
Build the Forest in Python Series: Make the Forest Thread-Safe
4.73/5 (4 votes)
Use Python to build atomic binary trees
Multithreading is a common way to improve performance. However, the shared state and data among the threads become vulnerable to corruption if the shared state or data is mutable. The trees we built in the Build the Forest Series are not thread-safe. When multiple threads perform write operations (e.g., insert or delete) simultaneously, the trees are potentially corrupted or built incorrectly. Even read operations may return incorrect results when multiple threads perform write and read operations simultaneously. The topic of this article is to make the trees become thread-safe and discuss the impact of being thread-safe.
Multithreading and GIL in Python
The Global Interpreter Lock (GIL) is the mechanism used by the CPython interpreter (the one we download from the Python official website is CPython) to ensure that only one thread can execute Python bytecode at once. Although GIL assures that only one thread executes Python bytecode at a time, it does not mean that the Python programs we write are thread-safe automatically. That’s because the protection only happens on the bytecode level. For example, the following code snippet is the partial disassembly bytecode from the AVL tree’s insertion function. (Note that we can use dis module to disassembly Python bytecode.)
Disassembly of <code object insert at 0x7f136b391920,
file "forest/binary_trees/avl_tree.py", line 112>:
128 0 LOAD_GLOBAL 0 (Node)
2 LOAD_FAST 1 (key)
4 LOAD_FAST 2 (data)
6 LOAD_CONST 1 (('key', 'data'))
8 CALL_FUNCTION_KW 2
10 STORE_FAST 3 (new_node)
129 12 LOAD_CONST 2 (None)
14 STORE_FAST 4 (parent)
130 16 LOAD_FAST 0 (self)
18 LOAD_ATTR 1 (root)
20 STORE_FAST 5 (current)
…
147 >> 128 LOAD_FAST 3 (new_node)
130 LOAD_FAST 4 (parent)
132 STORE_ATTR 4 (right)
154 >> 134 LOAD_FAST 4 (parent)
136 LOAD_ATTR 3 (left)
138 POP_JUMP_IF_FALSE 146
140 LOAD_FAST 4 (parent)
142 LOAD_ATTR 4 (right)
144 POP_JUMP_IF_TRUE 156
155 >> 146 LOAD_FAST 0 (self)
148 LOAD_METHOD 8 (_insert_fixup)
150 LOAD_FAST 3 (new_node)
152 CALL_METHOD 1
154 POP_TOP
…
When multiple threads invoke the AVL tree’s insert function, the Python interpreter may switch out one thread before the thread executes _insert_fixup (i.e., 148 LOAD_METHOD) instruction. At the same time, another thread comes along and performs some bytecode instructions of the insertion function. Whether the insertion completes, the second thread interrupts the previous insertion function. This scenario may result in an incorrect AVL tree, or even worse, the program crushes.
Thread-Unsafe Example
Following the discussion above, there are two scenarios multithreading may become unsafe: write contention and read-write contention. The former means multiple write operations manipulate shared mutable resources simultaneously; the latter means read operations are reading some resources that write operations are updating simultaneously.
Scenario 1 – Write Contention
To simulate the scenario, we need to perform some write operations concurrently. In this example, we will use five threads to insert 500 non-duplicated data simultaneously. For instance, the first thread inserts data from 0 to 99, the second thread inserts data from 100 to 199, and so on. After all the insertions are complete, the total number of nodes added will be 500.
Switch Interval
Since Python 3.2, the setswitchinterval function was introduced, which allows us to set the interpreter’s thread switch interval. The value determines the duration of the timeslices allocated to concurrently running threads. To make the multithreading issues (e.g., race condition) happen easily, we use the setswitchinterval function to reduce the switch interval to a tiny value so that the thread switch will occur much quickly between bytecode instructions.
The following code is the example to simulate the issue using the AVL tree we built in Build the Forest Series: AVL Tree.
Thread-Unsafe Example Code
import threading
import sys
from typing import List
from forest.binary_trees import avl_tree
from forest.binary_trees import traversal
# Use a very small thread switch interval to increase the chance that
# we can reveal the multithreading issue easily.
sys.setswitchinterval(0.0000001)
def insert_data(tree: avl_tree.AVLTree, data: List) -> None:
"""Insert data into a tree."""
for key in data:
tree.insert(key=key, data=str(key))
def multithreading_simulator(tree: avl_tree.AVLTree) -> None:
"""Use five threads to insert data into a tree with non-duplicate data."""
try:
thread1 = threading.Thread(
target=insert_data, args=(tree, [item for item in range(100)])
)
thread2 = threading.Thread(
target=insert_data, args=(tree, [item for item in range(100, 200)])
)
thread3 = threading.Thread(
target=insert_data, args=(tree, [item for item in range(200, 300)])
)
thread4 = threading.Thread(
target=insert_data, args=(tree, [item for item in range(300, 400)])
)
thread5 = threading.Thread(
target=insert_data, args=(tree, [item for item in range(400, 500)])
)
thread1.start()
thread2.start()
thread3.start()
thread4.start()
thread5.start()
thread1.join()
thread2.join()
thread3.join()
thread4.join()
thread5.join()
result = [item for item in traversal.inorder_traverse(tree=tree)]
incorrect_node_list = list()
for index in range(len(result)):
if index > 0:
if result[index] < result[index - 1]:
incorrect_node_list.append(
f"{result[index - 1]} -> {result[index]}"
)
if len(result) != 500 or len(incorrect_node_list) > 0:
print(f"total_nodes: {len(result)}")
print(f"incorrect_order: {incorrect_node_list}")
except:
print("Tree built incorrectly")
if __name__ == "__main__":
tree = avl_tree.AVLTree()
multithreading_simulator(tree=tree)
After the threads insert 500 data (from 0 to 499), this example does a few checks:
- If the total node count is 500.
- If the output from the in-order traversal is in order.
- No exception.
If any of these checks fail, the tree is not built correctly. Therefore, we proved that the previously implemented AVL tree is not thread-safe.
If we run the example enough times (multithreading issues are timing issues; they may not always happen), the checks will eventually fail and look like the sample below.
total_nodes: 454
incorrect_order: ["(459, '459') -> (319, '319')"]
Or Tree built incorrectly if any exception raised.
The same situation applies to all other trees we previously built in the Build the Forest Series. The complete thread-unsafe code is available at multithreading_not_safe.py.
Scenario 2 – Read-Write Contention
Although read operations do not modify the state of any resources, the state may be affected by write operations while a read operation is reading. For example, thread A is searching for a node N while thread B is deleting node M and during the deleing process, thread B also move node N to a different location. In this case, thread A could fail to find node N. The following code simulates this situation.
import threading
import sys
from typing import Any, List
from forest.binary_trees import avl_tree
# Use a very small thread switch interval to increase the chance that
# we can reveal the multithreading issue easily.
sys.setswitchinterval(0.0000001)
flag = False # Flag to determine if the read thread stops or continues.
def delete_data(tree: avl_tree.AVLTree, data: List) -> None:
"""Delete data from a tree."""
for key in data:
tree.delete(key=key)
def find_node(tree: avl_tree.AVLTree, key: Any) -> None:
"""Search a specific node."""
while flag:
if not tree.search(key):
print(f" Fail to find node: {key}")
def multithreading_simulator(tree: avl_tree.AVLTree, tree_size: int) -> None:
"""Use one thread to delete data and one thread to query at the same time."""
global flag
flag = True
delete_thread = threading.Thread(
target=delete_data, args=(tree, [item for item in range(20, tree_size)])
)
query_node_key = 17
query_thread = threading.Thread(target=find_node, args=(tree, query_node_key))
delete_thread.start()
query_thread.start()
delete_thread.join()
flag = False
query_thread.join()
print(f"Check if the node {query_node_key} exist?")
if tree.search(key=query_node_key):
print(f"{query_node_key} exists")
if __name__ == "__main__":
print("Build an AVL Tree")
tree = avl_tree.AVLTree()
tree_size = 200
for key in range(tree_size):
tree.insert(key=key, data=str(key))
print("Multithreading Read/Write Test")
multithreading_simulator(tree=tree, tree_size=tree_size)
In this example, we first build a tree with 200 nodes and then use one thread to continue searching for node 17 while another thread deletes nodes from 20 to 200. Since the example does not delete node 17, the search thread should find node 17 all the time. Also, after the delete thread finishes, we query node 17 again to make sure node 17 still exists in the tree. If at any moment, the search thread cannot find node 17, that means we prove the previously implemented AVL tree is not thread-safe in the read-write contention situation. And it’s easy to happen when we run the example enough times. When that happens, the following output will show.
Build an AVL Tree
Multithreading Read/Write Test
Fail to find node: 17
Check if node 17 exist?
17 exists
Project Setup
Following the same style and assumption as other articles in the Build the Forest Series, the implementation assumes Python 3.9 or newer. This article adds two modules to our project: atomic_trees.py for the atomic trees’ implementation and test_automic_trees.py for unit tests. After adding these two files, our project layout becomes the following:
forest-python
├── forest
│ ├── __init__.py
│ ├── binary_trees
│ │ ├── __init__.py
│ │ ├── atomic_trees.py
│ │ ├── avl_tree.py
│ │ ├── binary_search_tree.py
│ │ ├── double_threaded_binary_tree.py
│ │ ├── red_black_tree.py
│ │ ├── single_threaded_binary_trees.py
│ │ └── traversal.py
│ ├── metrics.py
│ └── tree_exceptions.py
└── tests
├── __init__.py
├── conftest.py
├── test_atomic_trees.py
├── test_avl_tree.py
├── test_binary_search_tree.py
├── test_double_threaded_binary_tree.py
├── test_metrics.py
├── test_red_black_tree.py
├── test_single_threaded_binary_trees.py
└── test_traversal.py
(The complete code is available at forest-python.)
Build Atomic Trees
To make the Forest thread-safe, we need to prevent write contention and read-write contention.
What Do We Want to Protect?
The first thing we may ask is what to protect? In general, we need to cover any shared mutable state and data. A tree data structure is a composite with tree nodes. Any change to a node updates the tree’s state, and tree nodes are shared and mutable. Therefore, to be thread-safe, we need to ensure the transition of tree nodes is not interruptible.
What Could Change the State?
In general, we don’t need to worry about read-only operations because read operations do not modify anything. Only two functions will change the state of the trees we built in the series: insertion and deletion. Take the AVL tree’s insertion as an example. The following picture highlights the nodes touched after we insert a node 35.
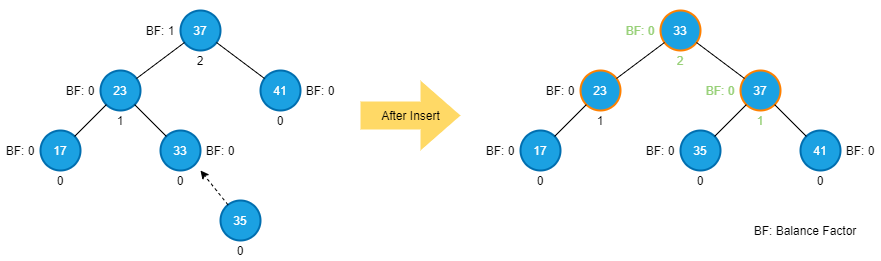
From this example, we can see that multiple nodes are updated during the insertion operations. If there is any other thread that touches these nodes (I.e., 23, 33, and 37) or modifies other nodes that also affect the properties (e.g., height and balance factor) of the nodes, 22, 33, and 37 during the insertion, the insertion will produce an incorrect AVL tree or worse – the program crushes.
The same scenario can be applied to deletion as well. Therefore, we need to ensure that both insertion and deletion can complete without any interference. In other words, the insertion and deletion functions are the critical section that cannot be executed by more than one thread simultaneously.
How About Fixup, Transplant, and Rotation Functions?
These functions also update trees’ state. However, their purpose is to support the insertion and deletion, and that’s why they are defined as internal functions (i.e., a client code should not call them directly). As long as we ensure that we perform the insertion or deletion one at a time, these auxiliary functions are accessed by one single thread at a time only – no need to protect them.
How to Protect?
One common solution to prevent simultaneous access to a shared resource is mutual exclusion. We can use Python’s built-in Lock Objects to protect a critical section: a thread needs to acquire a lock before entering a critical section and release the lock after leaving the critical section. Use the AVL tree’s insertion as an example. We can update the insertion algorithm to be thread-safe as the following:
- Acquire a lock.
- Insert the new node with the height 0 in the same way as the binary search tree insertion: find the proper location (i.e., the parent of the new node) to insert the new node by walking through the tree from the root and comparing the new node’s key with each node’s key along the way.
- Update the height and check if the violated AVL-tree-property happens by traceback from the new node to the root. While traveling back to the root, update each node’s height on the way if necessary. If we find an unbalanced node, perform certain rotation(s) to balance it. After the rotation, the insertion concludes. If no unbalanced node is found, the insertion completes after reaching the root and updating its height.
- Release the lock.
The second and third steps are critical sections and are now protected by the lock mechanism. Since the atomic insertion function does not change its original functionality, we can implement the atomic AVL tree as a derived class from the original AVL tree and extend the insertion like the following.
import threading
from typing import Any, Optional
from forest.binary_trees import avl_tree
class AVLTree(avl_tree.AVLTree):
def __init__(self, registry: Optional[metrics.MetricRegistry] = None) -> None:
avl_tree.AVLTree.__init__(self, registry=registry)
self._lock = threading.Lock() # The lock object
def insert(self, key: Any, data: Any) -> None:
self._lock.acquire()
# The original insertion function is the critical section, and
# is protected by the lock.
avl_tree.AVLTree.insert(self, key=key, data=data)
self._lock.release()
Using Locks in the with-statement
One good practice in Python programming is that if a code block needs to manage resources (e.g., open/close a file or acquire/release a lock), we should always use the with-statement context manager. The code block wrapped with the with statement is guaranteed to release the resource (e.g., locks), even if an exception is thrown within the with-statement (See using locks in the with-statement for more detail). With the best practice in mind, we can update the above implementation by utilizing the with-statement to manage the lock resource. We can also protect the deletion in the same way. Besides, the syntax also simplifies the implementation like the following.
import threading
from typing import Any, Optional
from forest.binary_trees import avl_tree
class AVLTree(avl_tree.AVLTree):
def __init__(self, registry: Optional[metrics.MetricRegistry] = None) -> None:
avl_tree.AVLTree.__init__(self, registry=registry)
self._lock = threading.Lock()
def insert(self, key: Any, data: Any) -> None:
with self._lock:
avl_tree.AVLTree.insert(self, key=key, data=data)
def delete(self, key: Any) -> None:
with self._lock:
avl_tree.AVLTree.delete(self, key=key)
How about the read-write contention?
So far, the change we made above protects the tree from the write contention situation, but it does not prevent the read-write contention. The simplest solution is the same as the insertion and deletion functions – using the lock mechanism. However, a deadlock situation may occur if we don’t use the lock mechanism carefully. The picture below shows the case. The left-hand side is the atomic AVL tree with a lock in the search function, and the right side is the original AVL tree from which the atomic AVL tree derives.
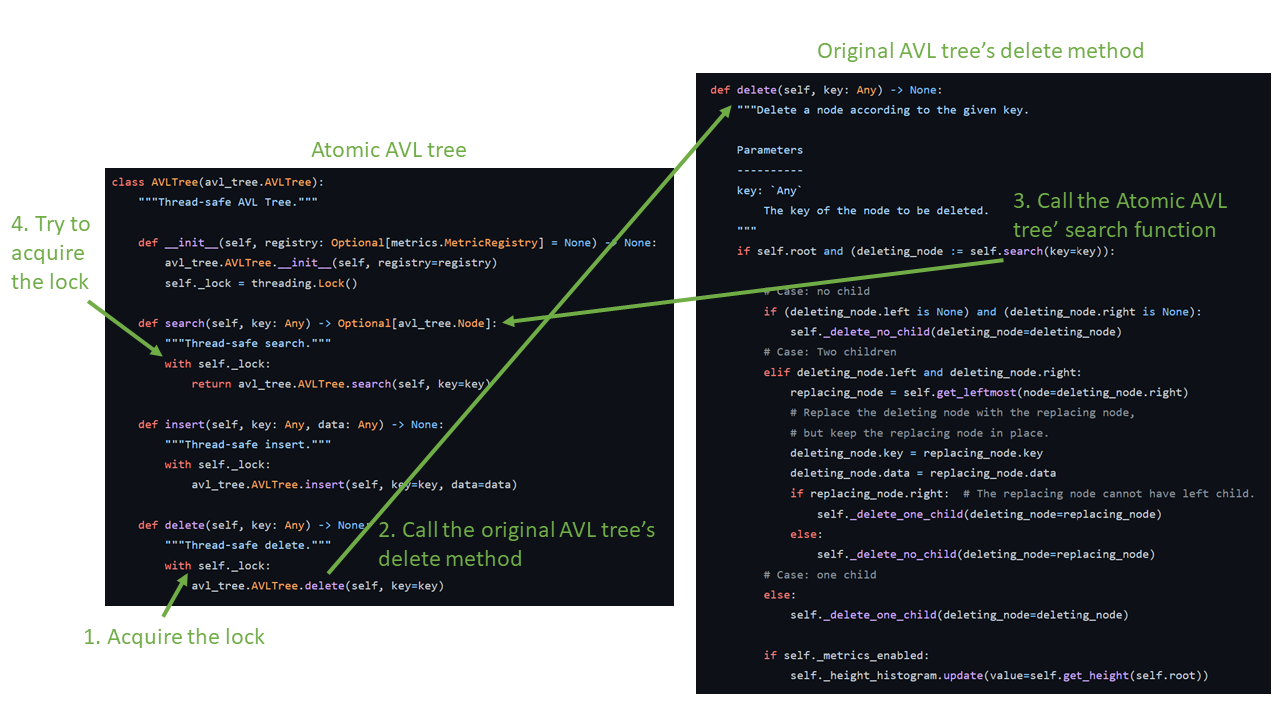
When a client calls the atomic AVL tree’s delete function, it first acquires the lock and then calls its parent’s delete function (i.e., the delete function from the original AVL tree). When we implemented the original AVL tree’s delete function, we leveraged the tree’s search function to identify the node to be deleted. However, since the delete function is invoked from the atomic AVL tree (i.e., the derived class), the search function to be invoked will be the atomic AVL tree’s search function. And the first thing the atomic AVL tree’s search tries to do is acquire the lock, which will never happen because the caller (i.e., the atomic AVL tree’s delete function) still holds the lock. That’s how the deadlock occurred.
There are many ways to deal with the deadlock situation. The solution we are to use is separating the search function’s interface and implementation in the original AVL tree – the new _search function contains the search implementation, and the interface search function calls _search function like the code snippet below.
def search(self, key: Any) -> Optional[Node]:
return self._search(key=key)
def _search(self, key: Any) -> Optional[Node]:
current = self.root
while current:
if key < current.key:
current = current.left
elif key > current.key:
current = current.right
else: # Key found
return current
return None
Any method that needs to call the search function will call the implementation function _search instead of the interface search. Therefore, the delete function of the original AVL tree becomes the following.
def delete(self, key: Any) -> None:
if self.root and (deleting_node := self._search(key=key)):
# The rest of the code remains the same
…
A few reasons to do so. First of all, since the interface remains the same, a client code that calls the original AVL tree will not be affected. Second, we avoid duplication of code. Third, we simplify the implementation of the thread-safe search function of the atomic AVL tree. The following is the atomic AVL tree implementation.
class AVLTree(avl_tree.AVLTree):
"""Thread-safe AVL Tree."""
def __init__(self, registry: Optional[metrics.MetricRegistry] = None) -> None:
avl_tree.AVLTree.__init__(self, registry=registry)
self._lock = threading.Lock()
def search(self, key: Any) -> Optional[avl_tree.Node]:
"""Thread-safe search."""
with self._lock:
return avl_tree.AVLTree.search(self, key=key)
def insert(self, key: Any, data: Any) -> None:
"""Thread-safe insert."""
with self._lock:
avl_tree.AVLTree.insert(self, key=key, data=data)
def delete(self, key: Any) -> None:
"""Thread-safe delete."""
with self._lock:
avl_tree.AVLTree.delete(self, key=key)
The same situation happens to other trees we previously implemented. Therefore, we can apply the same idea to implement the rest of the trees. The complete atomic trees are available at atomic_trees.py, and their parents are also modified by separating the search function’s interface and implementation. See the file changed list for the completed updates.
Test
We should always have unit tests for our code as much as possible. Since we have proved that the original AVL tree (using the AVL tree as an example) is not thread-safe, we could run the same tests to ensure the atomic AVL tree is thread-safe from both write contention and read-write contention. Likewise, we can run the same tests against the rest of the atomic trees. Check the test_atomic_trees.py for the complete unit test.Analysis
Although the atomic trees are thread-safe, using locks comes with a cost. The mechanism forces the critical section (e.g., the insertion and deletion functions) to be accessed sequentially. The motivation of multithreading programming is to have better performance. When a code must run sequentially, we lose the benefit of multithreading. Besides, in the Python world (i.e., CPython specifically), the GIL also plays an essential role in multithreading programming. The GIL diminishes the performance gained from the multithreading approach in some cases. The rest of this section will use the AVL tree (both the original AVL tree (i.e., the non-thread-safe AVL tree) and the atomic AVL tree) to evaluate the performance impact by the lock mechanism and the GIL in multithreading situations.
In addition, we can only compare the search function between the original AVL tree and the atomic AVL tree because the insertion and deletion are not thread-safe in the original AVL tree. To measure the performance impact, we will perform the following actions:
- Define an original AVL tree with 200,000 nodes and search every node with a single thread. And measure the time it takes.
- Use the same AVL tree from step 2 but use two threads to search 200,000 nodes – one thread searches the nodes 0 to 99,999, and the other thread queries 100,000 to 199,999. And measure the time it takes.
- Define an atomic AVL tree with 200,000 nodes and use two threads to search 200,000 nodes. Also, one thread for 0 to 99,999 and the other thread for 100,000 to 199,999. And measure the time it takes.
By comparing the results between step 1 and step 2, we can see the impact of the GIL. And the comparison of the outcome of steps 2 and 3 provides the idea of performance impact by using the lock mechanism. The following is the example code.
import threading
import time
from typing import List
from forest.binary_trees import avl_tree
from forest.binary_trees import atomic_trees
def query_data(tree: avl_tree.AVLTree, data: List) -> None:
"""Query nodes from a tree."""
for key in data:
tree.search(key=key)
def multithreading_simulator(tree: avl_tree.AVLTree, total_nodes: int) -> float:
"""Use two threads to query nodes with different ranges."""
thread1 = threading.Thread(
target=query_data, args=(tree, [item for item in range(total_nodes // 2)])
)
thread2 = threading.Thread(
target=query_data,
args=(tree, [item for item in range(total_nodes // 2, total_nodes)]),
)
start = time.time()
thread1.start()
thread2.start()
thread1.join()
thread2.join()
end = time.time()
return end - start
if __name__ == "__main__":
total_nodes = 200000
original_avl_tree = avl_tree.AVLTree()
# Single thread case
for key in range(total_nodes):
original_avl_tree.insert(key=key, data=str(key))
data = [item for item in range(total_nodes)]
start = time.time()
query_data(tree=original_avl_tree, data=data)
end = time.time()
delta = end - start
print("Single Thread Case")
print(f"Time in seconds: {delta}")
# Multithreads case
delta_with_threads = multithreading_simulator(
tree=original_avl_tree, total_nodes=total_nodes
)
print("Multithread Case")
print(f"Time in seconds: {delta_with_threads}")
# Multithread with lock case
avl_tree_with_lock = atomic_trees.AVLTree()
for key in range(total_nodes):
avl_tree_with_lock.insert(key=key, data=str(key))
delta_with_lock = multithreading_simulator(
tree=avl_tree_with_lock, total_nodes=total_nodes
)
print("Multithread with Lock Case")
print(f"Time in seconds: {delta_with_lock}")
After we run the example, we will get the run-time for each case.
Single Thread Case Time in seconds: 0.3944363594055176 Multithread Case Time in seconds: 0.4100222587585449 Multithread with Lock Case Time in seconds: 2.7478058338165283
(Note that the resulting number varies based on the machines. However, the comparison between the three cases should be similar on any device.)
Here we can see that the performance gain with two threads is significantly limited, or even negative from one thread to two threads (the results from the first and second). By comparing the second and third results, we also realize that the cost of using the lock mechanism is relatively high.
Example
Using the atomic trees is the same as using the original trees. For example, if we would like to use the atomic AVL tree, we need to import the atomic_trees and use the atomic AVL tree in this module like the code snippet below – which is the same as using the original AVL tree.
from forest.binary_trees import atomic_trees
if __name__ == "__main__":
tree = atomic_trees.AVLTree()
tree.insert(key=17, data="data")
tree.insert(key=21, data="other_data")
tree.delete(key=17)
Summary
In this article, we implemented the thread-safe version of binary trees. We also realized that the cost of making things thread-safe is not free. However, the correctness of a program is way more important than its performance. In some cases, we need to sacrifice performance to ensure correctness.