
Fast Circle Coordinate Mapping and Color Wheel Creation: Part 2 – Code
4.68/5 (7 votes)
Part 1 of this article discussed an algorithm for addressing all pixels within a circle with surgical precision, optionally expanded to filling in those pixels as required to create a color wheel; this is part 2 of 2, covering the actual implementation.
A Note on HSL
HSL, or Hue, Saturation and Lightness, is a system for specifying color that closely resembles the logic used to generate this color wheel. The main difference is the weighting in the distribution of colors. HSL uses only 3 “slices” around the wheel for red, green, and blue, making it potentially more difficult to specify the four remaining colors across the rainbow, which receive considerably less real estate on the wheel in that system.
“Don’t Hate Me Because I’m Beautiful”
All of the following code discussed is assembly language code. This may cause many readers to shake their heads in disgust. The reasons why assembly language is used are twofold: first, it’s my own native language. Beyond the rare cases of extenuating circumstances, assembly is all I program in. It’s what I know, and therefore it offers the highest likelihood for the code presented to be error-free. Second, in today’s world, there are so many languages used by developers that native Intel/AMD assembly is a logical choice for a generic presentation that just about everyone can either understand or decipher. The instructions are so direct and simple, and memory access is so void of cryptic casting and declarations, that using ASM is (in my opinion) the best option for creating a generic presentation that everyone can live with.
The material in this (part 2) article is exceedingly technical, reaching deep into the specific behaviors of SSE instructions. If you begin to experience road hypnosis going through it, then it’s recommended that you reference the material only where necessary; when you see something in the code that you don’t immediately grasp.
Minimum Requirements
The minimum iteration of SSE for this code is SSE2. Many times in the code that follows, integers are loaded into the XMM registers, then converted into 32-bit single-precision floats. Any 64-bit processor from Intel or AMD will support the SSE2 instruction set, which is why the infinitely more advanced AVX instructions were not used: this article is a learning tool and I wanted the widest range of hardware compatibility for the code presented.
Well, Isn’t That Odd…
DANGER WILL ROBINSON! If you model actual code off the sample code shown here, USE AN ODD RADIUS VALUE FOR YOUR COLOR WHEEL! If you don’t, there will be any number of issues with the wheel created. An odd value radius allows for a single pixel in the center of the color wheel. All of the code presented here makes the assumption that the radius is an odd number.
Initial Data
A cardinal rule for me is to avoid memory hits whenever possible. They are not free, and when coding for performance, which is always my top priority, memory access is the first thing to be avoided. This plays out in the code that follows. While memory hits have not been reduced to absolute zero, they are nonetheless few and far between. When possible, often-used float values that will remain constant across the main loop are stored in XMM registers to avoid having to continually reload them. I’ve even gone so far as to store the running y coordinate in XMM1, and XMM4 retains a float value of 1.0 just for decrementing y each loop pass.
Beyond this, I look at which values are being moved to where, in a general sense, and take steps to minimize that movement when possible. Especially important is avoiding recalculation of values that will always yield the same, or predictable, results through each iteration of the loop. For instance ( r ^ 2 ) will be applied to every pixel’s calculations. High level code would most likely end up compiling to calculate the value every loop pass because it’s not immediately obvious that the redundancy is occurring. In assembly, it’s glaring.
In the code to follow, I reserve the XMM0 register to hold ( r ^ 2 ). It’s calculated once before the loop begins, and the register is only ever read after that point until the loop completes. XMM1 holds the current y coordinate, and XMM4 is initialized at a float value of 1.0. XMM4 is used exclusively through the life of the loop for decrementing XMM1. So XMM1 always holds the single-precision float (32 bits) representation of the current y coordinate. Memory never needs to be accessed for these values. The variable SliceSize holds the value 360 / 7, which again remains constant. In my code, SliceSize is initialized to 51.4285714285714285714285714286. It’s yet another value that will be needed every pass and won’t have to be reloaded from memory.
The code below shows the data declarations for all values used in the color wheel generation code that are stored in memory. Note that for ease of reference, I’ve mixed constant equates in with variable declarations. It isn’t how I normally do things, but the ML64.EXE compiler (as most or all other ASM compilers) will accept equates anywhere, code or data, so all the declarations are presented in one place.

The above declarations should be more or less self-explanatory. EQU is a constant equate. A data type of REAL4 is a 4-byte or 32-bit single-precision floating point value.
The FPU, which is used to obtain the angle for a pixel with the FPATAN instruction, only takes values from memory (except for a few special instructions). The BCW_Value variable is used for this purpose.
Creating the Bitmap
The code shown below handles creation of the bitmap that holds the color wheel.

Line 7 shows the C equivalent of lines 9 and 10. This section creates the device context BCW_dc, which is required for the CreateDIBSection function call.
WC is my own ASM macro for calling a Windows function using the 64-bit calling convention. The first four parameters passed to any Windows API function must be contained in the RCX, RDX , R8, and R9 registers, respectively. This macro accepts a variable number of parameters and sets up the call as required for compliance with the 64-bit convention. For any other language besides ASM, the developer should not need to be concerned with this process; simply call the function as you normally would.
With the device context created, lines 24 through 27 zero the BCW_BMI structure (a BitmapInfo structure which must be passed, initialized, to the CreateDIBSection function). Line 22 shows the C equivalent of this function.
Lines 31 through 35 initialize the relevant fields of the BitmapInfo structure. Only the fields required for the call are filled in. The constants CWheel_Width and CWheel_Height are the same for the square bitmap that will hold the color wheel. Separate constant names are used only for clarification since the cost to the compiled app for doing so is zero. Note that the biHeight field is set to -CWheel_Height. Specifying a negative height creates a top-down bitmap in memory. This is critical for the section of code that handles writing the actual pixels.
Lines 41 through 45 handle setting the required parameters and calling CreateDIBSection. Line 39 shows the C version of this call, and barring an error, line 53 saves the handle for the bitmap into CWheel_hBmp.
Once the bitmap is created, CWheel_pBits can be used to write pixel data directly to the bitmap. There is one DWORD value per pixel. For a flood fill of the entire bitmap, lines 65 through 68 set the write pointer RDI to point at the first pixel of memory, the store count is set to CWheel_Width * CWheel_Height (the number of pixels in the bitmap), register EAX (the lower 32 bits of register RAX) is set to 0xFF000000h for full opacity alpha and a color of black. Line 68 actually fills the bitmap.
The Main Processing Loop
The code below is the main loop that generates and processes the pixel location “strips.” It increments through y from ( radius – 1 ) to 1, setting the value for x each pass; x is passed to the handler function which processes all pixels at y from -x to x.
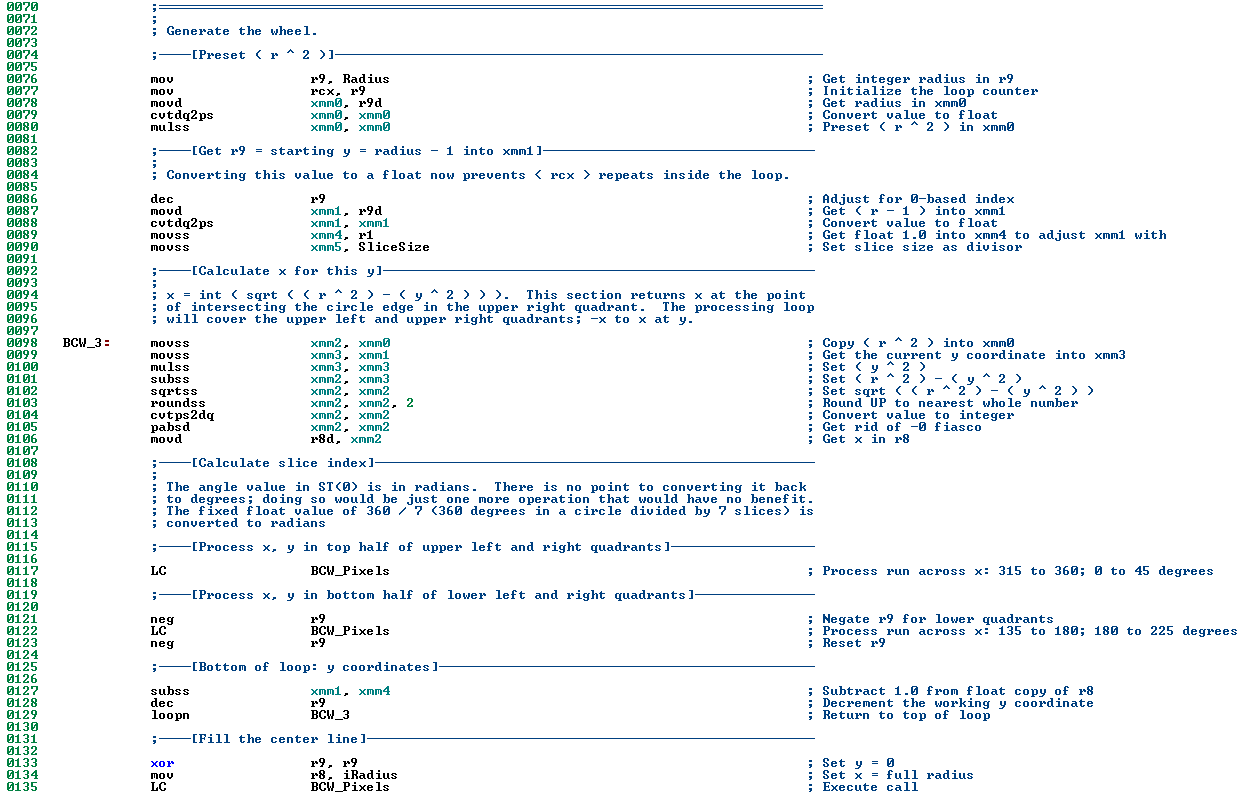
Line 77 initializes the counter for the loop to process y coordinates from ( radius – 1 ) to 1, inclusive. R9 is a general register that can be assigned integer values directly or from memory. In this case, the integer variable Radius, already initialized to the circle’s radius, is placed into the R9 register. R9 is then copied into register RCX; making the loop counter the same as the starting value for y. Note that RCX is a one-based loop count, not a 0-based y coordinate. The ASM LOOP instruction decrements RCX (this is hardwired behavior) and jumps to the top of the loop if RCX > 0. Shortly, R9 will be decremented (R9--) to enter the main loop as the 0-based y coordinate.
Line 78 moves the Radius value from the R9d register into the XMM0 register. R9 is a 64-bit register; R9d represents the lower 32 bits of R9. The XMM registers LOGICALLY consist of four “slots” or “parts” of 32 bits each, so a 32 bit value needs to be moved into XMM0 when moving from a general register.
Since the value in R9 came from the integer value Radius, it’s still stored as an integer in XMM0 and needs to be converted to a floating point value after being loaded into XMM0. This is done on line 79 with the CVTDQ2PS instruction. The second XMM0 in this instruction tells the CPU what to convert; the first parameter (also XMM0) tells it where to store the result.
Line 80 multiplies XMM0 (the second parameter) by itself (the first parameter) and stores the value in the first parameter (XMM0). This leaves ( radius ^ 2 ) in XMM0. This value will remain in XMM0 and will not change across the life of the loop. This is done so that it doesn’t require recalculating every pass when the result will never change.
So far, R9 has been equal to Radius. Line 86 decrements the value to become the 0-based y coordinate. The value is then moved into XMM1 in line 87, then converted to a single precision floating point value in line 88.
Line 89 moves the floating point value r1 (a fixed value of 1.0) into XMM4. This is used to decrement XMM1 each loop pass. This is done with the MOVSS instruction, which loads only the low 32 bits (a scalar value) of an XMM register from memory. Following this, on line 90, the value SliceSize, a floating point variable holding 360/7, is loaded into XMM5.
All of this preloading and precalculation is done once, before the main loop begins. Once inside the loop, x is calculated for each value of y, and the callout process of BCW_Pixels is executed. The BCW_Pixels handler takes care of looping between -x and x; it only requires the current x and y to be passed as parameters.
The Main Loop
In case you’re wondering what happened to labels BCW_1 and BCW_2, they were jump destinations for error handling which was replaced with a comment for this article.
Lines 98 through 106 take the float value of the current y coordinate from XMM1, and the value for ( radius ^ 2 ) in XMM0, and calculate the x coordinate for x, using the current y, in the upper right quadrant of the circle. The equation x = int ( sqrt ( ( r ^ 2 ) - ( y ^ 2 ) ) ) is executed to determine x for the current y. When the BCW_Pixels handler receives x and y, it runs through each value for x from -x through x.
XMM2 and XMM3 are used as work registers because XMM0 and XMM1 are protected by this loop – their values are kept intact and unaltered.
Note line 105 setting the final value for XMM2 to its absolute value. Do not skip this line in your code. SSE has an apparent infatuation with creating -0 results. When this goofy value is converted to an integer in a general register, it ends up being stored as 0x80000000 which destroys proper calculations.
A float value for x is not used. The integer value is moved into register R8d. The BCW_Pixels callout requires x in R8 and y in R9. As long as the high 32 bits in both registers are clear, the 64-bit values in R8 and R9 will be the same as their 32-bit counterparts in R8d and R9d respectively.
With the angle in XMM2, x in R8d and y in R9d, BCW_Pixels is called on line 117 to process the row of pixels at y from -x to x.
Assembly language allows calls to any code in an app. Like the WC macro, my LC (Local Call) macro is simply an alias for CALL. There is no requirement for formatting the callee as a function. The only caveat to remember is that if a chunk of code is to be called from within the same function it resides in, it cannot return with a RET statement. The compiler will see that and freak out, attempting to close out the function hosting the callee. It tries to destroy the stack frame that the function uses, lose RBP (which is the base pointer for all local variables), and the app either crashes or moves into high weirdness mode if it compiles at all. I use a single-line macro called LocalRet, which is simply a byte declaration of 0xC3. This is the opcode for a near RET statement.
Lines 121 through 123 negate y in R9, call BCW_Pixels again, then negate R9 a second time to undo the first negate.
Remember that XMM4 holds a float value of 1.0. Line 127 subtracts this value from XMM1 (the running y coordinate) to decrement that coordinate. The sister integer y coordinate in R9 is also decremented.
The original 8088 set the maximum distance for a LOOP instruction target to be 255 bytes away ( a short jump). If a jump target farther than that is specified, the compiler issues an error because it can only encode 8 bits of destination data, as a relative offset, in the instruction. For some reason, more than 40 years after the Intel architecture’s initial design, this restriction remains. No suitable replacement instruction was ever created for expanding the jump range. (This was likely because the use of assembly fell out of favor some time around the demise of King Tut.) To compensate, I use the 2-line macro called LOOPN, which decrements RCX and jumps to the top of the loop as long as it’s > 0. This macro is invoked on line 129.
The process closes out with the center line of the circle, y = 0, processed “manually” outside the loop because there is no matching lower quadrant to process if the radius is an odd number.
The BCW_Pixel Callout
In covering the BCW_Pixel callout, sections of code will be referenced as opposed to individual lines. Enough of a knowledge base should be established at this point where only instructions not seen before need to be covered individually.
Figure 4 shows the BCW_Pixels callout used to process the row of pixels for each iteration of y.

Line 512 saves the RCX register on the stack because it’s in use as the main loop counter for the caller. RCX will be restored immediately before returning from the callout.
RAX is a 64-bit register; EAX is the lower 32 bits of RAX. Intel 64-bit architecture automatically clears the high 32 bits of a general register when a 32 bit value is moved into its low 32 bits. This behavior has its benefits and its problems, but it has to be worked with since it’s hardwired into the CPU.
Lines 513 through 518 perform the task of setting the incoming x coordinate in R8d to a negative value. Bit 31 of the 32-bit value is shifted into bit position 0, clearing all but that bit position. If R8d is negative, the value will be one, otherwise zero. The bit is then shifted left one bit so that a negative R8d will be 2 and a positive will be zero. Finally, the value is decremented to make a negative value 1 and a positive value -1. Multiplying R8d by this value leaves a negative value as-is and changes a positive value to negative. Remember that 32-biti values are stored in twos-complement so there’s more to flipping the sign of a value than simply toggling the sign bit.
Bitwise instructions are among the lowest cycle count instructions to execute; a simple compare/jump instruction pair would flush the CPU’s prefetch queue and force it to refill.
With the x coordinate in R8d forced negative, line 525 sign-extends the value to 64 bits. This is critical for using RCX as the loop counter; without this step, RCX would end up holding an extremely large 64-bit value: garbage in the high 32 bits and the actual counter in the low 32 bits. Line 526 negates the value, making RCX a positive count for the incoming value of R8d. Shifting this value left by 1 bit in line 527 doubles the value, since the process will run ( 2x ) times, from -x to x.
Line 534 is the top of the actual process loop from -x to x.
Lines 534 through 547 utilize the FPU to obtain the angle between the 0, 0 center point and the current x, y location. The FINIT instruction is issued on line 534 only because Intel documentation says it should be done. The FPU only has 8 registers (ST(0) through ST(7)) and they work as a stack. Each time FLD or any other FPU instruction placing a value into ST(0) does so, ST(6) is pushed down to ST(7), ST(5) is pushed down to ST(6), and so forth. The FPU starts generating exceptions when its stack overflows so it can’t be used indefinitely without specifically clearing values off the top of that stack. Issuing FINIT is per spec, and it’s a lot simpler than implementing ongoing tracking of the FPU stack to take out the garbage.
The FPU will only load values from other FPU registers or from memory.
On line 535, the x coordinate is moved from R8d into the variable BCW_Value so that the FPU can load it. FILD (on line 536) tells the FPU to load an integer value; conversion to a floating point value is automatic when the FPU is loading integer values. The y coordinate is then moved from R9d into BCW_Value on line 537, and line 538 loads it into ST(0), moving the previously loaded x coordinate from ST(0) down to ST(1).
Per Intel documentation, the FPATAN instruction divides ST(1) by ST(0), stores the result in ST(1), then pops the register stack, moving the result to ST(0). After the FPATAN instruction on line 539, line 540 pops the angle for the current pixel off ST(0) and places it in BCW_Angle. Since the value was moved with FSTP and not FISTP, it’s stored in memory as a 32-bit float. Line 541 can then load the angle as a float into XMM2 with no conversion being required.
Line 542 necessarily divides the angle – which the FPU returned as radians – by the radians per degree count to convert it to degrees.
Lines 543 and 544 execute one of only two compare/jump instruction pairs in the code. Bit testing inside XMM registers is possible, but it was implemented in a very strange way, setting all bits in the XMM register if the compare is true otherwise clearing them. With this setup, the values have to be retrieved and examined, and there’s little choice but to perform a conditional jump anyway. The point of lines 543 through 547 is to set a negative angle to (360 – angle).
Lines 553 through 555 set the value of SliceIndex to ( 7 * angle ) / 360; this is a rework of calculating angle / ( 360 / 7 ). Recalling that XMM5 holds the float result of 360/7, the angle is divided by this value. This process is taking the long way around to calculating the remainder of angle / ( 360 / 7 ). This is necessary because SSE won’t give up remainders. The third operand in the ROUNDSS instruction on line 555 specifies truncation; drop any decimal regardless of its value and round the result down to the next lower whole number. This is the same as 360 % ( 360 / 7 ).
Lines 559 through 563 multiply this whole number (the slice index) back up to some number of degrees and subtract that result from the original angle, leaving only the remainder. The remainder is used to determine how far into the target slice to move; this will give the final color.
Lines 567 through 569 locate the table entry from the SliceIndex value. A range from Table [ index + 1 ] to Table [ index ] is determined for each color component – red, green, and blue.
Line 571 executes a priceless SSE instruction: it loads an integer DWORD value from the table, splitting it up into four bytes that are each placed into one “slot” of the XMM7 register. This separates the color components for us, from a single DWORD (the high 8 bits are the alpha channel; they’re along for the ride during calculations). XMM7 then converted to a float value. The process is repeated for the other table entry (the low value), moving it into XMM6 and converting it to a float value.
The range between start and end colors is used; the % of the way across the slice is multiplied by this range. The result must be added to the start (low) color for the final base color. For this reason, XMM3 gets a copy of the start color before it’s altered in XMM7.
Line 576 subtracts the start color in XMM7 from the end value in XMM6. This gives the range of red, green, and blue colors spanned by the target color slice. Red is in part 2 of XMM6, green is in part 1, and blue is in part 0.
Line 577: this is a little trick I picked up from somebody else who I can’t remember. It only works when the SHUFPS instruction is executed with the source and destination operands being the same because the register is self-modifying as the instruction executes. The net effect is that a scalar value in part 0 of an XMM register is copied to all four parts of the register. Think of it as a “fill” instruction. On line 577, the % of the way across the slice, initially present only in part 0 of XMM2, is copied to all four parts of that register. It’s needed to operate on the red, green, and blue color components simultaneously.
With that done, the slice % in XMM2 is multiplied on line 579 by the start-to-end range for each component in XMM7. The result is added to the start color, producing the final base values for red, green, and blue according to the distance across the slice.
Lines 587 through 594 calculate the distance from the current x, y to the 0, 0 center point.
With the base (at distance [ radius – 1 ] from the 0, 0 center point) color is known, lines 587 through 594 proceed to shift the color toward white. This is done by the % of the distance from the center point to ( radius – 1 ). This process follows the same method used in lines 567 through 579, except that the high color value is always 0xFF for all components and doesn’t need to be read from a table. Beyond that, the same process is followed. The distance from the 0, 0 center point to the x, y pixel is divided into ( radius – 1 ) to give a % of the distance along that line. ( 1 – this % ) is the amount each component moves from the base color to 0xFF (all components are at max value for pure white). The rounding implemented in this process occasionally produces a negative distance for ( 1 - % ); the compare/jump instruction pair adjusts for this – the app crashes if it’s not present because it ends up referencing a non-existent location in the output bitmap.
Lines 624 through 630 set the final color, post-movement toward white. This is the color that is stored in the bitmap. The color components still need to be gathered into a DWORD value; this is done after the write position is set.
Rather than using Windows’ SetPixel function, directly storing the pixel into the bitmap data at x, y is much faster. The location in the bitmap is ( ( y * bitmap_width * 4 ) + x * 4 ) bytes into the bitmap data. The final color is directly stored at this location.
Lines 634 through 643 calculate this location. However, because the 0, 0 center of the wheel is actually in the center of the bitmap, ½ of the bitmap height needs to be added to y, and ½ of the bitmap width needs to be added to x. These are fixed offset values that apply to all pixels.
Line 635 uses the MOVSXD instruction to move, while sign-extending, a 32 bit value for y from R9d to the 64-bit RAX register. The high 32 bits of R9 must be assumed to contain junk; the presumption can’t be made that they are clear. This is why the MOVSXD instruction is used instead of directly moving R9 into RAX.
The value for y is converted from the circle coordinate system to a bitmap-relative row index, then multiplied by <bitmap width> pixels times four bytes per pixel. This gives the distance into the bitmap data to the start of the bitmap row containing the target pixel. This value is added to RDI, adjusting it from pointing to pixel 0 in the bitmap to the start of the target row. Next, R8d is moved (again using MOVSXD) into RAX, shifted left two bits for the effect of multiplying by four bytes per pixel, and the write pointer is again adjusted by this amount. RDI now points to the actual write position.
Lines 647 through 657 build the final color value and store in EAX. The SHUFPS instructions in lines 648, 650, and 654 progressively rotate XMM3 so that each color component is moved into slot 0 of XMM3. This allows the MOVD instruction to used to move just one component value at a time into a general register. EBX is initially the accumulator that receives a component value, then shifts left by 8 bits to receive the next. Since EAX is used for the final STOSD instruction, the last color component performs a logical OR of EAX, where the component is loaded, with EBX which was used as the accumulator to that point.
At this point RDI is pointing at the write position, and EAX contains the final color value. The last step, in line 661, is to set the high 8 bits of EAX to ensure full alpha is present. Line 662 stores the actual pixel.
Line 666 increments the running x coordinate, and the LOOPN macro (covered earlier) executes to jump to the top of the loop until the RCX loop counter reaches zero.
Line 671 restores the entry RCX value, which was saved as the first order of business in the callout, then returns to the caller. Remember that LocalRet is simply an alias for <byte 0C3h> which is a RET statement.
Conclusion
As is probably apparent by now, a lot more thinking and responsibility fall into the developer’s lap when using assembly than is present for other languages, but it pays off in spades in execution speed and small executable size. This is particularly true in game programming. How deep you want to go into this is your choice. If your color wheel is only ever built once during the execution of your app, you would probably not see any noticeable difference in performance if you used your language’s built-in math handling for the entire process. However in cases where heavy math is used often, extra time and effort get extra performance results. The option is always there for the times you may decide it’s warranted.