
Implementing Joins in Hadoop Map-Reduce
5.00/5 (8 votes)
How to implement Joins in Hadoop Map-Reduce applications during Reduce and Map phases
Introduction
Joining two datasets in HADOOP can be implemented using two techniques:
- Joining during the
Mapphase - Joining during the
Reducephase
In this article, I will demonstrate both techniques, starting from joining during the Reduce phase of Map-Reduce application. This technique is recommended when both datasets are large.
Then, I will incorporate another join in the example query and implement during the Map phase. So let’s begin.
Downloading the Dataset
The dataset I will use to demonstrate Join is the popular Adventure Works dataset by Microsoft. For this article, I will use a .csv version of Adventure Works Dataset, which can be downloaded from here.
For this example, download the Adventure Works 2012 OLTP Script, which contains a script to load the .csv files into an SQL Server Database, and of course, the .csv files that will be used in this example. The three files used in this example are:
- SalesOrderDetails.csv
- Products.csv
- ProductSubCategory.csv
The files contain tab-separated data, and do not contain a header row, therefore this reference can be used to look at what data each column contains.
Joining during Reduce-Phase
The best way to explain the objective of the join is to explain it using SQL. Referring to the dataset, the objective here is to join SalesOrderDetail data with Product data, and to get total quantity of each product sold, and the total amount for each product (sum of LineTotal). The equivalent SQL Query is:
select P.ProductID, P.Name, P.ProductNumber, Sum(S.OrderQty), Sum(S.LineTotal)
from SalesOrderDetails S join Products P
on S.ProductID = P.ProductID
where S.OrderQty > 0
So let’s see how this query is implemented in Map-Reduce.
Initial Setting-up of the Project
I am using Eclipse with Maven plugin for this example. Maven does away with the need to include dependencies manually, and makes the process easier and quicker. How to install Maven plugin in Eclipse is beyond the scope of this article, but it is easy and a quick Google search should be enough to point you in the right direction.
So begin a new Maven project, and let’s call it HadoopJoinExample.

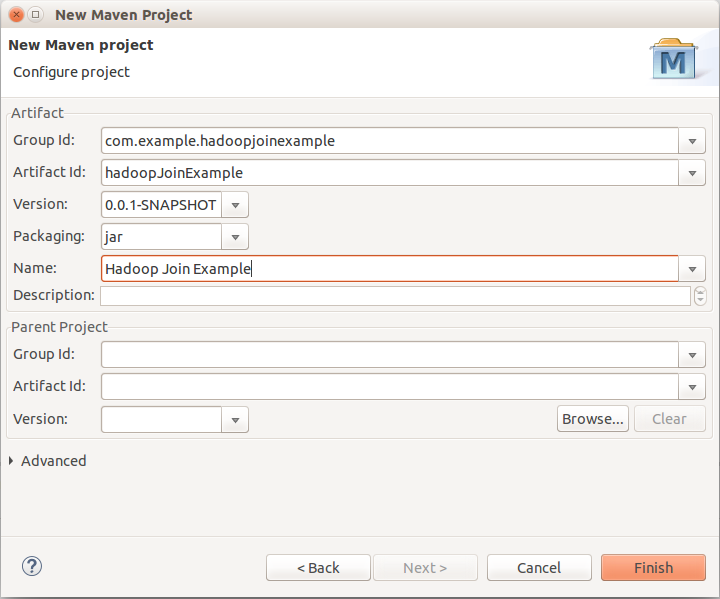
Make sure to select Simple Project checkbox. Next, include Hadoop 2.5.1 dependencies in the project using Maven. Open the pom.xml file, and in dependencies, add new dependency:

Add the following in the fields:
Grpup Id: org.apache.hadoop
Artifact Id: hadoop-client
Version: 2.5.1

Next, right click the project, and select Run As → Maven Install. It includes the dependencies, and shows the success message. The added dependencies can be viewed in the project explorer in Maven Dependencies:

Implementing Mapper Key Class
The Mapper key class will have two fields: ProductId and RecordType (indicating whether the record is coming from Products or Sales Order data. This example uses two mappers, one for Products data and other for Sales Order data.
The class is called ProductIdKey, and it implements WritableComparable<ProductIdKey>, which allows it to be serialized and deserialized, and also, to compare it with other records. This comparison is important later when it comes to sorting and grouping the records.
In addition to this, ProductIdKey has another method hashCode that returns the hash code which will be used by the partitioner. I will explain all of this along the way, so, create a new class called ProductIdKey, implementing the WritableComparable<ProductIdKey> interface.
The WritableComparable<T> interface requires to implement the following methods from the Writable interface which it extends:
public void write(DataOutput out)
public void readFields(DataInput in)
These write and readFields methods come from the Writable interface, which the WritableComparable<T> interface extends from, and they allow the data to be serialized and deserialized. This is required since data is sent over the network from Mapper to Reducer nodes, therefore, the Mapper key and value classes must be serializable, and implementing WritableComparable<T> for the key class is an easy way of achieving this (there are alternatives such as using the RawComparator, but they are not part of this article). The Mapper value class only needs to implement Writable since sorting and grouping is done only on the key class, and hence comparable part is not needed on the value (or data) classes. Most of the important key classes provided by default in Hadoop, such as IntWritable, Text implement WritableComparable<T>.
The write method writes all the attributes to Java's java.io.DataOutput stream. And the read methods reads it from the java.io.DataInput stream. The reading of fields has to happen in the same order the fields were written in.
Next is the Comparable<T> interface, which the WritableComparable<T> extends, and this interface provides the method:
public int compareTo(ProductIdKey other)
Which returns an integer based on its comparison. This comparison is used by Comparators (sorting comparator used to sort the key/value pairs sent by the mapper, and the grouping comparator which groups them) to sort and group the data when sending it to the reducer nodes.
So, as explained earlier, our ProductIdKey class has two fields, ProductId and RecordType (0 = Product record, and 1 = Sales Order data record). Declare them as:
public IntWritable productId = new IntWritable();
public IntWritable recordType = new IntWritable();
And for our convenience, we shall provide a constructor to initialize them both, and a default no parameters constructor that is required by Hadoop:
public ProductIdKey(){}
public ProductIdKey(int productId, IntWritable recordType) {
this.productId.set(productId);
this.recordType = recordType;
}
Next comes the Writable part of the WritableComparable interface, and the fields are written and read like:
public void write(DataOutput out) throws IOException {
this.productId.write(out);
this.recordType.write(out);
}
public void readFields(DataInput in) throws IOException {
this.productId.readFields(in);
this.recordType.readFields(in);
}
Next, the Comparable interface method:
public int compareTo(ProductIdKey other) {
if (this.productId.equals(other.productId )) {
return this.recordType.compareTo(other.recordType);
} else {
return this.productId.compareTo(other.productId);
}
}
This is important concept, because the sorting comparator and the grouping comparator, both if not provided externally, their default implementation will call this method. The grouping comparator groups keys, and sends each key (and all its values wrapped in Iterable<T>) to a single reduce call of the reducer, whereas the sorting comparator determines the order in which the keys are sorted.
Our objective is to catch the output of the two mappers (one for the Product data and other for the Sales Order data) and send each Product Id to the same reduce call, ignoring whether the record is coming from Product or Sales Order data (i.e. ignoring the RecordType field), and sorting has been implemented in this example in a way that the Product record will come before the data records, so the default compareTo can be used, and there is no need to use a custom sorting comparator, because the default method calls it, but for explaining, I will provide custom sorting and grouping comparators.
Next, we need the equals method and hashCode method. The hashCode method will be used by the partitioner to determine which record will be sent to which reducer. In this case, we want all the records with the same ProductId to arrive at the same reducer, therefore, the hashCode method will use only ProductId field of the key to generate hash, which is facilitated by the fact that IntWritable already provides it, so only a call to it will suffice:
public boolean equals (ProductIdKey other) {
return this.productId.equals(other.productId) && this.recordType.equals(other.recordType );
}
public int hashCode() {
return this.productId.hashCode();
}
Finally, the two constants:
public static final IntWeriable PRODUCT_RECORD = new IntWritable(0);
public static final IntWritable DATA_RECORD = new IntWritable(1);
And the Mapping key class is complete. This will be emitted by both Mappers. The next step is to define the Data classes.
SalesOrderDataRecord and ProductRecord Classes
As stated earlier, the data classes only need to implement Writable to allow serialization and deserialization.
SalesOrderDataRecord will be emitted by the mapper that processes the Sales Order data, and it will contain the quantity, in a field called orderQty, and line total in a field called lineTotal. The class becomes:
public class SalesOrderDataRecord implements Writable {
public IntWritable orderQty = new IntWritable();
public DoubleWritable lineTotal = new DoubleWritable();
public SalesOrderDataRecord(){}
public SalesOrderDataRecord(int orderQty, double lineTotal) {
this.orderQty.set(orderQty);
this.lineTotal.set(lineTotal);
}
public void write(DataOutput out) throws IOException {
this.orderQty.write(out);
this.lineTotal.write(out);
}
public void readFields(DataInput in) throws IOException {
this.orderQty.readFields(in);
this.lineTotal.readFields(in);
}
}
And the ProductRecord class, as clear from the SQL statement in the beginning, should be:
public class ProductRecord implements Writable {
public Text productName = new Text();
public Text productNumber = new Text();
public ProductRecord(){}
public ProductRecord(String productName, String productNumber){
this.productName.set(productName);
this.productNumber.set(productNumber);
}
public void write(DataOutput out) throws IOException {
this.productName.write(out);
this.productNumber.write(out);
}
public void readFields(DataInput in) throws IOException {
this.productName.readFields(in);
this.productNumber.readFields(in);
}
}
Extending GenericWritable Class
Since both mappers emit different classes, the reducer needs a generic type, and the obvious choice is Writable, which both classes implement, but as it turns out, Hadoop reducer needs exact type, and we need to specify that while setting up the job as well, using the setMapOutputValue method. Otherwise upon running the job, there are errors like “Expected Writable, getting SalesOrderDataRecord”. Hadoop provides GenericWritable class that can wrap the classes emitted by multiple mappers, and this can be used to get and set Writable instance like we require.
Please refer to this document for details regarding GenericWritable.
GenericWritable is used by extending it and overriding getTypes method that tells which types will be wrapped. All the types specified here must implement Writable.
The code is as follows:
public class JoinGenericWritable extends GenericWritable {
private static Class<? extends Writable>[] CLASSES = null;
static {
CLASSES = (Class<? extends Writable>[]) new Class[] {
SalesOrderDataRecord.class,
ProductRecord.class
};
}
public JoinGenericWritable() {}
public JoinGenericWritable(Writable instance) {
set(instance);
}
@Override
protected Class<? extends Writable>[] getTypes() {
return CLASSES;
}
}
Partitioner
For the purpose of this example, we need all the records having same ProductId to go to the same Reducer, so that total can be calculated. Partitoner class's getPartition function is called on each key/value pair of Mapper's output, and is sent to the Reducer accordingly. The default partitioner is called if no partitioner is specified, like in this case. Since we have defined the getHashCode function in a way that it returns keys based only on productId field of our key class, the default partitioner serves our purpose and there is no need to define a custom partitioner.
The default org.apache.hadoop.mapreduce.lib.partition.hashPartitioner has the following implementation of getPartition function:
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
The logical & with the hashCode is to prevent negative value to be returned if -2147483648 is returned by key.getHashCode function.
Driver
Create a new class, I will call it Driver, which will contain the main function, as well as the Comparators, and Mapper and Reducer as inner classes.
Grouping and Sorting Comparators
As stated earlier, the Grouping comparator compares the keys, and groups similar keys into a single reduce call, and in this case, the requirement is to send all the records having same value of productId in ProductIdKey class, regardless of the recordType value, to be sent to the same reduce call, so the ProductRecord containing Product Name and Product Number, can be combined (or Joined in SQL terminology) with the instances of SalesOrderDataRecord having same productId in key. The grouping comparator called JoinGroupingComparator can be defined as:
public static class JoinGroupingComparator extends WritableComparator {
public JoinGroupingComparator() {
super (ProductIdKey.class, true);
}
@Override
public int compare (WritableComparable a, WritableComparable b){
ProductIdKey first = (ProductIdKey) a;
ProductIdKey second = (ProductIdKey) b;
return first.productId.compareTo(second.productId);
}
}
The compare method of the WritableComparator uses only the productId, ensuring that the records having same productId will be sent to the same reduce call.
The sorting comparator is defined as:
public static class JoinSortingComparator extends WritableComparator {
public JoinSortingComparator()
{
super (ProductIdKey.class, true);
}
@Override
public int compare (WritableComparable a, WritableComparable b){
ProductIdKey first = (ProductIdKey) a;
ProductIdKey second = (ProductIdKey) b;
return first.compareTo(second);
}
}
This sorts the records making sure that the first record is the Product record, and then all the data comes.
Here, it is important to understand an important assumption that the ProductId is unique for each product, like primary key in an RDBMS table, so there will be only one Product record associated with the data records containing a particular product. So, in each call of the reducer following the sorting and grouping done by the sorting and grouping comparators we have just defined, the data passed will contain one Product record and zero or more Sales Order data records.
This could also be implemented in other ways, such as by eliminating the recordType field from the ProductIdKey class altogether, and using the default sorting and grouping comparators which would have sent all the records of the same key to the same reduce call, since there is no recordType field in the key and therefore the key of a particular Product and that of the Sales Order data records having that key (same ProductId) is the same. In the reducer, we could get the Writable from the JoinGenericWritable objects, and use type identification to identify a product record among the data records. I chose it to do this way since it covers the concepts of Sorting Comparators and Grouping Comparators.
Now, the next step is creating the Mapper and the Reducer.
Mappers
There are two mappers required for this function. One will process the SalesOrderData.csv file and emit ProductIdKey, and SalesOrderDataRecord instances, and the other will process the Products.csv file, and emit ProductIdKey, and ProductRecord instances. Both mappers are simple, and create a key class and value class instance for each record. The best way to explain them is to show the code:
public static class SalesOrderDataMapper extends Mapper<LongWritable,
Text, ProductIdKey, JoinGenericWritable>{
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] recordFields = value.toString().split("\\t");
int productId = Integer.parseInt(recordFields[4]);
int orderQty = Integer.parseInt(recordFields[3]);
double lineTotal = Double.parseDouble(recordFields[8]);
ProductIdKey recordKey = new ProductIdKey(productId, ProductIdKey.DATA_RECORD);
SalesOrderDataRecord record = new SalesOrderDataRecord(orderQty, lineTotal);
JoinGenericWritable genericRecord = new JoinGenericWritable(record);
context.write(recordKey, genericRecord);
}
}
public static class ProductMapper extends Mapper<LongWritable,
Text, ProductIdKey, JoinGenericWritable>{
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] recordFields = value.toString().split("\\t");
int productId = Integer.parseInt(recordFields[0]);
String productName = recordFields[1];
String productNumber = recordFields[2];
ProductIdKey recordKey = new ProductIdKey(productId, ProductIdKey.PRODUCT_RECORD);
ProductRecord record = new ProductRecord(productName, productNumber);
JoinGenericWritable genericRecord = new JoinGenericWritable(record);
context.write(recordKey, genericRecord);
}
}
As can be seen, both mappers split each record of the csv file by tab, and pick the required columns, and write them to context.
The input key class of both Mappers is LongWritable, and their input value class is Text. This is because we will specify the org.apache.hadoop.mapreduce.lib.input.TextInputFormat class as the job's input format class, which reads the file line by line, and sends line numbers as keys, and the lines themselves as values to the mapper class.
Reducer
Next, let's look at the reducer, that looks at the recordType field in the key to determine which value (instances of Writable wrapped in JoinGenericWritable objects) passed to it is the ProductRecord and which are the type SalesOrderDataRecord. It then writes the Product Id, Product Name and Product Number (the fields picked by the ProductMapper during map phase) and to the context along with the summed values of orderQty and lineTotal.
The code is as follows:
public static class JoinRecuder extends Reducer<ProductIdKey,
JoinGenericWritable, NullWritable, Text>{
public void reduce(ProductIdKey key, Iterable<JoinGenericWritable> values,
Context context) throws IOException, InterruptedException{
StringBuilder output = new StringBuilder();
int sumOrderQty = 0;
double sumLineTotal = 0.0;
for (JoinGenericWritable v : values) {
Writable record = v.get();
if (key.recordType.equals(ProductIdKey.PRODUCT_RECORD)){
ProductRecord pRecord = (ProductRecord)record;
output.append(Integer.parseInt(key.productId.toString())).append(", ");
output.append(pRecord.productName.toString()).append(", ");
output.append(pRecord.productNumber.toString()).append(", ");
} else {
SalesOrderDataRecord record2 = (SalesOrderDataRecord)record;
sumOrderQty += Integer.parseInt(record2.orderQty.toString());
sumLineTotal += Double.parseDouble(record2.lineTotal.toString());
}
}
if (sumOrderQty > 0) {
context.write(NullWritable.get(), new Text(output.toString() +
sumOrderQty + ", " + sumLineTotal));
}
}
}
Final Steps
The final step is to make the Driver class extend org.apache.hadoop.conf.Configured, which allows the Driver class to be configured using a org.apache.hadoop.conf.Configuration object, and implement the org.apache.hadoop.util.Tool interface that “supports handling of generic command-line options” according to its description.
Tool interface has a run method, which will be like so:
public int run(String[] allArgs) throws Exception {
String[] args = new GenericOptionsParser(getConf(), allArgs).getRemainingArgs();
Job job = Job.getInstance(getConf());
job.setJarByClass(Driver.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapOutputKeyClass(ProductIdKey.class);
job.setMapOutputValueClass(JoinGenericWritable.class);
MultipleInputs.addInputPath(job, new Path(args[0]),
TextInputFormat.class, SalesOrderDataMapper.class);
MultipleInputs.addInputPath(job, new Path(args[1]),
TextInputFormat.class, ProductMapper.class);
job.setReducerClass(JoinRecuder.class);
job.setSortComparatorClass(JoinSortingComparator.class);
job.setGroupingComparatorClass(JoinGroupingComparator.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(allArgs[2]));
boolean status = job.waitForCompletion(true);
if (status) {
return 0;
} else {
return 1;
}
}
As it can be seen, it used the getConf method of Configuration base class, and passes the Configuration to get an instance of org.apache.hadoop.mapreduce.Job, which is the Job we will set-up and run.
Finally, the main class, which initializes the Configuration object, and runs the job by calling ToolRunner.run method:
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
int res = ToolRunner.run(new Driver(), args);
}
Running the Job
The job can either be run in Eclipse in Local Mode, or can be deployed to a cluster. Local Mode allows to quickly test the job on a limited set of data.
Build the application to make sure there is no error. Then right click the project in Project Explorer, and select Run As → Run Configurations. Right click Java Application, and select New. Name the configuration “Java Run Config” in the main tab. The project should already be selected. Under the main class heading, click the search button, and select “hadoopJoinExample.Driver” from the list. This tells the main class of the program. Next, click the Arguments tab, and in the Program Arguments, we need to pass the two files (SalesOrderDetails.csv and Products.csv) and the output folder. It is clear from the way the run method has been written that first path is that of SalesOrderData.csv file, and the second is path is of Products.csv file. In my system, the string looks like:
/home/hduser/Desktop/sales_data/SalesOrderDetail.csv /home/hduser/Desktop/sales_data/Product.csv /home/hduser/Desktop/sales_data/output/output3
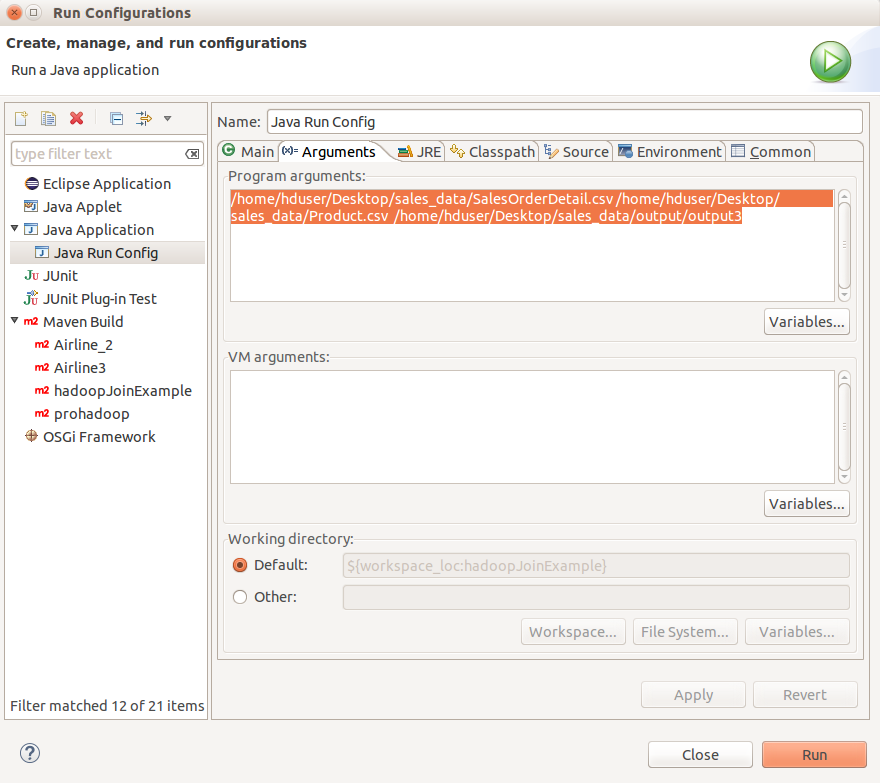
Click Apply, and then click Run. The job should run and the output path should contain the output once it has completed running. A snapshot of it is:

Open the part-r-00000 file with gedit and you should be able to see the results like so:

See that along with the total of each Product, its details that we joined from the Products.csv file are also present.
At this stage, only running the job in Local Mode to see everything is working fine should be enough, at the end, I will show you how to deploy it to the cluster.
Join during Map Phase
Now, let’s move on to Joining during the Map phase. This is recommended when the data to join with is small. Joining during the map phase allows to join quickly when one set is small, and also allows to join on separate keys with multiple sets, or with single set repeatedly (for example, in warehouse to warehouse transfer of products data, the "from warehouse" and "to warehouse" can be mapped), this is something which cannot be done in a single job if Reduce-phase joins are used.
So for this example, let’s imagine we need more information about the Product, Product Sub Category for example, then the equivalent SQL Statement should be like:
select P.ProductID, P.Name, P.ProductNumber, C.Name, Sum(S.OrderQty), Sum(S.LineTotal)
from SalesOrderDetails S
join Products P on S.ProductID = P.ProductID
join ProductSubCategory C on P.ProductSubcategoryId = C.ProductSubcategoryId
where S.OrderQty > 0
The Product Sub Categories are present in the file ProductSubCategory.csv.
In this approach, I will demonstrate the use of cache files which can be used by Hadoop Map-Reduce applications. They are copied to each node at the beginning of the job, and can be retrieved in the setup method. The cache files can be present in the local file system or Hadoop's HDFS. In this example however, I will demonstrate the use of cache file present in the local file system (and use Java.io.File), and in the end, briefly explain the way to read the cache file present in HDFS.
In this example, the ProductSubCategories.csv file is passed to the ProductMapper class, which is read in the setup(Context) method, which is called in the beginning of each Mapper task. Each ProductSubCategoryId is stored in a java.util.HashMap<Integer, String> instance.
Then in the map method of the mapper, we will read the productCategoryId field of each product (it is a nullable field in Adventure Works database) and based on that get the name of the Sub Category and store it in the ProductRecord instance. The first step is to add the ProductSubCategoryName to the ProductRecord class.
The modified ProductRecord class is:
public class ProductRecord implements Writable {
public Text productName = new Text();
public Text productNumber = new Text();
public Text productSubcategoryName = new Text();
public ProductRecord(){}
public ProductRecord(String productName, String productNumber,
String productSubcategoryName){
this.productName.set(productName);
this.productNumber.set(productNumber);
this.productSubcategoryName.set(productSubcategoryName);
}
public void write(DataOutput out) throws IOException {
this.productName.write(out);
this.productNumber.write(out);
this.productSubcategoryName.write(out);
}
public void readFields(DataInput in) throws IOException {
this.productName.readFields(in);
this.productNumber.readFields(in);
this.productSubcategoryName.readFields(in);
}
}
The updated ProductMapper is:
public static class ProductMapper extends Mapper
<LongWritable, Text, ProductIdKey, JoinGenericWritable> {
private HashMap<Integer, String> productSubCategories = new HashMap<Integer, String>();
private void readProductSubcategoriesFile(URI uri) throws IOException{
List<String> lines = FileUtils.readLines(new File(uri));
for (String line : lines) {
String[] recordFields = line.split("\\t");
int key = Integer.parseInt(recordFields[0]);
String productSubcategoryName = recordFields[2];
productSubCategories.put(key, productSubcategoryName);
}
}
public void setup(Context context) throws IOException{
URI[] uris = context.getCacheFiles();
readProductSubcategoriesFile(uris[0]);
}
public void map(LongWritable key, Text value, Context context) throws IOException,
InterruptedException{
String[] recordFields = value.toString().split("\\t");
int productId = Integer.parseInt(recordFields[0]);
int productSubcategoryId = recordFields[18].length() > 0 ?
Integer.parseInt(recordFields[18]) : 0;
String productName = recordFields[1];
String productNumber = recordFields[2];
String productSubcategoryName = productSubcategoryId > 0 ?
productSubCategories.get(productSubcategoryId) : "";
ProductIdKey recordKey = new ProductIdKey(productId, ProductIdKey.PRODUCT_RECORD);
ProductRecord record = new ProductRecord
(productName, productNumber, productSubcategoryName);
JoinGenericWritable genericRecord = new JoinGenericWritable(record);
context.write(recordKey, genericRecord);
}
}
Here, in the setup method, we read the file line by line and populate the HashMap. The cache file URI is read in the run method from the arguments, and the cache file for the job is set. Add the following lines in the run method:
job.addCacheFile(new File(args[2]).toURI());
Here, we assume that the third file passed to the job from the command line is the cache file containing ProductSubCategories. Finally, we update the JoinReducer class accordingly, the updated code is:
public static class JoinRecuder extends Reducer
<ProductIdKey, JoinGenericWritable, NullWritable, Text>{
public void reduce(ProductIdKey key, Iterable<JoinGenericWritable> values,
Context context) throws IOException, InterruptedException{
StringBuilder output = new StringBuilder();
int sumOrderQty = 0;
double sumLineTotal = 0.0;
for (JoinGenericWritable v : values) {
Writable record = v.get();
if (key.recordType.equals(ProductIdKey.PRODUCT_RECORD)){
ProductRecord pRecord = (ProductRecord)record;
output.append(Integer.parseInt(key.productId.toString())).append(", ");
output.append(pRecord.productName.toString()).append(", ");
output.append(pRecord.productNumber.toString()).append(", ");
output.append(pRecord.productSubcategoryName.toString()).append(", ");
} else {
SalesOrderDataRecord record2 = (SalesOrderDataRecord)record;
sumOrderQty += Integer.parseInt(record2.orderQty.toString());
sumLineTotal += Double.parseDouble(record2.lineTotal.toString());
}
}
if (sumOrderQty > 0) {
context.write(NullWritable.get(), new Text(output.toString() +
sumOrderQty + ", " + sumLineTotal));
}
}
}
Running the Job
Running the job in Local Mode is same as it was done earlier, the only change being adding the ProductSubCategories.csv path in the program arguments of the run configuration. The updated program arguments are:
/home/hduser/Desktop/sales_data/SalesOrderDetail.csv
/home/hduser/Desktop/sales_data/Product.csv
/home/hduser/Desktop/sales_data/ProductSubCategory.csv
/home/hduser/Desktop/sales_data/output
Next, the final step is to run the job on the hadoop cluster. I have set-up a single node cluster which I will use to demonstrate the process.
First, start the cluster if it is not already running. Next create a folder in the cluster called JoinExample, run the following command:
hadoop dfs -mkdir /JoinExample
Then use copyFromLocal command to copy the files from local file system into Hadoop HDFS at the newly created folder:
hadoop dfs -copyFromLocal /home/hduser/Desktop/sales_data/*.csv /JoinExample
Next, Maven creates a .jar file in the target folder of the project, as can be seen in the project explorer in Eclipse:

We will use this .jar file, I will copy it to desktop before using.
Finally, the job can be run by using the following command:
hadoop jar /home/hduser/Desktop/hadoopJoinExample-0.0.1-SNAPSHOT.jar
hadoopJoinExample.Driver /JoinExample/SalesOrderDetail.csv
/JoinExample/Product.csv /home/hduser/Desktop/sales_data/ProductSubCategory.csv
/JoinExample/output/

Copy the output to local file system, and examine the output:
cd Desktop
mkdir output
hadoop dfs -copyToLocal /JoinExample/output/* /home/hduser/Desktop/output/

It can be seen that the location of the cache file is on local file system. Alternatively, for completing the example, let's look at a brief explanation of the way a cache file present in HDFS can be used:
The file can be read using FSFileInputStream like so:
URI[] uris = context.getCacheFiles();
FSDataInputStream dataIn = FileSystem.get(context.getConfiguration()).open(new Path(uris[0]));
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(dataIn));
And then, call read lines in a loop like:
String line = bufferedReader.readLine();
while (line != null) {
bufferedReader.readLine();
}
And save them in String array and use them in the method readProductSubcategoriesFile. As an exercise, try implementing it after reading.
Conclusion
To sum up, we looked at two ways to perform join in a Map-Reduce application:
Joinduring theReduce-phaseJoinduring theMap-Phase
I hope I have managed to explain the process clearly. As always, any feedback, criticisms, corrections, comments are welcome.
History
- 25th January, 2015: Initial version