
Making a Search Engine
This article discusses the making of a search engine.
- Download Executable files - 178.3 KB
- Download source -21.5 KB
- Download PHP file - 6.83 KB




Introduction
This project is still not complete. You must use it to crawl thousands of URLs because you may find that it crawls the same URL for the last 100 times. (This is because of some unidentified problem in conversion of relative to absolute URL.)
Like most search engines, this one also has a crawler whose basic aim is to retrieve the source code of a given URL and then break the content into words with which we can create an array of tag words which will represent the content of the site. It is not a fool proof method, but can work for sites with lots of words in it, like a blog or article or a discussion forum, etc.
For example:
TAG CLOUD of http://www.google.co.in

TAG CLOUD of http://www.wikipedia.org
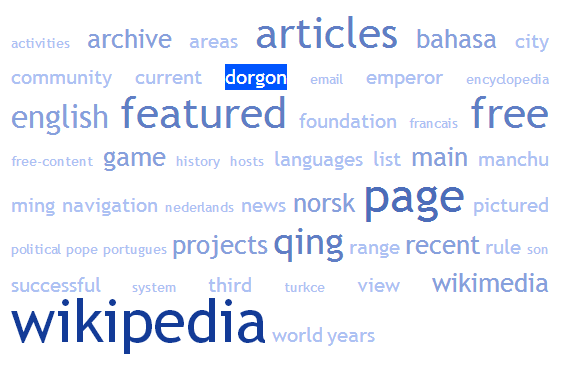
TAG CLOUD of http://www.w3schools.com

It is clear how tag cloud can highlight the key words which could describe a given URL.
Now these keywords are stored in a database and then used to find the relevant URL for given keywords.
Background
It all started when my friend showed me his search engine with 4 URLs in an XML file. It seemed like an auto complete rather than a search engine, but later that night it was 2:00 am, and I couldn't sleep at all because of that auto complete feature with which I was too impressed. I wanted my own... there was a thunder storm of ideas in my mind. After 3 sleepless nights, on the 3rd day at 6:00 a.m., I was ready with my search engine working with 100 URLs in database... that was the time when I finally slept comfortably and full of satisfaction. It took me 3 days because every day I started from the beginning because I was not satisfied with the performance of the crawler or there was some problem.
Using the Code
I have basically divided every task into small parts so that the work could become easy. So you would find lots of classes in the project.
Some important classes are given below:
Panda-> It retrieves the source code of a given URL using aget_sourcecode(url)from Module 'func' and then passes it tojuicer(class) for extracting the useful information and after the work is completed, reports to thepanda_manger(boss of all thepandas) and again assigns a new job topandaif any.panda_manger-> It manages all thepandas and from this class we assign any web URL for crawling and it will automatically assign this work to any freepandaand if nopandais free, then it creates a newpandaand assigns the work to it. When apandafinishes, it works and reports back topanda_mangerthenpanda_mangerchecks whether there is any URL left to be crawled, if any then it gives the command to crawl that URL to thepanda.juicer->This could be said to be the main class for the whole crawler which extracts keywords from the source code of any website and then saves it into the database.juicer->extract_juice-> This class gets the source code and then converts it intoHtmlAgilityPack.HtmlDocumentusing the methodLoadHtml(source). It is used because we need an HTML parser to scrap the text out of HTML (building a custom one will require a lot of time) and since it supports xpath for retrieving any element(s) from source, it simplifies our work a lot.
Now we pass theHtmlDocument.DocumentNode(.SelectNodes)to the various methods of this class for extraction of some type of information.
Dim doc As New HtmlAgilityPack.HtmlDocument() doc.LoadHtml(source) process_texttag(doc.DocumentNode.SelectNodes("//meta")) prcess_anchor(doc.DocumentNode.SelectNodes("//a")) process_image(doc.DocumentNode.SelectNodes("//img"))juicer->process_metatag-> Currently, it just processes the meta tag containing keywords and then assigns every word a 45% to total word count in the document and 30% of total word count to the words which are mentioned in the keywords but can't be found in the document.juicer->process_anchor->This is the most important part if you want the search engine to automatically move to the next link without manually entering every link to the crawler and the hardest part was to convert the relative URL to absolute URL. But Microsoft saved me with the URI class which can easily be used to convert the URI.
Database Structure
At the starting point, we have a 4 tables stored in a database named as "Crawler" by default.
Table Name : "Keyword_index"
This table is used to provide the suggested result in the search box. It contains all the words which the crawler has encountered till now and no word is repeated.


For multiple keywords, we first break the keyword from " ", then find the urlhash for the word and then find what the other words are that urlhashes contain and show the words. {Not yet implemented because I was getting an unidentified error and if I used SQL join, then it took more than 1 minute to search the database for 1 keyword and time increased exponentially.}
Table Name :"Keyword_list"
This table contains all the words in a tag cloud of the given URL. And to identify this word belongs to which URL, we store the urlhash of that website with the word.


Table Name :"url_webpage"
This table is used to store all the links which it finds in the pages that it crawled till now. In this table, we also use MD5 hash of URL to refer to that URL instead of the original URL because no one knows how long the URL which we may find can be. So we change it to MD5 because it does not mater how long the URL is, the MD5 will always be 32 chars long.


Table Name : "url_image"
This table is used to store all the links of the image which are found in the webpage it crawls. It will be used for image search, but I have not yet completed its processing and front end(PHP code).
So I will not discuss it right now. But I would like to tell that it will take a lot of processing power.

How the Crawler Works
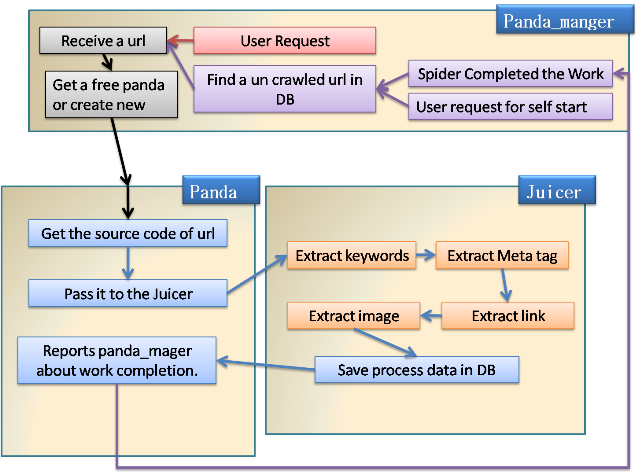
Points of Interest
It was very annoying to get rid of the relative URL. I tried several ways of resolving it, but every one ends up with some bug. Then I got a magic class, named as URI which solved all my problems, but while writing this article I should crawl codeproject.com and show the result for CodeProject search, but then a problem hit my crawler after identifying that I have deleted my database of URL, otherwise I would have posted a screenshot of that. It was something like /search.aspx (some text)(same text repeated again)(and again, increasing with each crawl). It may be a problem with my code. I will try later to identify this problem and post the solution.
Currently Crawler is not following robots.txt so be careful while crawling.
It is you responsibility if crawling a site which is not to be crawled.
Sorry, but currently i am working on a new model of crawler.