lf.lfStrikeOut;
ar >> lf.lfCharSet;
ar >> lf.lfOutPrecision;
ar >> lf.lfClipPrecision;
ar >> lf.lfQuality;
ar >> lf.lfPitchAndFamily;
ar >> strFace;
_tcscpy_s(lf.lfFaceName, strFace);
return ar;
}
After you have defined the LOGFONT extraction and insertion operators all you need to do is following code snippet.
//
// Serialize LOGFONT structure m_lf
//
void CRoot::Serialize(CArchive& ar)
{
CBase::Serialize(ar);
if (ar.IsStoring())
{ // storing code
ar << m_lf; // Write LOGFONT
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
ar >> m_lf; // Read LOGFONT
break;
}
}
}
Next code snippet serializes WINDOWPLACEMENT SDK structure:
//
// Serializing WINDOWPLACEMENT
//
// WINDOWPLACEMENT write
inline CArchive& AFXAPI operator <<(CArchive& ar, const WINDOWPLACEMENT& val)
{
ar << val.flags;
ar << val.length;
ar << val.ptMaxPosition.x;
ar << val.ptMaxPosition.y;
ar << val.ptMinPosition.x;
ar << val.ptMinPosition.y;
ar << val.rcNormalPosition.bottom;
ar << val.rcNormalPosition.left;
ar << val.rcNormalPosition.right;
ar << val.rcNormalPosition.top;
ar << val.showCmd;
return ar;
}
// WINDOWPLACEMENT read
inline CArchive& AFXAPI operator >> (CArchive& ar, WINDOWPLACEMENT& val)
{
ar >> val.flags;
ar >> val.length;
ar >> val.ptMaxPosition.x;
ar >> val.ptMaxPosition.y;
ar >> val.ptMinPosition.x;
ar >> val.ptMinPosition.y;
ar >> val.rcNormalPosition.bottom;
ar >> val.rcNormalPosition.left;
ar >> val.rcNormalPosition.right;
ar >> val.rcNormalPosition.top;
ar >> val.showCmd;
return ar;
}
Then reading and writing the WINDOWPLACEMENT structure becomes as trivial as this
//
// Reading and writing WINDOWPLACEMENT structure
//
void CRoot::Serialize(CArchive& ar)
{
CBase::Serialize(ar);
if (ar.IsStoring())
{ // storing code
ar << m_wp; // Write WINDOWPLACEMENT struct
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
ar >> m_wp; // Read WINDOWPLACEMENT struct
break;
}
}
}
Serializing STL collections
Serialization of the STL collection is just as trivial as the serialization of the SDK data structures. Let’s define insertions and extractions operators for the popular STL collections. To serialize std::vector<int> we would need following definitions
//
// STL vector<int> write
//
inline CArchive& AFXAPI operator <<(CArchive& ar, const std::vector<int>& val)
{
// first store the size of the vector
ar << (int)val.size();
for each (int k in val)
{
ar << k; // store each int into the file
}
return ar;
}
To read the STL vector back into the std::vector<int> we do the following
//
// STL vector<int> read
//
inline CArchive& AFXAPI operator >> (CArchive& ar, std::vector<int>& val)
{
int nSize;
ar >> nSize; // read the vector size
val.resize(nSize); // resize vector to the read size
for (size_t i = 0; i < (size_t)nSize; i++)
{
ar >> val[i]; // retrieve values
}
return ar;
}
Serialization of the std::map<char, int> collection. First we store the size of the map. Because underlying element of the std::map<char, int> is a std::pair<char, int> we store the first and the second members of the pair.
//
// std::map<char, int> write
//
inline CArchive& AFXAPI operator <<(CArchive& ar, const std::map<char, int>& val)
{
ar << (int)val.size();
for each (std::pair<char, int> k in val)
{
ar << k.first;
ar << k.second;
}
return ar;
}
Reading code for the std::map<char, int> as follows.
//
// std::map<char, int> read
//
inline CArchive& AFXAPI operator >> (CArchive& ar, std::map<char, int>& val)
{
int nSize;
ar >> nSize;
for (size_t i = 0; i < (size_t)nSize; i++)
{
std::pair<char, int> k;
ar >> k.first;
ar >> k.second;
val.insert(k);
}
return ar;
}
Serialization of the STL fixed size std::array<int, 3>.
//
// STL std::array<int, 3> write
//
inline CArchive& AFXAPI operator <<(CArchive& ar, const std::array<int, 3>& val)
{
for each (int k in val)
{
ar << k;
}
return ar;
}
std::array<int, 3> reading operator.
//
// STL std::array<int, 3> read
//
inline CArchive& AFXAPI operator >> (CArchive& ar, std::array<int, 3>& val)
{
for (size_t i = 0; i < (size_t)val.size(); i++)
{
ar >> val[i];
}
return ar;
}
Serialization of the std::set<std::string> collection.
//
// STL std::set<std::string> write
//
inline CArchive& AFXAPI operator <<(CArchive& ar, const std::set<std::string>& val)
{
ar << (int)val.size(); // write the size first
for each (std::string k in val)
{
ar << CStringA(k.c_str());
}
return ar;
}
Reading code of the std::set<std::string> collection.
//
// STL std::set<std::string> read
//
inline CArchive& AFXAPI operator >> (CArchive& ar, std::set<std::string>& val)
{
int nSize;
ar >> nSize;
for (size_t i = 0; i < (size_t)nSize; i++)
{
CStringA str;
ar >> str;
val.insert(std::string(str));
}
return ar;
}
Serializing STL data types
Serialization of the STL types is just as trivial as the serialization of the SDK data structures. First we need an extraction and the insertion operator definition. To serialize or de serialize std::string we need to add following operators:
//
// STL std::string write
//
inline CArchive& AFXAPI operator <<(CArchive& ar, const std::string& val)
{
ar << CStringA(k.c_str()); // because std::string is ANSI we can pass it as a constructor to the CStringA class
return ar;
}
De serialize std::string:
//
// STL std::string read
//
inline CArchive& AFXAPI operator >> (CArchive& ar, std::string& val)
{
CStringA str;
ar >> str;
val = str;
return ar;
}
I will stop here with the STL data and containers serialization implementation. When you saw one STL collection and one STL type serialized, you have seen them all. I will leave it to the reader as an exercise to serialize std::pair, std::tuple, std::unordered_map etc.
Serializing flat C style arrays
To serialize flat C arrays you will follow the same procedure as with serializing collection. But because flat C style array has known size there is no need to store its size in the file.
//
// Write float val[3]
//
inline CArchive& AFXAPI operator <<(CArchive& ar, float val[3])
{
for(int i = 0; i < 3; i++)
{
ar << val[i];
}
return ar;
}
Reading flat C style array.
//
// read float val[3]
//
inline CArchive& AFXAPI operator >> (CArchive& ar, float val[3])
{
for (size_t i = 0; i < 3; i++)
{
ar >> val[i];
}
return ar;
}
Serializing enumerated types
To serialize enumeration you really need an extraction operator because when inserting an enumeration implicitly converted into an int. But providing both the insertion and extraction operators for enumeration results in the much more cleaner solution and potentially eliminates nasty surprises in the future.
//
// Enumeration that we want to serialize
//
enum EMyTestEnum
{
ENUM_0,
ENUM_1,
};
Write enumeration code.
//
// Write enumeration EMyTestEnum
//
inline CArchive& AFXAPI operator <<(CArchive& ar, const EMyTestEnum& val)
{
int iTemp = val;
ar << iTemp;
return ar;
}
Read enumeration code.
//
// Read enumeration EMyTestEnum
//
inline CArchive& AFXAPI operator >> (CArchive& ar, EMyTestEnum& val)
{
int iTmp = 0;
ar >> iTmp;
val = (EMyTestEnum)iTmp;
return ar;
}
Serialization versioning for CObject derived classes
This is rather interesting topic and versioning of the CObject derived can be done in two ways. Let assume we have a class whose version is constantly evolving as the new features are implemented into the core application.
//
// Any source code blocks look like this
//
class CMyObject : public CObject
{
DECLARE_SERIAL(CMyObject)
public:
CMyObject();
virtual ~CMyObject();
virtual void Serialize(CArchive& ar);
// Version 1 data
float m_f;
double m_d;
// Version 2 data
COLORREF m_backColor;
COLORREF m_foreColor;
// Version 3 data
CString m_strDescription;
// Version 4 data
CString m_strNotes;
};
To serialize such an object and still being able to read the Versions 1, 2, and 3 older files, we can implement this in the following ways.
//
// Version 4 object
//
IMPLEMENT_SERIAL(CMyObject, CObject, VERSIONABLE_SCHEMA | 4)
void CMyObject::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code
ar << m_f;
ar << m_d;
ar << m_backColor;
ar << m_foreColor;
ar << m_strDescription;
ar << m_strNotes;
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
case 1:
ar >> m_f;
ar >> m_d;
break;
case 2:
ar >> m_f;
ar >> m_d;
ar >> m_backColor;
ar >> m_foreColor;
break;
case 3:
ar >> m_f;
ar >> m_d;
ar >> m_backColor;
ar >> m_foreColor;
ar >> m_strDescription;
break;
case 4:
ar >> m_f;
ar >> m_d;
ar >> m_backColor;
ar >> m_foreColor;
ar >> m_strDescription;
ar >> m_strNotes;
break;
}
}
}
This approach although crystal clear is tedious at best. There is much of the repetitive code. Another approach is to load this data in reverse and let the switch case statement to fall through to the correct version of the file.
//
// Version 4 object
//
IMPLEMENT_SERIAL(CMyObject, CObject, VERSIONABLE_SCHEMA | 4)
void CMyObject::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{ // storing code
// Add new features to the top rather than bottom
ar << m_strNotes; // Version 4
ar << m_strDescription; // Version 3
ar << m_backColor; // Version 2
ar << m_foreColor; // Version 2
ar << m_f; // Version 1
ar << m_d; // Version 1
}
else
{ // loading code
UINT nSchema = ar.GetObjectSchema();
switch (nSchema)
{
// Reverse case statements. New version goes on top without break statement
// to let it simply fall through all the versions
case 4:
ar >> m_strNotes; // fall through to version 3
case 3:
ar >> m_strDescription; // fall through to version 2
case 2:
ar >> m_backColor;
ar >> m_foreColor; // fall through to version 1
case 1:
ar >> m_f;
ar >> m_d;
break; // finally break from version 1
}
}
}
This is much cleaner versioning solution that eliminates all of the repetitive code.
Serialization versioning for non CObject classes
To serialize non CObject derived class we simply will follow same rule as with the Windows SDK structures.
//
// Non CObject class
//
class CMyObject
{
public:
CMyObject();
virtual ~CMyObject();
static const short VERSION = 1;
float m_f;
double m_d;
};
Write the version number as the very first member. Then when reading depending what is the version inside the file you can take it through appropriate read procedure that corresponds to the version loaded.
//
// Serializing CMyObject
//
// CMyObject write
inline CArchive& AFXAPI operator <<(CArchive& ar, const CMyObject & val)
{
ar << val.VERSION; // Write the current version of the class as very first item
ar << val.m_f;
ar << val.m_d;
return ar;
}
// CMyObject read
inline CArchive& AFXAPI operator >> (CArchive& ar, CMyObject & val)
{
short nVersion = 0;
ar >> nVersion;
switch(nVersion)
{
case 1:
ar >> val.m_f;
ar >> val.m_d;
break;
}
return ar;
}
Caveats
Do not serialize WIN32 and WIN64 typedefs ever! If you upgrade your application to the 64 bit and try to read a file which was created with the 32 bit version of the application, which happened to serialize WIN32/64 typedefs (such as DWORD_PTR) it will fail miserably. Because DWORD_PTR on the 32 bit architecture is 4 bytes long and 8 bytes long on WIN64 so reading 4 bytes into the 8 bytes and vice versa will result in CArchiveException and it will make your file useless to another bit aligned version of your application. Serialize only hard known types. If you must use 64 bit integer then serialize it as __int64 explicitly in both 32 and 64 bit versions of your application. This is especially concerning if you are serializing SDK structures. You will need to carefully examine structure declaration and if there are potentially WIN32/64 typedefs present, explicitly cast them to the largest size if you building 32 bit application and plan to upgrade it to 64 bit in the future.
Stick to either to UNICODE or ANSI period. If for whatever reason you must maintain both ANSI and UNICODE versions of your application then serialize exclusively either CStringA or CStringW so another version can read the file. Suffice it to say that string such as "hello" will be stored as 5 bytes long in ANSI string but 10 bytes long for the UNICODE version.
Link to MFC statically to eliminate runtime dependency from the MFCXX.DLL, or any other 3rd party library for that matter. Hypothetically if the sizeof(WhateverClass) has changed in a newer version of the 3rd party DLL and your application dynamically linked to it plus serializes it, your application will fail to read the file. Better safe than sorry. So if you are not in control of the 3rd party library code, then link to it statically. A little planning ahead goes a long way.
Using the code
I have supplied the SerializeDemo solution project that demonstrates all aspects described in this article. This solution contains 4 subprojects:
SerializeData– houses data structures and operators that are used by all projectsSerializeDemo– MFC Document / View applicationSerializeTcpServer– a console server application running on a local host"127.0.0.1"port1011. You may need to change the port number if is already 1011 occupied on your machine. SerializeDemo application demo application can connect to this server for transmitting serialized dataSerializationWithoutDocView– console application that demonstrates usage ofCArchivewithout Document / View architecture

SerializeDemo application in action.
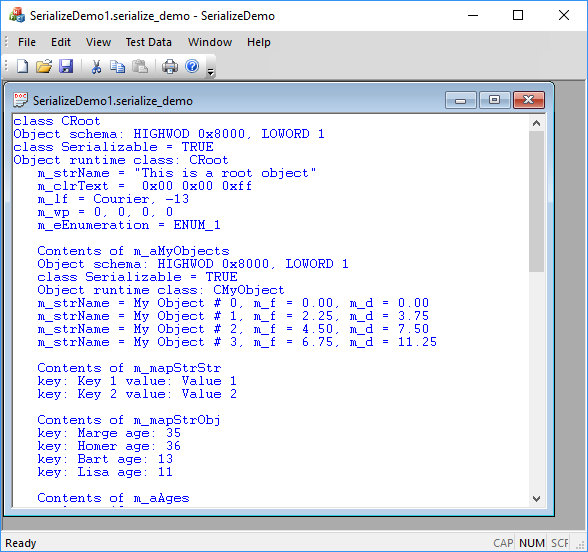
Try to play with this application using following menu commands.

Try using Edit Copy and Paste into the new instance of the SerializeDemo application.
Serialize TCP Server in action.

The SerializeDemo app sent serialized data to the server. Server prints received binary data.

History
March 16th 2017 Original artice.
Sep 28 2018. Fixed a few typos
Jan 9 2019. Added table of contents since article is quiet long