
XLL Auto-Generation - An Example of a Metadata Driven Tool
4.60/5 (6 votes)
XLL Auto-Generation - An Example of a Metadata Driven Tool
Introduction
It is not uncommon for libraries to support multiple languages. That typically requires interface layers to wrap the core functionality. For example, in banking, pricing libraries are typically written in C++ for speed but are made available in a range of languages such as Java, Python, C#, R as well as Excel.
Although the writers of the core library are hopefully highly skilled, they may not be experts in cross-language development. Even if they were, writing interface code would not be a good use of their time.
There are at least two ways in which the issue is usually addressed, (i) the code library can be written in such a way that it is easy to interface with client code, or (ii) interface code can be generated by a tool.
The first approach is seductive. However the problem is that the client code can have an undue influence on the structure of the library. The author has seen numerous pricing libraries that are proported to have been written in C++ for speed but are infested with VARIANTs or XML or COM objects at every level. The compromises entailed in using those structures invariably increases complexity and decreases performance. The "correct" architecture is shown below; each layer is concerned with optimising its own behaviour. No data structures migrate from the client code into the library or visa versa simply because at some point it might be convenient to do so.

The second approach is consistent with the architecture but can be costly if there is no off-the-shelf tool available. This article shows the steps involved in writing such a tool. In particular, the project code demonstrates how to automatically generate interface code for a C++ library using metadata. The metadata is produced by a parser and used to generate code - in our case, code for an XLL to expose functions, objects and methods in EXCEL.
Code Generation
Code generators have several benefits: (i) The code produced should be of a consistent high quality. If the library is large and/or widely distributed, the benefit of knowing that one potential source of error (bugs in the interface code) has been removed cannot be underestimated. (ii) Code generation should be much quicker and easier to do than writing by hand.
The ideal situation is to have the library authors simply "mark" relevant sections of the library code as externally available. Code is then generated by running a parser is run over the (preprocessed) source code to build a meta-data description of the exported functions/methods; the meta-data is then used to drive the code generators.
The Metadata Compiler
Library code is made available in .dll (Windows) or .so or .a(Linux) files. The nature of the beast is that it must be possible to find out what functions are exported by (are available in) libraries. To see the information available, use depends.exe on a Windows .dll or nm -D on Linux .so or .a file. However there is insufficient information for our purposes.
It is therefore necessary to provide an additional mechanism to mark the exported functions/methods in the source. Our project code uses the pseudo-attribute QExport as below. Note there are no spaces inside the [[ ]].
// [[QExport]] <== This marks the following function/method as exported.
double density(double T, double P, double humidity);
Restriction of data types
It is a complex task to map complex data types from one language to another. To make auto-generation viable, the data types used in the signature of an QExported function is restricted to the following types:
bool, char,short,int,long,long long,float,double- unsigned versions of the integer types specified in the previous item.
- pointers and references to the previously specified numeric types.
- objects references.
The code generator does not support for any string types such as std::string (which is a C++ only construct that should not be allowed to make its way across the boundary into client code). Support for objects will be discussed later on the section on object wrappers.
Tokeniser
At first glance parsers appear to be beasts of unimaginable complexity, but that is not so. Generally parsing is broke down into 2 steps:
- A character stream is transformed into a token stream.
- The token stream is matched against a grammar.
Tokenisation is not mandatory and some parsers do not have a separate step, however it is often easier to think in terms of tokens rather than characters. For example, the following string
"int main(int argc, char** argv);"
generates the following token list:
int main ( int argc , char * * argv ) ;
A separate tokenisation step can simplify the consuming grammar. For example, the scope resolution operator "::" can be returned as a single token, rather than requiring the parser to look ahead to see if each ":" is followed by another.
Parser
1. The parser is only interested in export functions/methods. It therefore needs to detect the [[QExport]] pseudo-attribute. A separate token type will be dedicated to it.
2. The parser needs to detect comments, both C style (/* ... */) and C++ style (// ... \n) since these may be inserted into the code at any point. For example:
// [[QExport]]
double density(double T, // temperature in Celsius
double P, /* pressure in millibars */
double humidity // 0.01 = 1% humidity
);
3. Ideally the parser should not cause any artificial organisation of the code since this will have a detrimental effect on development at some point. QExported functions and methods could be declared anyway in the code-base, including deeply nested in header files.
Recursing into header files to locate declaration is a complex task. The easiest way to handle the situation is probably to invoke the C++ preprocessor. I.e. the original source file is preprocessed and the parser run over the output.
4. The parser needs to detect strings since they could contain tokens which should be ignored but could confuse the parser if it was unaware that inside a string.
5. The parser needs to know whether a function definition occurs inside a class definition. If it does, it becomes a method definition. The parser therefore needs to track { } pairs.
6. If an error occurs, the parser needs to know the line number and character position of the error. The tokeniser therefore needs to track line breaks and character position. Note that the location of the 'A' in the string "\tA" is 2 even though some editors may report that the characters is at position 3,5 or 9 depending how tabs are expanded.
The tokeniser is implemented in the project by the parser_base class.
Grammars
Grammars are used to describe acceptable streams of tokens and to trigger appropriate actions (e.g. the generation of code). Grammars are described by productions which specify how high-level grammar constructs are made up from other grammar fragments.
The project parser grammar (EBNF) is shown below:
Data types
type-decl = [ "const" ] [ undecorated-type | [ "class" ] class-type ] [ "*" | "&" ]
undecorated-type = boolean-type
| signed-type
| floating-type;
boolean-type = "bool";
signed-type = [ "unsigned" | "signed" ] ( "wchar_t" | "char" | integer-type );
integer-type = [ "short" | "long" [ "long" ] ] [ "int" ];
floating-type = "float" | "double";
Function declarations
export-decl = QExport-decl [ api-decl ] exported
QExport-decl = "///[[QExport]]" <== special token.
api-decl = export_tag | "__declspec" "(" "dllexport" ")" <== for the moment this is hard coded.
exported = class-decl | function-decl
function-decl = [ "static" ] type-decl declarator
declarator = name [ "::" method-name ] "(" [ parameter-decl ] { "," parameter-decl } ")"
parameter-decl = type-decl name
Class declaration
class-decl = "class" class-name [ ":" baseclass {[ "," baseclass]} ] class-body
class-body = "{" tokens "}"
main
code = export-decl | persist-decl | class-decl | token code
Grammars are generally of two types: LL(n) and LALR(n) - the 'n' indicates the number of 'look-ahead' tokens needed to parse the grammar.
LL Grammars
LL parsers start by identifying a high level production and then match successive tokens against the rule. It is a bit of a simplitication but basically our project parser looks out for one of two statement types:
-
class classname : baseclasses { -
//[[QExport]] Keyhole_API datatype classname :: methodname ( datatype1 param1, ... datatypen paramn)
Once the parser encounters the first token (class for production 1, //[[QExport]] for production 2), the parser knows the matching production and so knows what's coming next.
Our project grammar is a LL(1) grammar - the parser does not need to look more than 1 token ahead at any point, even when our 2 simplified high level productions above are broken down into smaller (sub-)productions. Furthermore the parser is an example of an LL(n) that does not need to backtrack (process more than one possibility and then abandon any that cannot be correct) and so is a Predictive Parser.
Parser implementations are often table based, but LL(n) parsers can also be implemented as a Recursive Descent Parser using "mutually recursive procedures usually implements one of the productions of the grammar. Thus the structure of the resulting program closely mirrors that of the grammar it recognizes"[1] which makes them amenable to hand coding.
Our parser is a hand-coded recursive descen parser.
LL(n) parsers cannot handle left recursion; the result of attempting to parse the following grammar would be infinite recursion.
number = number | number digit
The parser would check to see of the number production on the LHS matches the input by checking to see if it matches the first part of the production on the RHS - which means it would check to see if it is a Number, ...
Grammars can be left-factored to make them LL(n). For example the grammar
sum = number "+" number | number "-" number
cannot be parsed by a LL(1) grammar, while the following grammar can.
sum = number ( "+" | "-" ) number
LALR Grammars
LALR parsers process tokens and use a state machine to keep track of possible production matches. For example, consider parsing the character stream "1234.56" against the grammar below.
integer = [ sign ] { digit }
number = [ sign ] { digit } "." { digit } "E" digit [digit]
... other productions ...
For the first 4 digits the parser does not know which production can be applied to the stream. The parsing state is one in which the tokens processed so far could be an integer or number. Once the '.' is encountered the parsing state changes to one which expects a number.
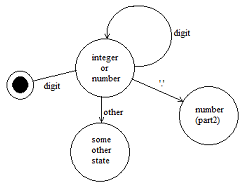
Unlike LL parsers, LALR parsers have no idea "what is coming next"; they build expressions from the "bottom up" rather than the "top down".
State machines are complex; LALR parsers are pretty much always table driven and generated by feeding a grammar into tools such as yacc.
Parser Actions
To be of any use, the parser needs to perform actions at specific points. In particular, completion of the following Productions triggers the specified actions (not a complete description).
{ -> increase the tracked indent level.
} -> increase the tracked indent level.
class-decl -> remember the indent level.
Used to determine whether a function is a class method or not.
function_decl -> create new function_info object; update return type
declarator -> update the function_info with the classname, function name and
parameter info.
type_decl -> create, update and return new dtype_info
parameter -> create, update and return new parameter_info
Implementation
Caveat: Our parser implementation is sub-optimal. For example, more sophisticated parsers typically assign numeric values to tokens which makes comparison fast and table driven logic easy. The project implementation uses few tokens and regularly does string comparisons. The purpose of this project was not to produce the most efficient or theoretically correct parser, rather it was to demonstrate their use in useful software development tools.
The XLL Generator
XLL are DLLs that make user-defined functions available in Excel as if they are provided by Excel itself.
XLL are usually written in C or C++. They provide a fast and efficient way to interface C/C++ code with Excel.
The auto-generation of XLL code highlights many of the issues that arise when there is a mis-match between the underlying library language (C++) and the client language (xls).
XLL Data Types
The table below shows the data types in the XLL. Note that a number of C++ data types have a dual purpose. EXCEL determines how to interpret parameters by looking at the function registration performed in the xlAutoOpen function.
| Data Type | Value | Pointer |
|---|---|---|
| char | null terminated string. | |
| unsigned char | byte counted string. | |
| short | used for numeric and boolean values | pointer to numeric values. |
| unsigned short | numeric value | used for null terminated and length counted strings. |
| long (int) | numeric value | pointer to numeric value. |
| double | numeric value | pointer to numeric value. |
| XLOPER12 | variant structure, used to manage memory. |
The already limited number of data types supported by the metadata compiler has been reduced further. For example, the is no float or distinct bool data type.
The generated XLL code can only use supported metadata types - that means it must map types not used by EXCEL to those that are. float is a mapped to double, and bool to short. All reference type types are mapped to the equivalent pointer types.
The EXCEL API extensively uses XLOPER12 data types. An XLOPER12 is like an EXCEL version of VARIANT, and used by the XLL to manage memory. The projects applies following rules to UDF (users-defined functions):
-
Input parameters are regarded as read-only since their ultimate origin is unknown.
-
It is OK to return data stored in static memory - EXCEL will not attempt to delete it, but the function will not be thread-safe.
-
If memory is allocated for a string or other dynamic structure, it must be deallocated after use. Functions return values in
XLOPER12structures allocated by the DLL; theXLOPER12has thexlbitDLLFreebit set. When EXCEL is finished with the data, it will call back into the XLL viaxlAutoFree12to notify the XLL that it should delete the data. -
If EXCEL returns a string or array value (in an XLOPER12), then memory is reclaimed by calling
Excel12(xlFree, 0, 1, &xloper12)
XLL Functions
The exported XLL functions closely resemble the functions exported from the wrapped library. Types need to be translated to those usable by EXCEL, return values are wrapped in XLOPER12(s) and memory management rules need to be respected, otherwise the generation of XLL functions is relatively straight forward. For example, the library function
float calculate_sphere_volume(float radius);
is wrapped with the XLL function
XLOPER12* xl_calculate_sphere_volume(double radius);
Dealing with objects
Large software project tend to deal with objects and not rely on functions alone. The object interface follows C/C++ - class methods are replaced by functions with the same signature as the method they replace, except for (i) translation to EXCEL data types, (ii) an additional leading parameter which takes an objectstr and (iii) an LPXLOPER12 return type. For example, the methods in the class below
class A
{
public:
static A* create() { return new A; }
double R;
void put_R(double _R) { R = _R; }
double calc_circumference() { return 2*M_PI*R; }
};
are implemented using in the XLL by the following functions.
__declspec(dllexport) LPXLOPER12 A__create() { ... }
__declspec(dllexport) LPXLOPER12 A__put_R(objectstr str, double R) { ... }
__declspec(dllexport) LPXLOPER12 A__calc_circumference(objectstr str) { ... }
Flow control
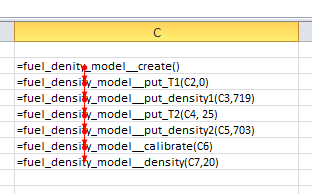
Traditional imperative languages execute instructions listed sequentially in a source file. For example, in the following C++ program execution begins at the top of the "compilation unit" and proceeds sequentially to the bottom.
fuel_density_model* calc = fuel_density_model::create();
calc->put_T1(0.0);
calc->put_denisty2(719.0);
calc->put_T1(25.0);
calc->put_denisty2(703.0);
calc->calibrate();
double density = calc->density(20.0); // 25 Celsius
delete calc;
density) returned a reference to the underlying object, the code can be then written as:
fuel_density_model* calc = fuel_density_model::create();
double denisty = (*calc).put_T1(0.0)
.put_denisty1(719.0)
.put_T1(25.0)
.put_denisty2(703.0)
.calibrate().
.density(20.0); // 20 Celsius
delete calc;
Implementation
What is the best way to implement the object methods?
Consider a simple report generation object shown in the figure below.
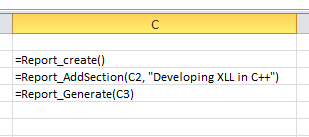
It is tempting to follow C++ and create a single instance of the report object under the covers; the Report_AddSection and Report_Generate would then update that instance. The problem is that each cell can be recalculated at any time. What would happen if Report_AddSection was recalculated multiple times?
The approach needs object methods to be idempotent. I.e. calling a method multiple times has the same effect as called it once. However it is not possible to demand that the wrapped library functions are idempotent. Worse still, any errors that happen as a result of multiple recalculation are likely to go un-noticed. It is for this reason that the approach is untenable.
Hidden Names
There is an alternative way using functional programming techniques. Once an object is created, it is never modified. Methods such as fuel_density_model__put_T1 create another copy of the original object with an updated T1 property. Since the starting point for any cell recalculation is always the same (the previous incarnation of the object), recalculation of a cell does not change its value.
Multiple copies of an object in different states obviously has a penalty in terms of memory usage.
How do we attach the object to a cell? A possible scheme is to store in-memory objects in a hash-table and store the hash-key as cell text. It is however more standard to programmatically name each cell containing an object and store the object in serialised form with the name as 'big data'; Names and big data are stored automatically when a workbook is saved, and loaded automatically when the workbook is openned. Names added by the C API are hidden and do not appear in (and polute) the normal Names dialog. Names also provide some protection against operation such as cut-n-paste.
Persistence
If a workbook is closed down and re-openned, the underlying object network needs to be recreated. I.e spreadsheet objects need to be persistent.
It is not the responsibility of the XLL code generator to provide persistence services to the wrapped library. The task is simply too intrusive and complex; persistence code frequently accesses private data members, and judgements must be made regarding how "deep" persistence should go. Persistence must be built-into the underlying library, as below.
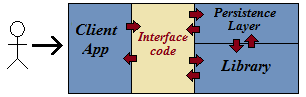
Saying that, the original XLL generator parser has been modified so it can be used to drive persistence code generation (naughty). The two parsers serve different purposes and really should be separated. The persistence code generator uses psuedo attributes like the XLL generator and is used by the 'CarbyCalcLib' project. Note that it only supports serialisation of value type (non-reference) data members.
The XLL support code expects that for any class A, the following persistence functions are available:
A* A__load(const unsigned char* buffer, size_t size);
persistence_provider_type* get_persistence_provider__A(A& obj);
The Project
The project code is organised into a number of directories and solutions.
-
The include, lib and bin directories contain header files, libraries and executables shared between the projects.
-
The CarbyCalcLib solution contains 3 subprojects.
- 'CarbyCalcLib' - A simple DLL used to calculate air density and other quantities used to tune carburettors.
- 'Simple_Persistence_Provider' - An executable simple persistence provider that generates serialisation code based on method attributes. The Simpler Persistence Provider provides serialisation code for CarbyCalcLib.
- 'Simple_Persistence_Test' - test code for the simple persistance provider.
-
The Metadata toolkit solution contains 2 subprojects.
- Metadata Compiler - the parser that generates the metadata by reading the library source code.
- The API Report creates a text-based metadata report and is used to confirm that the parseris generating a faithful representation of the object described in the input files.
- The 'XLL_Generator' generator solution contains 3 subprojects.
- The 'XLL_Generator' project - An executbale that generates XLL code to wrap a DLL based on attributes and class definitions defined in an input file. Uses the 'Metadata_toolkit' library.
- The 'XLL_support' project - Support functions called by the generated XLL code.
- The 'XLL_Generator_Test' - A simple test XLL to calculate circle circumferences.
-
The 'CarbyCalcLib_XLL' generator solution contains only 1 project. The 'CarbyCalcLib_XLL' project provides an XLL wrapper for the functions and objects exported from 'CarbyCalcLib.dll'. The project contains only 5 editable files:
- CarbCalcLib_XLL.h - a common header file.
- dllmain.cpp - which contains the standard XLL entry points.
- air_fuel_wrapper.cpp - which #includes the generated code.
- air_fuel_iface_defn.h, air_fuel_iface_defn.h - which are used as input to the XLL generated.
The reader is encouraged to browse the source files in the 'CarbyCalcLib_XLL' project to get a feeling for the amount of effort required to wrap a DLL.
The header files in the original 'CarbyCalcLib' project could have been used to drive the XLL generator. The files air_fuel_wrapper.h and air_fuel_wrapper.cpp contains only the class and method definitions required to drive the generator; indeed the 'CarbyCalcLib' header files does not even contain //[[QExport]] attributes; the 'CarbyCalcLib' library is totally "unaware" that it is wrapped.
Prerequisites
This project requires
- EXCEL XLL SDK (2007+).
- The hotfix described in KB 2459118.
The projects were developed using Visual Studio Community 2013 and EXCEL 2013 XLL SDK.
VC++ Directories
You will need to set the Include, Library and Executable VC++ directories for each project. The should include the shared include, lib and bin directories, as well as the relevant EXCEL SDK directories.
Points of Interest
The EXCEL SDK Framework
The project does not use the framework that comes with the 2007 EXCEL SDK as memory pool grabs memory and does not let go. It generates the following characteristic memory "leak" message. (Since it is by design, it is not really a leak).
Detected memory leaks!
Dumping objects ->
{88} normal block at 0x04D750E8, 10240 bytes long.
Data: < > CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD
{87} normal block at 0x04D728A8, 10240 bytes long.
Data: < > CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD
{86} normal block at 0x04D70068, 10240 bytes long.
Data: < > CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD CD
{85} normal block at 0x03FFC008, 10240 bytes long.
Data: < > 18 C0 FF 03 CD CD CD CD 02 00 CD CD CD CD CD CD
{84} normal block at 0x03FF2EC8, 52 bytes long.
Data: < x > 04 00 00 00 78 11 00 00 08 C0 FF 03 00 00 00 00
{83} normal block at 0x03FF2E80, 12 bytes long.
Data: < . > 01 00 00 00 04 00 00 00 CC 2E FF 03
Object dump complete.
Exporting C functions
Exported C functions are declared extern "C" and prefixed with macro Keyhole_API which expands to __declspec(dllexport). Reading the documentation, one would imagine that would be enough to ensure that an exported function had the same name as that declared in the source code. Not so. The function foo below is exported with the name _foo@8 (8 is the number of bytes on the stack used by the parameters). If you want the function foo to be exported with its own name, you need a .def file.
#define Keyhole_API __declspec(dllexport) extern "C" short foo(double x);
UTF8
I like to use Greek symbols in source code. I find that

is more readable than
Pressure = density*R*Temperature
Non-ASCII source code is allowed by the C++ standard and partially supported by compilers.
There are various ways to represent non-ASCII symbols, ranging from code-pages that use values from 128-255 to Unicode encodings such as UTF8, UCS-2, UTF16, UTF16BE, UTF16LE, UTF32. It appears that UTF8 is the most sensible choice and it usage is begining to out-strip that of its competitors (as of 2015).
The Code Generator has been engineered to process UTF8 source files containing ASCII and Greek characters, at the cost of some potential fragility. It will not accept any other non-ASCII characters. The reason for the compromise: As I said, I like Greek symbols and Unicode is a minefield.
The project code follows the recommendations from utf8everywhere.org.
I was unable to get the C++ preprocessor or linker to work with UTF8 using 2013 Community MSVC. That means Greek symbols can be used within the wrapped code but not in the names of exported functions, methods or classes.
Through the Keyhole
This article is not just about writing XLLs; there are many more examples of C++ meta-data driven tools. The author encountered an interesting example at a large investment bank many, many years ago. The tool generated a wrapper for the Quant (pricing) library which prevented direct access to the exported functions. There was only a single entry point into the library, similar to the VB's IDispatch::Invoke, and referred to as the keyhole.
Why do that? The functions and methods exported by the Quant library changed from release to release, in a relatively uncontrolled manner. (The bank was so big it would have been impossible to "control" library development) If application code linked directly to functions/methods in the Quant library, then there was a good chance that at some point an application would fail to link with a new release, causing a great deal of grief. The single entry point meant that the library always linked and the application could be built even if a small number of calls failed.
Please note that I am not necessarily recommending the approach. There were several issues with it: (i) problems with missing/changed functions/methods were not really solved by the approach, just minimised, (ii) the complexity of the code made debugging a nightmare, and (iii) there was significant performance degradation.
Caveat
None of the code in the project has undergone commercial levels of testing or review. Lots of features are missing, including:
- The code generators are not configurable. There are no configuration files and few command line options.
- The C++ preprocessor writes to disk. Significant speed improvements are possible by writing to a memory stream. The preprocessor logic has been disabled in the current code version by code to support preprocessing is present in the codebase.
- EXCEL does not make it easy to trap all the required events to fully support user-defined object methods. The XLL support code needs further work. If you cut-n-paste cells, jump between worksheets etc., you will no doubt confuse the support code and generate an error.
- There is no direct support for UDF functions that use vector and arrays.
- The support for non-ASCII characters is very limited. Full support for UTF8 probably would entail using a third party library.
- Error handling is rudimentry, as is warning generation.
- Additional "flow control" and functional programming constructs such as map/reduce are missing.
- An object viewer to display the content of cells would be welcome.
Please report major bugs to me rather than down-arrowing me. If there is enough interest in the XLL generator I shall move the latest code to a repository and possibly even write some proper documentation or an another article! If you wish to develop the code further, please feel free to do so or contact me.
Comment
The auto-generation of interface code is the method of choice for providing library code functionality across multiple languages and environment. The approach ensures that code is of a uniform quality and delivers enhanced productivity. None of that is possible without metadata driven code generators.
C++ lacks the reflection capabilities found in other languages. Even though parsers are interesting and powerful tools, I look forward to the day when C++ has standard and powerful metadata features built into the language so that for many tasks, parsers will be unnecessary.
References
1. Burge, W.H. (1975). Recursive Programming Techniques. ISBN 0-201-14450-6.