
Bringing Control Back to Database Deployment with ReadyRoll and Entity Framework Code First Migrations
0/5 (0 vote)
In this article, I’m going to show you how you can continue using EF Code First to model your database, while also using ReadyRoll to do the actual deployment of T-SQL change scripts and overcome the challenges of the Code First approach.
Introduction
Database change management is frequently seen as something that slows down deployment. That’s probably why Entity Framework (EF) has proven popular among many in the development community. It offers a straightforward workflow for modelling and deploying database changes when working locally. Migrations can also be authored through the Fluent API of Code First and written in C#, making for a more familiar change authoring experience than working directly against the database in T-SQL. Some difficulties can arise, however, when using the EF Code First migrations approach among a team and you want to branch or merge code, or coordinate schema changes that are more complex than the approach is able to support. There are workarounds for some of these limitations, but others cannot be solved, simply because it’s just the way Code First is. For example, there is no support for objects outside the Entity Framework model, such as database views or functions (these objects have to be deployed separately).
This is where I believe a tool that works with the native language of the platform, Transact-SQL can help. It’s part of the reason I originally developed ReadyRoll – to solve exactly the sorts of challenges developers face when they want to get a database change out on time, but also want to do it the right way rather than doing a ‘quick fix’.
In this article, I’m going to show you how you can continue using EF Code First to model your database, while also using ReadyRoll to do the actual deployment of T-SQL change scripts and overcome the challenges of the Code First approach.
Why do database migrations?
Let’s tackle the question of why use database migrations for change management first.
A bit of background - I worked for many years as a release engineer in the financial services industry, handling the deployment of all the company’s line of business applications. The most gruelling part of the release process was, without a doubt, the database part of the release. Database changes were coded by hand and the scripts deployed manually. Things sometimes went wrong at release time – scripts could be missed or deployed in the wrong order. Database comparison tools improved things because they eliminated the need to hand-code all the changes, but I still needed to do a lot of work behind the scenes to ensure the scripts ran in the correct order.
When I started using migrations frameworks, I suddenly had visibility and control over the precise changes we wanted to execute and in what order. We developed changes in individual T-SQL scripts, added them to source control and each script was given a pre-defined number that would mean it would be executed numerically in turn in the exact order we specified upfront. It’s this oversight of changes right from the start that is the reason many development teams like the migrations approach for database changes. There shouldn’t be any surprises at deployment time.
Why use ReadyRoll?
When I first started developing ReadyRoll as a migrations tool, I knew that the migrations approach was right for our team, but we experienced limitations with the frameworks out there. We couldn’t branch and merge changes in the way we wanted, and the Continuous Integration and automated deployment support within these tools was often severely lacking. We also continued to find ourselves spending a lot of time coding changes by hand, which was a bit daunting when faced with hundreds of databases to deploy changes to across our environments.
So I set about creating ReadyRoll as a migrations-driven hybrid tool for SQL Server database changes. The hybrid style of deployment means the usual migrations model approach applies (each change script is executed against a target database in a pre-defined numerical order), but ReadyRoll also includes a set of features that use the state-based approach to change management. These include the ability to generate T-SQL scripts with a database diff engine and track the history of individual database object changes.
From a hands-on development perspective, our team was very happy in Visual Studio, but there were also team members who preferred to code database changes in SQL Server Management Studio (SSMS) first. So I designed ReadyRoll to be an extension for Visual Studio with the flexibility to import changes from SSMS into Visual Studio whenever needed.
This database-first development workflow doesn’t suit everyone, however. If you find the code-first workflow to be a more natural fit, then ReadyRoll can offer you a workflow that takes the best parts of Entity Framework Code First migrations, and combines them with the flexibility of the migrations-hybrid approach.
Adapting an existing Entity Framework project to a T-SQL migrations-based one
To bring a T-SQL migrations-based approach with ReadyRoll to an existing Entity Framework project, let’s look at a quick example. We’ll use Microsoft’s own sample project for Entity Framework Code First (Contoso University), as shown below in Fig 1:

There’s a series of steps to go through in order to create an empty ReadyRoll database project and then point our new project to the same database as the Entity Framework-enabled project. You can see these steps in detail in the online documentation.
Once these steps are completed, we need to create the baseline for the project, which is a script generated from the current state of the schema model and which sets the starting point for all future migrations. This means the baseline should ultimately reflect the state of the schema model in our Production environment.
We create the baseline script by opening the Package Manager Console window and executing the following:
Update-Database -Script -Source $InitialDatabase
This means Entity Framework generates the T-SQL for all existing migrations. The script is also automatically added to the new ReadyRoll database project. The $InitialDatabase argument causes Entity Framework to generate a script that should be runnable on all target environments, regardless of whether a new database is being created (as in this case), or if a subset or even all migrations have already been deployed to an upstream environment such as Test or Production.
Now that we have the script in the ReadyRoll database project, we can execute it against our local SQL Server instance. The baseline script has been created.
We can now set up ReadyRoll to control the database deployments. This means enabling Automatic Migrations (AutomaticMigrationsEnabled=true), as seen in Fig 2. We’ll still generate the migrations, but they’ll be in the T-SQL format rather than in Fluent (C# migration class) format.

(Note that you can also set AutomaticMigrationsEnabled=false if you would prefer to use the Fluent API to author your changes but use T-SQL to deploy to your Test and Production environments.)
Making a database model change – how to go Up
When you want to make a database model change, you don’t actually have to forego any of the smarts that Code First offers in order to make T-SQL your deployment language of choice. You can author your change as normal and then execute the below command to generate a new T-SQL change script:
Update-Database -Script
This script, unlike the previous script when we were creating a baseline, assumes a certain state is already present in the target database. This means the script will only contain the most recent change made to the model. You can see an example of a change (modifying the length of the LastName and FirstName properties to 255) in detail in the online documentation. The below image in Fig 3, taken from the example, shows a change script generated by ReadyRoll:

At this point, we can choose whether to make further edits to the migration logic in the script before deployment. This case of a change to length of properties is straightforward, so we can deploy the change script as it is without more work needed.
Other changes need careful consideration to prevent loss of data, however. If we’re merging columns (e.g. if FirstName and LastName were merged into one column called Fullname), for example, Entity Framework would script it as a CREATE COLUMN / DROP COLUMN set of statements. To prevent our data being lost with the column drop, we need to edit the migration script to create the new column, then merge and copy the data to the new columns before dropping the original columns.

The editing of the generated script might take some time, but it’s better to do this with more control, than risk unknowingly dropping a column and all the data in it. The great thing about working directly with T-SQL, rather than through a layer of abstraction, is that we can include all the logic to perform the data motion right alongside the generated code. This code will be validated by the T-SQL parser at build time, prior to deploying it to the database. All the statements will be executed in a transaction together, ensuring that the entire deployment is atomic.
We can also bring further control to our deployment process by choosing whether we want to pass those changes through a verification stage. This means executing our T-SQL change script against a shadow database that ReadyRoll maintains (created automatically from your project scripts). The sorts of errors the verification stage can pick up include missing dependencies (such as a user that does not have a related login), invalid code in legacy objects and syntax errors. If the script fails at the verification stage, ReadyRoll gives us the error details and the option to fix the script.
After deployment, we can also use ReadyRoll’s DBSync tool to check that the deployment went as intended. Fig 5 below gives an example of the original/sandbox and target database both in sync after the Person object in the database was changed to increase the length of the LastName and FirstName properties:

Since the ReadyRoll project (displayed on the left) and the sandbox database (displayed on the right) are in sync with the change we intended to make, we know that the deployment was successful.
Reverting a model change – how to go Down
If, after deploying a change to the database model, we decide we want to undo that migration, we can use ReadyRoll to revert that specific change without having to redeploy the database from scratch (thus preserving the data within our database).
If we first delete the migration we want to revert from the project, we can then use ReadyRoll’s DBSync tool to re-synchronize the database to the revised project model. This is done by clicking the Refresh button within the tool-window, which will display the object differences between the project and the sandbox database. We can also see the individual object differences in a side-by-side view, with the project model version on the left and the sandbox database version on the right. Fig 6 below shows an example.

We can select the object we want to revert and discard the change. This brings the sandbox database into sync with the project sources, by generating a one-time script and applying it to your sandbox database. To do this, ReadyRoll uses its DBSync tool (built with the engine from the industry-leading schema comparison tool, Redgate SQL Compare) and saves you from having to write all the SQL code yourself.
The final step is to ensure that Entity Framework remains in sync with our connected database. This can also be done with ReadyRoll’s DBSync tool by tracking the data within the __MigrationHistory table, including table data and reverting the selected objects, as shown in Fig 7 below.

Further database change management techniques
This article has so far covered how you can use ReadyRoll with Entity Framework for setting a baseline and migrating changes up or down. There is more you can do with ReadyRoll to support your database change management processes, including:
How to gain an overview of your database assets
ReadyRoll provides an option for us to include an Offline Schema Model within the project assets, which means we get a read-only view of our database changes at the object level. This is one of ReadyRoll’s hybrid features provided through the use of the DBSync tool, and borrowed from the state-based model for making database changes. The Offline Schema Model lets us audit changes to the tables, schemas, users and types in our database within the project itself. This makes it possible to track changes to those objects over time, e.g. using the source control Annotate command. Whenever we import changes from our sandbox database, the DBSync tool updates the offline model in line with the schema changes being imported. It’s useful for auditing and also for assessing the higher level structure of our database before developing further changes.
Fig 8 below shows how the offline model stores database objects by type in sub-folders, using their fully qualified names, such as dbo\Tables\Person.sql

How to save time when working with code-based objects
If we’re making changes to code-based objects, such as stored procedures, triggers or views, on a regular basis, ReadyRoll’s Programmable Objects saves us time. By extracting all the supported objects from our schema into idempotent script files (e.g. dbo\Stored Procedures\Department_Update.sql), we can re-use the scripts by simply editing the existing files. This means we can deploy the same object more than once without having to add a numeric migration script each time. Not only it is easier to source control each of our database objects as individual files, but we can also more simply branch, merge and annotate them, which is handy when working in teams with developers making concurrent changes to those objects at any one time.
Fig 9 below shows ReadyRoll’s Programmable Objects structure, with a script for each of the objects accessible:
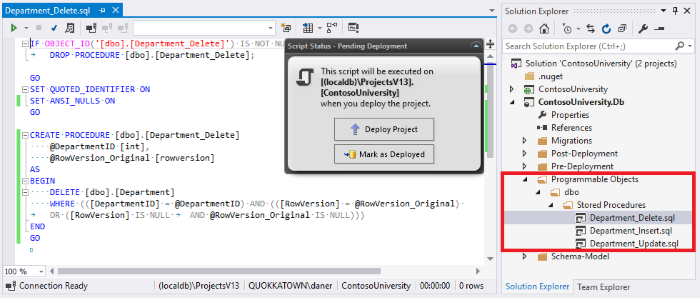
How to navigate your project as it grows
Many of us work in environments where databases fill up over time with hundreds, maybe even thousands of scripts from different releases. For those who are considering migrations as an approach to database change management, the thought of this growing pile of scripts can sometimes feel daunting. Semantic versioning in ReadyRoll makes it easier to manage this scenario and plan releases.
It separates our migrations into discrete subfolders with a semantic version number, so that we can put our migrations into logical groups. If we, for example, branch by release, semantic versioning means that each release branch is given a unique reference number. We can use this unique reference number as part of the version number (e.g. 1.2.0-RL125) to look up the release in source control. If we create a new semver folder every time we branch out a new release of our code, we also reduce the potential for collisions to occur in our database deployments. This is because semantic versioning ensures that the numbering resets with a new branch or when multiple concurrent branches are merged into one. If the numbering of the releases were allowed to continue between branches and merges without any semantic versioning in place, the deployment order of scripts against the target database would potentially be inconsistent with the order of scripts in source control. This could result in unforeseen deployment problems or, worst case scenario, data loss.
How to correct database drift
The migrations-based model for making database changes introduces, by its very nature, both control and oversight of database changes right from the point of development. Individual changes are captured in multiple small scripts as they are developed and added to source control. These migration scripts are then applied in a pre-defined sequence. Teams need to be aware, however, that a migration is only valid for the versions of the database it was written for.
Before deploying any database migration, we should check that the source and target databases are at the versions expected for the migration. If a ‘hotfix’ or ‘out of process’ change has been made on the target database, causing the target database version to ‘drift’, the migration script may have unintended consequences on the target database. It could, for example, quietly and unintentionally undo the changes that had been made to fix a serious problem on the server.
As a result, it’s an important risk mitigation technique to check for database drift before deployment. One way to do this is to perform a schema comparison to check that the target database matches the known state. Some developers use Event Notifications and SQL Trace, among other techniques. There are also tools available that are specifically designed to alert teams as drift occurs, such as DLM Dashboard (a free tool from Redgate).
ReadyRoll can help you manage schema drift too as part of a Continuous Integration process by using its DBSync tool at build time to perform a schema comparison between the source and target database. This process generates a drift report and a drift correction script. The report details the objects that have drifted from the source control baseline. The script, if executed, resynchronizes the target database with source control and undoes the changes made directly to the target database. A setting can be implemented to ensure we get a chance to review the correction script before it is deployed. It’s a manual step, but an important one in the scenario where drift is detected. Of course, if teams are rigorous in following the same development and deployment process and check their changes into source control, drift is less likely to occur - but even the most disciplined teams are still vulnerable to unexpected events.
Summary
I developed ReadyRoll based on real-world experience of the pains of manual database deployments. It can’t remove that natural pause for breath that we all have when hitting the release button, but it does make that experience much less fraught.
It gives you control of the changes right from the start in development, support for more complex data changes and the ability to test changes before deployment.
It also makes working with T-SQL a better experience for developers who are happier in application code. As one of our customers, Damian Haynes, Senior .NET developer at FlexiGroup, told us – it’s with ReadyRoll that “All developers become T-SQL script authors once you show them how easy it is to import table changes and even look-up data.”
I’ve included the completed projects detailed in this article in a zipped folder – ContosoUniversity.PlusReadyRoll.zip. It contains the ASP.NET/Entity Framework project and the ReadyRoll database project. To use both projects together, you’ll need to download ReadyRoll. A free 28-day trial is available on the Redgate website.