
Dynamic Programming or How to Use Previous Computation Experience
4.60/5 (4 votes)
A walkthrough of dynamic programming
Introduction to Dynamic Programming
The term Dynamic Programming was first used by the famous American mathematician, one of the leading specialists in computer technology, Richard Bellman, back in the 1950s. Dynamic Programming (DP) is a method of solving complex tasks by breaking them down into smaller sub-problems.

The kind of problems that DP can solve must meet two criteria:
1. Optimal substructure. In dynamic programming means that the solution for smaller sub-problems can be used to solve the initial one. The optimal substructure is the main characteristic of the “Divide and Conquer” paradigm.
A classic example of implementation is the merge sort algorithm, in which we recursively break the problem down into the simplest sub-problems (size 1 arrays), after which we make calculations based on each one. The results are used to solve the next layer(larger sub-problems) up until the initial layer is achieved.
2. Overlapping sub-problems. In computer science, a problem is said to have overlapping subproblems if the problem can be broken down into subproblems which are reused several times. In other words running the same code with the same input data and the same results. A classic example of this problem is the calculation of an N-th element in a Fibonacci sequence, which we will look at below.
You could say that DP is a special case of the use of the Divide and Conquer paradigm, or a more complex version of it. The pattern is well suited for solving tasks involving combinatorics, where a large number of different combinations are calculated, but the N-quantity of elements is frequently monotonous and identical.
In the problems of optimal substructure and overlapping sub-problems, we have numerous repeat calculations and operations, if we apply a brute-force approach. DP helps us optimize the solution, and avoid the doubling of computation by using two main approaches: memoization and tabulation:
1. Memoization (top-down approach) is implemented through recursion. A task is broken down into smaller sub-problems, their results are fed into a memory and combined to solve the original problem through repeated use.
- Cons: This approach uses stack memory through recursive method calls
- Pros: Flexibility toward DP tasks.
2. Tabulation (bottom-up approach) is implemented using an iterative method. Sub-problems from the smallest to the initial are calculated in succession, iteratively.
- Cons: limited range of application. This approach requires an initial understanding of the entire sequence of sub-problems. But in some problems, this is not feasible.
- Pros: efficient memory use, as everything is run within a single function.
The theory may sound tedious and incomprehensible — let’s look at some examples.
Problem: Fibonacci Sequence
A classic example of DP is calculating an N-th element in a Fibonacci sequence, where each element is the sum of the two preceding ones, and the first and second elements are equal to 0 and 1.
By hypothesis, we initially focus on the nature of the optimal substructure, as, in order to calculate one value, we need to find the preceding one. To calculate the preceding value, we need to find the one that came before that, and so on. The nature of overlapping subtasks is illustrated in the diagram below.
For this task, we will be looking at three cases:
- Straightforward approach: what are the minuses?
- An optimized solution using memoization
- An optimized solution using tabulation
Straightforward/Brute-force Approach
The first thing you might think of is to enter the recursion, sum up the two preceding elements, and give their result.
/**
* Straightforward(Brute force) approach
*/
fun fibBruteForce(n: Int): Int {
return when (n) {
1 -> 0
2 -> 1
else -> fibBruteForce(n - 1) + fibBruteForce(n - 2)
}
}
On the screen below, you can see a stack of function calls, to calculate the fifth element in the sequence.

Note that the function fib(1) is called five times, and fib(2) three times. Functions with one signature, with the same parameters, are launched repeatedly, and do the same thing. When the N number is increased, the tree increases, not linearly, but exponentially, which leads to a colossal duplication of calculations.
Math Analysis:
Time Complexity: O(2n),
Space Complexity: O(n) -> proportionate to the maximum depth of the recursive tree, as this is the maximum number of elements that can be present in the stack of implicit function calls.
Result: This approach is extremely inefficient. For example, 1,073,741,824 operations are needed to calculate the 30th element.
Memoization (Top-Down Approach)
In this approach, implementation is not all that different from the foregoing “brute-force” solution, except allocation of memory. Let it be the variable memo, in which we collect the results of the calculations of any completed fib() function in our stack.
It should be noted that it would have been sufficient to have an array of integers and refer to it by index, but, for the sake of conceptual clarity, a hash map was created.
/**
* Memoization(Top-down) approach
*/
val memo = HashMap<Int, Int>().apply {
this[1] = 0
this[2] = 1
}
fun fibMemo(n: Int): Int {
if (!memo.containsKey(n)) {
val result = fibMemo(n - 1) + fibMemo(n - 2)
memo[n] = result
}
return memo[n]!!
}
Let’s focus again on the function call stack:

- The first completed function that writes the result in the memo is the highlighted
fib(2). It returns control to the highlightedfib(3). - The highlighted
fib(3)finds its value after summing up the results of thefib(2)andfib(1)calls, enters its solution in the memo and returns control tofib(4). - We have reached the stage for reusing earlier experience — when control is returned to
fib(4), thefib(2)call awaits its turn in it.fib(2)in turn, instead of calling (fib(1) + fib(0)), uses the entire finished solution from the memo, and returns it straightaway. fib(4)is calculated and returns control tofib(5), which only has to launchfib(3). In the last analogy,fib(3)immediately returns a value from the memo without calculations.
We can observe a reduction in the number of function calls and calculations. Also, when N is increased, there will be exponentially fewer reductions.
Math Analysis:
Time Complexity: O(n)
Space Complexity: O(n)
Result: There is a clear difference in asymptotic complexity. This approach has reduced it to being linear in time, in comparison to the primitive solution, and has not increased it in memory.
Tabulation (bottom-up approach)
As mentioned above, this approach involves iterative calculation from a smaller to a larger sub-problem. In the case of Fibonacci, the smallest “sub-problems” are the first and second elements in the sequence, 0 and 1, respectively.
We are well aware of how the elements relate to each other, which is expressed in the formula: fib(n) = fib(n-1) + fib(n-2). Because we know the preceding elements, we can easily work out the next one, the one after that, and so on.
By summing up the values we are aware of, we can find the next element. We implement this operation cyclically until we find the desired value.
/**
* Tabulation(Bottom-up) approach
*/
fun fibTab(n: Int): Int {
var element = 0
var nextElement = 1
for (i in 2 until n) {
val newNext = element + nextElement
element = nextElement
nextElement = newNext
}
return nextElement
}
Math Analysis:
Time Complexity: O(n)
Space Complexity: O(1)
Result: This approach is just as effective as memoization in terms of speed, but it uses up a constant amount of memory.
Problem: Unique Binary Trees
Let’s look at a more complex problem: we need to find the number of all structurally unique binary trees that can be created from N nodes.
A binary tree is a hierarchical data structure, in which each node has no more than two descendants. As a general rule, the first is called a parent node, and has two children — the left child and the right child.
Let’s assume that we need to find a solution for N = 3. There are 5 structurally unique trees for the three nodes. We can count them in our head, but if the N is increased, the variations would escalate immensely, and visualizing these in our head would be impossible.
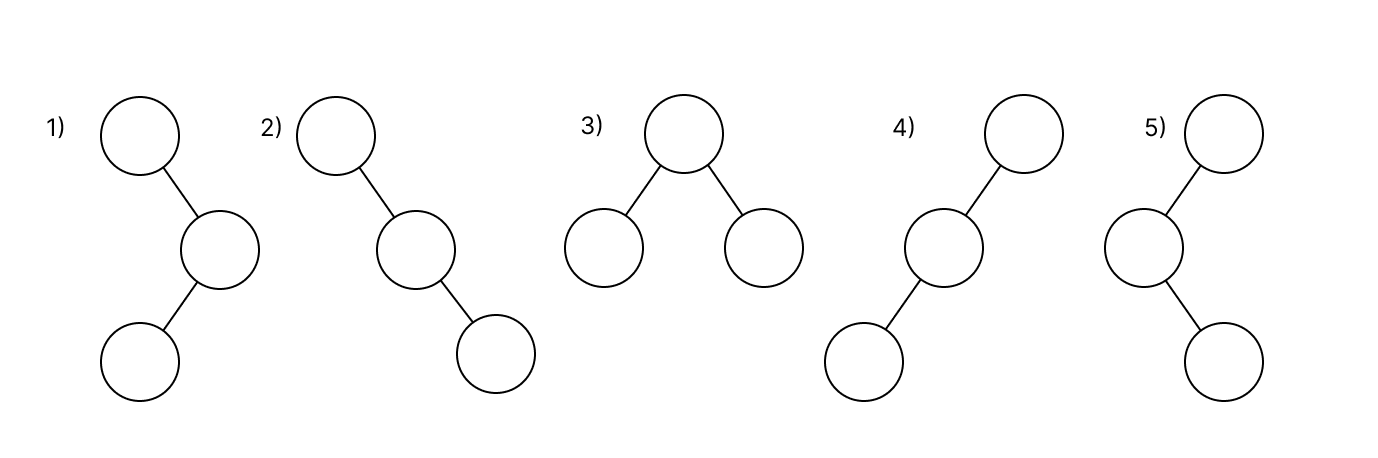
This task could be ascribed to combinatorics. Let’s work out which combinations can be formed, and how we can find a pattern for their formation.
- Each tree starts from the top node (Vertex of the Tree). The tree then expands in depth.
- Each node is the start of a new child tree (subtree), as shown on the screen. The left subtree is colored green, and the right — red. Each one has its own vertex.

Let’s look at an example of a task, where N = 6 at the conceptual level. We’ll call our calculation function numOfUniqueTrees(n: Int).
In our example, 6 nodes are given, one of which, according to the principle mentioned earlier, forms the vertex of the tree, and the other 5 — the remainder.
From now on, we interact with the remaining nodes. This can be done in various ways. For example, by using all five nodes to form the left subtree or sending all five to the right subtree. Or by dividing the nodes into two — 2 to the left and 3 to the right (see screen below), we have a limited number of such variants.

To achieve the result numOfUniqueTrees(6), we need to consider all variants for distributing our nodes. They are shown in the table:

The table shows 6 different distributions of the nodes. If we find how many unique trees can be generated for each distribution and sum these up, we will achieve our final result.
How to find the number of unique trees for distribution?
e have two parameters: Left Nodes and Right Nodes (left and right column in the table).
The result will be equal to: numOfUniqueTrees(leftNodes) * numOfUniqueTrees(rightNodes).
Why? On the left, we will have X unique trees, and for each, we will be able to put Y unique variations of trees on the right. We multiply these to get the result.
So Let's Find Out Variations for the First Distribution (5 Left, 0 right).
numOfUniqueTrees(5) * numOfUniqueTrees(0), as we have no nodes on the right. The result is numOfUniqueTrees(5) — the number of unique subtrees on the left with a constant right.

Calculating numOfUniqueTrees(5).
Now we have the smallest sub-problem. We will be operating with it as we did with the larger one. At this stage, the characteristic of the DP tasks is clear — optimal substructure, recursive behavior.
One node (the green node) is sent to the vertex. We distribute the remaining (four) nodes in a way that is analogous to previous experience (4:0), (3:1), (2:2), (1:3), (0:4).
We calculate the first distribution (4:0). It is equal to numOfUniqueTrees(4) * numOfUniqueTrees(0) -> numOfUniqueTrees(4) by earlier analogy.

Calculating numOfUniqueTrees(4). If we allocate a node to the vertex, we have 3 remaining.
Distributions (3:0), (2:1), (1:2), (0:3).
For 2 nodes there are only two unique binary trees, for 1 — one. Previously we've already mentioned that there are 5 variations of unique binary trees for three nodes.
As a result — distributions(3:0), (0:3) are equal to 5, (2:1), (1:2) — 2.
If we sum up 5 + 2 + 2 + 5, we get 14. numOfUniqueTrees(4) = 14.
Let’s enter the result of the calculation in the variable memo according to the experience of memoization. Whenever we need to find variations for four nodes, we will not calculate them again, but reuse earlier experience.
Let’s return to the calculation (5:0), which is equal to the sum of the distributions (4:0), (3:1), (2:2), (1:3), (0:4). We know that (4:0) = 14. Let’s turn to the memo, (3:1) = 5, (2:2) = 4 (2 variations on the left * 2 on the right), (1:3) = 5, (0:4) = 14. If we sum these up, we get 42, numOfUniqueTrees(5) = 42.
Let’s return to the calculation of numOfUniqueTrees(6), which is equal to the sum of the distributions
(5:0) = 42, (4:1) = 14, (3:2) =10 (5 left * 2 right), (2:3) = 10, (1:4) = 14, (0:5) = 42. If we sum these up, we get 132, numOfUniqueTrees(5) = 132.
Task solved!
Result: Let’s note the overlapping sub-problems in the solution where N = 6. In the straightforward solution, the numOfUniqueTrees(3) would be called 18 times (screen below). With increasing N, repeats of same computation would be far greater.

I highlight that the number of unique trees for (5 left, 0 right) and (0 left, 5 right) will be the same. Only in one case they will be on the left, and in the other on the right. This also works for (4 left, 1 right) and (1 left, 4 right).
Memoization, as an approach of dynamic programming, has allowed us to optimize the solution for such a complex task.
Implementation
class Solution {
fun numTrees(n: Int): Int {
val memo = arrayOfNulls<Int>(n+1)
return calculateTees(n, memo)
}
fun calculateTees(n: Int, memo:Array<Int?>): Int {
var treesNum = 0
if(n < 1) return 0
if(n == 2) return 2
if(n == 1) return 1
if(memo[n]!=null)
return memo[n]!!
for (i in 1..n){
val leftSubTrees = calculateTees( i - 1, memo)
val rightSubTrees = calculateTees(n - i, memo)
treesNum += if(leftSubTrees>0 && rightSubTrees>0){
leftSubTrees*rightSubTrees
} else
leftSubTrees+leftSubTrees
}
memo[n] = treesNum
return treesNum
}
}

Conclusion
In some cases, solving tasks by means of Dynamic Programming can save a vast amount of time and make the algorithm work with maximum efficiency.
Thank you for reading this article to the end. I’d be happy to answer your questions.
History
- 7th February, 2023: Initial version