
SQL Server Express Edition on Steroids
5.00/5 (15 votes)
How to omit many restrictions on SQL Server Express Edition
Introduction
Wake up… you have always felt that the world is out of order. A strange thought, but it can’t be driven away – it’s like a splinter in the brain. You live your whole life in a dungeon of restrictions and rules imposed by the omnipotent Microsoft, and you fail to realize it.
Hit dislike and the story ends – you close the tab and go on wandering aimlessly around YouTube's recommendations.
But if you want to continue and enter a wonderland, I'll show you how deep… how impossible is the rabbit hole of successful development on SQL Server Express Edition.

From time to time, with some fondness, I recall the early years of my career… when the grass was greener after being fresh painted… when the company's management didn’t care much about various licensing conditions… but times are changing rapidly and you have to follow the rules of the market if you want to be the part of a big business.
The flip side of this medal is the bitter realization of the main truth of capitalism – the entire business is gradually forced to either migrate to cloud or pay for expensive licenses. But what if there is another way - when you don’t need to pay for licenses, but at the same time, freely use all the important benefits of commercial editions of SQL Server.
And now we are not even talking about the Developer Edition, which Microsoft made completely free back in 2014, although it had been willingly selling it for $59.95 before. More interesting is the cost optimization for production servers, when clients in the times of crisis ask for the maximum reduction of costs of their business for equipment.
Undoubtedly, now you can already pack your bags and migrate the logic to free analogues, like PostgreSQL or MariaDB. But a rhetorical question immediately arises – who is going to rewrite and test this in conditions when everyone needs everything done “yesterday”? And even if by a strong-willed decision to try to quickly migrate an enterprise project, then it’s more likely, as a result, to successfully play Kurt Cobain's favorite shooter than to release. Therefore, we will just think about how to get the most out of the Express Edition within the current technical restrictions.
A preliminary diagnosis for SQL Server Express Edition, made by a college of doctors: a patient can use no more than 4 logical cores within a single socket, a little more than 1GB of memory is allocated for Buffer Pool, the size of a database file cannot exceed 10GB… thanks, that the patient is at least able to walk somehow and the rest is somehow cured.
Implementation
Paradoxically, the first thing to start with is to find out the version of our SQL Server. And the thing is that when SQL Server 2016 SP1 was announced back in 2018, Microsoft demonstrated miracles of generosity and partially equalized all editions in functionality as part of its new initiative – consistent programmability surface area (CPSA).
If earlier you had to write code with an eye on a specific edition, then with the upgrade to 2016 SP1 (and later versions), many of the Enterprise features became available for use, including for the Express Edition. Among the new features of the Express Edition, one can single out the following: support for partitioning tables and indexes, creating Column-store indexes and In-Memory tables, as well as the ability to compress tables. This is one of the rare occasions when a SQL Server upgrade is worth installing.
Is it enough to use the Express Edition for production workloads?
In order to answer this question, let's try to consider several scenarios.
Let's test a single-threaded OLTP workload of different types of tables for inserting/updating/deleting 200,000 rows:
USE [master]
GO
SET NOCOUNT ON
SET STATISTICS IO, TIME OFF
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
GO
CREATE DATABASE [express]
ON PRIMARY (NAME = N'express', _
FILENAME = N'X:\express.mdf', SIZE = 200 MB, FILEGROWTH = 100 MB)
LOG ON (NAME = N'express_log', FILENAME = N'X:\express_log.ldf', _
SIZE = 200 MB, FILEGROWTH = 100 MB)
ALTER DATABASE [express] SET AUTO_CLOSE OFF
ALTER DATABASE [express] SET RECOVERY SIMPLE
ALTER DATABASE [express] SET MULTI_USER
ALTER DATABASE [express] SET DELAYED_DURABILITY = ALLOWED
ALTER DATABASE [express] ADD FILEGROUP [MEM] CONTAINS MEMORY_OPTIMIZED_DATA
ALTER DATABASE [express] ADD FILE (NAME = 'MEM', FILENAME = 'X:\MEM') TO FILEGROUP [MEM]
ALTER DATABASE [express] SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON
GO
USE [express]
GO
CREATE TABLE [T1_CL] (A INT PRIMARY KEY, B DATETIME INDEX IX1 NONCLUSTERED)
GO
CREATE TABLE [T2_MEM] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
CREATE TABLE [T3_MEM_NC] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
CREATE TABLE [T4_CL_DD] (A INT PRIMARY KEY, B DATETIME INDEX IX1 NONCLUSTERED)
GO
CREATE TABLE [T5_MEM_DD] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
CREATE TABLE [T6_MEM_NC_DD] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
CREATE TABLE [T7_MEM_SO] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY)
GO
CREATE TABLE [T8_MEM_SO_NC] (A INT PRIMARY KEY NONCLUSTERED, B DATETIME INDEX IX1 NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY)
GO
CREATE PROCEDURE [T3_MEM_I] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
INSERT INTO [dbo].[T3_MEM_NC] VALUES (@i, GETDATE())
END
GO
CREATE PROCEDURE [T3_MEM_U] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE [dbo].[T3_MEM_NC] SET B = GETDATE() WHERE A = @i
END
GO
CREATE PROCEDURE [T3_MEM_D] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
DELETE [dbo].[T3_MEM_NC] WHERE A = @i
END
GO
CREATE PROCEDURE [T6_MEM_I] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
INSERT INTO [dbo].[T6_MEM_NC_DD] VALUES (@i, GETDATE())
END
GO
CREATE PROCEDURE [T6_MEM_U] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE [dbo].[T6_MEM_NC_DD] SET B = GETDATE() WHERE A = @i
END
GO
CREATE PROCEDURE [T6_MEM_D] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
DELETE [dbo].[T6_MEM_NC_DD] WHERE A = @i
END
GO
CREATE PROCEDURE [T8_MEM_I] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
INSERT INTO [dbo].[T8_MEM_SO_NC] VALUES (@i, GETDATE())
END
GO
CREATE PROCEDURE [T8_MEM_U] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE [dbo].[T8_MEM_SO_NC] SET B = GETDATE() WHERE A = @i
END
GO
CREATE PROCEDURE [T8_MEM_D] (@i INT)
WITH NATIVE_COMPILATION, SCHEMABINDING
AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
DELETE [dbo].[T8_MEM_SO_NC] WHERE A = @i
END
GO
DECLARE @i INT
, @s DATETIME
, @runs INT = 200000
DROP TABLE IF EXISTS #stats
CREATE TABLE #stats (obj VARCHAR(100), op VARCHAR(100), time_ms BIGINT)
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
INSERT INTO [T1_CL] VALUES (@i, GETDATE())
SET @i += 1
END
INSERT INTO #stats SELECT 'T1_CL', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
UPDATE [T1_CL] SET B = GETDATE() WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T1_CL', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
DELETE [T1_CL] WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T1_CL', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
INSERT INTO [T2_MEM] VALUES (@i, GETDATE())
SET @i += 1
END
INSERT INTO #stats SELECT 'T2_MEM', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
UPDATE [T2_MEM] SET B = GETDATE() WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T2_MEM', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
DELETE [T2_MEM] WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T2_MEM', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T3_MEM_I] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T3_MEM_NC', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T3_MEM_U] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T3_MEM_NC', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T3_MEM_D] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T3_MEM_NC', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
INSERT INTO [T4_CL_DD] VALUES (@i, GETDATE())
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T4_CL_DD', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
UPDATE [T4_CL_DD] SET B = GETDATE() WHERE A = @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T4_CL_DD', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
DELETE [T4_CL_DD] WHERE A = @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T4_CL_DD', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
INSERT INTO [T5_MEM_DD] VALUES (@i, GETDATE())
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T5_MEM_DD', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
UPDATE [T5_MEM_DD] SET B = GETDATE() WHERE A = @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T5_MEM_DD', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
DELETE [T5_MEM_DD] WHERE A = @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T5_MEM_DD', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
EXEC [T6_MEM_I] @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T6_MEM_NC_DD', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
EXEC [T6_MEM_U] @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T6_MEM_NC_DD', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
BEGIN TRANSACTION t
EXEC [T6_MEM_D] @i
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
SET @i += 1
END
INSERT INTO #stats SELECT 'T6_MEM_NC_DD', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
INSERT INTO [T7_MEM_SO] VALUES (@i, GETDATE())
SET @i += 1
END
INSERT INTO #stats SELECT 'T7_MEM_SO', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
UPDATE [T7_MEM_SO] SET B = GETDATE() WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T7_MEM_SO', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
DELETE [T7_MEM_SO] WHERE A = @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T7_MEM_SO', 'DELETE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T8_MEM_I] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T8_MEM_SO_NC', 'INSERT', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T8_MEM_U] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T8_MEM_SO_NC', 'UPDATE', DATEDIFF(ms, @s, GETDATE())
SELECT @i = 1, @s = GETDATE()
WHILE @i <= @runs BEGIN
EXEC [T8_MEM_D] @i
SET @i += 1
END
INSERT INTO #stats SELECT 'T8_MEM_SO_NC', 'DELETE', DATEDIFF(ms, @s, GETDATE())
GO
SELECT obj
, [I] = MAX(CASE WHEN op = 'INSERT' THEN time_ms END)
, [U] = MAX(CASE WHEN op = 'UPDATE' THEN time_ms END)
, [D] = MAX(CASE WHEN op = 'DELETE' THEN time_ms END)
FROM #stats
GROUP BY obj
USE [master]
GO
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
As a result of the execution, we get the following values:
I U D
--------------- ------- ------- ------- -------------------------------------------------------
T1_CL 12173 14434 12576 B-Tree Index
T2_MEM 14774 14593 13777 In-Memory SCHEMA_AND_DATA
T3_MEM_NC 11563 10560 10097 In-Memory SCHEMA_AND_DATA + Native Compile
T4_CL_DD 5176 7294 5303 B-Tree Index + Delayed Durability
T5_MEM_DD 7460 7163 6214 In-Memory SCHEMA_AND_DATA + Delayed Durability
T6_MEM_NC_DD 8386 7494 6973 In-Memory SCHEMA_AND_DATA +
Native Compile + Delayed Durability
T7_MEM_SO 5667 5383 4473 In-Memory SCHEMA_ONLY
T8_MEM_SO_NC 3250 2430 2287 In-Memory SCHEMA_ONLY + Native Compile
One of the worst results for us is shown by the table based on the clustered index (T1_CL). If you look at wait stats within the framework of the execution of the first table:
SELECT TOP(20) wait_type
, wait_time = CAST(wait_time_ms / 1000. AS DECIMAL(18,4))
, wait_resource = _
CAST((wait_time_ms - signal_wait_time_ms) / 1000. AS DECIMAL(18,4))
, wait_signal = CAST(signal_wait_time_ms / 1000. AS DECIMAL(18,4))
, wait_time_percent = CAST(100. * wait_time_ms / _
NULLIF(SUM(wait_time_ms) OVER (), 0) AS DECIMAL(18,2))
, waiting_tasks_count
FROM sys.dm_os_wait_stats
WHERE waiting_tasks_count > 0
AND wait_time_ms > 0
AND wait_type NOT IN (
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR',
N'BROKER_TASK_STOP', N'BROKER_TO_FLUSH',
N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT',
N'CLR_MANUAL_EVENT', N'CLR_SEMAPHORE',
N'DBMIRROR_DBM_EVENT', N'DBMIRROR_EVENTS_QUEUE',
N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE',
N'EXECSYNC', N'FSAGENT',
N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION',
N'HADR_LOGCAPTURE_WAIT', N'HADR_NOTIFICATION_DEQUEUE',
N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP',
N'LOGMGR_QUEUE', N'ONDEMAND_TASK_QUEUE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'REQUEST_FOR_DEADLOCK_SEARCH', N'RESOURCE_QUEUE',
N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP',
N'SLEEP_MASTERDBREADY', N'SLEEP_MASTERMDREADY',
N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK',
N'SLEEP_TEMPDBSTARTUP', N'SNI_HTTP_ACCEPT',
N'SP_SERVER_DIAGNOSTICS_SLEEP', N'SQLTRACE_BUFFER_FLUSH',
N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS',
N'WAITFOR', N'WAITFOR_TASKSHUTDOWN',
N'WAIT_XTP_HOST_WAIT', N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG',
N'WAIT_XTP_CKPT_CLOSE', N'XE_DISPATCHER_JOIN',
N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT'
)
ORDER BY wait_time_ms DESC
then we will notice that the greatest wait is observed within the WRITELOG:
wait_type wait_time wait_resource wait_signal wait_time_percent waiting_tasks_count
-------------------------------- ---------- -------------- ------------ ------------------ --------------------
WRITELOG 13.5480 10.7500 2.7980 95.66 600048
MEMORY_ALLOCATION_EXT 0.5030 0.5030 0.0000 3.55 608695
PREEMPTIVE_OS_WRITEFILEGATHER 0.0250 0.0250 0.0000 0.18 3
ASYNC_IO_COMPLETION 0.0200 0.0200 0.0000 0.14 1
IO_COMPLETION 0.0200 0.0200 0.0000 0.14 8
Open the encyclopedia of SQL Server waits authored by Paul Randal and find WRITELOG there while checking MSDN:
This is the log management system waiting for a log flush to disk. It commonly indicates that the I/O subsystem can’t keep up with the log flush volume, but on very high-volume systems it could also be caused by internal log flush limits, that may mean you have to split your workload over multiple databases or even make your transactions a little longer to reduce log flushes. To be sure it’s the I/O subsystem, use the DMV sys.dm_io_virtual_file_stats to examine the I/O latency for the log file and see if it correlates to the average WRITELOG time. If WRITELOG is longer, you’ve got internal contention and need to shard. If not, investigate why you’re creating so much transaction log.
Our case is very obvious, and as a solution to the problem with WRITELOG waits, it would be possible to insert data not row by row, but in batch of rows at a time. But we have a purely academic interest in the above load optimization, so it would be worthwhile to figure out how data is modified in SQL Server?
Suppose we are doing a row modification. SQL Server calls the Storage Engine component, which, in turn, calls the Buffer Manager (which works with buffers in memory and disk) and says that it wants to change the data. After that, the Buffer Manager turns to the Buffer Pool and modifies the necessary pages in memory (if these pages aren’t there, it will load them from disk, and along the way, we will get PAGEIOLATCH_* waits). The moment the page in memory has changed, SQL Server can’t yet tell that the request has been completed. Otherwise, one of the principles of ACID (Durability) would be violated, when at the end of the modification, it is guaranteed that all data will be loaded to the disk.
After modifying the page in memory, the Storage Engine calls the Log Manager, which writes the data to the log file. But he does this not immediately, but through the Log Buffer, which has a size of 60Kb (there are nuances, but we will skip them here) and is used to optimize performance when working with the log file. Flushing data from the buffer to the log file occurs in situations when: the buffer is full, we manually executed sp_flush_log, or when a transaction was committed and everything from the Log Buffer was written to the log file. When the data has been saved in the log file, it confirms that the data modification was successful and notifies the client about it.
According to this logic, you will notice that the data doesn’t go straight to the data file. To optimize the work with the disk subsystem, SQL Server uses an asynchronous mechanism for writing changes to the database files. There are two such mechanisms in total: Lazy Writer (runs on a periodic basis, checks whether there is enough memory for SQL Server, if memory pressure is observed, then pages from memory are preempted and written to the database file, and those that have been changed are flushed to disk and thrown out of memory) and Checkpoint (scans dirty pages around once a minute, drops them to the disk and leaves them in memory).
When a bunch of small transactions occurs in the system (say, if the data is modified row by row), then after each commit the data goes from the Log Buffer to the transaction log. Remember that all changes are sent to the log file synchronously and other transactions have to wait for their turn – this is a limiting factor for building high-performance systems.
Then what is the alternative to solving this problem?
In SQL Server 2014, it became possible to create In-Memory tables, which, as declared by the developers, can significantly speed-up OLTP workload due to the new Hekaton engine. But if you look at the example above (T2_MEM), then the single-threaded performance of In-Memory there is even worse than that of traditional tables with a clustered index (T1_CL) – this is due to the XTP_PREEMPTIVE_TASK processes that, in the background, commit large changes in In-Memory tables to the log file (and they do it not very well, as practice shows).
In fact, the whole point of In-Memory is in an improved concurrent access mechanism and reduced locks when modifying data. In such a scenario, their use really leads to amazing results, but they should not be used for a banal CRUD.
We see a similar situation in further attempts to speed up the work of In-Memory tables, wrapping Native Compile stored procedures (T3_MEM_NC) over them, which perfectly optimize performance in the case of some calculations and iterative data processing in them, but as a wrapper for CRUD operations they manifest themselves mediocre and only reduce the workload on your actual call.
In general, I have a long-standing dislike of In-Memory tables and Native Compile storage - there were too many bugs in SQL Server 2014/2016 associated with them. Some things have been fixed, some have been improved, but you still need to use this technology very carefully. For example, after creating an In-Memory filegroup, you can’t just take it and delete it without re-creating the target database. And all would be fine, but sometimes this filegroup can grow into several gigabytes even if you just update a couple of rows in the In-Memory table… and if we are talking about production, then I would not use this technology within the main databases.
A whole different thing is to enable the Delayed Durability option, which allows you not to save data to the log file immediately upon committing a transaction, but wait until 60Kb of changes are accumulated. This can be done forcibly at the level of all transactions of the selected database:
ALTER DATABASE TT SET DELAYED_DURABILITY = FORCED
or within individual transactions:
ALTER DATABASE TT SET DELAYED_DURABILITY = ALLOWED
GO
BEGIN TRANSACTION t
...
COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON)
The advantage of using this option is clearly shown in the example of T4_CL_DD (2.5 times faster than T1_CL). There are, of course, some downsides to enabling this option, when under a successful coincidence (in the event of a system failure or power outage), you can lose about 60KB of data.
I think that you shouldn’t impose your opinion here, because in each situation, you need to weigh the pros and cons, but I will add from myself that the inclusion of Delayed Durability saved me more than once, when it was necessary to urgently unload the disk subsystem during OLTP load.
And now, we have come to the most interesting thing – how to speed up OLTP operations as much as possible? The answer lies in the correct use of In-Memory tables. Before that, I pretty much criticized them, but all performance problems relate only to tables created as SCHEMA_AND_DATA (when data is stored both in RAM and on disk). But if you create an In-Memory table with the SCHEMA_ONLY option, then the data will be stored only in RAM… as a minus – when the sequel is restarted, the data in such tables will be lost. Moreover, it is the ability to speed up data modification operations by 4 times compared to ordinary tables (T8_MEM_SO/T8_MEM_SO_NC).
To illustrate my working case, an intermediate database is created, within which there is an In-Memory SCHEMA_ONLY table (we wrap all operations on it in Native Compile procedures), records are continuously poured into it at maximum speed, and we transfer them in larger portions to the main database in a separate stream for permanent storage. In addition, In-Memory tables with SCHEMA_ONLY are great for ETL loading as an intermediate buffer, since they do not put any load on the disk subsystem.
Now let's move on to the DW workload, which is characterized by analytical queries with the extraction of voluminous chunks of data.
In order to do this, let's create several tables with different compression options and experiment with them:
USE [master]
GO
SET NOCOUNT ON
SET STATISTICS IO, TIME OFF
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
GO
CREATE DATABASE [express]
ON PRIMARY (NAME = N'express', FILENAME = N'X:\express.mdf', _
SIZE = 200 MB, FILEGROWTH = 100 MB)
LOG ON (NAME = N'express_log', FILENAME = N'X:\express_log.ldf', _
SIZE = 200 MB, FILEGROWTH = 100 MB)
ALTER DATABASE [express] SET AUTO_CLOSE OFF
ALTER DATABASE [express] SET RECOVERY SIMPLE
ALTER DATABASE [express] SET DELAYED_DURABILITY = FORCED
GO
USE [express]
GO
DROP TABLE IF EXISTS [T1_HEAP]
CREATE TABLE [T1_HEAP] (
[INT] INT NOT NULL
, [VARCHAR] VARCHAR(100) NOT NULL
, [DATETIME] DATETIME NOT NULL
)
GO
;WITH E1(N) AS (SELECT * FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) t(N))
, E2(N) AS (SELECT '1' FROM E1 a, E1 b)
, E4(N) AS (SELECT '1' FROM E2 a, E2 b)
, E8(N) AS (SELECT '1' FROM E4 a, E4 b)
INSERT INTO [T1_HEAP] WITH(TABLOCK) ([INT], [VARCHAR], [DATETIME])
SELECT TOP(5000000)
ROW_NUMBER() OVER (ORDER BY 1/0)
, CAST(ROW_NUMBER() OVER (ORDER BY 1/0) AS VARCHAR(100))
, DATEADD(DAY, ROW_NUMBER() OVER (ORDER BY 1/0) % 100, '20180101')
FROM E8
GO
DROP TABLE IF EXISTS [T2_CL]
SELECT * INTO [T2_CL] FROM [T1_HEAP] WHERE 1=0
CREATE CLUSTERED INDEX IX ON [T2_CL] ([INT]) WITH (DATA_COMPRESSION = NONE)
INSERT INTO [T2_CL] WITH(TABLOCK)
SELECT * FROM [T1_HEAP]
GO
DROP TABLE IF EXISTS [T3_CL_ROW]
SELECT * INTO [T3_CL_ROW] FROM [T2_CL] WHERE 1=0
CREATE CLUSTERED INDEX IX ON [T3_CL_ROW] ([INT]) WITH (DATA_COMPRESSION = ROW)
INSERT INTO [T3_CL_ROW] WITH(TABLOCK)
SELECT * FROM [T2_CL]
GO
DROP TABLE IF EXISTS [T4_CL_PAGE]
SELECT * INTO [T4_CL_PAGE] FROM [T2_CL] WHERE 1=0
CREATE CLUSTERED INDEX IX ON [T4_CL_PAGE] ([INT]) WITH (DATA_COMPRESSION = PAGE)
INSERT INTO [T4_CL_PAGE] WITH(TABLOCK)
SELECT * FROM [T2_CL]
GO
DROP TABLE IF EXISTS [T5_CCI]
SELECT * INTO [T5_CCI] FROM [T2_CL] WHERE 1=0
CREATE CLUSTERED COLUMNSTORE INDEX IX ON [T5_CCI] WITH (DATA_COMPRESSION = COLUMNSTORE)
INSERT INTO [T5_CCI] WITH(TABLOCK)
SELECT * FROM [T2_CL]
GO
DROP TABLE IF EXISTS [T6_CCI_ARCHIVE]
SELECT * INTO [T6_CCI_ARCHIVE] FROM [T2_CL] WHERE 1=0
CREATE CLUSTERED COLUMNSTORE INDEX IX ON [T6_CCI_ARCHIVE] _
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
INSERT INTO [T6_CCI_ARCHIVE] WITH(TABLOCK)
SELECT * FROM [T2_CL]
GO
The first thing to pay attention to is the final size of the tables:
SELECT o.[name]
, i.[rows]
, i.[type_desc]
, total_mb = CAST(i.total_pages * 8. / 1024 AS DECIMAL(18,2))
FROM sys.objects o
JOIN (
SELECT i.[object_id]
, a.[type_desc]
, total_pages = SUM(a.total_pages)
, [rows] = SUM(CASE WHEN i.index_id IN (0,1) THEN p.[rows] END)
FROM sys.indexes i
JOIN sys.partitions p ON i.[object_id] = p.[object_id] AND i.index_id = p.index_id
JOIN sys.allocation_units a ON p.[partition_id] = a.container_id
WHERE a.total_pages > 0
GROUP BY i.[object_id]
, a.[type_desc]
) i ON o.[object_id] = i.[object_id]
WHERE o.[type] = 'U'
Due to the possibility of using compression and Column-store indexes on the Express Edition, a bunch of options have appeared when it is possible to store more information within the allowed 10GB for a database file without significant loss of performance:
rows type_desc total_mb
--------------- -------- ------------ ---------
T1_HEAP 5000000 IN_ROW_DATA 153.38
T2_CL 5000000 IN_ROW_DATA 163.45
T3_CL_ROW 5000000 IN_ROW_DATA 110.13
T4_CL_PAGE 5000000 IN_ROW_DATA 72.63
T5_CCI 5000000 LOB_DATA 81.20
T6_CCI_ARCHIVE 5000000 LOB_DATA 41.13
If we start talking about data compression, then ROW compression truncates the value without loss to the lowest possible fixed type, PAGE – on top of ROW additionally compresses data in binary form at the page level. In this form, the pages are stored both on disk and in the Buffer Pool, and only at the moment of direct access to the data does the decompression take place on the fly.
The undoubted advantage from the use of compression is manifested in the decrease in IO operations from the disk and a smaller amount of Buffer Pool used for data storage – this is especially true if we have a slow disk, little RAM and a relatively unloaded processor. The flip side of the coin from the use of compression is an extra load on the processor, but not so critical as to completely ignore this functionality, courtesy of Microsoft, "like a leper".
It looks very interesting to use Column-store indexes, which can significantly compress data and increase the performance of analytical queries. Let's take a quick look at how they work… since this is a columnar storage model, the data in the table is split by a RowGroup of about a million rows (the total may differ from how the data was inserted into the table), then, within the RowGroup, each of the columns is represented in in the form of a segment that is compressed into a LOB object with its own meta information (for example, it stores the minimum and maximum values within the compressed sequence).
Unlike PAGE / ROW compression, Column-store indexes use different compression options depending on the data type of the target column – this can be Value Scale, dictionary-based compression, Bit-Array Packing, and various others (Run Length, Huffman Encoding, Binary Compression, LZ77). As a result, we are able to more optimally compress each of the columns.
You can see how one or another RowGroup is compressed with this query:
SELECT o.[name]
, row_group_id
, state_description
, total_rows
, size_mb = CAST(size_in_bytes / (1024. * 1024) AS DECIMAL(18,2))
, total_mb = CAST(SUM(size_in_bytes) OVER _
(PARTITION BY i.[object_id]) / 8192 * 8. / 1024 AS DECIMAL(18,2))
FROM sys.indexes i
JOIN sys.objects o ON i.[object_id] = o.[object_id]
CROSS APPLY sys.fn_column_store_row_groups(i.[object_id]) s
WHERE i.[type] IN (5, 6)
AND i.[object_id] = OBJECT_ID('T5_CCI')
ORDER BY i.[object_id]
, s.row_group_id
row_group_id state_description total_rows deleted_rows size_mb total_mb
------------- ------------------ ----------- ------------- -------- ---------
0 COMPRESSED 593581 0 3.78 31.80
1 COMPRESSED 595539 0 3.79 31.80
2 COMPRESSED 595539 0 3.79 31.80
3 COMPRESSED 599030 0 3.81 31.80
4 COMPRESSED 595539 0 3.79 31.80
5 COMPRESSED 686243 0 4.37 31.80
6 COMPRESSED 595539 0 3.79 31.80
7 COMPRESSED 738990 0 4.70 31.80
Let's note a small nuance that can greatly affect the performance of using the Column-store indexes in relation to the Express Edition. Since segments and dictionaries (on the basis of which decompression occurs) are stored in different structures on the disk, it is extremely important that the size of all our dictionaries fit in memory (for this, no more than 350 MB are allocated on the Express Edition):
SELECT [column] = COL_NAME(p.[object_id], s.column_id)
, s.dictionary_id
, s.entry_count
, size_mb = CAST(s.on_disk_size / (1024. * 1024) AS DECIMAL(18,2))
, total_mb = CAST(SUM(s.on_disk_size) OVER () / 8192 * 8. / 1024 AS DECIMAL(18,2))
FROM sys.column_store_dictionaries s
JOIN sys.partitions p ON p.hobt_id = s.hobt_id
WHERE p.[object_id] = OBJECT_ID('T5_CCI')
column dictionary_id entry_count size_mb total_mb
---------- ------------- ------------ -------- ----------
VARCHAR 1 593581 6.39 53.68
VARCHAR 2 738990 7.98 53.68
VARCHAR 3 686243 7.38 53.68
VARCHAR 4 595539 6.37 53.68
VARCHAR 5 595539 6.39 53.68
VARCHAR 6 595539 6.38 53.68
VARCHAR 7 595539 6.39 53.68
VARCHAR 8 599030 6.40 53.68
DATETIME 1 100 0.00 53.68
DATETIME 2 100 0.00 53.68
DATETIME 3 100 0.00 53.68
DATETIME 4 100 0.00 53.68
DATETIME 5 100 0.00 53.68
DATETIME 6 100 0.00 53.68
DATETIME 7 100 0.00 53.68
DATETIME 8 100 0.00 53.68
At the same time, segments can be loaded from disk as needed and practically don’t affect the processor load:
SELECT [column] = COL_NAME(p.[object_id], s.column_id)
, s.segment_id
, s.row_count
, CAST(s.on_disk_size / (1024. * 1024) AS DECIMAL(18,2))
FROM sys.column_store_segments s
JOIN sys.partitions p ON p.hobt_id = s.hobt_id
WHERE p.[object_id] = OBJECT_ID('T5_CCI')
column segment_id row_count size_mb total_mb
---------- ----------- ----------- -------- ---------
INT 0 593581 2.26 31.80
INT 1 595539 2.27 31.80
INT 2 595539 2.27 31.80
INT 3 599030 2.29 31.80
INT 4 595539 2.27 31.80
INT 5 686243 2.62 31.80
INT 6 595539 2.27 31.80
INT 7 738990 2.82 31.80
VARCHAR 0 593581 1.51 31.80
VARCHAR 1 595539 1.52 31.80
VARCHAR 2 595539 1.52 31.80
VARCHAR 3 599030 1.52 31.80
VARCHAR 4 595539 1.52 31.80
VARCHAR 5 686243 1.75 31.80
VARCHAR 6 595539 1.52 31.80
VARCHAR 7 738990 1.88 31.80
DATETIME 0 593581 0.01 31.80
DATETIME 1 595539 0.01 31.80
DATETIME 2 595539 0.01 31.80
DATETIME 3 599030 0.01 31.80
DATETIME 4 595539 0.01 31.80
DATETIME 5 686243 0.01 31.80
DATETIME 6 595539 0.01 31.80
DATETIME 7 738990 0.01 31.80
Pay attention to the fewer unique records within the RowGroup segment, the smaller the dictionary size will be. Partitioning the Column-store and inserting data into the desired section along with the TABLOCK hint will result in smaller local dictionaries, which means it will reduce the overhead of using Column-store indexes. Actually, the easiest way to optimize dictionaries is in the data itself – the fewer unique data within a column, the better (this can be seen in the example of DATETIME).
Due to the columnar model, only those columns that we request will be subtracted, and additional filters can limit the subtraction of the RowGroup due to the above meta information. As a result, we get a kind of analogue of the pseudo-index, which is simultaneously on all columns, and this allows us to very quickly aggregate and filter… again with its own nuances.
Let's look at a few examples to show the benefits of Column-store indexes:
DBCC DROPCLEANBUFFERS
SET STATISTICS IO, TIME ON
SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T1_HEAP]
SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T2_CL]
SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T3_CL_ROW]
SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T4_CL_PAGE]
SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T5_CCI]
SELECT COUNT(*), MIN([DATETIME]), MAX([INT]) FROM [T6_CCI_ARCHIVE]
SET STATISTICS IO, TIME OFF
As the saying goes, feel the difference:
Table 'T1_HEAP'. Scan count 1, logical reads 19633, ...
CPU time = 391 ms, elapsed time = 400 ms.
Table 'T2_CL'. Scan count 1, logical reads 20911, ...
CPU time = 312 ms, elapsed time = 391 ms.
Table 'T3_CL_ROW'. Scan count 1, logical reads 14093, ...
CPU time = 485 ms, elapsed time = 580 ms.
Table 'T4_CL_PAGE'. Scan count 1, logical reads 9286, ...
CPU time = 828 ms, elapsed time = 1000 ms.
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 5122, ...
CPU time = 8 ms, elapsed time = 14 ms.
Table 'T6_CCI_ARCHIVE'. Scan count 1, ..., lob logical reads 2576, ...
CPU time = 78 ms, elapsed time = 74 ms.
When filtering, not very good nuances can come out:
DBCC DROPCLEANBUFFERS
SET STATISTICS IO, TIME ON
SELECT * FROM [T5_CCI] WHERE [INT] = 1
SELECT * FROM [T5_CCI] WHERE [DATETIME] = GETDATE()
SELECT * FROM [T5_CCI] WHERE [VARCHAR] = '1'
SET STATISTICS IO, TIME OFF
And the thing is that for certain data types (NUMERIC, DATETIMEOFFSET, [N] CHAR, [N] VARCHAR, VARBINARY, UNIQUEIDENTIFIER, XML) Row Group Elimination is not supported:
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 2713, ...
Table 'T5_CCI'. Segment reads 1, segment skipped 7.
CPU time = 15 ms, elapsed time = 9 ms.
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 0, ...
Table 'T5_CCI'. Segment reads 0, segment skipped 8.
CPU time = 0 ms, elapsed time = 0 ms.
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 22724, ...
Table 'T5_CCI'. Segment reads 8, segment skipped 0.
CPU time = 547 ms, elapsed time = 669 ms.
In some situations, there are obvious flaws in the optimizer, which painfully resemble an old bug in SQL Server 2008R2 (when pre-aggregation is faster than aggregation written in a more compact way):
DBCC DROPCLEANBUFFERS
SET STATISTICS IO, TIME ON
SELECT EOMONTH([DATETIME]), Cnt = SUM(Cnt)
FROM (
SELECT [DATETIME], Cnt = COUNT(*)
FROM [T5_CCI]
GROUP BY [DATETIME]
) t
GROUP BY EOMONTH([DATETIME])
SELECT EOMONTH([DATETIME]), Cnt = COUNT(*)
FROM [T5_CCI]
GROUP BY EOMONTH([DATETIME])
SET STATISTICS IO, TIME OFF
And such moments, to be honest, are in abundance:
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 64, ...
CPU time = 0 ms, elapsed time = 2 ms.
Table 'T5_CCI'. Scan count 1, ..., lob logical reads 32, ...
CPU time = 344 ms, elapsed time = 380 ms.
It will not be possible to consider all of them within the framework of this article, but much about what you need to know is perfectly provided at this blog. I highly recommend this resource for a deeper dive into the topic of Column-store indexes!
If the functionality is more or less clear and, I hope, I was able to convince with the examples above that they are often not a limiting factor for full-fledged development for Express Edition. But what about resource restrictions… I would say each specific case is decided individually.
Express Edition is allowed to use only 4 cores per instance, but what prevents us from deploying several instances within a server (for example, on which 16 cores), for each of them to fix their physical cores and get a cheap analogue of a scalable system, especially in the case of a microserver architecture – when each service works with its own copy of the database.
Missing a 1GB Buffer Pool? Perhaps it is worth minimizing physical reads by optimizing queries and introducing partitioning, Column-store indexes, or corny compressing data in tables. If this is not possible, then migrate to faster RAIDs.
But what about the maximum size of the database file, which cannot exceed 10GB, and when we try to increase it beyond the specified value, we expect to get an error:
There are several ways to work around this problem.
We can create several databases that will contain our own portion of historical data. For each of these tables, we will set a constraint and then combine all these tables within one view. This will give us horizontal sharding within a single instance.
USE [master]
GO
SET NOCOUNT ON
SET STATISTICS IO, TIME OFF
IF DB_ID('DB_2019') IS NOT NULL BEGIN
ALTER DATABASE [DB_2019] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [DB_2019]
END
GO
IF DB_ID('DB_2020') IS NOT NULL BEGIN
ALTER DATABASE [DB_2020] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [DB_2020]
END
GO
IF DB_ID('DB_2021') IS NOT NULL BEGIN
ALTER DATABASE [DB_2021] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [DB_2021]
END
GO
IF DB_ID('DB') IS NOT NULL BEGIN
ALTER DATABASE [DB] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [DB]
END
GO
CREATE DATABASE [DB_2019]
ALTER DATABASE [DB_2019] SET AUTO_CLOSE OFF, RECOVERY SIMPLE
CREATE DATABASE [DB_2020]
ALTER DATABASE [DB_2020] SET AUTO_CLOSE OFF, RECOVERY SIMPLE
CREATE DATABASE [DB_2021]
ALTER DATABASE [DB_2021] SET AUTO_CLOSE OFF, RECOVERY SIMPLE
CREATE DATABASE [DB]
ALTER DATABASE [DB] SET AUTO_CLOSE OFF, RECOVERY SIMPLE
GO
USE [DB_2019]
GO
CREATE TABLE [T_2019] ([A] DATETIME, [B] INT, PRIMARY KEY ([A], [B]))
ALTER TABLE [T_2019] WITH CHECK ADD CONSTRAINT [T_CK]
CHECK ([A] >= '20190101' AND [A] < '20200101')
GO
INSERT INTO [T_2019] VALUES ('20190101', 1), ('20190201', 2), ('20190301', 3)
GO
USE [DB_2020]
GO
CREATE TABLE [T_2020] ([A] DATETIME, [B] INT, PRIMARY KEY ([A], [B]))
ALTER TABLE [T_2020] WITH CHECK ADD CONSTRAINT [T_CK]
CHECK ([A] >= '20200101' AND [A] < '20210101')
GO
INSERT INTO [T_2020] VALUES ('20200401', 4), ('20200501', 5), ('20200601', 6)
GO
USE [DB_2021]
GO
CREATE TABLE [T_2021] ([A] DATETIME, [B] INT, PRIMARY KEY ([A], [B]))
ALTER TABLE [T_2021] WITH CHECK ADD CONSTRAINT [T_CK]
CHECK ([A] >= '20210101' AND [A] < '20220101')
GO
INSERT INTO [T_2021] VALUES ('20210701', 7), ('20210801', 8), ('20210901', 9)
GO
USE [DB]
GO
CREATE SYNONYM [dbo].[T_2019] FOR [DB_2019].[dbo].[T_2019]
CREATE SYNONYM [dbo].[T_2020] FOR [DB_2020].[dbo].[T_2020]
CREATE SYNONYM [dbo].[T_2021] FOR [DB_2021].[dbo].[T_2021]
GO
CREATE VIEW [T]
AS
SELECT * FROM [dbo].[T_2019]
UNION ALL
SELECT * FROM [dbo].[T_2020]
UNION ALL
SELECT * FROM [dbo].[T_2021]
GO
When filtering within the column on which the restriction is set, we will only read the data we need:
SELECT COUNT(*) FROM [T] WHERE [A] > '20200101'
what can be seen in the execution plan or in statistics:
Table 'T_2021'. Scan count 1, logical reads 2, ...
Table 'T_2020'. Scan count 1, logical reads 2, ...
In addition, due to restrictions, we are allowed to transparently modify the data within the view:
INSERT INTO [T] VALUES ('20210101', 999)
UPDATE [T] SET [B] = 1 WHERE [A] = '20210101'
DELETE FROM [T] WHERE [A] = '20210101'
Table 'T_2021'. Scan count 0, logical reads 2, ...
Table 'T_2021'. Scan count 1, logical reads 6, ...
Table 'T_2020'. Scan count 0, logical reads 0, ...
Table 'T_2019'. Scan count 0, logical reads 0, ...
Table 'T_2021'. Scan count 1, logical reads 2, ...
Table 'T_2020'. Scan count 0, logical reads 0, ...
Table 'T_2019'. Scan count 0, logical reads 0, ...
Applying this approach, we can partially solve the problem, but still, each individual database will be limited to the cherished 10GB.
Another option was specially invented for fans of architectural perversions – since the limitation on the size of the data file does not apply to system databases (master, msdb, model and tempdb), then all development can be done in them. But more often than not, this practice of using system databases as user databases is a shot in the foot from a rocket launcher. Therefore, I will not even paint all the pitfalls of such a decision, but if you still really want it, this will definitely guarantee you a quick pumping of the obscene vocabulary to the level of a foreman with 30 years of experience.
Now let's move on to a working solution to the problem.
We create a database of the size we need on the Developer Edition and make a detach:
USE [master]
GO
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
GO
CREATE DATABASE [express]
GO
ALTER DATABASE [express] MODIFY FILE (NAME = N'express', SIZE = 20 GB)
ALTER DATABASE [express] MODIFY FILE (NAME = N'express_log', SIZE = 100 MB)
ALTER DATABASE [express] SET DISABLE_BROKER
GO
EXEC [master].dbo.sp_detach_db @dbname = N'express'
GO
Create a base with the same name on the Express Edition and then stop the service:
USE [master]
GO
IF DB_ID('express') IS NOT NULL BEGIN
ALTER DATABASE [express] SET SINGLE_USER WITH ROLLBACK IMMEDIATE
DROP DATABASE [express]
END
GO
CREATE DATABASE [express]
GO
ALTER DATABASE [express] MODIFY FILE (NAME = N'express', SIZE = 100 MB)
ALTER DATABASE [express] MODIFY FILE (NAME = N'express_log', SIZE = 100 MB)
ALTER DATABASE [express] SET DISABLE_BROKER
GO
We move the files of our database from the Developer Edition to the place where the same database is located on the Express Edition, replacing some files with others. Launch an instance of SQL Server Express Edition.
Checking the size of our databases:
SET NOCOUNT ON
SET ARITHABORT ON
SET NUMERIC_ROUNDABORT OFF
SET STATISTICS IO, TIME OFF
IF OBJECT_ID('tempdb.dbo.#database_files') IS NOT NULL
DROP TABLE #database_files
CREATE TABLE #database_files (
[db_id] INT DEFAULT DB_ID()
, [name] SYSNAME
, [type] INT
, [size_mb] BIGINT
, [used_size_mb] BIGINT
)
DECLARE @sql NVARCHAR(MAX) = STUFF((
SELECT '
USE ' + QUOTENAME([name]) + '
INSERT INTO #database_files ([name], [type], [size_mb], [used_size_mb])
SELECT [name]
, [type]
, CAST([size] AS BIGINT) * 8 / 1024
, CAST(FILEPROPERTY([name], ''SpaceUsed'') AS BIGINT) * 8 / 1024
FROM sys.database_files WITH(NOLOCK);'
FROM sys.databases WITH(NOLOCK)
WHERE [state] = 0
AND ISNULL(HAS_DBACCESS([name]), 0) = 1
FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')
EXEC sys.sp_executesql @sql
SELECT [db_id] = d.[database_id]
, [db_name] = d.[name]
, [state] = d.[state_desc]
, [total_mb] = s.[data_size] + s.[log_size]
, [data_mb] = s.[data_size]
, [data_used_mb] = s.[data_used_size]
, [data_free_mb] = s.[data_size] - s.[data_used_size]
, [log_mb] = s.[log_size]
, [log_used_mb] = s.[log_used_size]
, [log_free_mb] = s.[log_size] - s.[log_used_size]
FROM sys.databases d WITH(NOLOCK)
LEFT JOIN (
SELECT [db_id]
, [data_size] = SUM(CASE WHEN [type] = 0 THEN [size_mb] END)
, [data_used_size] = SUM(CASE WHEN [type] = 0 THEN [used_size_mb] END)
, [log_size] = SUM(CASE WHEN [type] = 1 THEN [size_mb] END)
, [log_used_size] = SUM(CASE WHEN [type] = 1 THEN [used_size_mb] END)
FROM #database_files
GROUP BY [db_id]
) s ON d.[database_id] = s.[db_id]
ORDER BY [total_mb] DESC
Voila! Now the size of the database file exceeds the limit and the database is fully functional:
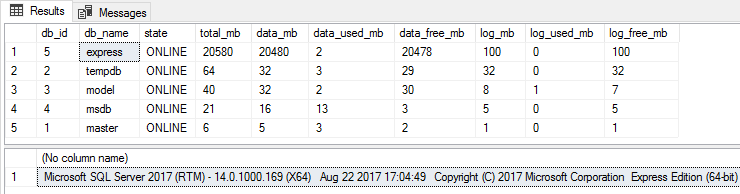
You may, as before, shrink it, create backups or change the settings of this database. Difficulties will arise only in cases when you need to restore the database from a backup or once again increase the size of the database file. In such situations, we can restore the backup to the Developer Edition, increase the size to the required size and then replace the files as described above.
Conclusion
As a result, SQL Server Express Edition is often undeservedly bypassed under the guise of resource restrictions and a bunch of other excuses. The main message of the article is that you can design a high-performance system on any edition of SQL Server.
Thank you all for your attention!
History
- 13th March, 2021: Initial version