
Create Your Own Googlebot
In this article, I explain how to create an application like Googlebot - it finds and indexes websites throught hyperlinks.
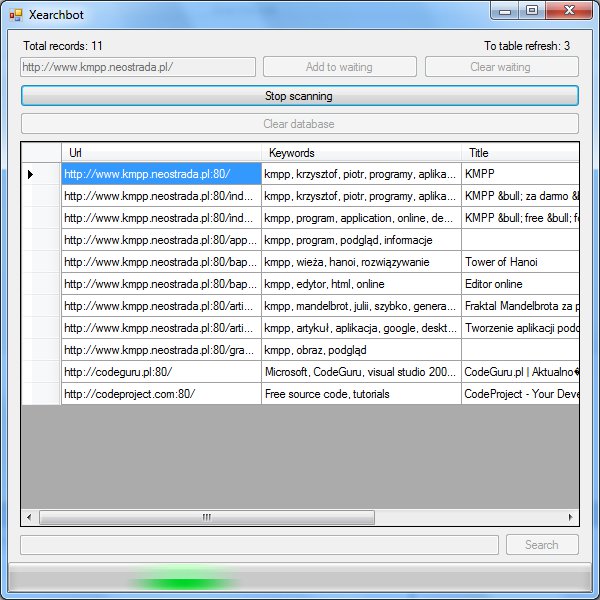
Introduction
Googlebot finds and indexes the web through hyperlinks. It still goes to the new pages through hyperlinks in the old sites. My searchbot (Xearchbot) can find sites and stores its URL, title, keywords metatag and description metatag in database. In the future, it will store the body of the document converted to plain text. I don't calculate PageRank, because it is very time-consuming.
Before Googlebot downloads a page, it downloads file robots.txt. In this file, there is information where bot can go and where it musn't go. This is an example content of this file:
# All bots can't go to folder "nobots":
User-Agent: *
Disallow: /nobots
# But, ExampleBot can go to all folders:
User-Agent: ExampleBot
Disallow:
# BadBot can't go to "nobadbot1" and "nobadbot2" folders:
Disallow: /nobadbot1
Disallow: /nobadbot2
There is the second way to block Googlebot: Robots metatag. It's name attribute is "robots" and content attribute has values separated by comma. There is "index" or "noindex" (document can be indexed or not) and "follow" or "nofollow" (follow hyperlinks or not). For indexing document and following hyperlinks, metatag looks like this:
<meta name="Robots" content="index, follow" />
Blocking of following of single link is supported too - in order to do that, it's rel="nofollow". Malware robots and antiviruses' robots ignore robots.txt, metatags and rel="nofollow". Our bot will be normal searchbot and must allow all of the following blockers.
There is an HTTP header named User-Agent. In this header, client application (eg., Internet Explorer or Googlebot) shall be presented. For example User-Agent for IE6 looks like this:
User-Agent: Mozilla/4.0 (Compatible; Windows NT 5.1; MSIE 6.0)
(compatible; MSIE 6.0; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)
Yes, the name of Internet Explorer for HTTP is Mozilla... This is Googlebot 2.1 User-Agent header:
User-Agent: Googlebot/2.1 (+http://www.googlebot.com/bot.html)
The address in brackets, after plus char is the information about the bot. We put similar data in this header for our bot.
In order to speed up searchbot, we can support GZIP encoding. We can add header Accept-Encoding with value "gzip". Some websites allow GZIP encoding and if we accept gzip, then they send compressed document to us. If content is compressed, then server will add Content-Encoding header (in response) with value "gzip". We can decompress the document using System.IO.Compression.GZipStream.
For parsing robots.txt, I use string functions (IndexOf, Substring...) and for parsing HTML I use Regular Expressions. In this article, we will use HttpWebRequest and HttpWebResponse for downloading files. At first, I thought about using WebClient, because it's easier, but in this class we can't set timeout of downloading.
For this article, SQL Server (can be Express) and basic knowledge about SQL (DataSets, etc.) are required.
Fundamentals discussed, so let's write a searchbot!
Database
First we have to create new Windows Forms project. Now add a Local Database named SearchbotData and create its DataSet named SearchbotDataSet. To database, add table Results:
| Column Name | Data Type | Length | Allow Nulls | Primary Key | Identity |
id_result |
int |
4 | No | Yes | Yes |
url_result |
nvarchar |
500 | No | No | No |
title_result |
nvarchar |
100 | Yes | No | No |
keywords_result |
nvarchar |
500 | Yes | No | No |
description_result |
nvarchar |
1000 | Yes | No | No |
In this table, we will store results. Add this table to SearchbotDataSet.
Preparation
First, we must add the following using statements:
using System.Net;
using System.Collections.ObjectModel;
using System.IO;
using System.IO.Compression;
using System.Text.RegularExpressions;
The sites will wait for indexing in Collection:
Collection<string> waiting = new Collection<string>(); // Here sites wait for indexing
In the web, there are billions of pages and the number of them is increasing. Our bot would never have finished indexing. So we must have a variable, which stops the bot:
bool doscan; // Do scanning. If doscan is false then main bot function will exit.
The bot function will check this variable before it starts indexing next page. Let's add Scan method - the main function of our bot's engine.
/// <summary>
/// Scans the web.
/// </summary>
void Scan()
{
while (waiting.Count > 0 && doscan)
{
try
{
string url = waiting[0];
waiting.RemoveAt(0);
Uri _url = new Uri(url);
}
catch { }
}
}
The code for indexing page will be in the loop. At the start, in waiting there must be minimum one page with hyperlinks. When the page is parsed, it will be deleted from waiting, but found hyperlinks will be added - and so we have the loop. The Scan function can be run in other thread by e.g., BackgroundWorker.
Parsing robots.txt
Before we start indexing of any website, we must check robots.txt file. Let's write class for parsing this file.
In my bot, I name this class RFX - Robots.txt For Xearch.
/// <summary>
/// Robots.txt For Xearch.
/// </summary>
class RFX
{
Collection<string> disallow = new Collection<string>();
string u, data;
/// <summary>
/// Parses robots.txt of site.
/// </summary>
/// <param name="url">Base url of site</param>
public RFX(string url)
{
try
{
u = url;
}
catch { }
}
}
The url parameter is an address without "/robots.txt". The constructor will download the file and parse it. So download the file: first create request. All must be inner try statement, because HTTP errors are thrown.
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(u + "/robots.txt");
req.UserAgent = "Xearchbot/1.1 (+http://www.kmpp.neostrada.pl/xearch.htm)";
req.Timeout = 20000; // Maximal downloading time is 20 seconds.
Now get response and its stream:
HttpWebResponse res = (HttpWebResponse)req.GetResponse();
Stream s = res.GetResponseStream();
We can read all data from s by StreamReader.
StreamReader sr = new StreamReader(s);
data = sr.ReadToEnd();
At the end of downloading, we must close all:
sr.Close();
res.Close();
Now the downloaded robots.txt is in data variable, so we can parse it. Write function for parsing single agent section.
/// <summary>
/// Parses agent in robots.txt.
/// </summary>
/// <param name="agent">Agent name</param>
/// <returns>True if agent exists, false if don't exists.</returns>
bool parseAgent(string agent)
{
}
If there is a specified section for our bot then we must parse only it, but if not then we must parse section for all bots. So add the following lines into constructor.
// If it's section for Xearchbot then don't parse section for all bots.
if (!parseAgent("Xearchbot"))
parseAgent("*");
Now let's write code of parseAgent. First, we must find the start of section for specified user agent:
int io = data.LastIndexOf("User-agent: " + agent); // Start of agent's section
if (io > -1)
{
int start = io + 12 + agent.Length;
return true;
}
else
return false;
If the section exists then at the end it returns true, if not it returns false. Now we must find the end. Add this after line with start.
int count = data.IndexOf("User-agent:", start); // End of agent's section
if (count == -1)
count = data.Length - start; // Section for agent is last
else
count -= start + 1; // end - start = count
Now we have region with commands to parsing. I will not prolong, add these lines:
while ((io = data.IndexOf("Disallow: /", start, count)) >= 0) // Finding disallows
{
count -= io + 10 - start; // Recalculating count
start = io + 10; // Moving start
string dis = data.Substring(io + 10); // The path
io = dis.IndexOf("\n");
if (io > -1)
dis = dis.Substring(0, io).Replace("\r", ""); // Cutting to line end
if (dis[dis.Length - 1] == '/')
dis = dis.Substring(0, dis.Length - 1); // Deleting "/" at the end of path.
disallow.Add(u + dis); // Adding disallow
}
These lines find and parse Disallow statements. Now add new method for checking if we can parse document:
/// <summary>
/// Checks we can allow the path.
/// </summary>
/// <param name="path">Path to check</param>
/// <returns>True if yes, false if no.</returns>
public bool Allow(string path)
{
foreach (string dis in disallow)
{
if (path.StartsWith(dis))
return false;
}
return true;
}
This compares the path with every disallowed path.
Now go back to main form's class and add collection for robots files:
Dictionary<string, RFX> robots = new Dictionary<string, RFX>(); // Parsed robots files
Here we will store compiled robots files.
Checking URLs
Our bot will support only HTTP and HTTPS protocols. So we have to check the scheme of url in try in Scan function:
Uri _url = new Uri(url);
if (_url.Scheme.ToLower() == "http" || _url.Scheme.ToLower() == "https")
{
}
The addresses can have a different protocol. For disambiguation, let's reformat the url:
string bu = (_url.Scheme + "://" + _url.Host + ":" + _url.Port).ToLower();
url = bu + _url.AbsolutePath;
The bu variable is the baseUrl for RFX. Now each protocol is specified in path, default protocol (80) also.
The address can be indexed and then we should not index the second time. So let's add new query to ResultsTableAdapter (it should be created when you add Result table to dataset). The query will be type of SELECT, which returns a single value. It's code:
SELECT COUNT(url_result) FROM Results WHERE url_result = @url
Name it CountOfUrls. It returns a count of specified URLs. Using it, we can check if the URL is in database.
To main form, add a resultsTableAdapter. If you want to display results in DataGrid and refresh it, while scanning, then use 2 table adapters - first for displaying, second for Scan function. So we have to check if the url is indexed:
if (resultsTableAdapter2.CountOfUrls(url) == 0)
{
}
Now we must check the robots.txt. We have declared a Dictionary for these parsed files. If we have the parsed robots.txt of the site, we get it from the Dictionary, otherwise we must parse robots.txt and add this to Dictionary.
RFX rfx;
if (robots.ContainsKey(bu))
{
rfx = robots[bu];
}
else
{
rfx = new RFX(bu);
robots.Add(bu, rfx);
}
Now the parsed file is in the rfx and we can check the URL:
if (rfx.Allow(url))
{
}
The url is checked. We can now proceed to parsing the file.
Downloading Document
How to download document you know from the section "Parsing robots.txt". Here it is more complicated because we have to check document type.
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(url);
req.UserAgent = "Xearchbot/1.1 (+http://www.kmpp.neostrada.pl/xearch.htm)";
req.Timeout = 20000;
HttpWebResponse res = (HttpWebResponse)req.GetResponse();
Information about document type is in Content-Type header. The beginning of this header's value is MIME type of document. Typically after MIME, there are other information separated by semicolon. So parse Content-Type header:
string ct = res.ContentType.ToLower();
int io = ct.IndexOf(";");
if (io != -1)
ct = ct.Substring(0, io);
The MIME type of HTML document is text/html and XHTML document can have text/html too or application/xhtml+xml. So if document type is text/html or application/xhtml+xml, we can process the document.
if (ct == "text/html" || ct == "application/xhtml+xml")
{
}
res.Close();
At the end, we must close response. Now we have to read all data from document (put this inside if of course):
Stream s = res.GetResponseStream();
StreamReader sr = new StreamReader(s);
string d = sr.ReadToEnd();
sr.Close();
Parsing Metatags
It's time for parsing the document. For parsing HTML elements, I chose the way through the regular expressions. In .NET, we can use them by System.Text.RegularExpressions.Regex class. The regular expressions are powerful tools for comparing strings. I will not explain the syntax. For finding and parsing metatags, I designed the following regex:
<meta(?:\s+([a-zA-Z_\-]+)\s*\=\s*([a-zA-Z_\-]+|\"[^\"]*\"))*\s*\/?>
The regular expressions can store some parts of matched strings. This regex store names and values of attributes.
So declare this regex in the class:
/// <summary>
/// Regular expression for getting and parsing Meta tags.
/// </summary>
public Regex parseMeta = new Regex(@"<meta(?:\s+([a-zA-Z_\-]+)\s*\=\s*([a-zA-Z_\-]+|\" +
'"' + @"[^\" + '"' + @"]*\" + '"' + @"))*\s*\/?>",
RegexOptions.Compiled | RegexOptions.IgnoreCase);
Here there are escaped quote chars. This regex has flags Compiled and IgnoreCase. I think I don't have to explain what they mean. Now go to the loop and declare these variables:
string title = "";
string keywords = "";
string description = "";
bool cIndex = true;
bool cFollow = true;
Let's parse metatags. With regex, this is very easy:
MatchCollection mc = parseMeta.Matches(d);
mc is collection of found metatags. Now we have to process all of the metatags:
foreach (Match m in mc)
{
}
In m, we have a found metatag. We want to read attributes. The captured names and values we can get from the Groups property.
CaptureCollection names = m.Groups[1].Captures;
CaptureCollection values = m.Groups[2].Captures;
In names we have names of attributes and in values we have values of attributes in the same order. If metatag is correct, then the count of names is equal to the count of values:
if (names.Count == values.Count)
{
}
Now let's declare the variables, which will contain metatag name and content:
string mName = "";
string mContent = "";
Now we have to find the name and content attributes in names and values.
for (int i = 0; i < names.Count; i++)
{
string name = names[i].Value.ToLower();
string value = values[i].Value.Replace("\"", "");
if (name == "name")
mName = value.ToLower();
else if (name == "content")
mContent = value;
}
We have name of metatag in mName and content of metatag in mContent. Our bot will check robots metatag, but it will store keywords and description metatags too. So parse it:
switch (mName)
{
case "robots":
mContent = mContent.ToLower();
if (mContent.Trim().ToLower().IndexOf("noindex") != -1)
cIndex = false;
else if (mContent.IndexOf("index") != -1)
cIndex = true;
if (mContent.IndexOf("nofollow") != -1)
cFollow = false;
else if (mContent.IndexOf("follow") != -1)
cFollow = true;
break;
case "keywords":
keywords = mContent;
break;
case "description":
description = mContent;
break;
}
Keywords and description is simple - we don't have to parse it. Robots metatag is more complicated, because it controls the robot and we must parse it. Metatags parsing is completed.
Parsing hyperlinks and base tags
To parse hyperlinks, I create other regex:
<a(?:\s+([a-zA-Z_\-]+)\s*\=\s*([a-zA-Z_\-]+|\"[^\"]*\"))*\s*>
In HTML there is a tag for changing base path of all links. We have to implement this in our bot. There is a regex for parsing it:
<base(?:\s+([a-zA-Z_\-]+)\s*\=\s*([a-zA-Z_\-]+|\"[^\"]*\"))*\s*\/?>
We have to declare it:
/// <summary>
/// Regular expression for getting and parsing A tags.
/// </summary>
public Regex parseA = new Regex(@"<a(?:\s+([a-zA-Z_\-]+)\s*\=\s*([a-zA-Z_\-]+|\" +
'"' + @"[^\" + '"' + @"]*\" + '"' + @"))*\s*>",
RegexOptions.Compiled | RegexOptions.IgnoreCase);
/// <summary>
/// Regular expression for getting and parsing base tags.
/// </summary>
public Regex parseBase = new Regex(@"<base(?:\s+([a-zA-Z_\-]+)\s*\=\s*([a-zA-Z_\-]+|\" +
'"' + @"[^\" + '"' + @"]*\" + '"' + @"))*\s*\/?>",
RegexOptions.Compiled | RegexOptions.IgnoreCase);
Let's write method for parsing and adding hyperlinks to waiting.
void follow(string d, Uri abs)
{
}
We must find and parse tags:
MatchCollection bases = parseBase.Matches(d);
mc = parseA.Matches(d);
foreach (Match m in mc)
{
CaptureCollection names = m.Groups[1].Captures;
CaptureCollection values = m.Groups[2].Captures;
if (names.Count == values.Count)
{
string href = "";
string rel = "";
for (int i = 0; i < names.Count; i++)
{
string name = names[i].Value.ToLower();
string value = values[i].Value.Replace("\"", "");
if (name == "href")
href = value;
else if (name == "rel")
rel = value;
}
}
}
We must check rel attribute. If its value is nofollow then we don't have to add it to waiting. If href is empty then we don't add URL to waiting either. The href can be relative path. So we have to join it with abs.
if (rel.IndexOf("nofollow") == -1 && href != "")
{
Uri lurl = new Uri(abs, href);
waiting.Add(lurl.ToString());
}
Now can come back to Scan method. We have to check cFollow variable - we store parsed value from robots metatag in it.
if (cFollow)
{
}
Let's parse base tags:
mc = parseBase.Matches(d);
Uri lastHref = _url;
for (int j = 0; j < mc.Count; j++)
{
Match m = mc[j];
CaptureCollection names = m.Groups[1].Captures;
CaptureCollection values = m.Groups[2].Captures;
if (names.Count == values.Count)
{
string href = "";
for (int i = 0; i < names.Count; i++)
{
string name = names[i].Value.ToLower();
string value = values[i].Value.Replace("\"", "");
if (name == "href")
href = value.ToLower();
}
}
}
Hyperlinks can be before the first base tag too. So before loop, we must parse hyperlinks with default absolute path - document path:
string d2 = d;
if (mc.Count > 0)
d2.Substring(0, mc[0].Index);
follow(d2, _url);
Now let's parse sections with links for each base tags:
d2 = d.Substring(m.Index);
if (j < mc.Count - 1)
d2.Substring(0, mc[j + 1].Index);
if (href != "")
lastHref = new Uri(href);
follow(d2, lastHref);
When base tag haven't href attribute then we use href from latest base tag.
Parsing Title and Adding to Database
It's time for title and adding indexed document to database. We have to check index.
if (cIndex)
{
}
Now we have to declare the regex for parsing title:
/// <summary>
/// Regular expression for getting title of HTML document.
/// </summary>
public Regex parseTitle = new Regex(@"<title(?:\s+(?:[a-zA-Z_\-]+)" +
"\s*\=\s*(?:[a-zA-Z_\-]+|\" + '"' + @"[^\" + '"' + @"]*\" + '"' +
@"))*\s*>([^<]*)</title>", RegexOptions.Compiled | RegexOptions.IgnoreCase);
So let's parse the title:
mc = parseTitle.Matches(d);
if (mc.Count > 0)
{
Match m = mc[mc.Count - 1];
title = m.Groups[1].Captures[0].Value;
}
We consider only last appearance of title tag. Now we must add new SQL INSERT command for adding a row to table. Its name will be InsertRow. This is the command:
INSERT INTO Results (url_result, title_result, keywords_result, description_result)
VALUES (@url, @title, @keywords, @description)
Now we can add the result to Results table:
resultsTableAdapter2.InsertRow(url, title.Trim(), keywords.Trim(), description.Trim());
This will be added after title is parsed.
GZIP Encoding
We can speed up downloading with GZIP encoding. Some websites support this feature.
We have to add an Accept-Encoding header to request:
req.Headers["Accept-Encoding"] = "gzip";
When we get stream:
Stream s = res.GetResponseStream();
...we must check if the stream is gzipped and ungzip it if it is so:
Stream s;
if (res.Headers["Content-Encoding"] != null)
{
if (res.Headers["Content-Encoding"].ToLower() == "gzip")
s = new GZipStream(res.GetResponseStream(), CompressionMode.Decompress);
else
s = res.GetResponseStream();
}
else
s = res.GetResponseStream();
You can add this in the Scan method and in RFX.
The robot is completed!
Conclusion
In the web, there are billions of pages and the number of them is increasing. In order to block robots, we can use robots.txt file, robots metatag and rel="nofollow" attribute. Malware robots will ignore these blockers. In order to speed up downloading, we can use GZIP encoding. The regular expressions are powerful tools for parsing strings.
History
- 2011-08-20 - Initial post
- 2011-08-22 - Corrections,
basetag support