
Introducing Jupyter and Pandas
5.00/5 (12 votes)
This article is the first in the Data Cleaning with Python and Pandas series that helps working developers get up to speed on data science tools and techniques.

Series Overview
This article is the first in a series that helps working developers get up to speed on data science tools and techniques. We’ll start with a brief introduction to the series, and explain everything we’re going to cover.
Developers and data scientists working on data analysis and machine learning (ML) projects spend the majority of their time finding, cleaning, and organizing datasets. In this introductory series, we will walk through some of the most common data cleaning scenarios, including:
- Visualizing "messy" data
- Reshaping datasets
- Replacing missing values
- Removing and fixing incomplete rows
- Normalizing data types
- Combining datasets
We'll do this by using Python, Pandas, and Seaborn in a Jupyter notebook to clean up a sample retail store's messy customer database. This seven-part series will take the initial round of messy data, clean it, and develop a set of visualizations that highlight our work. Here’s what the series will cover:
- Part 1 - Introducing Jupyter and Pandas
- Part 2 - Loading CSV and SQL Data into Pandas
- Part 3 - Correcting Missing Data in Pandas
- Part 4 - Combining Multiple Datasets in Pandas
- Part 5 - Cleaning Data in a Pandas DataFrame
- Part 6 - Reshaping Data in a Pandas DataFrame
- Part 7 - Data Visualization using Seaborn and Pandas
Before we start cleaning our dataset, let's take a quick look at two of the tools we’ll use: Pandas and Jupyter Notebooks.
What is Pandas?
Pandas is a flexible, high-performance, open-source Python library built specifically to provide data structures and analysis tools for data scientists.
As a developer, you’ll find that Pandas is like a programmatic, GUI-free Excel. When you import data into a Pandas, you get a DataFrame object that represents your data as a series of columns and rows — much like you’d see in an Excel worksheet.
This makes it very easy to analyze and clean up data sets. Performing operations like removing rows that don’t meet certain criteria, automatically removing columns that have too many missing values, or adding new columns calculated from existing columns can usually be done with a single function call.
Working with tables of data this way — by cleaning and transforming the data using clean, easy-to-understand Python — is usually much quicker and more portable for developers than point-and-click your way through complex, built-in Excel functions or writing custom VBA code.
What is Jupyter?
Jupyter is a web application that acts like a container for data science projects. It allows you to put data, code, visualizations, documentation, and more into a single notebook.
I’ll be honest, if you’re an experienced software developer who is accustomed to an IDE like Eclipse or a text editor like Visual Studio Code, Jupyter is going to seem weird.
Jupyter is, essentially, a modern reincarnation of Donald Knuth’s Literate Programming. Literate programming aims to break down the barriers between code and natural language. In a typical literate programming file, programming code is interspersed with prose in a natural English-like language that describes what the code does.
This approach might sound repugnant to modern developers. After all, shouldn’t your code be so clear and self-explanatory that it doesn’t need comments?
That may be true for ordinary, mechanical code where it’s clear what is going on. But the situation is different when you’re writing code for data science and machine learning projects. In these scenarios, you’re often writing code that’s going to be consumed by a wider audience including data scientists, business analysts, and even managers.
In those cases, your code alone isn’t enough. Even if the reader understands the code, you must add prose to give context to your code — to help readers understand why you wrote the code you did, and understand how your code is transforming the data it imports.
Jupyter Notebooks take literate programming a step further. Not only is it easy to write a document that alternates between prose and code, the code is also live and executable. You can run the code and observe its output from inside the document. Even better, colleagues who have a copy of your notebook can edit your code, re-run it, and observe the new output — all without leaving the notebook. A notebook that contains code, prose, and output looks something like this:
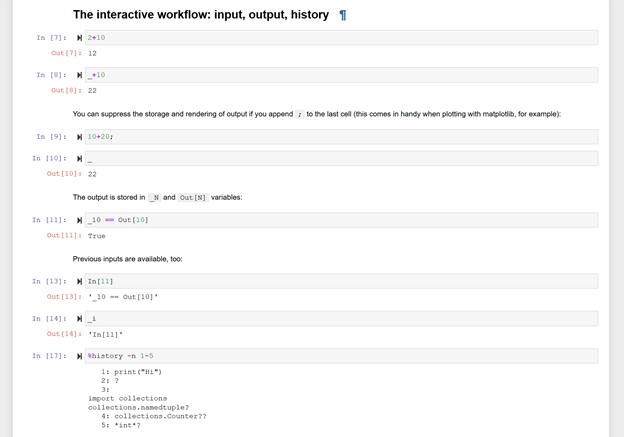
Don’t just take my word for it, though. You can find a live, interactive, editable online Jupyter Notebook to experiment with here.
If this weren’t enough, Jupyter makes it easy to embed charts and other visualizations in the document. So if, for example, you import data from a database, transform it, and then want to easily share the results, you can feed your data into several different visualization libraries and the charts they generate will appear right in the notebook.
You can even embed Markdown, videos, and mathematical equations using LaTeX or MathML.
Last, but not least: Jupyter is language agnostic. Although Python is the most common use case, you can embed and run many programming languages in your notebooks. These include Julia, R, and even Java, C#, and F#. If you’re a .NET developer, Scott Hanselman has written a great introduction to Jupyter Notebooks for you.
Installing Jupyter and Pandas
Now that you’re (hopefully) excited about Jupyter and Pandas, I’m going to show you the easiest way to get started.
The best way to get Jupyter, Pandas, and other libraries we'll need for future data analysis tasks is to install Anaconda. It’s a Python distribution for data science that comes preloaded with the most popular libraries. This is one of the easiest ways to get up and running with data science using Python.
I know Anaconda is a big install at over 400MB. While you absolutely can install Python, Jupyter, and Pandas separately, I’m asking you to trust that this is the easiest way to install everything with minimal pain. In addition, if you decide to continue your data science journey after working through this series, you’ll find that Anaconda has already set up most of the tools you’ll need.
You can find an Anaconda package for your operating system on the Anaconda download page. Follow the download and install instructions. Once the install is complete, you’ll find that the installer set up an application called Anaconda Navigator. In Windows, it’ll be in the start menu. On MacOS, it’ll be in your Applications folder. On Linux, you can run it by opening a terminal and running the following command: anaconda-navigator.
Next, we’ll start up our own Jupyter Notebook.
Using Anaconda Navigator, open Jupyter Notebook and create a new notebook. A notebook can be thought of as a simplified version of what other IDEs call a project — as we discovered above, it’s a collection of code, prose, and multimedia.

When you first open a Jupyter Notebook, you’ll see a single line consisting of In [ ]. This is a code cell. Each cell can contain either code run by the notebook’s kernel or information to be displayed.
Each notebook has an associated kernel, which is the runtime used to compile the code within the notebook. The default is Python, and in most cases it’s the language used, but you can use a number of other languages as well.

You can also change a code cell to a documentation line by switching the code dropdown to markdown.
Setting Up and Importing Libraries
It’s important to note that items set and manipulated in one cell are available in the preceding cells. This allows you to break up the code in your notebooks and keep projects more organized. Because of this behavior, it’s common to use the first cell in a notebook to hold all the generic setup and library imports that will be used across the notebook.
Since we will be loading and manipulating data with some specific Python libraries that are already included in the Anaconda suite of products, let's set them up by importing them into our Jupyter notebook by adding the following to the first code cell. You can add a code cell to your document by clicking the  button.
button.

Once you’ve added the code cell, put the following code in it:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
If you hover your mouse over the square brackets beside the code cell, you’ll see a play button that lets your run the code in the cell. This won’t do much at the moment since we’re just importing some libraries, but don’t worry, we’ll have plenty of code to run soon.
As you can see, we’re importing four libraries:
- Pandas, the data analysis library
- NumPy, a dependency of Pandas (we won't be using this directly)
- Matplotlib, a data visualization library
- Seaborn, which adds a number of visual improvements to matplotlib
Additionally, the last line sets a default style for Seaborn. Let’s save our Notebook by going File, Save As and entering a file path. It’s worth noting that Jupyter will base its file system from your profile directory. On Windows, this is C:\Users\<username>.

Review
We’ve learned about what Pandas and Jupyter are, and why we might want to use them.
Then, we learned how to set up our own data science ready development environment using Anaconda.
We finished up by taking a quick look at using Jupyter Notebooks to set up our Python-based data analysis project and imported a few Python libraries, including Pandas for data structures and Seaborn for data visualization.
Next up, we’ll load our external data source into a data structure provided by Pandas and start analyzing and manipulating our base data set.
Jupyter image source: https://www.dataquest.io/blog/jupyter-notebook-tutorial/