
High Performance Unicode Text File I/O Routines for C++
4.76/5 (25 votes)
Surprisingly, neither the C++ runtime library nor the Win32 Platform SDK provides any routines to read and write Unicode text files. This article provides high performance routines to read all types of Unicode files (both UTF-16 and UTF-8) as well as ANSI files.
- Download demo project (Visual Studio 2005) - 49.23 KB
- Download source files (Visual Studio 2005) - 15.2 KB
Introduction
Surprisingly, neither the C++ runtime library nor the Win32 Platform SDK provides any routines to read and write Unicode text files, so, when I needed some, I had to write my own. There are three reasons why you might choose to use these routines over others you can find out there on the Internet and elsewhere here on CodeProject: performance, performance and performance. And convenience. You can read and write any or all of ANSI, UTF-8, UTF-16 little-endian and UTF-16 big-endian files with no code changes on your part. These routines are not reliant on MFC in any way, so you can use them in any C++ project you like.
Just What are Unicode Text Files, Anyway?
Unicode text files come in three flavours: UTF-16 little-endian, UTF-16 big-endian, and UTF-8. There are also, unfortunately, three different conventions for delimiting lines: DOS/Windows (CRLF), Unix (LF only), and Mac (CR only). EZUTF handles all three types of file encoding (as well as ANSI files) and two of the three types of line delimiters. It cannot read CR-delimited files (although it can write them).
UTF-16 files store two bytes per character, which is why there are little-endian and big-endian variants. Little-endian files store the characters least-significant-byte first whereas big-endian files do the reverse. It is possible to tell which type of file you are reading because, by convention, UTF-16 files contain a two-byte marker - called a BOM - at the start of the file which differs between the two formats. For little-endian files it is 0xFF, 0xFE whereas for big-endian files it is - you guessed it - the reverse.
UTF-8 files are rather nifty, in that they can encode the entire UTF-16 character set but are half the size of UTF-16 files if you are storing only ASCII characters (i.e. character codes below 128). They are also highly portable between different systems and this is how multi-lingual Web pages travel around, in case you were curious. UTF-8 files store characters as sequences of 1, 2, 3 or 4 bytes depending on the character code in question, with ASCII characters always being encoded as 1 byte and all Latin (and other western) characters as 2 bytes. On the other hand, Chinese and Japanese characters encode as 3 bytes, so if you are storing a lot of these, UTF-16 might be a better choice. There are no byte-ordering issues with UTF-8 files, thankfully, and the 4 byte sequences are never used in Windows apps because they encode characters which lie outside the UTF-16 character set (which is what Windows uses internally).
A UTF-8 file can also be identified as such as they always start with the sequence 0xEF, 0xBB, 0xBF, which differs from the BOMs used for both types of UTF-16 encoding. The encoding of UTF-16 characters as UTF-8 byte sequences is not particularly complicated and is described in more detail here. Alternatively, just take a look at the code, which is commented (a bit).
Finally, just for completeness, ANSI files store each character as a single byte, and hence can only represent character codes of 255 and below. To properly understand an ANSI file, you have to know which code page was used when it was written, although a lot of software simply assumes Windows-1252.
What Does EZUTF Do?
EZUTF provides a set of high-performance routines to read and write all of the types of text files described above without the application having to do any of the necessary translations itself. It can also handle both DOS/Windows (CRLF) and Unix (LF) line-delimiters, but not Mac (CR-only). When a file is opened for reading, EZUTF can be instructed to read the BOM (if any) and hence deduce the file encoding. Alternatively, you can force EZUTF to use a particular encoding to avoid, for example, erroneously treating an ANSI file which happens to start with 0xFF, 0xFE as a UTF-16 file (which would be disastrous). When a file is opened for writing, you tell EZUTF what encoding and line delimiters you want to use and it will take care of all the details, including writing out a BOM at the start of the file.
No 'seek' functionality is provided, but EZUTF can append data to the end of an existing file. In this case, no BOM is written out unless the file was initially empty (or did not exist at all).
Using the Code
The entire public API is wrapped in a single class: TextFile. A TextFile object can be opened and closed, and can read and/or write either lines or single characters.
Reading Files
Here, typically, is how you would open a file for reading:
TextFile *tf = new TextFile;
int result = tf->Open (L"MyFile.txt", TF_READ);
When a file is opened for reading in this way, EZUTF will read the BOM mark in the file, if present, and deduce the file encoding from it. If you want to know what that is, you can use the following (after you have opened the file):
// TF_TF_ANSI, TF_UTF16LE, TF_UTF16BE or TF_UTF8
int file_encoding = tf->GetFileEncoding ();
Alternatively, if you know that you are opening an ANSI file, you would be wiser to use...
TextFile *tf = new TextFile;
int result = tf->Open (L"MyFile.txt", TF_READ, TF_ANSI);
... as this avoids any danger of interpreting the file as Unicode by mistake.
To read lines from a file, you do something like this:
TCHAR *line_buf = NULL;
int result;
while ((result = tf->ReadLine (NULL, &line_buf) >= 0)
// do something; the line just read from the file is in line_buf
free_block (line_buf);
Note that any line delimiter is stripped from the line before it is returned and that line_buf is allocated from within TextFile, not by the caller. This is to handle varying line lengths without having to allocate a buffer on each call. The caller must initialise line_buf to NULL and is responsible for freeing it when done (by calling free_block ()). If you fail to initialise line_buf to NULL, your program will die a horrible death, and if you fail to pass it to free_block () when you are done with it, you will have a memory leak. The pointer returned in line_buf remains valid until you pass it to another TextFile routine (or free it). The initial NULL parameter is for optionally returning 'data lost' in ANSI builds, where Unicode to ANSI translations are required within the TextFile class (see WideCharToMultiByte in the Platform SDK docs).
Writing Files
To open a file for writing, you must specify the encoding you want to use, like so:
TextFile *tf = new TextFile;
int result = tf->Open (L"MyFile.txt", TF_WRITE, TF_UTF8);
Then to write out a line, you would do this:
int result = tf->WriteString (NULL, L"This is a string");
if (result >= 0)
result = tf->WriteChar (NULL, '\n');
Of course, if the line you are writing out is already terminated with a newline (\n) character, you can skip the call to WriteChar (). The initial NULL parameters are for optionally returning 'data lost' when writing to ANSI files, where Unicode to ANSI translations are required within the TextFile class (see WideCharToMultiByte in the Platform SDK docs).
If, like me, you are a fan of fprintf, you can write out formatted data like so:
int n_bottles = 10;
int result = tf->FormatString
(NULL, L"There are %d green bottles, standing on the wall.\n", n_bottles);
Please note that I have not provided support for streams as I do not use them, but adding them would not be difficult and if someone would care to, I will gladly roll their changes into the master sources.
Reading and Writing Unix Files
When reading files, Unix-style (LF-only) line delimiters are handled automatically, i.e. you can just open the file in the normal way and then call ReadLine () as described above. To write out a file using Unix line delimiters, you can do:
TextFile *tf = new textFile;
int result = tf->Open (L"MyFile.txt", TF_WRITE, TF_UTF8 | TF_UNIX);
Writing out a \n character will then write just an LF to the file, rather than a CRLF sequence.
Error Handling and HPSLib
All TextFile methods return an integer, and if an error has occurred this will be negative. End of file also returns a negative value - TF_EOF - so test for this first. To retrieve a string describing the error, call a GetLastErrorString (). This works in a similar way to GetLastError (), but returns a pointer to an internal buffer (per thread) containing a user-friendly error message (e.g. 'Could not open file xyz, error blah'). The pointer returned is valid until you call TextFile again (or SetLastErrorString () from within the same thread. Alternatively, you can call GetLastError () in the usual way and report error conditions in whatever way you choose.
Performance
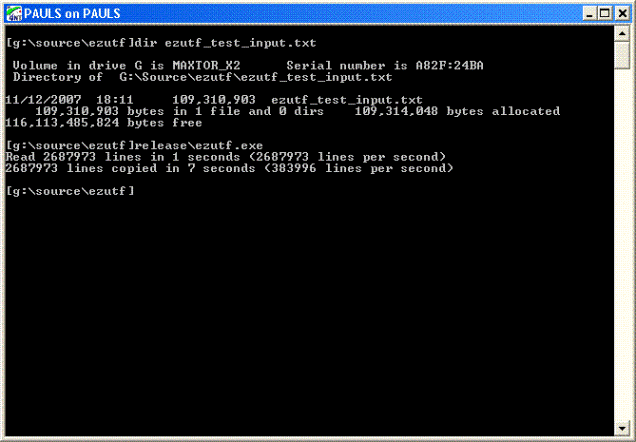
EZUTF is fast! If you have the need for speed, these are the routines for you. Reading a UTF-8 file some 100MB / 2,500,000 lines in size takes under a second on my AMD Athlon 64 3000+, once the file is in the cache. Copying the same file takes about 7 seconds, about the same time as it takes to do a binary copy, although there is considerably more CPU overhead.
By contrast, loading the same file into Notepad takes around 45 seconds, and loading it into Visual Studio 2005 2-3 seconds (which is actually pretty good; I was impressed). These figures refer to the release build - the debug build is a good deal slower.
HPSLib, and Miscellanea
EZUTF is built on top of an in-house library modestly entitled HPSLib. I have provided a minimal subset of this - in files hpslib.cpp, hpsutils.h, hpslib.rc and hpslib.hr - which provide enough functionality for the TextFile class to operate as designed. You will need to include these in any project where you use the TextFile class, or you might elect to copy the text strings from hpslib.rc (there are only 4 of them) across into your own *.rc file.
The demo app is a console app and expects to find a file called ezutf_test_input.txt in the current directory, which it copies to ezutf_test_output.txt. If you want to step through the code, build the debug version.
Newcomers to C++ might be interested in the use made of templates, virtual functions and inline functions in the implementation. Personally, I use templates rarely, but when you need 'em, you need 'em. More methods should probably be private.
History
- December 2007: Initial version
- February 2008: Added some
consts - March 2008: Fixed a memory overwrite when reading files with long lines (sorry about that - thanks to IanLo for uncovering the problem) and added support for Unicode surrogate pairs. Please note that the latter has only been lightly tested.
- August 2008: You can now pass a file encoding (e.g.
TF_UTF8) toTextFile::Openwhen opening a file forTF_READaccess. EZUTF will still attempt to read the BOM but will not require it to be present. - November 2008: Made it clear that the source code and project files included in the download zip files are for Visual Studio 2005.