
Xbox Gamer Tag Reader
5.00/5 (1 vote)
Crawls any public Xbox live gamer card and provides the tags / users data in an easy to access manner for formatting and manipulation. Uses regex for parsing.
Introduction
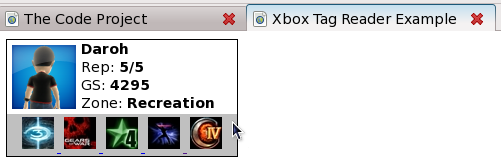
When I first found out about the Xbox Live Gamer Cards, I quickly started thinking about how I could use it on forums, emails, etc. The problems started however when I wanted to be able to integrate the card seamlessly into my own site, the basic design never seemed to work. After a bit of web searching, I was disappointing to find no API available (for free) that allowed you to customize it. Sure there are a few websites that offer a solution but the same basic problem always exists - you are stuck with their designs.
A couple of years ago, I wrote a little python script that crawled the basic gamer cards HTML and re-organized it into a new image (there are a few examples of this on the web). Recently I've been thinking about integrating the card data into my sites again, the custom image could work but trying to use image libraries to make complex designs can be a pain programmatically for something so small. Why does it need to be an image? What if I want to split the card data for a user over several pages of my site, or simply display the users most recent games on one side of my page and their gamer score on another. For this, I need the raw data to manipulate, save and format.
The Solution
There are a couple of things I wanted to do differently from my original python script. The first was to use PHP, my current web host doesn't support python, it's growing into the LAMP stack but I don't think it's quite there yet (from shared host point of view). The second was to take a less brute force approach to line by line parsing of the file, looking for specific HTML and moving n characters forward or back. Finally I wanted to try and use reg-ex, which to be honest, is something I've tended to avoid in the past because I just can never remember what all the characters mean :-(.
Attached to this article is a simple PHP class and example web page. The class downloads the HTML data of a given gamers card based on their tag / user name and parses the data into a set of class properties such as reputation, gamer-score and recently played games for easy access. I wanted to keep the code fairly focused and have avoided expanding it too much to include more complex features such as caching and connection error handling (such as what to do if the xbox.com website is down). This is largely because this is my first CodeProject article and I wanted to test the water and partly because I would like the class to act as a foundation and for any additional complexity to be provided at a higher level in my application, e.g. a user object class may use the class to reference the gamer card data if its database record is blank or has expired.
Using the Code
The code is pretty easy to use in it current form. Simply create an instance of the class and call the load() method with a valid gamer tag / user name for Xbox Live.
require_once 'XboxTagReader.php';
$tag = new XboxTagReader();
$tag->load("Daroh");
...
That's it. If the load() method returns true, then at least the basic information for the user has been read successfully, to then access data call the appropriate get methods on the class.
...
<a href="%22<?= $tag->getProfileURL() ?>%22">getProfileURL() ?>">
<img src="%22<?= $tag->getAvatarURL() ?>%22" style=""float:left;"
padding:5px">getAvatarURL() ?>" style="float:left; padding:5px" /> </a>
<?= $tag->getName(); ?>
...
The above example simply shows the user's avatar / icon as a hyperlink to their profile on xbox.com and their user name. An example of all the available methods is provided in the demo project within the index.php file.
Points of Interest
One of the first things the class does when you provide a gamer tag is to download the HTML from the xbox.com website. PHP makes this very simple as all you need to do is provide the URL / IP address of the host (in this case gamercard.xbox.com) and then read the files contents. The only 'trick' when you want to read a web page over HTTP is the file will be empty until you request its contents using a GET request. This is one of those things you don't need to understand to use. If you are interested however I'd advise looking into sockets, file pointers and HTTP protocol GET, POST requests.
/*
* Download the entire gamer card (html string) from the base host and path
*
* @return false on error or string response from base host and path
*/
private function download_card($gamerTag)
{
$fp = fsockopen(BASE_HOST, 80, $errno, $errstr, 30);
if (!$fp)
{
echo "$errstr ($errno)<br />\n";
return false;
}
else
{
// Build a HTTP GET request, this includes the path of the base host
// replace [GamerTag] in the path with the current gamer tag
$getRequest = "GET /".str_replace("[GamerTag]",
strtolower($gamerTag), BASE_PATH)." HTTP/1.1\r\n";
$getRequest .= "Host: ".BASE_HOST."\r\n";
$getRequest .= "Connection: Close\r\n\r\n";
fwrite($fp, $getRequest);
$response = "";
while (!feof($fp))
$response .= fgets($fp, 128);
fclose($fp);
// Remove space characters (space, new line, etc) from the response
return preg_replace('/\s+/', " ", $response);
}
}
First the functions connects to our host (gamercard.xbox.com) on port 80 (the standard web port) using fsockopen, this returns a file pointer ($fp) to the host. Think of this as our link to the web server.
The second thing the function does is to request our file contents using a GET request, this is a formatted string that we 'write' to our file pointer and tell the host what we want from it (e.g. to get .../users/index.html, we would use a GET request like GET /users/index.html).
After a valid get request, our file will contain the web pages HTML, simply read the file into a string and close the file pointer. The last line of the function uses a simple reg-ex find and replace on the entire string to remove any space characters (\s) such as new line, space, tab, etc. This is fairly brutal and will remove every space so we replace with a single space, effectively trimming the document contents.
Once we have the card's HTML, we need to be able to translate it into something meaningful, taking out the key values we want and getting rid of the rest. As I mentioned at the start of the article I wanted to use reg-ex to do this and so the approach I have taken is to tokenize the entire document. All this really means is splitting the long HTML string into an array of smaller strings. After looking at the source HTML, I found all the values that we need are either within a HTML tag attribute e.g. title="Halo 3" or src=".../halo_icon.gif" or within a tag itself e.g. <span>Name Here</span>. We never need to know what tag a value came from so we can disgregard most of the HTML itself.
/*
* The meat of the class. Given a raw html response string from the gamer
* card use regex and string functions to tokenize into an array. The resulting
* array contains allot of rubbish but critically makes everything we need
* later easily available.
*
* @return array
*/
private function tokenize_card($rawData)
{
$tokens = array();
// Creates an array of $matches for all response data that
// lands between '>' and '<' characters OR
// between =" and " characters
// e.g. <span>GETS THIS</span> or title="GETS THIS"
preg_match_all('/>[^<(.*)]+<|="[^"]+"/', $rawData, $matches,
PREG_SET_ORDER);
foreach($matches as $match)
{
// Each match is returned as an array and includes its
// surrounding characters,
// remove them (<,>,=,") and save the token for return
$token = trim(preg_replace('/<|>|="|["]/', "", $match[0]));
if($token != '')
$tokens[] = $token;
}
return $tokens;
}
Given our HTML response string, this function passes it straight into the PHP function preg_match_all which splits our raw data into an array of $matches in the order that they are found based on a reg-ex pattern. As detailed above, there are two patterns where our data could be stored in the HTML, as you'd expect then our reg-ex pattern also has two parts. The first part gets any data between the > and < characters.
>[^<(.*)]+<
The is followed by an OR character | and then the second pattern, telling the preg_match_all function to return every match for either part of our pattern.
="[^"]+"
Once we have an array of matches, the function simply loops through them removing any unwanted HTML characters and spaces. If, after cleaning, our new token isn't an empty string we save it for return. By taking this approach to our HTML string, we have made the parsing stage (looking for our actual data) much easier, for example, to get the users gamer score, we simply reference the correct token index in our array.
... $this->gamerscore = (int)$tokens[29]; ...
Obviously, if the gamer tag HTML provided by Xbox changes (though it hasn't in the last 3 years) the class will need to be updated, however, hopefully due to the nature of HTML the tokenize function should not need to be updated (there aren't that many other places values could be stored). In order to minimize any changes that would be required in the case of a change all the token references to specific indexes are used within a single function called update_data(). If the HTML does change the most likely result would be the data would shift in our token array maybe changing the gamer score from index 29 to 30, for example.
Although this is fairly simplistic I wouldn't advise trying to over complicate your parsing as its simply impossible to tell what Microsoft may do with the tags in the future.