
Yet Another Concurrent Expression Evaluator
5.00/5 (3 votes)
High-performance expression evaluator that allows filtering large number of messages
Introduction
When I recently started implementing a log viewer, I could not find a complete working example of high-performance expression evaluator that allows filtering large number of messages in a log based on expression provided by a user. So I decided to write my own expression evaluator and publish its source code for everyone’s benefit. I chose Yacc/Bison for parsing the user expressions since I learned it in the school (MIET). I also chose boost::thread since it is portable and compatible with C++0x standard.
To compile the code, I used:
- Visual Studio 2005 with Service Pack 1
- Boost 1.39. The installation module for Windows can be downloaded from http://www.boostpro.com/download. I selected
boost::threadandboost::regexoptions during installation. A custom build rule is used in VS to build “.y” files (see bison.rules).
Goals and Definitions
The expression evaluator should be able to accept a filter expression from user and apply it to variable length messages in order to determine which message satisfies the filter criteria. Each message contains the same number of fields of numeric, date, enumeration and string types. I've created a custom SQL messages log format specifically for the purposes of the article. The following table explains the format:
| Field No | 1 | 2 | 3 | 4 | 5 | 6 |
| Name | Time | SQLType | ClientSQL | Parse | Execute | Rows |
| Type | Date | Enum | String | String | Number | Number |
| Size | 8 | 2 | (variable) | 8 | 8 | 4 |
User expression consists of one or more conditions connected via logical operators. Each condition can include a Field Name and Numeric, Enum or String constants.
- Example 1. Find messages with Execute field larger than 1.0: Execute > 1.0
- Example 2. Find messages of type ERROR: SQLType = ERROR
- Example 3. Find messages with SQL field started with “
SELECT”: SQL ilike '^SELECT(.)+' - Example 4. Find SQL schema alterations with execution time longer than 1ms: (ClientSQL ilike 'Alter(.)+' || ClientSQL ilike 'Create(.)+' || ClientSQL ilike 'Drop(.)+') && SQLType != ERROR && Execute > 1.0
Note: string constant can contain regular expression (see boost::regex here).
The demo console application accepts a user expression and input/output files names via command line. It can read a file with arbitrary number of messages and writes filtered messages to the output file. It can also generate binary log files with test messages and can convert a binary log file into text representation. Here are command line parameters:
F:\src\yacee>debug\yacee.exe -h
USAGE:
F:\src\yacee\debug\yacee.exe {-f <string>|-g <int>|-p <string>} [-e
<string>] -o <string> [--] [-v] [-h]
Where:
-f <string>, --filter <string>
(OR required) (value required) Filter the log file.
-- OR --
-g <int>, --generate <int>
(OR required) (value required) Generate test log file with the
specified number of messages.
-- OR --
-p <string>, --print <string>
(OR required) (value required) Print content of the log file.
-e <string>, --expression <string>
(value required) Expression to use for filtering the log. The option
should be used with -f option.
-o <string>, --output <string>
(required) (value required) Redirect output to the file.
Sequential Filter Implementation
Yacc/Bison grammar for expression is very simple:
exp: NUM { $$ = $1; }
| VAR { $$ = $1->value.var; }
| VAR like STRING { $$ = driver.IsLike($1, $2, $3->c_str()); }
/* note: = and == are the same, i.e. "is equal" operator */
| VAR '=' NUM { $$ = ($1->value.var == $3); }
| VAR "==" NUM { $$ = ($1->value.var == $3); }
| VAR '=' STRING { $$ = 0 == strcmp($1->value.pstr, $3->c_str()); }
| VAR "==" STRING { $$ = 0 == strcmp($1->value.pstr, $3->c_str()); }
| VAR "!=" NUM { $$ = ($1->value.var != $3); }
| VAR "<>" NUM { $$ = ($1->value.var != $3); }
| VAR "!=" STRING { $$ = 0 != strcmp($1->value.pstr, $3->c_str()); }
| VAR "<>" STRING { $$ = 0 != strcmp($1->value.pstr, $3->c_str()); }
| exp "||" exp { $$ = ($1 != 0.0) || ($3 != 0); }
| exp "&&" exp { $$ = ($1 != 0.0) && ($3 != 0); }
| VAR '>' exp { $$ = $1->value.var > $3; }
| VAR '<' exp { $$ = $1->value.var < $3; }
| VAR ">=" exp { $$ = $1->value.var >= $3; }
| VAR "<=" exp { $$ = $1->value.var <= $3; }
| exp '+' exp { $$ = $1 + $3; }
| exp '-' exp { $$ = $1 - $3; }
| exp '*' exp { $$ = $1 * $3; }
| exp '/' exp { $$ = $1 / $3; }
| '(' exp ')' { $$ = $2; }
| '-' exp %prec NEG { $$ = -$2; }
| '!' exp %prec NOT { $$ = !($2); }
;
like: "like" { $$ = 0; } | "ilike" { $$ = 1; } | "not" "like" { $$ = 2; }
| "not" "ilike" { $$ = 3; }
Lexemes Scanner
Initially I considered writing a lexical scanner and using lexer.exe from Cygwin package. However, since an expression can include only few simple lexemes such as numeric values, identifiers, arithmetic and logical operators, it is even easier to write a C procedure to convert an expression text into list of lexemes.
The implementation of the lexemes scanner can be found in BuildLexemes() method of Driver class. The lexemes are stored in _lexemes array of CLexeme objects declared as:
std::vector<CLexeme> _lexemes;
class CLexeme
{
public:
Parser::token::yytokentype _type;
LexemeVal _val;
CLexeme() : _type(BISLEX_EOF)
{}
CLexeme(Parser::token::yytokentype type, LexemeVal val) : _type(type), _val(val)
{}
CLexeme(Parser::token::yytokentype type) : _type(type)
{
_val.sVal = 0;
}
};
union LexemeVal
{
std::string* sVal;
double dVal;
CVariable* vVal;
};
LexemeVal holds a lexeme value. sVal is used for string literals; dVal – for integer and floating point numbers; CVariable – allocated when an existing field name recognized.
Filter Loop
The sequential filter processes input messages from rgMessageOffsets array and stores messages that satisfy expression into rgFilteredMessages array. Here is the main filter loop from FilterLog procedure:
Driver driver;
vector<LONG> rgFilteredMessages;
if (driver.Prepare(filter, "input")) // parse expression
{
for (size_t i=0; i < rgMessageOffsets.size(); i++)
{
SetVariables(logStart + rgMessageOffsets[i]);
if (driver.Evaluate())
{
err = 3; // failed to apply filter
goto Cleanup;
}
if (driver.bisrez != 0.0)
{
rgFilteredMessages.push_back(rgMessageOffsets[i]);
}
}
}
else
{
err = 4; // invalid expression
goto Cleanup;
}
The main loop fetches messages one by one, calls SetVariables procedure to copy values from a message into filter driver buffer, calls Evaluate method and stores the message if the driver state ‘bisrez’ is not equal to zero. The following diagram demonstrates the control flow:
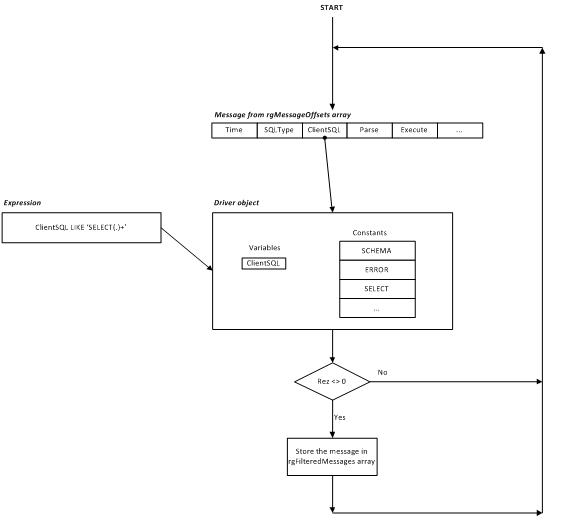
The expression evaluation is performed by Parser::parse method called from Driver::Evaluate. Its performance was good enough for the purposes of my application (see benchmarks at the end of the article). The expression evaluation can be optimized by the introduction of an efficient execution plan. However, this is beyond the scope of the article.
Concurrent Filter Implementation
I chose a simple approach to concurrent filter design. I used a thread per processor in PC and made the main thread work as well:
SYSTEM_INFO systemInfo;
GetSystemInfo(&systemInfo);
if (systemInfo.dwNumberOfProcessors > 1)
{
CDriverThread** threads = (CDriverThread**)_alloca
((systemInfo.dwNumberOfProcessors-1) * sizeof(CDriverThread*));
for (unsigned i=0; i < systemInfo.dwNumberOfProcessors-1; i++)
{
threads[i] = new CDriverThread(logStart, rgMessageOffsets, GetNext, filter);
threads[i]->Go();
}
driverThread.DoWork();
// At this point the main thread had finished filtering,
// but some threads may not have finished yet.
// We have to wait for those threads to finish.
for (unsigned i=0; i < systemInfo.dwNumberOfProcessors-1; i++)
{
threads[i]->Join();
delete threads[i];
}
}
else
{
// This is a single CPU system. Filtering is performed in the current thread.
driverThread.DoWork();
}
Filtering of all the messages could be equally separated among the threads. But some of the CPU cores could be used by other applications and it can result in unnecessary waiting time by those threads which finished the filtering first. To prevent the waiting, each thread processes small number of messages at a time (128 messages). Callback function GetNext is used to get next piece of work:
typedef void (*GetNextFunc)(vector<LONG>** pprgFilteredMessages,
int& startIndex, int& count);
typedef vector<LONG> MessagesArray;
static MessagesArray rgMessageOffsets; // storage for all messages
static boost::mutex mymutex;
static int workStart; // index of next available work
static map<int, MessagesArray*> mapFilteredMessages;
// Callback function a thread uses to obtain next piece of work
void GetNext(vector<LONG>** pprgFilteredMessages, int& startIndex, int& count)
{
MessagesArray* prgFilteredMessages = new MessagesArray();
{
boost::mutex::scoped_lock l(mymutex);
if (workStart < (int)rgMessageOffsets.size())
{
mapFilteredMessages[startIndex = workStart] =
(*pprgFilteredMessages = prgFilteredMessages);
workStart += (count = min(WORK_SIZE,
(int)rgMessageOffsets.size()-startIndex));
return;
}
}
// no work is left
*pprgFilteredMessages = 0;
startIndex = count = 0;
delete prgFilteredMessages;
}
The first parameter pprgFilteredMessages is used for returning the filtered messages and assembling the final result. We want to preserve time ordering of the filtering messages. One possible option was to store filtered messages in a global array and sort it by time field. This approach is often used in supercomputers and cluster computers with distributed memory architecture. Another approach is to get advantage of PC shared memory architecture and populate result so that it is automatically sorted. This approach is implemented in GetNext function and the following lines (responsible for storing result in output file):
// assemble filtered messages from pieceses and write them to the output file
for (int start=0; start < (int)rgMessageOffsets.size(); start += WORK_SIZE)
{
MessagesArray* prgFilteredMessages = mapFilteredMessages[start];
n = (*prgFilteredMessages).size();
for (unsigned i=0; i < n; i++)
{
const BYTE* baseAddr = logStart + (*prgFilteredMessages)[i];
...
WriteFile(hOutFile, baseAddr, msgLen, &numBytes, 0);
}
}

Other
The test log files generation and conversion of log files into text representation are implemented in GenerateLog.cpp and PrintLog.cpp files. The code is pretty simple and straightforward. See batch files that generate, filter and print log files.
Benchmarks and Conclusion
The development and benchmarking were performed on a PC with the following configuration:
- CPU: Intel Core i7 950 @ 3.07GHz, Hyperthreading enabled
- Memory: DDR3 6144MB 2138MHz 4-7-7-20
- Mainboard: ASUS P6T
- Hard drives: Disk_C WD 500GB Black RAID1; Disk_D WD 640GB Black RAID1
The following table shows performance for single-thread and multi-thread expression evaluation:
| Test | Single-thread, ms | Multi-thread, ms | Msg count |
| 10p3 | 34 | 8 | 1000 |
| 10p4 | 212 | 42 | 10000 |
| 10p5 | 1400 | 353 | 100000 |
| 10p6 | 13720 | 3305 | 1000000 |
| 10p7 | fail | fail | 10000000 |
I’ve run the tests with Intel hyper-threading (HT) enabled and disabled, and found that performance was the same (which was expected).
The article described an expression evaluator that can be used for filtering large number of messages in a log. The evaluator can easily be extended to support more complex or different expressions. The attached source code can be compiled in Visual Studio 2005 or later. Parallel expression evaluation allows significantly faster filtration. The performance grows linearly to the number of CPU cores in a system.
History
- December 2009. Initial draft written