
A Review of Three Natural Language Processors, AlchemyAPI, OpenCalais, and Semantria
4.91/5 (17 votes)
In this article, I review three NLP services
Source Code
The source code for this article is located here: https://github.com/cliftonm/nlp
To run the code, you will need to register with each of the NLP providers and obtain an API key (discussed below.)
Introduction
I've been looking into Natural Language Processors (NLP's) and thought I would share the results of my investigations. We'll look at:
- Pricing
- .NET support
- API call examples
- NLP results
I've reviewed three NLP providers: AlchemyAPI, OpenCalais, and Semantria. They each offer similar services in that they will process text, producing a list of entities and relevance of those entities, along with additional information that is unique to each provider which I'll explore briefly as well. I have a particular interest in using NLP's to acquire the semantic content from websites (blogs, news feeds, articles, etc.) and began investing three NLP's (AlchemyAPI, OpenCalais, and Semantria) with regards to price and features. You can also read my article on how I use the AlchemyAPI service to parse RSS feeds here. For my particular purposes, I was interested in a low-document volume service that was hopefully free for limited use and that could provide web page content scraping. As I started investigating these three services, it occurred to me that this might be useful information for others as well, and thus this article came into being.
With regards to my specific requirements (for a different project) the upshot is that only AlchemyAPI and OpenCalais provide the price point (free for my small volume requirements) and only AlchemyAPI provides the webpage scraping functionality natively, as opposed to using a potentially costly third-party package. That said, my requirements are obviously not yours and you should choose a provider accordingly.
What is an NLP?
"Natural language processing (NLP) is a field of computer science, artificial intelligence, and linguistics concerned with the interactions between computers and human (natural) languages. As such, NLP is related to the area of human–computer interaction. Many challenges in NLP involve natural language understanding, that is, enabling computers to derive meaning from human or natural language input, and others involve natural language generation." (wikipedia)
Uses for NLP
Borrowing from another NLP provider, Smartlogic, which I have not reviewed here:
"The ability to derive metadata, often in real-time, means that information locked-up in content can be made available alongside Big Data flows. It is this metadata that will help you turn Big Data into smart data for use in decision support."
and...
"The resulting metadata drives an array of business-critical tasks including:
- Semantic user experience for search
- Text analytics
- Workflow processes driven by meaning
- Regulatory compliance involving unstructured content
- Automatic classification for Content management
- Decision support using information locked-up in content
- Knowledge management
- Policy application for records management
- Content visualization
- Content monetization
- Improved SEO
- Text mining"
I think that says it very well.
But What Does an NLP Actually Do?
Each of the three NLP services that I review here parse text and determine something called "entities." While each of the services gives some examples of entities, only Semantria provides a clear definition of what an entity is: "Semantria’s Named Entity Extraction (NER) feature automatically pulls proper nouns from text, such as people, places, companies, brands, job titles and more. Each extracted named entity is classified, tagged and assigned a sentiment score, which gives meaning and context to each entity." (https://semantria.com/features/entity-extraction)
In other words, the primary purpose of an NLP is to extract the nouns, determine their types, and provide some "scoring" (relevance or sentiment) of the entity within the text. Using relevance, one can supposedly filter out entities to those that are most relevant in the document. Using sentiment analysis, one can determine the overall sentiment of an entity in the document, useful for determining the "tone" of the document with regards to an entity -- for example, is the entity "sovereign debt" described negatively, neutrally, or positively in the document? NLP's are also capable of extracting higher order concepts and, in the case of OpenCalais, events.
According to the OpenCalais documentation: "Entity relevance scores are comparable across input texts. This means that you can use entity relevance scores in order to determine entity relevance at a collection level, not just at a document level." (http://www.opencalais.com/documentation/calais-web-service-api/api-metadata/entity-relevance-score) If this meaning can be applied to the other providers, it is a useful value for comparing against other documents, but without a definitive meaning of the term "relevance", I'm not sure what the results of such a comparison actually mean. To my knowledge, Semantria is the only NLP service that can natively compare documents, which is a feature I do not explore in this article.
Entity Extraction
Entities are things such as people, companies, organizations, cities, geographic features, and so forth. In edition to the extraction of the entity, each service provides additional information about the entity, usually a relevance or sentiment.
AlchemyAPI Entity
AlchemyAPI's entity has several attributes:
- Type
- Relevance
- Count
- Text
Also, sentiment analysis is turned off by default, as it incurs an additional transaction count against one's daily/monthly allowance.
AlchemyAPI also supports the concept of "linked data". "Linked Data is a method of exposing, sharing, and connecting data on the Web via dereferenceable URIs. Linked Data aims to extend the Web with a data commons by publishing various open datasets as RDF on the Web and by setting RDF links between data items from different data sources. The Linked Data cloud currently consists of over 7.4 billion RDF triples, interlinked by 142+ million RDF links." (http://www.alchemyapi.com/api/linked-data-support/.) Linked data is partially demonstrated in Concepts (see below) in the demonstration program. Currently, Alchemy draws on several linked data resources (see the link above as well as http://linkeddata.org/.)
OpenCalais Entity
Note that in this demo, I'm using OpenCalais' "Simple Format" output. According to Ofer Harari:
"Simple Format output which is the poorest format in terms of capabilities (Simple format is for a quick and easy output from Calais. Not for a detailed response). The standard format is RDF or JSON. These outputs include all the metadata that Open Calais can extract."
"The Resource Description Framework (RDF) is a family of World Wide Web Consortium (W3C) specifications [1] originally designed as a metadata data model. It has come to be used as a general method for conceptual description or modeling of information that is implemented in web resources, using a variety of syntax notations and data serialization formats. It is also used in knowledge management applications." (http://en.wikipedia.org/wiki/Resource_Description_Framework)
It was being the scope of this article to parse the resulting RDF.
An OpenCalais entity has several attributes:
- Value
- Frequency
- Relevance
- Type
OpenCalais supports linking entities to DBpedia, Wikipedia, Freebase, Reuters.com, GeoNames, Shopping.com, IMDB, LinkedMDB. This feature is not demonstrated in the demo code. See also http://linkeddata.org/.)
Semantria's Entity
Semantria's entity has several attributes (which basically conflicts with the documentation on their web page https://semantria.com/features/entity-extraction.)
- Type
- Evidence
- Confident
- IsAbout
- EntityType
- Title
- Label
- Sentiment Score
- Sentiment Polarity
Other Semantic Information
In addition, each provides several additional categories of parsing. Be aware that the names of these categories and their attributes is derived from the API names.
AlchemyAPI
- Keywords
- attributes of Keywords are Text and Relevance
- Concepts
- attributes of Concepts are Text, Relevance, dbpedia (linked data), freebase (linked data), and opencyc (linked data.)
- Relationships - "AlchemyAPI provides the ability to identify named entities within subjects and objects of identified Subject-Action-Object relations, supporting advanced entity recognition capabilities including disambiguation, coreference resolution, and linked data output." (http://www.alchemyapi.com/api/relation/entities.html) I do not show relationship information in the demo code.
OpenCalais
- Topics
- attributes of Topics are Value, Score, and Taxonomy (so far I've only seen "Calais" for taxonomy.)
- Events
- attributes of Events is EventName
Semantria
- Topics
- attributes are Title, Type, Hitcount, StrengthScore, SentimentScore, Label, and SentimentPolarity
- Themes - "Semantria extracts themes within your content so that you can determine and follow trends that appear over a period of time. Themes are noun phrases extracted from text and are the primary means of identifying the main ideas within your content. In addition, Semantria assigns a sentiment score to each extracted theme, so you’ll understand the tone behind the themes." (https://semantria.com/features/themes)
- attributes are Evidence, IsAbout, StrengthScore, SentimentScore, SentimentPolarity, Title
Anaphora Resolution
As pointed out by the folks at OpenCalais, NLP includes something called anaphora resolution:
"In linguistics, anaphora /əˈnæfərə/ is the use of an expression the interpretation of which depends upon another expression in context (its antecedent or postcedent). In the sentence Sally arrived, but nobody saw her, the pronoun her is anaphoric, referring back to Sally. The term anaphora denotes the act of referring, whereas the word that actually does the referring is sometimes called an anaphor (or cataphor)." (http://en.wikipedia.org/wiki/Anaphora_%28linguistics%29)
It first puzzled me as to why the counts of entities were often higher than the actual instances of those entities, and the above explains the reason why.
The Three Contenders
We'll look shortly at what each of the three providers has to say about themselves. First however, I'd like to talk a little about document processing, web content scraping, and initialization.
Documents and Web Content Scraping
All three providers can work with text documents, however only AlchemyAPI provides web content scraping directly as part of the API. OpenCalais and Semantria are both document-based NLP's and as such require that that the web page scraping has been performed a priori. While AlchemyAPI uses its own web page scraping technology, Semantria can integrate with Diffbot for this service. For the purposes of this demo (since DiffBot offers only a 7 day limited free trial), I will be using AlchemyAPI's URLGetText API method to provide the scraped content for the OpenCalais and Semantria NLP's.
/// <summary>
/// We use AlchemyAPI to get the page text for OpenCalais and Semantria.
/// </summary>
protected string GetPageText(string url)
{
AlchemyWrapper alchemy = new AlchemyWrapper();
alchemy.Initialize();
string xml = alchemy.GetUrlText(url);
XmlDocument xdoc = new XmlDocument();
xdoc.LoadXml(xml);
return xdoc.SelectSingleNode("//text").InnerText;
}
To reduce this hits on the AlchemyAPI server, extracting the URL content is cached based on the URL hashcode:
/// <summary>
/// Uses AlchemyAPI to scrape the URL. Also caches the URL, so
/// we don't hit AlchemyAPI's servers for repeat queries.
/// </summary>
protected string GetUrlText(string url)
{
string urlHash = url.GetHashCode().ToString();
string textFilename = urlHash + ".txt";
string pageText;
if (File.Exists(textFilename))
{
pageText = File.ReadAllText(textFilename);
}
else
{
pageText = GetPageText(url);
}
File.WriteAllText(textFilename, pageText);
return pageText;
}
This way, the text being handed to each NLP will be the same. If you're not processing content from web pages (blogs, news feeds, articles, etc.) then this is a moot point with regards to OpenCalais and Semantria.
Initialization and Limits
Initialization of AlchemyAPI and OpenCalais is very simple. One of the issues that you may encounter however is limits to the number of entities (or other items) returned. While OpenCalais does not impose any limits, AlchemyAPI defaults to 50 entities (with a maximum I believe of 250) and Semantria defaults to 5 (with a maximum of 50). Changing the limit in AlchemyAPI is very simple -- you pass in some additional parameters when requesting the processing:
eparams = new AlchemyAPI_EntityParams(); eparams.setMaxRetrieve(250);
Semantria is tailored more toward bulk document processing. You can have a large number of different configurations that you can choose from depending on the document you want processed. Initialization of these configurations however takes some time to communicate to the server and the get a response back. In the demo code, I first request the current configurations (there are 8 initially based on language) and then I change the limit (which has a maximum of 50) and then this new configuration must be uploaded.
protected void IncreaseLimits()
{
// This takes considerable time to get the configurations back from the server.
List<Configuration> configurations = session.GetConfigurations();
config = configurations.FirstOrDefault(item => item.Language.Equals("English"));
if (config != null)
{
config.Document.NamedEntitiesLimit = 50;
config.Document.ConceptTopicsLimit = 50;
config.Document.EntityThemesLimit = 50;
session.UpdateConfigurations(new List<Configuration>() { config });
}
}
This all takes time and is why the Process button is disabled for so long at application startup. However, once done, the configurations can be used without further time penalty. It is also interesting to note that the configurations are persisted between sessions -- I assume they are associated with your API key, so once configurations are created, technically I don't need to run this step unless I want to make a change. For this reason, the method IncreaseLimits() in the Initialize method can be commented out after you first configure Semantria:
public void Initialize()
{
string apikey = File.ReadAllText("semantriaapikey.txt");
string[] keys = apikey.Split('\r');
consumerKey = keys[0].Trim();
consumerSecret = keys[1].Trim();
serializer = new JsonSerializer();
session = Session.CreateSession(consumerKey, consumerSecret, serializer);
IncreaseLimits(); // <---- Comment me out when the limits have been increased after the first-ever run
}
AlchemyAPI


"AlchemyAPI is helping pioneer a computer’s ability to understand human language and vision. Our web services for real-time text analysis and computer vision give you the intelligence needed to transform vast amounts of unstructured data into actions that drive your business. Now you can easily perform sentiment analysis, keyword extraction, entity extraction, image tagging and much more on the massive volumes of web pages, documents, tweets and photos produced every second."
One of the unique things about AlchemyAPI that I noticed right away is that it performs analysis not just on text but also on images.
AlchemyAPI supports named entity, keyword, and text extraction for content in the following eight languages:
- English
- French
- German
- Italian
- Portuguese
- Russian
- Spanish
- Swedish
Content sentiment analysis currently supports English and German, with support for additional languages in development.
To avoid biasing the timing results, I first request the page text using AlchemyAPI and then feed this text into all three NLP's. It should be noted that this produces worse timing for AlchemyAPI than if I had provided the web page URL directly -- meaning that if you give AlchemyAPI the URL, it performs better, and in many cases, significantly better than the other two.
OpenCalais


"We want to make all the world's content more accessible, interoperable and valuable. Some call it Web 2.0, Web 3.0, the Semantic Web or the Giant Global Graph - we call our piece of it Calais. Calais is a rapidly growing toolkit of capabilities that allow you to readily incorporate state-of-the-art semantic functionality within your blog, content management system, website or application."
OpenCalais supports English, French and Spanish.
OpenCalais
Semantria


"Semantria applies Text and Sentiment Analysis to tweets, facebook posts, surveys, reviews or enterprise content. Semantria is a complete cloud-based text and sentiment analysis solution launched in 2011. Faster than a human (60,000x), more accurate than 2 humans (80% of the time it's flat out smarter), and living in the Amazon cloud, Semantria extracts the meaning, tone, and so much more from any text it’s given."
One of the interesting things about Semantria is the Excel plugin: "Semantria is the only Text and Sentiment Analysis solution for Excel. It turns it into a powerful and easy-to-use tool for monitoring and visualizing Twitter, Facebook, surveys and other unstructured data."
Also, Semantria supports these languages:
- English (US/UK)
- French (FR/CA)
- Spanish
- Portuguese
- Italian
- German
- Mandarin (Traditional and Simplified)
- Korean
- Japanese (beta)
- Malay (Bahasa Melayu)
- Indonesian (Bahasa Indonesia)
- Singlish (Singapore Colloquial Language)
Also, Semantria integrates tightly with Diffbot for webpage scraping.
Pricing
Pricing varies considerably and is based on number of transactions being processed daily/monthly and level of customer support.
AlchemyAPI
The pricing that I describe here may not be up on the AlchemyAPI website at the time of this writing, as I was notified directly that the pricing structure was being changed.
There are five tiers:
- Free: 1,000 transactions / day, supporting five concurrent requests, no support
- $250/month: 90,000 transactions / month, 5 concurrent requests, email support
- $750/month: 300,000 transactions / month, 15 concurrent requests, email support
- $1750/month: 3,000,000 transactions / month, 25 concurrent requests, email and phone support, uptime guarantee
- Custom for more than 3M transactions.
For academia, AlchemyAPI offers an increased number of transactions per day in the Free tier.
There is also a "Performance and Support Package" that you can select:
- Free
- Pro plan - $595 / mo
- Enterprise plan - $1995 / mo
As well as a month-to-month subscription option:
- First 250,000 transactions / mo: $0.0035 / transaction
- Next 750,000 transactions /mo: $0.0015 / transaction
- Next 1,000,000 transactions /mo: $0.00075 / transaction
- Next 3,000,000 transactions /mo: $0.00050 / transaction
- Anything over 5,000,000 transactions / mo: $0.0035 / transaction
OpenCalais
Free: 50,000 transactions per license per day and four transactions per second
Commercial License: "Our commercial services provide the same functionality as OpenCalais but with a production-strength twist. The service provides a high-performance SLA, a daily transaction limit of 100,000 transactions and an enhanced 20 transactions per second rate. Additional volume blocks up to maximum of 2,000,000 transactions per day are available. ProfessionalCalais meets needs unique to larger-scale publishers. ProfessionalCalais is available as an annual contract."
Semantria
There are five tiers:
- Free Trial: First 10,000 transactions (total, not per month) free, full featured (although see below in the API discussion for issues that I encountered)
- $999/month: Excel Seat, unlimited transactions
- $999/month: API Standard, 100,000 transactions / month, some limits (like number of supported languages)
- $1999/month: API Premium, 1,000,000 transactions / month
- Custom for more than 1M transactions per month
DiffBbot, which integrates with Semantria for webpage scraping, has its own pricing structure and I am not aware of how that changes the pricing structure.
API's
Each provider requires that you obtain a product key to interface with the API, which is a simple process. I have not included my keys, so to run the code, you will need to register with each provider to obtain your own API key and place it into the appropriate text file (see the code for filenames.) Because I'm working in C# / .NET, I obtained a .NET library to handle the SOAP/REST calls, either from the provider directly or one that I was referred to by the provider. All API's provided examples and various degrees of unit tests.
AlchemyAPI
The AlchemyAPI, to put it simply, just worked. It provided the functionality that I was looking for (give it a URL and it returns semantic results) and it worked without any issues, which was not my experience with OpenCalais or Semantria, though in hindsight, my issues with Semantria were more related to not fully understanding the document queuing model that Semantria uses. Interfacing with the .NET API that AlchemyAPI provides is quite simple, for example:
protected AlchemyAPI.AlchemyAPI alchemyObj;
public void Initialize()
{
alchemyObj = new AlchemyAPI.AlchemyAPI();
alchemyObj.LoadAPIKey("alchemyapikey.txt");
}
// Process a URL directly.
public DataSet LoadEntitiesFromUrl(string url)
{
DataSet dsEntities = new DataSet();
string xml = alchemyObj.URLGetRankedNamedEntities(url);
TextReader tr = new StringReader(xml);
XmlReader xr = XmlReader.Create(tr);
dsEntities.ReadXml(xr);
xr.Close();
tr.Close();
return dsEntities;
}
AlchemyAPI returns an XML document that is well suited for loading directly into a DataSet, as seen by the above code.
One issue I encountered with the .NET AlchemyAPI was that a useful exception message was not being returned, so I modified it slightly to return the message from the server as part of the exception:
if (status.InnerText != "OK")
{
string errorMessage = "Error making API call.";
try
{
XmlNode statusInfo = root.SelectSingleNode("/results/statusInfo");
errorMessage = statusInfo.InnerText;
}
catch
{
// some problem with the statusInfo. Return the generic message.
}
System.ApplicationException ex = new System.ApplicationException (errorMessage);
throw ex;
}
This change has been folded into the C# AlchemyAPI hosted on GitHub.
AlchemyAPI's content size limits are 150KB of cleaned text and 600KB of HTML.
OpenCalais
The Open Calais .NET library on Codeplex was the most difficult of the three libraries to work with, requiring me to fix the entity enumerator. The first issue with this library is that, when you unzip it, all the files are read-only. This made it impossible to load the projects and solutions into VS2012 without first changing all the files and folders to read-write.
Second, using their sample document, I was getting "Unhandled Exception: System.ArgumentException: Requested value 'PoliticalEvent' was not found." because there were missing types in the CalaisSimpleEntityType enumerator:
// Ignore topics and events are they are processed seperately
if (elementName != "Topics" && elementName != "Event" && elementName != "Topic")
{
newSimpleEntity.Type = (CalaisSimpleEntityType)Enum.Parse(typeof(CalaisSimpleEntityType), result.Name.ToString());
yield return newSimpleEntity;
}
To fix this, I had to go in and change this class:
public class CalaisSimpleEntity
{
public string Value { get; set; }
public int Frequency { get; set; }
public string Relevance { get; set; }
public CalaisSimpleEntityType Type { get; set; }
}
so that Type was a string (why it's mapped to an enumeration is beyond me):
public class CalaisSimpleEntity
{
public string Value { get; set; }
public int Frequency { get; set; }
public string Relevance { get; set; }
public string Type { get; set; }
}
and the offending line of code:
newSimpleEntity.Type = result.Name.ToString();
I also had to fix a unit test that failed to compile as the result of the type change.
I also found it annoying that the properties for Entities, Topics, and Events are IEnumerable's, meaning you have to explicitly iterate through the collection to acquire the contents, which, underlying, involves some processing of the XML document. This seems inefficient, especially if the collection is iterated over many times by different functions, but can be worked around by converting the collections to lists, as I did in the simple "get" functions, for example:
return document.Entities.ToList();
Given that the contents of these collections is unchanging, I see no reason not to pre-populate the collections with their items.
My other issue with OpenCalais is that my sample document (the text of Wikipedia's page on Computer Science) resulted in a "content is not valid" exception from the server. It turns out that the offending sentence is this:
The term is used mainly in the Scandinavian countries. Also, in the early days of computing, a number of terms for the practitioners of the field of computing were suggested in the Communications of the ACM – turingineer, turologist, flow-charts-man, applied meta-mathematician, and applied epistemologist.[34]
and can be further reduced to the use of the "–" character -- the Unicode character 0x2013 "EN DASH". OpenCalais is apparently rather sensitive, but we can strip Unicode:
// A couple options: http://stackoverflow.com/questions/123336/how-can-you-strip-non-ascii-characters-from-a-string-in-c
string asAscii = Encoding.ASCII.GetString(
Encoding.Convert(
Encoding.UTF8,
Encoding.GetEncoding(
Encoding.ASCII.EncodingName,
new EncoderReplacementFallback(string.Empty),
new DecoderExceptionFallback()
),
Encoding.UTF8.GetBytes(content)
)
);
Once properly sanitized, the actual call to parse the document and extract data is very simple:
CalaisDotNet calais = new CalaisDotNet(apikey, asAscii);
document = calais.Call<CalaisSimpleDocument>();
...
public IList GetEntities()
{
return document.Entities.ToList();
}
Other Tidbits Regarding OpenCalais
There is a complementary service, http://semanticproxy.com/, that is supposed to perform content scraping, however, when I tried to use it (at different times) I constantly received a "Java out of memory" error.
In this demonstration code, I am using "Simple Format" output. According to Ofer Harari:
"Simple Format output which is the poorest format in terms of capabilities (Simple format is for a quick and easy output from Calais. Not for a detailed response). The standard format is RDF or JSON. These outputs include all the metadata that Open Calais can extract."
Semantria
I originally found Semantria's .NET API to be complicated to work with, which I realized after having success with it was that it takes a different approach to processing documents. With AlchemyAPI and OpenCalais, you make the call and wait for the results. With Semantria, it is very bulk-document centric. Documents that are sent to the Semantria servers are queued and can return asynchronously with results or in a different order from the original input into the queue. This makes working with a single document more complex (see code below) but clearly, the strength of Semantria's API is much more evident when working with bulk documents.
There are also two modes of document analysis, described here: https://semantria.com/support/developer/overview/processing
- Detailed Mode
- Discovery Mode
Detailed Mode
"After submitting documents to be queued, each document will be analyzed independently of the others. Semantria API will return an analysis for each document."
Discovery Mode
"This method submits an array of documents to be analyzed in relation to each other and returns one output. Discovery analysis will contain a summary of commonalities, sentiments, named entity extraction, themes, and categorization for all the documents in the collection."
This article reviews Detailed Mode only, however, when working with Discovery Mode I "discovered" an issue with document size--with my scraped webpage content string, I was getting "line too long" exceptions. It seems that Discovery Mode is intended to work with smaller datasets, such as paragraphs or single sentences. I am not sure what the line limit is when in Discovery Mode.
Calling the parser requires polling to see if the document is analyzed. While there is a DocsAutoResponse event callback, this isn't what it seems -- if the document is queued (which is the standard behavior) this callback is never made, and I'm not sure how this event helps, unless it is associated with the bulk processing. Here is the parse request and response poll code:
public void ParseUrl(string content)
{
string docId = Guid.NewGuid().ToString();
Document doc = new Document() {Id = docId, Text = content};
docResults = new List<DocAnalyticData>();
int result = session.QueueDocument(doc, configID);
DocAnalyticData ret;
DateTime start = DateTime.Now;
do
{
// Semantria guarantees a result within 10 seconds. But how fast is it really?
Thread.Sleep(100);
ret = session.GetDocument(doc.Id, configID);
if ((DateTime.Now - start).TotalSeconds > 15)
{
throw new ApplicationException("Semantria did not return with 15 seconds.");
}
} while (ret.Status == Semantria.Com.TaskStatus.QUEUED);
if (ret.Status == Semantria.Com.TaskStatus.PROCESSED)
{
docResults.Add(ret);
}
else
{
throw new ApplicationException("Error processing document: " + ret.Status.ToString());
}
}
As stated at the beginning of this article under Initialization, the default number of entities is 5 (themes is also 5 and topics is 10). In this article I have increased the limit to 50, which is the maximum.
Running the Demo
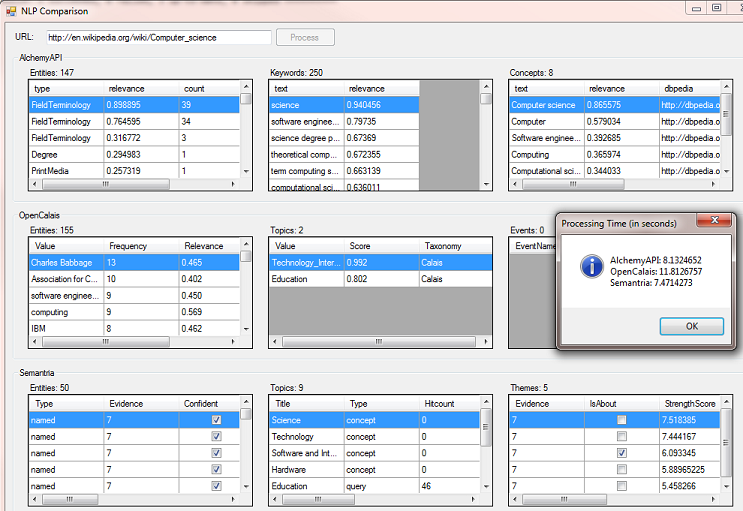
The screenshots that I've been using come from parsing this page: http://en.wikipedia.org/wiki/Computer_science. You can of course enter your own URL in the demo application (try a Code Project article, the results are often interesting.) The code that does the processing runs each service request asynchronously, marshalling the UI data grid updates back onto the UI thread (not shown). I also cache (using the URL's hash code) the scraped web page returned by AlchemyAPI so I'm not constantly making a "get page content" request to AlchemyAPI when testing the same web pages over and over.
/// <summary>
/// Process the URL with AlchemyAPI, OpenCalais, and Semantra NLP's.
/// </summary>
protected async void Process(object sender, EventArgs args)
{
btnProcess.Enabled = false;
ClearAllGrids();
string url = tbUrl.Text;
sbStatus.Text = "Acquiring page content...";
// Eases debugging when we comment out one or more of the NLP's to test the other.
double alchemyTime = 0;
double calaisTime = 0;
double semantriaTime = 0;
string pageText = await Task.Run(() => GetUrlText(url));
sbStatus.Text = "Processing results with Alchemy...";
double alchemyTime = await Task.Run(() =>
{
LoadAlchemyResults(pageText);
return ElapsedTime();
});
sbStatus.Text = "Processing results with OpenCalais...";
double calaisTime = await Task.Run(() =>
{
LoadCalaisResults(pageText);
return ElapsedTime();
});
sbStatus.Text = "Processing results with Semantria...";
double semantriaTime = await Task.Run(() =>
{
LoadSemantriaResults(pageText);
return ElapsedTime();
});
sbStatus.Text = "Done processing.";
ReportTimes(alchemyTime, calaisTime, semantriaTime);
btnProcess.Enabled = true;
}
Using .NET's Task.Run allows the to UI remain responsive so you can interact with it while other results are still coming in.
Keys
Of course, to run the demo, you will need to register with each provider and obtain your own API keys. These go into their respective files in the bin\debug folder:
alchemyapikey.txt
[your key]
calaisapikey.txt
[your key]
semantriaapikey.txt
[your consumer key]
[your secret key]
A Second Example
I decided to throw something more interesting at these providers--Rudolf Steiner's Chapter 3 "Culture, Law, and Economics" of his lecture series The Renewal of the Social Organism. The results are interesting and reveal the differences between the three NLP's. Keep in mind that I'm using the Simple Format with OpenCalais and so the results may not represent its full semantic processing capability. It was being the scope of this article to parse the resulting RDF.

Resulting Entities
AlchemyAPI Entities
| type | relevance | count | text |
|---|---|---|---|
| PrintMedia | 0.734508 | 1 | Law and Economics |
| Crime | 0.684892 | 1 | monopolization |
| JobTitle | 0.635413 | 1 | business manager |
| Facility | 0.61222 | 1 | St. Simon |
| JobTitle | 0.606995 | 1 | official |
| Person | 0.602684 | 1 | Marx |
| Person | 0.581026 | 1 | Fourier |
OpenCalais Entities
(No topics or events were returned)
| Value | Frequency | Relevance | Type |
|---|---|---|---|
| natural law | 2 | 0.286 | IndustryTerm |
| devise external systems | 1 | 0.251 | IndustryTerm |
| economic services | 1 | 0.318 | IndustryTerm |
| manager | 1 | 0.314 | Position |
| government official | 1 | 0.239 | Position |
| business manager | 1 | 0.314 | Position |
| shopkeeper | 1 | 0.239 | Position |
Semantria Entities
| Type | Evidence | Confident | IsAbout | EntityType | Title | Label | SentimentScore | SentimentPolarity |
|---|---|---|---|---|---|---|---|---|
| named | 7 | True | False | Job Title | manager | Job Title | 0.171760261 | neutral |
| named | 4 | True | False | Person | Marx | Person | 0.294535 | neutral |
| named | 2 | True | False | Quote | “It is impossible to bring about satisfactory conditions through this organic formation of society. It can be done only through a suitable economic organization.” | Quote | 0.218072414 | neutral |
| named | 1 | True | False | Quote | “social question” | Quote | 0 | neutral |
| named | 1 | True | False | Quote | “simplicity” | Quote | 0.49 | neutral |
| named | 1 | True | False | Quote | “self-evident fact” | Quote | 0 | neutral |
| named | 1 | True | False | Quote | “social question” | Quote | 0 | neutral |
AlchemyAPI Concepts
| text | relevance | dbpedia | freebase | opencyc |
|---|---|---|---|---|
| Sociology | 0.965445 | http://dbpedia.org/resource/Sociology | http://rdf.freebase.com/ns/m.06ms6 | http://sw.opencyc.org/concept/Mx4rvVvb3pwpEbGdrcN5Y29ycA |
| Law | 0.445281 | http://dbpedia.org/resource/Law | http://rdf.freebase.com/ns/m.04gb7 | http://sw.opencyc.org/concept/Mx4rvV1TLJwpEbGdrcN5Y29ycA |
| Economy | 0.40107 | http://dbpedia.org/resource/Economy | http://rdf.freebase.com/ns/m.0gfps3 | |
| Economics | 0.391207 | http://dbpedia.org/resource/Economics | http://rdf.freebase.com/ns/m.02j62 | http://sw.opencyc.org/concept/Mx4rvqlEOpwpEbGdrcN5Y29ycA |
| Human | 0.36315 | http://dbpedia.org/resource/Human | http://rdf.freebase.com/ns/m.0dgw9r | http://sw.opencyc.org/concept/Mx4rIcwFloGUQdeMlsOWYLFB2w |
| Religion | 0.353719 | http://dbpedia.org/resource/Religion | http://rdf.freebase.com/ns/m.06bvp | http://sw.opencyc.org/concept/Mx4rvVkCHZwpEbGdrcN5Y29ycA |
| Spirituality | 0.344812 | http://dbpedia.org/resource/Spirituality | http://rdf.freebase.com/ns/m.070wm | |
| Communism | 0.280482 | http://dbpedia.org/resource/Communism | http://rdf.freebase.com/ns/m.01m59 | http://sw.opencyc.org/concept/Mx4rvVi0EZwpEbGdrcN5Y29ycA |
AlchemyAPI Keywords
(I'm only showing the first 10 of the 250 keywords returned.)
| life | 0.926948 |
| cultural life | 0.884749 |
| economic life | 0.766198 |
| economic power | 0.720022 |
| free cultural life | 0.717939 |
| practical life | 0.669134 |
| modern social movement | 0.668291 |
| spiritual life | 0.654856 |
| nature | 0.638823 |
| individual wills | 0.635454 |
..etc..
Semantria Topics
| Title | Type | Hitcount | StrengthScore | SentimentScore | SentimentPolarity | Label |
|---|---|---|---|---|---|---|
| Science | concept | 0 | 0.78942883 | 0.121833332 | neutral | |
| Economics | concept | 0 | 0.748247862 | 0.414984226 | neutral | |
| Law | concept | 0 | 0.7397579 | 0.356725723 | neutral | |
| Education | concept | 0 | 0.494773239 | 0.351259947 | neutral | |
| Science | query | 3 | 0 | 0.750133157 | positive |
Semantria Themes
| Evidence | IsAbout | StrengthScore | SentimentScore | SentimentPolarity | Title |
|---|---|---|---|---|---|
| 7 | True | 2.95010757 | 0.7593447 | positive | individual persons |
| 7 | False | 2.93402934 | 7.267939 | positive | economic life |
| 7 | True | 2.7541132 | -13.2000027 | negative | evils — evils |
| 7 | True | 2.544567 | 6.680146 | positive | Socialist thinkers |
| 7 | True | 2.48574352 | 9.6 | positive | wide range |
Conclusions
The testing here is not exhaustive--some may argue not even comprehensive. I am not testing high throughputs and haven't simulated customer service issues. All three providers replied very quickly when I emailed them that I was writing this article, and I've had excellent and helpful conversations with all of them. After working with each provider, I realized that they each would deserve a "deep dive" article on their own. Even this high-level review has taken a considerable amount of time and I have glossed over (or outright skipped) many of the features of these providers.
I strongly suggest that you invest each provider in detail yourself to see what additional features and capabilities exist. Especially with regards to OpenCalais, I would strongly suggest that anyone interested in using this service further investigate the RDF output.
Also, as a general criticism, each provider would do well to explicitly define what the various terms mean in their API's and the collection attributes. If one is to use these services for serious analysis of documents, an exact meaning is a requirement.
Lastly, I find the concept of Natural Language Processing intriguing and that it holds many possibilities for helping to filter and analyze the vast and growing amount of information out there on the web. However, I'm not quite sure exactly how one uses the output of an NLP service in a productive way that goes beyond simple keyword matching. Some people will of course be interested in whether the sentiment is positive or negative, and I think the idea of extracting concepts (AlchemyAPI) and topics (Semantria) are useful in extracting higher level abstractions regarding a document. NLP is therefore an interesting field of study and I believe that the people who provide NLP services would benefit from the feedback of users to increase the value of their service.