
Multi Threaded WebScraping in C#
4.92/5 (110 votes)
Beginner to Advance - Multithreaded Web Scraping with Examples of WebBrowser, WebClient, HttpWebRequest/HttpWebResponse, Regex, BackgroundWorker.
Suggestions have been incorporated. Kindly Suggest, Vote, Comment to improve it

Introduction
*All the code examples are for learning purpose. Any misuse is not encouraged.
* Project with Source Code of most of the Examples has been added.
Web Scraping involves obtaining information of interest from the webpages. I tried to make a step by step guide starting from basic of webscraping using WebBrowser
to a little bit advance topics like performing login and maintaining sessions via HTTPWebRequest. This is the first release of the article and there may be errors/mistakes. I welcome all the suggestions and would try to include them ASAP.
I have used the tutorial based Step by Step approach and web scrapping work starts from the first line of the tutorial. I have taken Example/Task Oriented method to keep it interested, 2-3 examples are followed by 2-3 Tasks to keep the learner motivated. I am assuming the users have basic knowledge of C# and Visual Studio Programming Environment.
Contents
The Contents I have covered are:
- WebBrowser
- WebBrowser Download Event
- Navigating To Olx's first Page
- Accessing All Adds Shown at ...
- Yahoo Signin Form Filling & Submission
- Modifying WebBrowser Headers
- Saving All Images of a WebPage
- Solving Captcha Using API ...
- Setting Proxy For WebBrowser
- Regular Expressions
- Finding a Number in Text
- Regex Operators
- Finding Words in a Sentence
- Numbers of Format ddd-ddddd
- Finding Email Addresses in Text
- Finding IP Addresses in Text
- A Regex Utility
- WebClient
- Downloading HTML as String
- Downloading & Saving an Image
- Blocking Mode of WebClient
- Non - Blocking Mode of WebClient
- Read / Write Streams
- Query String for WebClient
- Uploading File to URL
- Little more about WebClient ...
- BackGroundWorker
- Running Time Consuming Function
- Work Completion Report
- Updating the Progress
- Stopping the Worker
- Multi Threaded App to Download Images ...
- HttpWebRequest/HttpWebResponse
- HTTP Request Headers
- How the Sessions Work
- HTTP Response Headers
- Mozilla Live HTTP Headers
- User Agent Strings
- Getting Facebook Login Page HTML ...
- Performing Login by HTTP requests
- Custom HTTPWebRequest for Login...
- Understanding HTML Form Get/POST
- Getting Form Hidden Fields
- Preparing HTTP POST Data
- Picture Upload by HTTP to Facebook ...
And a lot of relevant Tasks to keep the learner motivated to explore his innovation.
WebBrowser Control
Top This control provides a built in full browser as a control. It enables the user to navigate Web pages inside your form.
Example: WebBrowser Download Event
Add WebBrowser Control to the Form. Make it Dock in Parent Container
Double click the WebBowser Control to Add WebDocumentCompleted Event
Navigate Function is used to navigate to the given address
Document completed event is fired once the document is completed loaded
Now Run the program
There are many solutions available to solve the above problem, like counting i-frames and then counting number of times the Document Completed Event Fire. This is pretty much complex and the easiest one is to Maintain History.
-
Add a
List<string>hist to the program, and modify the Document Competed Event as below:



Example: Navigate to OLX’s 1st Add’s Page
Before making any web scrapper, click bot etc, understanding of that website’s layout is necessary. After that following is important
Finding Fields of Interest
-
Narrowing Down the Text of Interest
Finding tags with ids near the interested tags
First Install Mozilla Firefox 15. Navigate to http://www.olx.com/cars-cat-378
Write click on the First Add Link and click on the Inspect Element.
You will see something like the image below
To Visit the 1st Add, we needs its link address.
The anchor tag highlighted in above picture has no id, so if we use
GetElementByTag(“a”)function, we will get a list of all the anchor tags, which will include links of other pages of olx, help, contact us etc.(so its not good option)So, try to Find the nearest Tag which has ID.
On the Tags Bar, Keep Selecting Tags toward the Left until you find some tag with ID
Once you reach the div tag with id the-list, you will see it is the container for all the Adds Links
So all the anchor tags in div#the-list, are links to the individual add pages
Following is the code to get it programmatically.
We want to navigate to 1st adds page



//Getting AddsBlock HtmlElement
HtmlElement he = webBrowser1.Document.GetElementById("the-list");
//Getting Collection of all the Anchor Tags in AddsBlock
HtmlElementCollection hec = he.GetElementsByTagName("a");
//Naviagting to 1st Add Page
//obtainign href value to get the page address
webBrowser1.Navigate(hec[0].GetAttribute("href"));
Example: Navigate to All the Adds shown on
http://www.olx.com/cars-cat-378
You have seen how to Navigate to the 1st Add.
To navigate to all the Pages, We need to store all the Adds Links in a List, so that later on we can visit those Adds
To Do This Make A List That Stores href values of all the Add’s Links
Modify the Document Completed Event to add all the links to the URLs
Why we are checking href != "http://www.olx.com/cars-cat-378" ? Because each individual Add Block contains a Link to the page on which it is being shown (that means to make accurate scrapper, you need to understand well what all is there and where is it).
All the links are stored in urls list, now we need to make the browser automatically navigate to all of these
List<string>
urls = new List<string>();
HtmlElement he = webBrowser1.Document.GetElementById("the-list");
HtmlElementCollection hec = he.GetElementsByTagName("a");
foreach(HtmlElement a in hec)
{
string href = a.GetAttribute("href");
if(href != "http://www.olx.com/cars-cat-378")
{
if(!urls.Contains(href))
urls.Add(href);
}
}
if(urls.Count > 0)
{
string u = urls[0];
urls.RemoveAt(0);
webBrowser1.Navigate(u);
this.Text = "Links Remaining" + urls.Count.ToString();
}
else
{ MessageBox.Show("Complete"); }
Task 1: Modify The Above Code, make it browse next pages
Like: http://www.olx.com/cars-cat-378-p-2
http://www.olx.com/cars-cat-378-p-3
http://www.olx.com/cars-cat-378-p-4 and so on
Task 2: On Each Add Page, scrape owner name and Number(if given)
Task 3: Make The App, which scrapes specified number of individual adds from the given url of olx categorey.
Example: Yahoo Signin Form Filling and Submission
Navigate to http://mail.yahoo.com/
Check the ID of the username and password textboxes (Use Inspect Element)
Make a Button Click Event in the app
For Sign in Button Click (actually we need to submit the form, so find Signin Form ID. Get its Element, and invoke submit function on it
htmlElement hu = webBrowser1.Document.GetElementById("username");
hu.Focus();
hu.SetAttribute("Value","userName");
HtmlElement hp = webBrowser1.Document.GetElementById("passwd");
hp.Focus();
hp.SetAttribute("Value", "password");
HtmlElement hf = webBrowser1.Document.GetElementById("login_form");
hf.InvokeMember("submit");
Task 1: Findout how to Select Value of Dropdown List, CheckBox, Radio Button. You can try Filling Yahoo Signup Page
Task 2: Perform Click on the Hyperlink
Example: In WebBrowser Control We can Add/Change the Headers. The Most important Header’s are Referrer and User-Agent.
User Agent header tells the Web Server about the Browser From which the Request was sent
Referrer Tells the Web Server, that From which web page the user was sent to the current web page
To Change User-Agent Header
webBrowser1.Navigate("url", "_blank", null, "Referrer: sample user agent");
Task1: Browse to webBrowser1.Navigate("logme.mobi");
To see HTTPHeaders, then try modifying your User-Agent and Referrer
You can get a Complete List of User Agent Strings at http://www.useragentstring.com/pages/useragentstring.phpTask2: Vist www.google.com in C# app, with some Apple, Linux browser User Agent. Get Google Search Results non-javscript page.
Example: Saving All the Images of the Web Page
Add Reference to using mshtml;
You can use Yahoo Sign up Page for Practice
IHTMLDocument2 doc = (IHTMLDocument2)webBrowser1.Document.DomDocument;
IHTMLControlRange imgRange = (IHTMLControlRange)((HTMLBody)doc.body).createControlRange();
foreach (IHTMLImgElement img in doc.images) {
imgRange.add((IHTMLControlElement)img);
imgRange.execCommand("Copy", false, null);
try{
using(Bitmap bmp = (Bitmap)Clipboard.GetDataObject().GetData(DataFormats.Bitmap))
bmp.Save(img.nameProp + ".jpg");
}
catch (System.Exception ex)
{
MessageBox.Show(ex.Message);
}
}
The Above code will save all the images of the Webpage in current directory
Task: Find Pattern in the captcha name, modify the code to only save captcha
Example: Solving Captcha using DeathByCaptcha Api
Add Reference to using DeathByCaptcha;
Following code solves the captcha.
Study How to Report that Captcha.Text was wrong
Client client = (Client)new SocketClient(capUser, capPwd);
try
{
Captcha captcha = client.Decode(path + capName, 50);
if (null != captcha)
{
//Captcha Solved
MessageBox.Show(captcha.Text);
}
else
{
//Captcha Not Solved Show Error Message
}
}
catch(DeathByCaptcha.Exception ex) {
MessageBox.Show(ex.Message);
}
Example: Setting Prxoy For WebBrowser
using Microsoft.Win32;
RegistryKey reg = Registry.CurrentUser.OpenSubKey(
"Software\\Microsoft\\Windows\\CurrentVersion\\InternetSettings", true);
registry.SetValue("ProxyEnable", 1);
registry.SetValue("ProxyServer", "192.168.1.1:9876");
Regex
Top A concise and flexible means of matching strings in the text
In C#, Regex, Match, MatchCollection classes are used for finding string patterns. These Clasess are in following Namespace.
using System.Text.RegularExpressions;
Example 1: Finding a Number in a text

Following are the Regex Operators:
|
[xyz] |
A character set. Matches any one of the enclosed characters. For example, "[abc]" matches the "a" in "plain". |
|
[^xyz] |
A negative character set. Matches any character not enclosed. For example, "[^abc]" matches the "p" in "plain". |
|
[a-z] |
A range of characters. Matches any character in the specified range. For |
|
[^m-z] |
A negative range characters. Matches any character not in the specified |
|
* |
Matches the preceding character zero or more times. For example, "zo*" matches either "z" or "zoo". |
|
+ |
Matches the preceding character one or more times. For example, "zo+" matches "zoo" but not "z". |
|
? |
Matches the preceding character zero or one time. For example, "a?ve?" matches the "ve" in "never". |
|
. |
Matches any single character except a newline character. |
Example 2: Finding Words in a sentence

The last word sentence is not in the match list, as it didnt have space after it.
|
{n} |
n is a non-negative integer. Matches exactly n times. For example, "o{2}" does not match the "o" in "Bob," but matches the first two o's in "foooood". |
|
{n,} |
n is a non-negative integer. Matches at least n times. For example, "o{2,}" does not match the "o" in "Bob" and matches all the o's in "foooood." "o{1,}" is equivalent to "o+". "o{0,}" is equivalent to "o*". |
|
{n,m} |
m and n are non-negative integers. Matches at least n and at most m times. For example, "o{1,3}" matches the first three o's in "fooooood." "o{0,1}" is equivalent to "o?". |
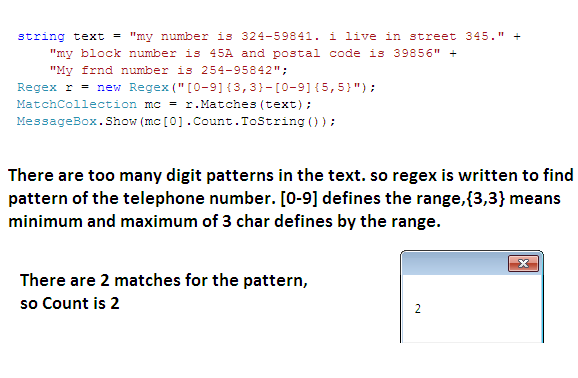
Example: Matching Telephone Number of the format ddd-ddddd. Where d means digit
Example: Finding email in the text
TheRegex of a normal email can be
"\b[A-Za-z0-9_]+@[A-Za-z0-9_]+\.[A-Za-z0-9]{2,4}\b"
Where \b defines a blank space [A-Za-z0-9_]+ defines username which may include repitition of anything from A-Z, 0-9, a-z and _(uderscore) @[A-Za-z0-9_]+ defines hosting company name, for example yahoo \. Defines dot(.) [A-Za-z0-9]{2,4} Matches Top Level doamin, like com, net, edu etc
Example: Regex to find IP address in the text
A basic regex to find ip address can be "\b[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+\b" But this wil match something of this type also 1925.68541.268.1 (that mean any number of deigits with 3 dots – and its not valid ip address)
An Other can be
"\b[0-9]{1-3}\.[0-9]{1-3}\.[0-9]{1-3}\.[0-9]{1-3}\b"
Now this wil not match a string whihc has more that 3 digits with dots. But it may matches 999.999.999.999 which is again invalid address
So a regex can be as complex as following
"b(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\."+ "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\."+"(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\."+"(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b"
There is always a trade of between complexity and accuracy. So depending upon you input text you may give one dimension more important over other.
Task 1: Anchor Tags of HTML are of vital importance in scrapping. The value of the link is placed in the href attribute as shown below. Write regex to Find href value

Answer 1: The Regex to this can be as simple as
Regex r = new Regex("href=\"[^\"]+\"");
\” is used to define double quote(“) as double quote is a special character so it needs to be written with slash(\). Later on u can remove href=” and “ from the value of the match.
Task 2: Pins at Pinterest.com has following format of web addresses.
"/pin/125678645821924781/" "/pin/63894888434527857/"
"/pin/25825397833321410/"Write Regex to find pins addresses from the html of the www.pinterest.com
Task 3: Thumbnail images of the Ads are shown at http://www.olx.com/cars-cat-378

Write a Regex to Match Images Links
Task 4: Make Following Utility.

Load Input Text File
Press Load Button
Write Regex
Press Execute
All The Matches are show in Multiple Line Text Box with One Match Value Per Line
WebClient
Top This class is found under using System.Net;. It provides various funtions to download files from the internet. It can be used to download HTML source of the webpages as string, as file. It supports downloading files as data bytes.
This class is very helpful in scrapping, as it lets the coder download only the html file where as using webbrowser for scrapping is simple, but not an efficient/speedy way.
Example: Dowloading Yahoo.com html source as string
Create a Button and TextBox on the form
In Button Click Event add the following code, and press the Button at run
Here we are making Webclient Variable and then using its DownloadString method to download the html of the given url.
The downloaded html is shown in the textbox1
WebClient wc = new WebClient();
textBox1.Text = wc.DownloadString("http://www.yahoo.com");

Benefits of using Webclient
Its easy to use
Supports Various Methods for file and string downloading
Efficient, uses much less bandwidth as compared WebBrowser
Once HTML source is downloaded, u can use Regex or 3rd party HTML Parsers to get required info from the HTML source.
Example 2: Downloading and Saving an Image
Add the Following Code to Button Click Event, and press the Button at run
WebClient wc = new WebClient();
wc.DownloadFile("http://www.dotnetperls.com/one.png", "one.png");
The image one.png will be downloaded and stored in the current directory

The 1st argument is the url of the image and 2nd is the name of the image
The same way, WebClient class provides methods for string and file uploading, but we wil use HTTPWebRequest class for that
wc.DownloadData()Method provides downloading the data as bytes. This is useful where differnent encoding is used like UTF8 etc
Example: Blocking Mode of Webclient
Adds Following code to the Button Click and press button at run
WebClient wc = new WebClient();
wc.DownloadData("http://www.olx.com");
Just after pressing buttion, try to move the Form, and Form will go to Not responding

Why is it so? The downloading string, file or data from internet is time consuming and webclient class is performaing download operation on the same Thread as the UI is. This causes UI to go Unresponsive
This mean, no other task can be performed by the App, once WebClient is downloading. This is blocking Mode. Solution to this problem is using WebClient in Non – Blocking Mode
Example: Non– blocking Mode of webclient
wc.DownloadStringAsync()isused to perform the download operation on a separate thread. This causes the UI to remain responsive and can App can do other task meanwhile the downloading is performed
wc.DownloadStringAsync(new Uri("http://www.yahoo.com"));
This Downloads a String from resource, without blocking the calling thread.
To Perform Asynchronous Download operation, user needs to define Download Completed Event, so that calling thread can be informed once Downloading is Complete
In above case, we need to add DownloadStringCompleted Event.
Following Piece of code will cause the Webclient to Asynchronous Dwonload string and will fire Download Completed event on completion
WebClient wc = new WebClient();
wc.DownloadStringCompleted+=new DownloadStringCompletedEventHandler(wc_DownloadStringCompleted);
wc.DownloadStringAsync(new Uri("http://www.yahoo.com"));
-
The Downloaded string is passed as argument to the Download Complete Event and can be accessed by following way
void wc_DownloadStringCompleted(object sender, DownloadStringCompletedEventArgs e)
{
//Accessing the Downloaded String
string html = e.Result;
//Code to Use Downloaded String
textBox1.Text = html;
}
The Download Completed Event is Fired at Calling Thread, so u can easily Access UI elements
Example: Read / Write Streams
Webclient class provides various Blocing and Non Blocking Methods to Access the Stream for direct Read and Write Operations
Following Piece of code obtains read Stream in blocking mode
WebClient wc = new WebClient();
StreamReader sr = new StreamReader(wc.OpenRead("http://www.yahoo.com"));
//Here You Can Perform IO
//Operations like, Read, ReadLine
//ReadBlock, ReadToEnd etc
//Supported by StreamReader Class
The Same Way Write stream can be obtained for Write Related IO operations
Example: QueryString for Webclinet
Gets or sets a collection of query name/value pairs associated with the request.
Query String is helpful in sending the parametres to the url by url posting mothed
Search Result Page of Google has following format of Address
https://www.google.com.pk/search?q=search+phrase
In above url, 1 is a parameter and search+phras is its value
Following Example Shows how to use Query String for sending parameters and their values to a URL
string uriString = "http://www.google.com/search";
//Create a new WebClient instance.
WebClient wc = new WebClient();
//Create a new NameValueCollection instance to hold the QueryString parameters and values.
NameValueCollection myQSC = new NameValueCollection();
//Add Parameters to the Collection
myQSC.Add("q", "Search Phrase");
// Attach QueryString to the WebClient.
wc.QueryString = myQSC;
//Download the search results Web page into 'searchresult.htm'
wc.DownloadFile(uriString, "searchresult.htm");
NameValueCollection class is under System.Collections.Specialized
Example: Uplading File To the URL
String uriString = "FileUploadPagePath";
// Create a new WebClient instance.
WebClient myWebClient = new WebClient();
//Path to The File to Upload
string fileName = "File Path";
// Upload the file to the URI.
//The 'UploadFile(uriString,fileName)' method
//implicitly uses HTTP POST method.
byte[] responseArray = myWebClient.UploadFile(uriString, fileName);
// Decode and display the response.
textBox1.Text = "Response Received. " + System.Text.Encoding.ASCII.GetString(responseArray);
Example: Additional Info for WebClient
Setting Proxy
wc.Proxy = new WebProxy("ip:port");
Adding Custom Headers
wc.Headers.Add(HttpRequestHeader.UserAgent, "user-agent");
Obtaining Respose Headers
WebHeaderCollection whc = wc.ResponseHeaders;
Task 1: Add Refrrer Header.
Task 2: Read Response Code and Status from Response Header
Task 3: What is BaseAddress of the WebClient
Task 4: Use WebClient.QueryString to Do Search on Google
Task 5: Use WebClient.Upload to upload some File
BackGroundWorker
Top This class provides an easy way to run time-consuming operations on a background thread. The BackgroundWorker class enables you to check the state of the operation and it lets you cancel the operation.
Example: Running Time Consuming Function on BackGroundWorker
For This Example We Are assuming Following Function a time consuming, and user need to run this function for various times which causes the UI to go unresponsive
private void HeavyFunction()
{
System.Threading.Thread.Sleep(1000);
}
Make a Form a shown Below with Start, Stop Button and Status Text. Add a BackGroundWorker from the Componnets to the Form

Create an event handler for the background worker's DoWork event. The DoWork event handler is where you run the time-consuming operation on the background thread. You can make this Event By Double Clicking in the Event Pane for BackGroundWorker

Any values that are passed to the background operation are passed in the Argument property of the DoWorkEventArgs object that is passed to the event handler.

Let's Call the HeavyFunction 5 times in the backgroundWorker1_DoWork Event
private void backgroundWorker1_DoWork(object sender, DoWorkEventArgs e)
{
for(int i = 0; i < 5; i++)
HeavyFunction();
}To Start the BackGroundWorker Work, we need to call RunWorkerAsync() Function of the backgroundWorker1. Call it in the Start Button Click Event
private void Start_Click(object sender, EventArgs e)
{
backgroundWorker1.RunWorkerAsync();
}
Once, the Start Button will be Clicked, the BackgroundWorker will start working, But UI will remain responsive.
You have sucessfully learnt how to put Time Consuming Functions on Easily Maneged Separate Thread
RunWorkerCompleted Event is Fired Once The Work is Complete
The Event is Called on the Calle Thread(Thread From which the BackGroundWorker.RunWorkerAsync() was called). In our case, its UI thread
To be notified, About BackGroundWorker Completion, add the Event RunWorkerCompleted

RunWorkerCompleted Event Will be Fired on UI Thread, so we can easily Access All the UI Elements
private void backgroundWorker1_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e)
{
Status.Text = "Work Complete";
}
Now After 5 seconds of Pressing Start Button, the Status Label Text Will be set to Work Complete

While Performing some Time Consuming Function on the BackGroundWorker, we may want to update the progress to the user. For example in a scenario of downloading several files, we may want to update UI to show how many files have been completed
To perform such update, ReportProgress Function is called which raises the PogressChanged Event on the calle Thread.
-
To Call Report Progrees, First you need to Add Progress Changed Event and set the WorkReportProgress Property to True


In Report Progress Method 2 arguments can be passed, int ProgresssPercentage and object UserState. These Both arguments are available in ProgressChangedEventArgs ProgressPercentage and UserState Properties

To Report Progress, Change the BackGroundWorker DoWork Event as Following
private void backgroundWorker1_DoWork(object sender, DoWorkEventArgs e)
{
for (int i = 0; i < 100; i++)
{
HeavyFunction();
backgroundWorker1.ReportProgress(i, " Heavy Function Done");
}
}
To update UI in ProgressChanged Event, modify it as following
private void backgroundWorker1_ProgressChanged(object sender, ProgressChangedEventArgs e)
{
Status.Text = e.ProgressPercentage.ToString() + (string)e.UserState;
}
Now Once you press the Start Button, the status will be updated with arguments passed in ReportProgress Method

When the BackGroundWorker will finish working, the RunWorkerCompleted Event will be fired, so the status will be updated to Work Complete.

To Stop the BackGroundWorker During the Work, We need to Set the Property WorkerSupportsCancellation to True

At any time during the Work, we can Stop the BackgroundWorker by calling CancelAsync() Function. Modify the Stop button Click Event as Following
private void Stop_Click(object sender, EventArgs e)
{
backgroundWorker1.CancelAsync();
}
Modfiy the DoWork Event as Following to Stop if Cancelling is Pending
private void backgroundWorker1_DoWork(object sender, DoWorkEventArgs e)
{
for (int i = 0; i < 1; i++)
{
if (backgroundWorker1.CancellationPending)
{
e.Cancel = true;
break;
}
HeavyFunction();
backgroundWorker1.ReportProgress(i, "Heavy Function Done");
}
}
To Update the UI with accurate info, u can modfiy BackGroundWorkerCompleted Event as following to show that either BackGroundWorker was stopped or it completed the Work
private void backgroundWorker1_RunWorkerCompleted(object sender, RunWorkerCompletedEventArgs e)
{
if(e.Cancelled)
Status.Text = "Work Stooped";
else
Status.Text = "Work Complete";
}
If BackGroundWorker is Busy in some Task and user again press the Start Button, this is going to cause an error and throw and Exception. The IsBusy Propert tells either worker is busy or not, So Before Calling RunWorkerAsync() function, one must check that either BackGroundWorker is Busy in Work or Not. Following Code Does so
private void Start_Click(object sender, EventArgs e)
{
if (!backgroundWorker1.IsBusy)
backgroundWorker1.RunWorkerAsync();
else
MessageBox.Show("Busy in Work - Press Stop");
}
You can send Non UI objects as argument to the RunWorkerAsync function and then access it in the DoWork Event
Example: Make Multi Threaded App to download images from pinterest.com
Design the UI as shown Blow

Add a one BackGroundWorker, name it backGroundWorker1, add DoWork, ProgressChange and RunWorkCompleted Events. Set WorkerReportsProgress and WorkerSupportsCancellation Properties to True
Program Logic: We are going to use backGroundWorker1 to download html source of the http://www.pinterest.com using WebClient, then we will use regex to find urls of all the images and add it to a List<string> urls. The BackGroundWorkers equal to the number of threads set by the user will be created at run time, each of these backgroundworkers will take one url from List<string> urls, and download that image using WebClient.
Add Following Code for the backgroundworker1 Events
private void backgroundWorker1_DoWork(object sender, DoWorkEventArgs e)
{
WebClient wc = new WebClient();
string html = wc.DownloadString("http://www.pinterest.com");
Regex reg = new Regex("src=\"http://[^/]+/upload/[^\"]+");
MatchCollection mc = reg.Matches(html);
backgroundWorker1.ReportProgress(0, mc.Count.ToString() + "Images Found");
System.Threading.Thread.Sleep(2000);
lock(urls)
{
foreach (Match m in mc)
{
urls.Add(m.Value.Replace("src=\"",""));
}
}
}
private void backgroundWorker1_ProgressChanged(object sender, ProgressChangedEventArgs e)
{
Status.Text = (string)e.UserState;
}
In DoWork, we have just downloaded the html, used regex to get images links, and added it in the List<string> urls
Now we need to make workers for downloading images. We will do this once user press that Start Button, Add Following Code to Start Button Click Event
private void Start_Click(object sender, EventArgs e)
{
int maxThrds;
if(!int.TryParse(NoOfThreads.Text, out maxThrds))
{
MessageBox.Show("Enter Correct Number of Threads");
return;
}
if(maxThrds <= 0)
{
MessageBox.Show("Enter 1 or more Threads");
return;
}
if (!backgroundWorker1.IsBusy)
{
for(int i = 0; i < maxThrds; i++)
{
BackgroundWorker bgw = new BackgroundWorker();
bgw.WorkerReportsProgress = true;
bgw.WorkerSupportsCancellation = true;
bgw.DoWork += new DoWorkEventHandler(bgw_DoWork);
bgw.ProgressChanged += new ProgressChangedEventHandler(bgw_ProgressChanged);
bgw.RunWorkerCompleted += new RunWorkerCompletedEventHandler(bgw_RunWorkerCompleted);
//Start The Worker
bgw.RunWorkerAsync();
}
backgroundWorker1.RunWorkerAsync();
}
else
{
MessageBox.Show("Busy in Work");
}
}
First we are checking for correct input, then we are making backgroundworkers at the run time.
Once all properties of the run time threads are set, we are calling bgw.RunWorkerAsync for each worker.
- Following is the Code for DoWork Event of the RunTime made Workers
private void bgw_DoWork(object sender, DoWorkEventArgs e)
{
BackgroundWorker bgw = (BackgroundWorker)sender;
while(true)
{
string imgLink = "";
lock(urls)
{
if(urls.Count > 0)
{
imgLink = urls[0];
urls.RemoveAt(0);
count++;
}
else
{
System.Threading.Thread.Sleep(500);
}
}
if (imgLink != "")
{
string filename = imgLink.Substring(imgLink.LastIndexOf("/") + 1);
WebClient wc = new WebClient();
wc.Headers.Add(HttpRequestHeader.Referer, "Mozilla/5.0 (Windows NT 6.1; rv:15.0) Gecko/20100101 firefox/15.0.1");
wc.DownloadFile(imgLink, filename);
bgw.ReportProgress(0, count.ToString() + "Images Downloaded");
}
}
}
In 1st line, we are casting sender to the BackGroundWorker object, so that we can ReportProgress for it. Then we have put all the code in a loop, in each iteration we are removing one url from List and then putting it on Download
If there is no link in List<string> urls, we have put the thread to sleep for 500ms
-
Since many threads will be accessing List<string> urls, so have put it in lock.
Task 1: How to Stop Run Time Created Workers
Task 2: Modify backgroundworker1 to collect user defined number of images. For example 30, 100, 220(for more than 50, u have to scrape page 2,3,4 ....
Hint for Task 1: Following Options can be used
Option 1: You can maintain a List of Run Tim Created Workers and then call
CancelAsync()for each worker in the List. Then modify the code of each run time Worker to break The Loop if CancellationPending
Option 2: Declare a Global Variable int rnd, assign it some random value in the start Button Click Event and pass it to BackGroundWorker DoWork Event as Argumet.
//Start Button Click Event
if(!backgroundWorker1.IsBusy)
{
rnd = new Random().Next(0, 99999);
for (int i = 0; i < maxThrds; i++)
{
BackgroundWorker bgw = new BackgroundWorker();
bgw.WorkerReportsProgress = true;
bgw.WorkerSupportsCancellation = true;
bgw.DoWork += new DoWorkEventHandler(bgw_DoWork);
bgw.ProgressChanged += new ProgressChangedEventHandler(bgw_ProgressChanged);
bgw.RunWorkerCompleted += new RunWorkerCompletedEventHandler(bgw_RunWorkerCompleted);
//Start The Worker, Pass rnd as Argument
bgw.RunWorkerAsync(rnd);
}
backgroundWorker1.RunWorkerAsync();
}
Cast the rnd value to a local int variable, Modify the DoWork Event to work until rnd is not changed
void bgw_DoWork(object sender, DoWorkEventArgs e)
{
int chk = (int)e.Argument;
while (chk == rnd)
{
//Do the Task
}
}In Stop Button Click Event, Assign some new value to rnd, which will cause all the runtime created workers to break from loop
private void Stop_Click(object sender, EventArgs e)
{
rnd = new Random().Next(0, 9999);
}
Task 3: Think of some more options
HTTPWebRequest / HTTPWebResponse
Before Starting this, we need to understand a bit about main HTTP Headers and install few ADD On’s which help us in determining Layout, Packets and Altering the Packets for a Website.
In an any of your Browser, Go to http://logme.mobi . You will get something like following

This is the Data of your HTTP Headers, which your browser sent to the web server of the http://logme.mobi In this, the User – Agent (it defines which browser is used for browsing) and Connection Headers are important.
Now Just Referesh the Page, and u will get something like following
![]()
This Header defines the Cookie, what is Cookie? A Cookie is a small piece of information stored as a text file on your computer that a web server uses when you browse certain web sites.
To maintain sessions, the cookie header is very important.
How the Sessions Work? Once user request login page, few cookies are issued by the server, then user submits login info along with the cookies, in case of successful login, server issues a new set of cookies, which identifies the user as authentiated user to the server. Then for further requests to the server, these newly issued set of cookies is used. This way a session is maintained. At any time, if u clean the Cookies Header, u will be redirected to the Login Page.

Install Mozilla Firefox 15.0 and then install the Live HTTP Headers add on for it. You can get it from here. Run the LiveHTTPHeader, and Referesh the Page http://logme.mobi. You will see something like following
The LiveHTTPHeader Add on shows the HTTPHeaders of all the Requests and Responses once you dosome browsing using Mozilla Firefox. This Tool is Helpful in determining the website’s HTTP Packet formats, specially it helps in knowing what all data is being posted once some POST Action is performed
Now install the Add on Tamper Data from here. This Tool is helpful in modifying the content of HTTP Headers while browsing the web, this tool is of great use in determining that what fields and headers are compulsory for performing some HTTP POST Request and what all stuff we can skip out from a perticular post request. Once u run it, it will look like following

Click on the Start Tamper Button. In address bar type useragentstring.com/ press Enter, As soon u press Enter Following Window Will open, asking for u to Tamper Data, Submit Request or Abort Request

Click on Tamper Data, Then Following Window will open up
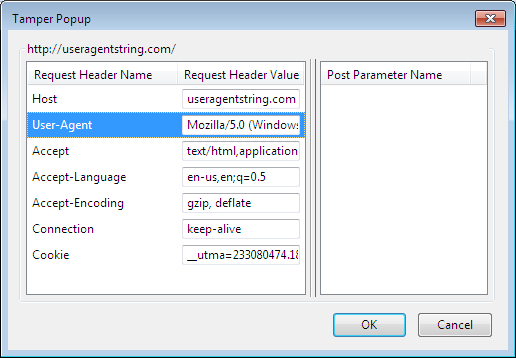
In the User Agent Field, Enter Following and Press OK
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1
Now submit all the subsequent requests and once the page will be loaded u will see website showing ur browser as Chrome where as you are using FireFox

The same way, you can alter the POST method parameters.
HTTPWebRequest Class in .Net: This class is under System.Net namespace and it provides methods and
properties to make HTTP Request to a web server.
Example 1: Downloading HTML of the Facebook login page
To make an object of this class, WebRequest.Create function is used HttpWebRequest myReq = (HttpWebRequest)WebRequest.Create(url);
Open LiveHTTPHeaders, in browser, and browse to http://www.facebook.com

The picture above, shows the HTTP Request Headers, lets make this in C#
HttpWebRequest request = (HttpWebRequest)WebRequest.Create("https://www.facebook.com/");
request.UserAgent = "Mozilla/5.0 (Windows NT 6.1; rv:11.0) Gecko/20100101 Firefox/15.0";
request.Accept = "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8";
request.Headers.Add("Accept-Language: en-us,en;q=0.5");
request.Headers.Add("Accept-Encoding: gzip, deflate");
request.KeepAlive = true;
First line, creates an HTTPWebRequest Object to the given url, then we are adding the User-Agent and Accept Header to the HTTP packet by using properties. Not all of the Herders are Accessible via properties so user may need to Add Headers by Adding it to Headers Collection. Then we are adding Accept-Language and Accept-Encoding Headers by Adding it to Headers Collection.
Next important Stuff is Adding the Cookie Container to the HTTPWebRequest Object, as we want to keep record of the Cookies sent by the server in response to the request. If no Cookie container is Added then we can not Access the Cookies in the Response Header.
request.CookieContainer = new CookieContainer();
Declare a CookieCollection variable Globally, all the received Cookies will be added in this Collection so that we can use received cookies for subsequent requests. If each time you use new Cookie Container, then its not possible to maintain session.
Now we are done with making required HTTPWebRequest Object. Before making HTTPWebResponse object, lets see what response we got in LiveHTTPHeader for the request which we sent by browser
The 1st line shows the Code and Status. Then we are interested in Cookies Only. We a got 4-5 Cookies, which wil stored in browser Cookies foleder and will be sent with the next request. In case we perform login, then these Cookies wil be sent with the HTTP Request which will be generated for login, and then for successful login, server will issue some additional Cookies(those Cookies wil contain info which wil make us authenticated users for subsequent Requests)
Now lets make the HTTPWebResponse Object, its very simple
Once Response is Received, next thing is adding the Received Cookies to the globally defined CookieCollection. But Before that Lets see what all Cookies we received. Add the following Code after above line to see recevied Cookies
This will show your cookies in a MessageBox
CookieCollectioncookies = new CookieCollection();

HttpWebResponse response = (HttpWebResponse)request.GetResponse();
string txt = "Cookies Count=" + response.Cookies.Count.ToString() + "\n";
foreach (Cookie c in response.Cookies)
{
txt += c.ToString() + "\n";
}
MessageBox.Show(txt);
//Adding Recevied Cookies To Collection
cookies.Add(response.Cookies);

Now the Response is recieved, Next Step can be downloding the Data from Stream, it can be HTML source code, some other file or may be nothing at all depending upon the url to which u made the request. In our case it is HTML source of the Facebook Login page.
StreamReader loginPage = new StreamReader(response.GetResponseStream()); string html = loginPage.ReadToEnd();
This html source can be used to get some info by Regex or using some 3rd party HTML Parsing Library or stored in an html file as offline page.
Example 2: Performing Login to FaceBook
Before diong login by C#, lets perform login in mozilla and analyze the HTTP Header by LiveHTTPHeaders. Start LiveHTTPHeader, Browse to http://www.facebook.com , enter username and password, click Login button. The HTTP Web Request sent by the Browser will look somthing like this

The First Line is the URL to which your username and password being sent(later in Example 3, we will see how to find this url). Second line tells the HTTP method and version used, which is POST and 1.1 respectively.
Then all the fields are just like normall HTTP Header as we saw in Example 1. The important stuff starts from Cookie Header, in Example 1, once we browse to http://www.facebook.com, there was no Cookie Header where as we received some Cookies in the Response Header, now when we click on the Login Button, the previously received set of Cookies is being sent in this Cookie Header.
Next Header shows Content Type, there are two major content types used to POST data, application/x-www-form-urlencoded and multipart/form-data. You can find more info about these here
Next Header shows Content Length and in last line Content is being shown. You will see your email address and password in this line. Actually last Line shows the data which is being sent to the server by HTTP Post method.
There are several other values also, later in Example, we will see what are these values and from where to obtain these Values ! ! !
Lets examine the Response Header for the above Request.

The Response Header shows a lot of Cookies, these are the Cookies which are issued by the server on successful login, now for any subsequect request, the browser will send these Cookies to the server and in this way session wil be maintained
Got to Tools->Clear Recent History and delete the Cookies, then try to browse to your facebook profile page, and u will see that u will be redirected to facebook login page.
-
Now lets create the same login Request header as we saw in above screen shot and test that either we are able to successfully log in or not
string getUrl = "https://www.facebook.com/login.php?login_attempt=1"; string postData = "lsd=AVo_jqIy&email=YourEmailAddress&pass=YourPassword&default_persistent=0& charset_test=%E2%82%AC%2C%C2%B4%2C%E2%82%AC%2C%C2%B4%2C%E6%B0%B4%2C%D0%94%2C%D0%84&timezone=-300&lgnrnd=072342_0iYK&lgnjs=1348842228&locale=en_US"; HttpWebRequest getRequest = (HttpWebRequest)WebRequest.Create(getUrl); getRequest.UserAgent = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/535.2 (KHTML, like Gecko) Firefox 15.0.0.1"; getRequest.CookieContainer = new CookieContainer(); //Adding Previously Received Cookies getRequest.CookieContainer.Add(cookies); getRequest.Method = WebRequestMethods.Http.Post; getRequest.ProtocolVersion = HttpVersion.Version11; getRequest.AllowAutoRedirect = false; getRequest.ContentType = "application/x-www-form-urlencoded"; getRequest.Referer = "https://www.facebook.com"; getRequest.KeepAlive = true;
The getUrl is assigned to the address to which data will be posted, postData variable is copy of the Content from above HTTP Request Packet. Then we have created an HTTPWebRequest Object, and set its User-Agent Header
The Cookies which we received in Response to the Request for http://www.facebook.com are added to the HTTPWebRequest object, if we dont add these Cookies, then instead of enterteaining our request for login, Server will redirect us to Login page. Next we are setting HTTP Method to Post and Version to 1.1(used for HTTPS).
Setting the AllowAutoRedirect Property to false for requests in which we try to login is very important, if this property is set to true, then the HTTPWebRequest object will follow the Redirection Responses. And
during the redirections, you may lost access to the Cookies which server sent in response to Login Request.
Now Lets send the Login Info to the Server.
//Converting postData to Array of Bytes byte[] byteArray = Encoding.ASCII.GetBytes(postData); //Setting Content-Length Header of the Request getRequest.ContentLength = byteArray.Length; //Obtaining the Stream To Write Data Stream newStream = getRequest.GetRequestStream(); //Writing Data To Stream newStream.Write(byteArray, 0, byteArray.Length); newStream.Close();
Data is written to stream, now lets get the Response and see what all Cookies we Receive
HttpWebResponse getResponse = (HttpWebResponse)getRequest.GetResponse();
string txt = "Cookies Count=" + getResponse.Cookies.Count.ToString() + "\n";
foreach (Cookie c in getResponse.Cookies) {
txt += c.ToString() + "\n";
}
MessageBox.Show(txt);

We successfully logged into the system and received 9 Cookies, the snapshot above shows very little info about the received Cookies, you can get more info by accessing the properties of the Cookies
Add the received Cookies to globally defined CookieCollection so that it can be used in subsequent requests
How to Check Login was Successfull or Not? Normally Cookies Count is an easy way to determine that Login was successfuly or not, to bemore sure, you can try getting HTML of Home Page, if you r not redirected to Login Page, that means u r successfully logged in.
Example 3: Custom HTTPWebRequest for Login
In Last example, we just replayed the HTTP Packet which mozilla Browser generated. Now let see from where the POST Url and PostData fields were obtained. Log Off from FaceBook, and open the Login Page. Right Click on Email textBox and click on Inspect Element.

Following HTML pane will appear in the bottom. Click on the Form Element

Here you can see the action filed in the highlighted area, this filed tells the url on which data is to be posted.
Below the highlighted area u can see few input fields, in Example 2, postData u saw many fields other than the email and password, so basically these fields were being sent to the server along with the email and password. These are part of the login Form, and these must be sent to the server along with the login info. Facebook changes the values of these fields frequently, so you cant hardcode these field’s values in the software/app.
Now we will see how to obtain these values from the facebook login page source code.
You can use Regex, string manipulation or some 3rd party HTML Parsing Library to obtain these fields and their values. I am using HTML Agility Pack to get the Login form tag and its all child input tags, and finally preparing the postData
Now you can post the Data in same way as we did in Example 2. Once the Successful Login Cookies are recevied, Add it to Globally defined CookieCollection, then for any subsequent request, send these Cookies with the HTTPWebRequest.
string email="youremail";
string passwd="yourpassword"; string postData = ""; //Load FB login Page HTML
A.HtmlDocument doc = new A.HtmlDocument();
doc.LoadHtml(fb_html); //Get Login Form Tag A.HtmlNode
node = doc.GetElementbyId("login_form");
node = node.ParentNode; //Get All Hidden Input Fields //Prepare Post Data
int i = 0; foreach(A.HtmlNode h in node.Elements("input"); {
if(i>0)
{
postData += "&";
}
if(i == 1)
{
postData += "email=" + email + "&";
postData += "pass=" + passwd + "&";
}
postData += (h.GetAttributeValue("name", "") + "=" +
h.GetAttributeValue("value", ""));
i++;
}
Example 4: Uploading Pic to the Profile
We are going to upload picture to the profile using mobile version of the facebook, and leaving the upload to normall facebook as a task for the user.
To upload pictures/files, multipart/form-data is used as Content Type.
-
First lets examine the HTTP traffic for uploading the picture by LiveHTTPHeaders
Login to http://m.facebook.com/, and upload a picture.
-
You will see HTTP Request like following in LiveHTTPHeaders

By now you must be familiarize with the above HTTP Request Headers, the only thing different is the way of posting the data, instead of using application/x-www-form-urlencoded, we are using multipart/form-data. You can also observe the layout of the postData (just below the ContenType)
Now Lets Examine from where these all fields like fb_dtsg, characterset etc came. Right Click on Upload Photo form on upload page and select Inspect element.

You can see all the fields are here under the form tag for photo upload. Again you can use Regex, string manipulation or HTMLAgilityPack to get the name and values of these fields. But 1st you need to get the HTML of this page
Let's get all these fields and add to a dictionary Collection. This class is available in
System.Collections. Make a dictionary variable nvcAs you can see there is no ID for the photoupload form, so 1st use string manipulation to get the form tag html and then use HTMLAgilityPack to easily get all input tags.
We will use Following Function to upload photo
The Details of the passes arguments is as following
HttpWebRequest req = (HttpWebRequest)WebRequest.Create("http://m.facebook.com/upload.php");
req.CookieContainer = new CookieContainer();
req.CookieContainer.Add(cookies);
req.AllowAutoRedirect=true;
req.UserAgent = "Mozilla/2.0 (Windows NT 6.1) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/5.0.874.121";
HttpWebResponse resp = (HttpWebResponse)req.GetResponse();
StreamReader sr = new StreamReader(resp.GetResponseStream());
string uploadHTML = sr.ReadToEnd();
Dictionary<string, string> nvc = new Dictionary<string, string>();
uploadHTML = uploadHTML.Substring(uploadHTML.IndexOf("<form"));
uploadHTML = uploadHTML.Replace("<form","<formid=\"myform\" ");
uploadHTML = uploadHTML.Remove(uploadHTML.IndexOf("/form>") + 6);
A.HtmlDocument doc = new A.HtmlDocument();
doc.LoadHtml(html);
A.HtmlNode node = doc.GetElementbyId("myform");
node = node.ParentNode;
foreach (A.HtmlNode h in node.Elements("input"))
{
string key = h.GetAttributeValue("name", "");
if (key != "")
nvc.Add(key, h.GetAttributeValue("value",""));
}
HttpUploadFile("http://upload.facebook.com/mobile_upload.php",
"file1", "filename", @"filePath", "image/jpeg", nvc);
Action URL of the Upload Form
Name of the input tag for the File to upload
Name of the file
Path to the file on your computer
File type, in this case its image with extension jpeg
A dictionary containing all the input tags name and values
Following the complete piece of code for the
HTTPUploadFilefunction
public void HttpUploadFile(string url,string paramName, string filename,
string filepath, string contentType, Dictionary<string,string> nvc)
{
//Prepairing PostData Format
string boundary = "---------------------------" + DateTime.Now.Ticks.ToString("x");
byte[] boundarybytes = System.Text.Encoding.ASCII.GetBytes("\r\n--" + boundary + "\r\n");
//Creating Request to Action URL
HttpWebRequest wr = (HttpWebRequest)WebRequest.Create(url);
wr.ContentType = "multipart/form-data; boundary=" + boundary;
wr.KeepAlive = true;
wr.CookieContainer = new CookieContainer();
//Adding Cookies Received at Login
wr.CookieContainer.Add(cookies);
wr.Method = WebRequestMethods.Http.Post;
wr.UserAgent = "Mozilla/2.0 (Windows NT 6.1) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/5.0.874.121";
wr.AllowWriteStreamBuffering = true;
wr.ProtocolVersion = HttpVersion.Version11;
wr.AllowAutoRedirect = true;
wr.Referer = "Referer: http://m.facebook.com/upload.php";
//Obtaining Stream to Write Data
Stream rs = wr.GetRequestStream();
string formdataTemplate = "Content-Disposition:
form-data; name=\"{0}\"\r\n\r\n{1}";
foreach (string key in nvc.Keys)
{
rs.Write(boundarybytes, 0, boundarybytes.Length);
string formitem = string.Format(formdataTemplate, key, nvc[key]);
byte[] formitembytes = System.Text.Encoding.UTF8.GetBytes(formitem);
//Writing all the input tags values
rs.Write(formitembytes, 0, formitembytes.Length);
}
rs.Write(boundarybytes,0, boundarybytes.Length);
//Writing File Contents
string headerTemplate = "Content-Disposition: form-data; " +
"name=\"{0}\"; filename=\"{1}\"\r\nContent-Type:{2}\r\n\r\n";
string header = string.Format(headerTemplate, paramName, filename, contentType);
byte[]headerbytes = System.Text.Encoding.UTF8.GetBytes(header);
rs.Write(headerbytes, 0, headerbytes.Length);
FileStream fileStream = new FileStream(filepath, FileMode.Open, FileAccess.Read);
byte[] buffer = new byte[4096];
int bytesRead = 0;
while((bytesRead = fileStream.Read(buffer, 0, buffer.Length)) != 0)
{
rs.Write(buffer, 0,bytesRead);
}
fileStream.Close();
//Completing the Data
byte[] trailer = System.Text.Encoding.ASCII.GetBytes("\r\n--" + boundary + "--\r\n");
rs.Write(trailer, 0, trailer.Length);
rs.Close();
//Receving Response
HttpWebResponse wresp = (HttpWebResponse)wr.GetResponse();
cookies.Add(wresp.Cookies);
StreamReader sr = new StreamReader(wresp.GetResponseStream());
string sourceCode = sr.ReadToEnd();
StreamWriter sw = new StreamWriter("upload.html");
sw.Write(sourceCode);
sw.Close();
Task 1: Make Wall Posting Software for www.tagged.com
Task 2: Investigate some site which uses AJAX, to see how to use HTTPWebRequest, HTTPWebResponse for it
Task 3: Perform Login at some sites, using login cookies, view login protected pages