
A Complex - Yet Quite Intelligible - Pathfinding in C#
A semi-analytic 2D path-finding for large dynamic scenarios.
- Download source (version 1.0) - 106.81 KB
- Download source (version 2.0) - 121.50 KB
- Download source (version 3.0) - 131.21 KB (NEW)
Introduction 
This article is about a pathfinding algorithm, that is semi-analytical in nature, and doesn't require heavy memory use, and in this aspect quite differentiates itself from the rest of the algorithms trying to solve the same problem. Most of them are graph searching algorithms. It's not a silver bullet algorithm by any means. It has its advantages, and also some disadvantages. I just think it deserves to be mentioned. You never know how it might be useful to someone, or it can inspire one to adopt it, or enhance it even to overcome its actual limitations, and become something more. I think it has great potential to be optimized.
In version 2.0, you can also specify the width of your object instead of having single point traveling. There are new algorithms (but unusable ones basically), new scenarios (in addition to the boxes, there are the circles and the lines now... what a rip off), better graphics, and also some optimizations and corrections.
The main feature of version 3.0 is the scenario virtualization that gets rid of the need to have some buffered underlying map. Again, some new algorithms are included. This time, they're even upto par with A*, and Evasion.
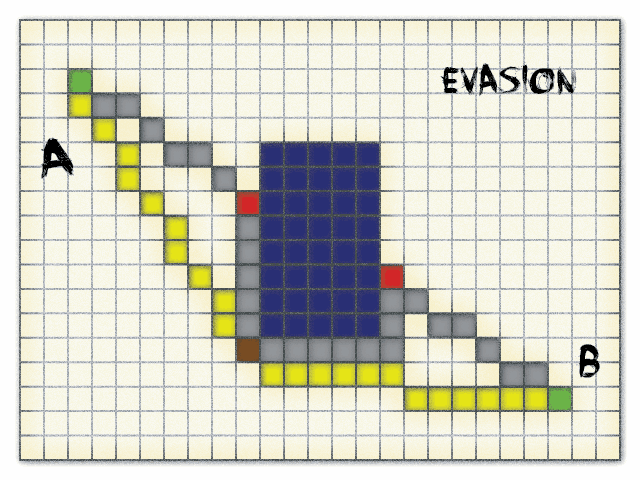
Background
I wasn't satisfied with all the variants of Dijkstra floating about on the Internet. I know they can be quite optimized, but they always seemed too heavy, too brutal force. Or maybe it was sight of all those nodes pointlessly growing out in the directions, that can be by human easily recognized as useless from the get go. Then I remembered that about 15 years ago, my friend and I came up with this algorithm. Well actually I think he did, so I'm giving him credit this way. But it was more of an idea. It was like a rough diamond waiting to take some useful shape. So I've started to chip away the unneeded clutter. It originally only walked around an obstacle on collision, in both left side and right side. If it found the point on the other side, it chose a shorter path (left or right), and continued on. This approach of course has problems with hollow (closed rooms for example) areas. Also, it has many other problematic edge cases. All of these were hopefully addressed, and shaped to a functional general algorithm.
Using the Code
This section always confuses me. The programmers are not using the code. We're (hopefully) living in a harmonious coexistence. I never know what to put here. I've tried to comment my code heavily, and I would hope it is self-explanatory and easy to read, but you can always ask me in the forum, if something seems unclear. So "use" the code as desired, and needed.
So What Is Pathfinding About?
To say it bluntly, it is about getting from point A to point B if possible, no matter what. There are - of course - the bad guys in this story as well. Let's call them the obstacles. And the worst of these are the hollow obstacles you just can't get into. You learn to hate them very quickly. But the salvation is near. This newly introduced algorithm just loves them. It goes through them like a hot knife through butter. More than that. The hollow objects are actually speeding this devil up (in some sense). So what is pathfinding? Finding a reasonable path approximating the optimal path, whenever one exists, while evading all the obstacles in the path. Static or moving ones. And all of this must be as fast as possible.
One Method APIs
It seems that in each article the API gets easier, and easier. This time we only got one method to work with. What a beautiful simplicity. What this interface lacks in the methods, it makes up for in the parameters. You provide this method with start (startPoint) and target point (endPoint), and it tries to find its way, returning the final path, or not. In case there's none to be found in the first place. It uses mapping function to retrieve unit (usually some kind of node, or cell in a 2D map) at given coordinates, and unit function to determine whether the input unit is an obstacle. These work around the usual way which requires nodes to implement some custom interfaces, and also maps to have some particular format (usually two dimensional array). Now you can have anything you want. The only limitation is point, but that depends on implementation anyway. The pivot points are only used for the purposes of this demo, and as such can be dropped in production, as well as the optimization flag. So here you go, meet the IPathfinder:
In version 2.0, I've already managed to deprecate two parameters that are now joined together, after slight Evasion algorithm optimizations. I'm not exactly big on stable (let alone backward compatible) APIs here on CodeProject; or so it seems.
public interface IPathfinder
{
Boolean TryFindPath<TMapUnit>(Point startPoint, Point endPoint,
StopFunction stopFunction, // introduced in version 2.0
MapFunction<TMapUnit> mapFunction, // deprecated in version 2.0
UnitFunction<TMapUnit>unitFunction, // deprecated in version 2.0
out IReadOnlyCollection<Point> path,
out IReadOnlyCollection<Point> pivotPoints,
Boolean optimize = true);
}
Since version 3.0, I've decided to include a new interface: IPathScenario. It has slowly grown to be important part as well. Its base implementation helps to provide some basic functionalities like caching. And the distance map was also moved here. The interface itself contains only a method, that determines whether a discrete unit on a given coordinates is blocked for an object of certain diameter. That's it:
public interface IPathScenario
{
Boolean IsBlocked(Int32 x, Int32 y, Int32 diameter);
}
A Complex Implementation of a Simple Problem
The Good Old Line
In the core of this algorithm lies the Bresenham's line algorithm. I'm using a slightly modified version to disable diagonal transitions. Those lead to what I call "inaccessible cavern" problem. They might go through an enclosed area, and exit using the diagonal. But this algorithm cannot reach it there, therefore looping around forever inside that cavern.
A Simple Idea
It is really quite easy to grasp this algorithm. But as both the article title, and title of this chapter spoil; that the implementation is not that easy as it might seem. Figure 1 is showing a simple scenario that illustrates how this algorithm works in a nutshell. You start at point A (departure point), you then use the line algorithm mentioned above, to enumerate all the points (points will be used as placeholder for any 2D discrete grid unit) up to the point B. While processing, you keep track of only the outside segments. Black signifies the "inside" in these figures. As you can see, you'll go from A to C. Then a collision at point C is detected, you ignore the points from C (+ one step) to D (- one step). Then you again start recording from D to B. So in this case, we've ended up with two segments (A->C, D->B). There, the first part is done.
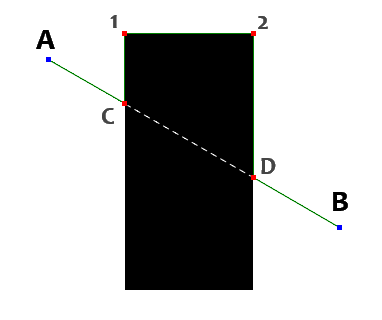
Now we start a cycle of taking segment, and solving the obstacle collision it suffered. We add the segment's path (A->C) to a result. So now it equals to {A, C}. Now another method tries to solve the collision by going around (left side in my case, but it shouldn't really matter). We create the list of all the starting points of all the segments (higher than the one being processed). That means only one segment this time D->B. We store our D point in a finish point set. A collision direction is detected in this case (figure 1) it is south-east direction. This direction is rotated left until the neighbor around collision point (C) is not blocked. East is still blocked, so we'll end up with north. We then on each step try to rotate from reverse of the current direction (i.e. south) to the left (not including the reversed direction of course), ensuring we follow the shape of the obstacle. But until point 1 (our first corner) we still detect north as our primary direction. In the corner point (1) we detect east suddenly. We mark this corner point to a corner points list (now {1}), we then continue east until we again detect another corner point (2), it is added to our set as well (now {1, 2}). Continuing still we encounter the finish (D) we've prepared earlier. We note the count of corner point list (at this moment it contains {1, 2}). This will be later used to split left side path, and right side path. Also we note the number of total steps at this moment. Again to determine whether the left path was shorter or longer than the right path. Then we continue as mentioned above to south, grabbing point 3, then west, encountering point 4, and finally north and we end up at starting point C again. So now have obstacle scanned with some useful information. We got list of corners {1, 2, 3, 4}, we've total step count (circumference of the obstacle), index up to which corner point list is left path (from that index on we can assume right path), similarly we have left side step count (right side can be inferred by a simple calculation: right side step count = total step count - left side step count), and finally a segment index the encountered finish point belongs to. We determine shorter path, use index to split corner list, and add that half to our result list. If we didn't encounter any finish point during our obstacle scan, the end point is inaccessible, and we can end the pathfinding now. After processing all the segments, we have our result list of points.
As I've said, phew, fairly complex for what one picture can describe in seconds. Last time it did me well, so I'm including the meta-bullet-code, here goes:
- Find all the accessible segments on a line from A to B.
- For actual segment
- Add both start point and end point to a result list
- Create set of finish point set (start points of segments after the one processed)
- Detect collision direction
- Rotate this direction to left, until a neighbor is unblocked
- Repeat until position is back on collision point
- Continue in actual direction
- Rotates from reverse of current direction to left, until unblocked
- If direction changes, add point to a corner point list
- If finish point is detected, note actual corner point count, and step count (left side step count)
- Increase total step count
- If we've found some finish point, set actual segment to finish point's segment (next to be processed)
- If none was found, we're done, path doesn't exist.
- If left side step count is higher than half of total step count we use right path, otherwise left path is shorter
- If left path is the path, split corner point list at corner point count and take left part, otherwise take right part
- Add these corner points to a result list (reverse them if right path was shorter).
The Hollow Threats
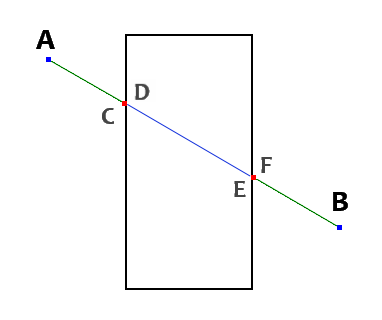
As you can see in this simple scenario (figure 2), the hollow areas are indeed evil. Most of the Dijkstra family algorithms have problems with these creatures, as it forces them to process all the nodes in a graph (exerting performance and memory to the maximum). That usually forces them to workaround it, and either ensure that there're no hollow areas (enclosed with unblocked points in it), or somehow preprocess the path. This algorithm skips them by making a set of all the finish points from segments posterior to one being processed. So when processing first segment A->C (for example) we gather all starting points (now finish points) from other following segments (D->E, F->B). This gives us set of {D, F}. If we encounter any of those while walking around the obstacle, we can use them to continue to next segment. As you can see, by walking around the obstacle only the next finish point (D) wouldn't be enough, as we would never hit it when walking around. By including all of them, we can now skip to segment F->B, and continue processing. So in a sense, we've not only solved it, but it spared use the time needed to walk around the inner wall. Thus we're using the archenemy of pathfinding to our advantage. This advantage makes algorithm immune to hollow areas, and we don't have to be bothered by them ever again.
Improving a Zombie Walk
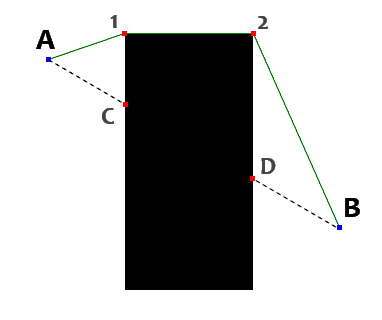
As well as the zombies, these dumb paths need some brains. At this moment, all we have is truly zombie like behavior. Walk towards the goal directly, when obstacle is encountered, just plow through around. We somehow need to optimize our path, to be more reasonable. One way is to use line of sight to verify, if we can drop some points in between. We begin by setting our start point to point A (figure 3). We add this point to our optimized result path, and we slowly go backward from the last point (B, D, then 2, then 1) to our start point. We use again the Brensenham's line algorithm to determine whether the path is blocked. When a path from start point (A) to processed point is unblocked (in this case 1) we've found our next step. As you can see, we've already optimized away the point C. We then add this point to result path, and continue again from the last point. But starting point is now set at the last visible point (1). So we're again testing 1->B, 1->D, 1->2, found, point 2 is our next result point. And again 2->B, again done (optimizing away the D point). This makes our result list {A, 1, 2}. If we end up at last point, we cannot process further, so we just add the last point to our result, and we're done. This leads to an optimized set of the points {A, 1, 2, B}. We've optimized away two points even in this limited scenario, and the path looks much more reasonable now. We have only four points for a quite large map now. It makes this algorithm boding well with large areas without a sweat (or excessive memory consumption).
Fat Object Movement
Now that our object is moving intelligently along the optimized pathway, we want more. We want our object to have additional constraint - fatness,... faticity, ok let's call it a diameter for brevity's sake. Instead of trying to alter our algorithm in some complicated way, we can use a precalculated distance map. This map is calculated only once per scenario, per fixed objects in the scenario that is (like buildings, rivers, you name it). At each pixel, it indicates the distance from the nearest obstacle (check the figures 4a-4d). This way, we simply make pixel an obstacle if the width wouldn't fit. We know the radius of the object, we know the distance from the nearest obstacle so it is a simple comparison. This way the final path is already taking into account the radius. We don't have to modify our algorithm, and not even the path optimization. You might now ask: "What if I need a different shape other then circle?" Well, imagine a rectangle case for example. It would need to turn, and rectangle turning all the way is again the circle. So there's always a diameter. You just need to fit your shape in one.
 |
 |
 |
 |
|
Figure 4a: Finds the obstacles first.
|
Figure 4b: Sets distance of 1 to the neighbors.
|
Figure 4c: Continues setting distance to next wave.
|
Figure 4d: Finished complete distance map.
|
GetPixel must die!
That's exactly right. It is a well known fact, that GetPixel is awfully slow. This led me to a full scenario virtualization. Sometimes the map can be represented better as a series of rectangles (for example buildings), or other simple shapes. It would be cruel to require drawing it all first on an image, and then finding the path using a slow method. But I'm aware that there's a certain limit (usually geometry instances count) after which even the geometric analytic scenario is not fast enough. For these cases, I've included a clever base scenario implementation, that supports also caching via BitArray. This way, we're using just 1 byte per 8 pixels (for example for a map of 512 by 512 units it only requires 32kB to store, instead of 256kB, or worse). The Random Markers scenario is implemented this way for you to understand. Handling the collision detection of five thousand rectangles was just too intensive, so instead the cache is used. Only a simple bit check is needed then.
Using virtualization, we're finally seeing some real bare-bone performance of the algorithms. There's also a significant speed-up in comparison with previous "GetPixel" version.
Algorithm Shopping Cart
I amended from the last time, and I'll try to introduce other available pathfinding algorithms in this section. To give the reader a context for the algorithm introduced in this article, I'll possibly implement some of them as versions will pass by; as I did in case of A Simple - Yet Quite Powerful - Palette Quantizer in C#.
Evasion Pathfinder (Included in version 1.0)
I've included this only as a comparison to other algorithms, I've tried to be objective.
|
|
|
Common for all of the Dijkstra family
|
|
|
A* (Included in version 1.0)
One of the most popular pathfinding algorithms out there. It is based on the Edsger Dijkstra's algorithm for finding the shortest path in a graph. It basically directed flood-fill algorithm that calculates heuristically the distance to the finish node. It also accumulates the score as it spreads out. As the source point expands to its neighbors, it creates a border surrounding the already processed area. In each step, a node with the best score is selected, and is processed with top priority (lowest estimated score). So you start with neighbors around the start point, you put them in a set of unprocessed coordinates. The best one is then selected to be processed next, its neighbors are then again added to the set of unprocessed neighbors, and the next candidate is selected from them all, and so on. So it is slowly pushing the boundary towards the goal. Each node also remembers which other node it was created by. So when you reach the finish node, you can traceback the path to a starting point. This is our final path (albeit reversed). If you deplete all the unprocessed nodes without finding a finish point, it is deemed inaccessible. There are plenty of the variants on Dijkstra (and similarly A*), they differ mostly in the ways the flood is directed, and also heuristics to calculate their score.
|
|
|
Best-first search (Included in version 3.0)
This algorithm is again a member of the Dijkstra family. It is basically the A* algorithm, with only a heuristic score. Again the flood-fill is performed, the neighbors are detected, then rated, and the one with the best heuristical score (pseudo-Euclidean distance from target point in this case) is processed immediately. The performance is similar to A*. Sometimes it performs better, usually a bit worse. A* is more of an evolutionary step up.
|
|
|
Breadth-first search & Depth-first search (Included in version 2.0)
These are again the variants of Dijkstra algorithm. They perform the flood- fill, but instead of the sophisticated heuristic (as it was case for A*), there's only a queue for BFS (resp. stack for DFS). You put the newly found nodes in as you find them. The already visited nodes are being skipped. BFS algorithm quite surprised me actually, as I didn't think it would do that well. It is still practically unusable (for these kinds of scenarios), but it works. It works slowly, but well. DFS on the other hand is what I expected, and more. Painfully slow (or maybe I did something wrong, it's always a possibility), and it just proved that it has nothing on this scenario. These two have other uses, like simple mazes, or mainly uses outside of realm of pathfinding.
I can't recommend these. Too slow, too memory use intensive.
|
|
|
Dijkstra (Included in version 2.0)
I was first going to do just a honorable mention, but it did quite well, so I've included it in the list. It is basically A* without heuristic, or I should rather say, that A* is Dijkstra with heuristic. The A* speed-up is quite noticeable, if not logical. Still it does surprisingly well. I would say it beat both BFS and DFS in most cases.
I can't recommend this algorithm for large areas such as those used here.
|
|
|
Jump-point search (Included in version 3.0)
I've read that it should consistently outperform the A*, but I wasn't able to confirm that. It is quite possible that I've made some mistakes here, but I've checked many times, from different sources, and it seems to be okay. It performs better in certain type of scenarios, but mostly performs quite worse than that. If someone can spot any problem, let me know. I think the inefficiency spans from the fact, that it still checks the points in a jump direction. So it skips opening the node for processing, but in these cases the StopFunction check still is performed. Removing the recursion didn't seem to improve it much. But it works, and in mazes it seems to perform better than A*.
To be sure rather check the original source: Jump-point search. I won't include cons/pros yet, before I'll do some more testing.
Screenshots Gallery
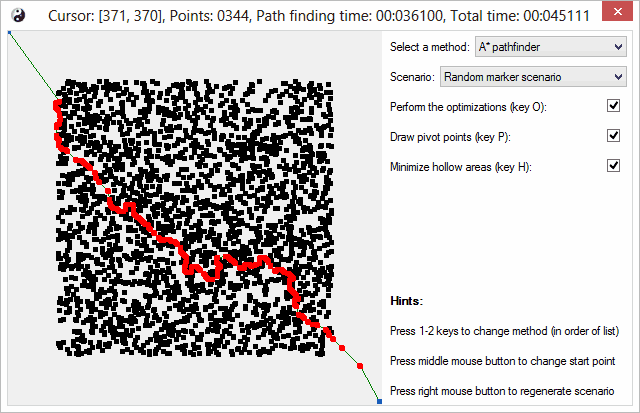
Unfortunately the screenshots are not as colorful and nice, as it was case for the color quantization. So I will just briefly show you these two ugly screenshots. I've tried my best to make it artistically pleasing, but there are limits to what's possible. This first screenshot shows random marker scenario (5000 small rectangles). It is used to simulate dense environments.
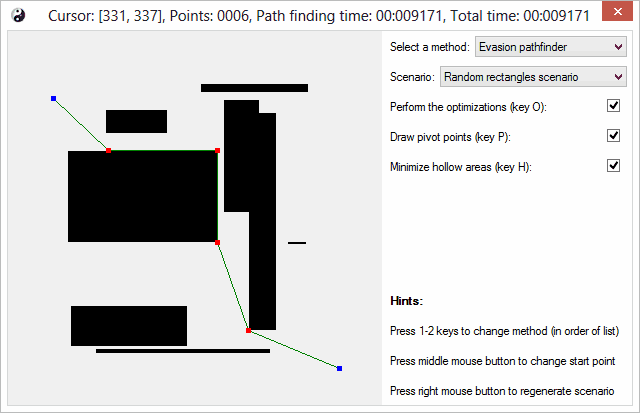
Another screen is showing the actual Evasion algorithm in action. This scenario on the other hand simulates large empty areas with less larger objects.
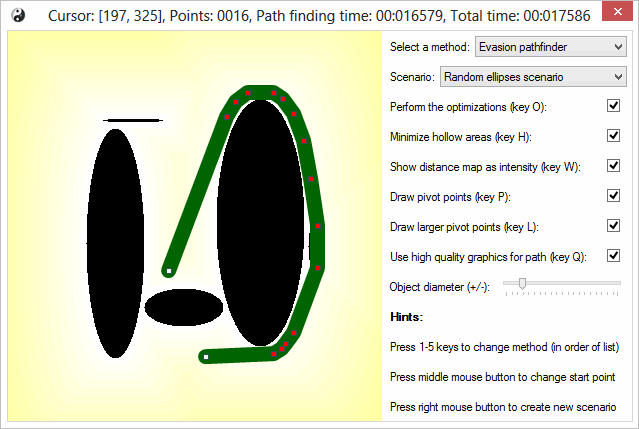
I've managed to sneak in some effects, to increase the eye candiness of it all. This image shows new distance map for calculating path for the objects with radius, and also demonstrates it in a newly added random ellipse scenario. You can also notice, there are few more settings to play with.
As you can see in version 3.0, the distance map includes the edges. In this screenshot also a virtualized scenario for the random lines is shown. Some of the scenarios now support quality of collision detection. You can choose between speed and quality.

Feedback
Feel free to ask anything in the forum below, as usual. If you find some interesting optimization or feature (aka bug ;-P), let me know.
Related Articles
- A Simple - Yet Quite Powerful - Palette Quantizer in C#
- Image per pixel enumeration, pixel format conversion and more
Change Log
Version 3.0
- Scenarios now can be fully virtualized
- New interface IPathScenario introduced
- Overall speed-up of algorithms, due to virtualization
- Distance map generation speed-up, and map is part of scenario now
- Borders are now included in distance map
- Two new algorithms included
Version 2.0
- The new algorithms and scenarios included
- Support for object radius (won't pass through narrow paths)
- High quality graphics is now supported (antialiasing basically)
- Better and faster path optimizations (yep, should've read my own article more carefully)
- Many bugfixes and code corrections included
- Code comments coverage increased
- The pathfinding interface is streamlined a bit now (code word for -> changed)
Version 1.0
- Initial spontaneous version released
History
- 2013-08-30: Version 3.0 published
- 2013-08-30: The section GetPixel must die! added
- 2013-08-24: Version 2.0 published
- 2013-08-24: The section Fat Object Movement added
- 2013-08-18: The initial article was posted