
A Problem Finding Optimal Number of Sentences and Possible Solutions
5.00/5 (3 votes)
We were asked to develop a piece of software which will select an optimal combination of sentences from e-books which will give the closest result to a set of targets for each character.
Introduction
To explain the problem, imagine that we have a list of sentences, for example, a list of 1000 sentences. They are all taken from a selected folder full of PDF e-books.
Our goal was to find a combination of sentences to match/'match closest' a certain frequency table:
[a:100, b:80, c:90, d:150, e:100, f:100, g:47, h:10 ..... z:900]
We tried various methods and algorithms, such as finding all possible combinations from the sentences list by using combinations like in here (so comb(1000, 1); to comb(1000, 1000); ) and then compare every combination with the frequency table, so that distance is minimum. So sum all frequency tables from a possible combination and compare this sum with the target, the combination with the smallest difference with the target should be recorded. There could be multiple combinations that match closest.
The problem is that the calculation of all combinations takes way too long to complete, apparently couple of days. Is there a known algorithm that could solve this efficiently? Ideally couple of minutes maximum?
Background
The purpose of this project was to create a tool whcih will be used to find an optimal set of sentences for a given language, which will represent all characters in that language and will be used to record these spoken sentences as part of a larger project for the blind people.
Application Flow
The application is used in the following way:
- You open the app:
- You set the targets. When you enter a number next to the Set button, it will be automatically inserted as the target of all characters, while rare characters will be given 1/10 of that value. You can then change these targets manually, and individually.
- You select a folder with PDF e-books.
and then the folder path will appear.
- Then you are ready to start. You press the "Go" button and the program starts running...
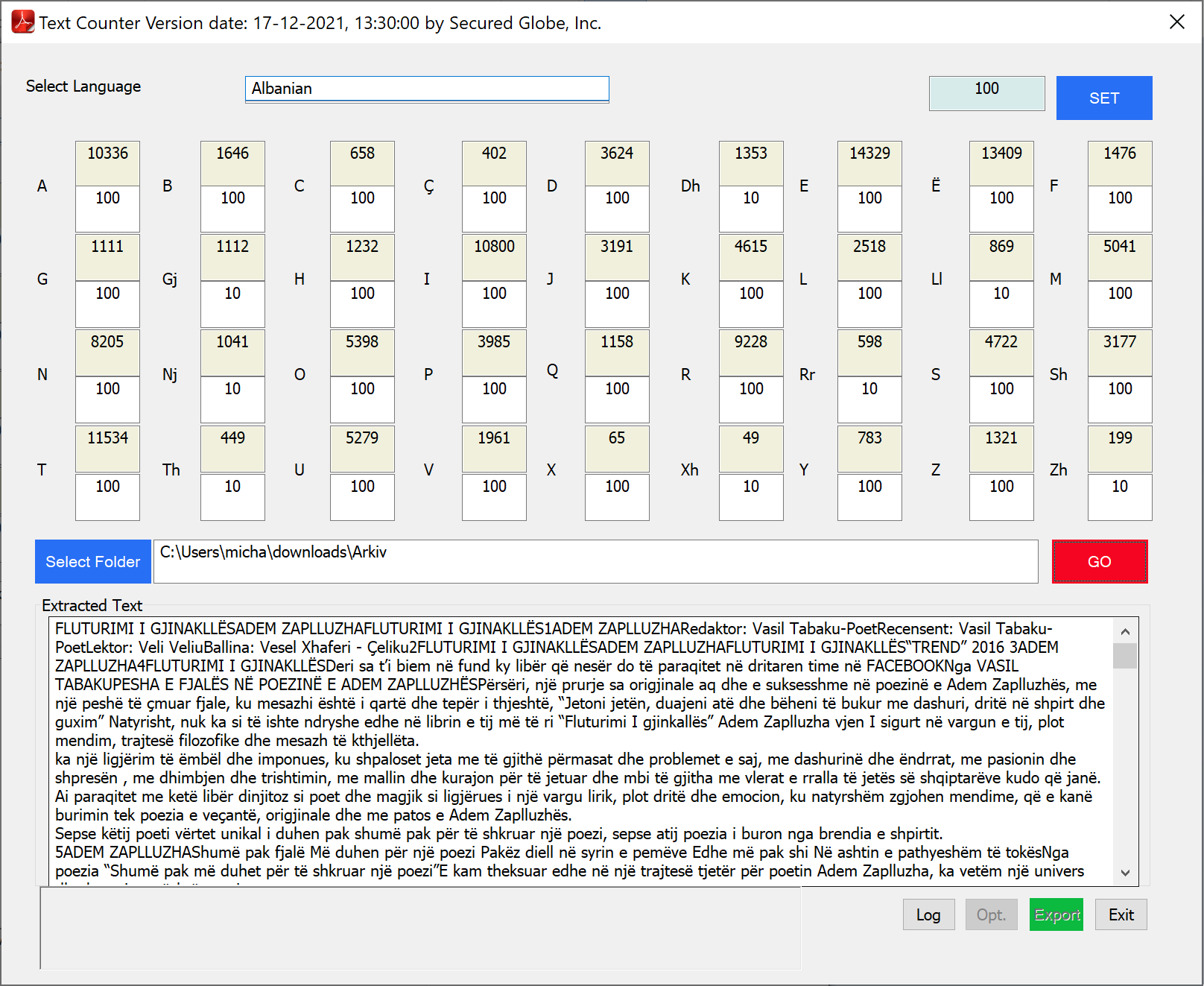
- Optimize the results - when the reading of the books is completed, these books are split into sentences and the characters of them in total, are counted and shown. Then when you press the "Opt" button, you get only some of these sentences which brings you to the closest result to the targets you have set.
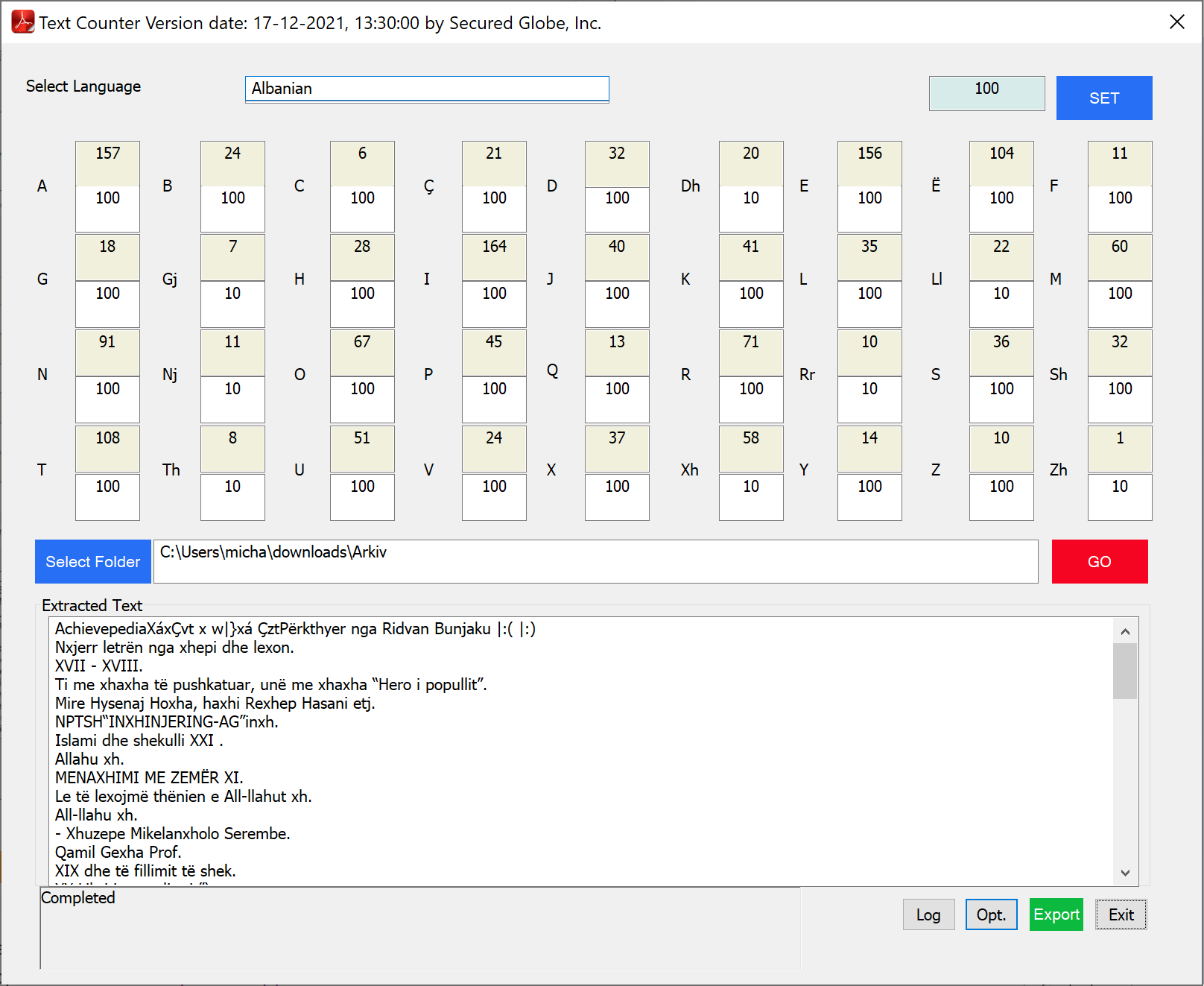
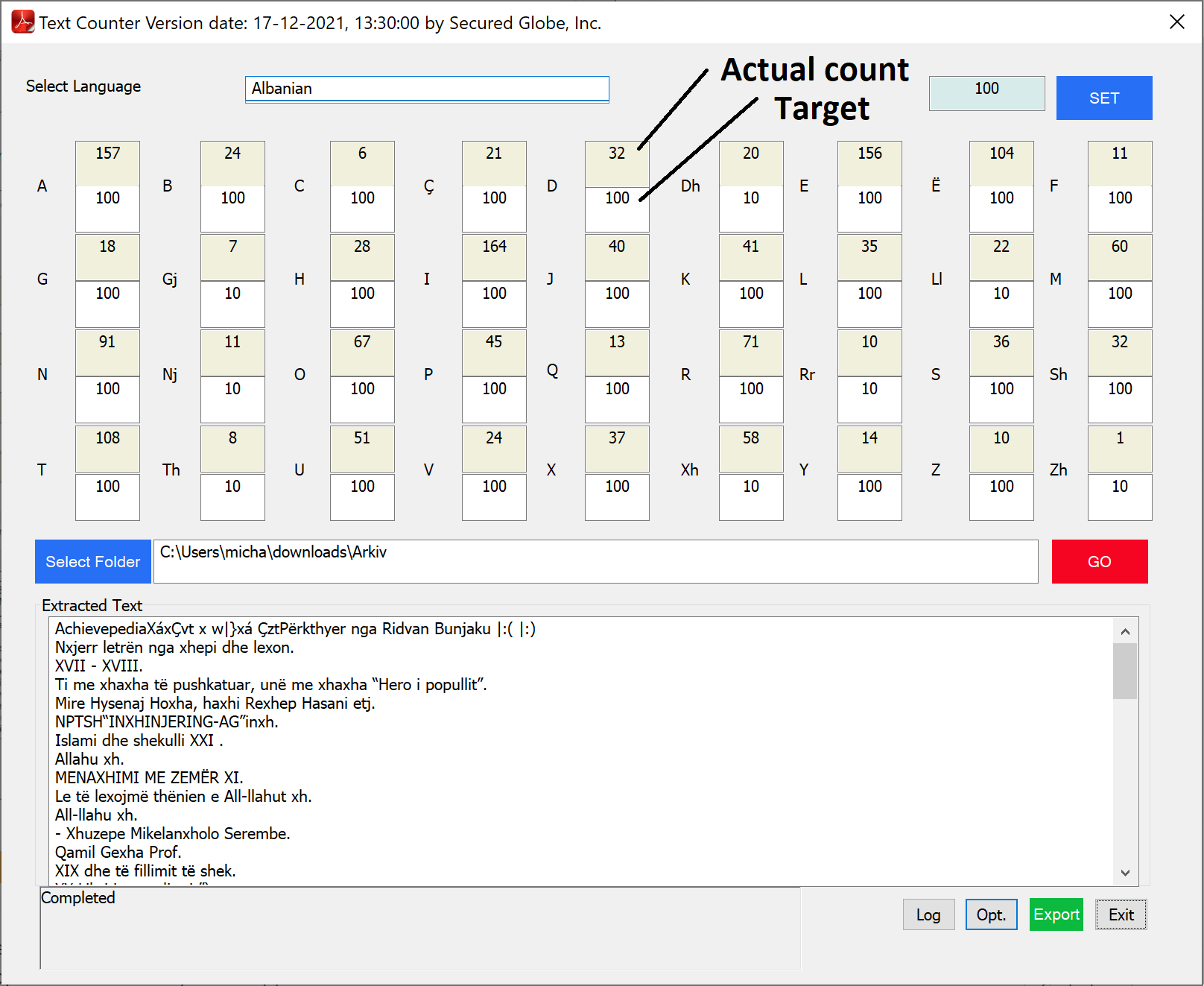
This is where we need improvements.
As you can see, the actual counts of each character in the selected sentences aren’t close enough to the target of that character.
The Source Code
The code is developed in Visual Studio 2017 Enterprise along with MFC. To run the code, you need to install MFC as well. The application is a Dialog based app.
The first functionality needed was going over PDF files and extracting from each file the text it contains. That was achieved using this source code repo we created, which is based on this excellent library.
The Albanian Alphabet
We had to build our code in such way that will support the Albanian Alphabet, but also be expandable to other languages in the future. We defined a structure named Language.
typedef struct
{
wchar_t m_CharU[3]{ L"" };
wchar_t m_CharL[3]{ L"" };
int m_Count{ 1 };
int index{ -1 };
} Char;
typedef struct
{
wstring LangName;
Char characters[80];
} Language;
and then defined Albanian as follows:
Language Albanian =
{
L"Albanian",
{
_T("A"),_T("a"),1,0,
_T("B"),_T("b"),1,1,
_T("C"),_T("c"),1,2,
_T("Ç"),_T("ç"),1,3,
_T("DH"),_T("dh"),2,5,
_T("E"),_T("e"),1,6,
_T("Ë"),_T("ë"),1,7,
_T("F"),_T("f"),1,8,
_T("GJ"),_T("gj"),2,10,
_T("H"),_T("h"),1,11,
_T("I"),_T("i"),1,12,
_T("J"),_T("j"),1,13,
_T("K"),_T("k"),1,14,
_T("LL"),_T("ll"),2,16,
_T("M"),_T("m"),1,17,
_T("NJ"),_T("nj"),2,19,
_T("O"),_T("o"),1,20,
_T("P"),_T("p"),1,21,
_T("Q"),_T("q"),1,22,
_T("RR"),_T("rr"),2,24,
_T("SH"),_T("sh"),2,26,
_T("TH"),_T("th"),2,28,
_T("U"),_T("u"),1,29,
_T("V"),_T("v"),1,30,
_T("XH"),_T("xh"),2,32,
_T("Y"),_T("y"),1,33,
_T("ZH"),_T("zh"),2,35,
_T(""),_T(""),-1,-1
}
};
We store the count of each character in the alphabet in this structure:
typedef struct
{
int counter[40]
{
0,0,0,0,0,
0,0,0,0,0,
0,0,0,0,0,
0,0,0,0,0,
0,0,0,0,0,
0,0,0,0,0,
0,0,0,0,0,
0,0,0,0,0
};
} CounterTotals;
The Optimization Part
The actual work is done when the Opt button is pressed. We then need to select a combination of sentences which will bring us closest to the target.
void SentencesCounter::SolveIR(vector<Sentence> &sentences, vector<Sentence> &SelectedData)
{
size_t sum = 0;
vector<Sentence> candidates;
//========= remove duplicate sentences ===========//
//set<Sentence> s(candidates.begin(), candidates.end());
//candidates.assign(s.begin(), s.end());
//rt(candidates.begin(), candidates.end());
//candidates.erase(unique(candidates.begin(), candidates.end()), candidates.end());
//unordered_set<int> s;
unordered_set<wstring> c1;
for (size_t i = 0; i < sentences.size(); i++) //remove duplicates
{
if (sentences[i].text.size() < 10) continue; // to avoid fake sentences
if (c1.find(sentences[i].text) == c1.end()) { //O(1)
c1.insert(sentences[i].text);
candidates.push_back(sentences[i]);
sum += sentences[i].text.length();
}
}
//-----------------------------------------------//
for (size_t i = 0; i < candidates.size(); i++)
{
sum += candidates[i].text.length();
}
CalculateValueFactor(sum);
for (size_t i = 0; i < candidates.size(); i++)
{
candidates[i].score = GetNewScore(candidates[i]);
}
sort(candidates.begin(), candidates.end(), orderByScoreDistance);
vector<Sentence> selection;
Sentence sAllSelected;
ResetSentence(sAllSelected);
int lastDistance = INT_MAX/2 -1, newDistance = INT_MIN;
for (auto &s : candidates) // access by reference to avoid copying
{
updateSentence(&sAllSelected, s);
newDistance = GetDistance(sAllSelected, m_target);
if (lastDistance < newDistance)
{
for (size_t i = 0; i < 40; i++)
{
sAllSelected.counter[i] -= s.counter[i];
}
break;
}
else {
selection.push_back(s);
lastDistance = newDistance;
}
}
ResetResults();
CString foundText{ _T("") };
for (auto& sentence : selection)
{
foundText.AppendFormat(_T("%s\r\n"), sentence.text.c_str());
UpdateTotals(sentence);
}
for (size_t i = 0; i < 40; i++)
{
m_totals.counter[i] = sAllSelected.counter[i];
//foundText.AppendFormat(_T("<%s:%d>,"), getAlbaniLetter(i), sAllSelected.counter[i]);
}
foundText.Append(L"\r\n");
MainDlg* pMainDlg = (MainDlg*)AfxGetApp()->GetMainWnd();
CString temp;
pMainDlg->m_FoundText.GetWindowText(temp);
temp.Append(foundText);
pMainDlg->m_FoundText.SetWindowTextW(temp);
SelectedData.clear();
SelectedData.insert(SelectedData.begin(),
selection.begin(), selection.end());
MessageBox(GetForegroundWindow(),
L"Selected " + (CString)(std::to_wstring(SelectedData.size()).c_str()) +
(CString)L" sentences", L"Result", MB_OK);
}
History
- 17th December, 2021: Initial version