
OWASP #6 Preventing Sensitive Data Exposure in ASP.NET – Part 1
5.00/5 (9 votes)
OWASP's #6 most vulnerable security risk has to do with keeping secrets secret.
Sensitive Data Exposure
In 2007, Albert Gonzalez went on a hacking spree, siphoning off businesses’ credit card information. Steve Heymann, a Massachusetts assistant U.S. attorney, pointed out that Gonzales and his fellow hackers succeeded because much of the data (90+ million credit card transactions) was unprotected and unencrypted.
The concept of protecting secrets is addressed in the Open Web Application Security Project (OWASP’s) #6 most critical risks for web applications, sensitivity data exposure. While these three simple words could be applied in many areas, we will be looking at proper password hashing, encryption of information at rest and securing communication in transit via HTTPS. These topics have one thing in common, keeping one’s secrets a secret.
Hashing vs. Encryption
Most developers understand that encryption is the process of transforming sensitive data to make it unreadable with the use of a key, resulting in what we call a ciphertext. It can be reversed. This means that the ciphertext can be decrypted using the same ingredients –the correct key, encryption algorithm (cipher) and ciphertext– to get back to the original data.
Hashing, on the other hand, is the term we have also applied to the process of transforming data into an unreadable value called a hash value (also known as digest, message digest or just hash). However, hashing is unlike encryption in important ways:
- It is a 1-way process. You can’t go from the hash value back to the original input
- You don’t need a shared key to generate a hash digest (as with encryption to allow a recipient to decrypt encrypted data).
- A hash value is deterministic, that is, the same input of data will always compute to the same hash value
Hash digest example:
A3EKhEs+xYnYLx5GriGT7/oy80n/lUMwUhTZyshcJxZ5DIBnZiP97GFG6vxVAGv34C4AAA==
User passwords basically identify valid users of a system. Given the disadvantages of traditional encrypted passwords, Roger Needham saw an opportunity and pioneered the use of one-way hash values in place of storing plaintext or encrypted passwords back in 1966.
Since a specific input generates the same hash value every time, you can validate system users by storing a cryptographic hash value of a password instead of retaining a user’s password (even if encrypted) in the system. We’ll talk more on encryption when we get to encrypting sensitive data and discussing insecure transport layer with HTTP.
Storing User Credentials
You might think that everyone knows it’s a huge no-no to store a user’s password in plain text, but you would be wrong. A user’s password is sensitive data that requires proper procedures to protect (e.g. don’t store in plain text). Whatever those proper procedures are, you can view them as a last line of defense. An attacker who has acquired access to the information has most likely exploited some other vulnerability in our system and circumvented other defense measures. Therefore, unprotected passwords provide a means to further exploit a compromised system. They also put at risk other systems that the user accesses with the same password (but no one repeats the same password right?).
Let me just state that no password is safe. Whatever measure you take to protect a user’s password, it will not be bulletproof. Period. What you are going to do is attempt to make it unfeasible and not worth an attacker’s time.
We have already determined that a cryptographic hash is potentially a good shield for sensitive data such as a user’s password. However, as is, hash functions are not perfect. With the same hash function and ingredients, a hash value will always be the same. For example, take thePassword1 and run it through a SHA-256 hash function to generate a 32 bit hash value:
19513fdc9da4fb72a4a05eb66917548d3c90ff94d5419e1f2363eea89dfee1dd
It doesn’t matter how many times we were to hash the value Password1, it would generate the same hash value. This poses a serious dilemma. If our data was compromised, and an attacker was to attempt to crack our list of users passwords, they would only require finding a value that would compute to the same hash value that was stored and they would know the original password. Therefore, if an attacker could have a pre-computed list of hashes (up to a given password length) and simply compare each password hash stored against that list, they could easily crack any password hash. Indeed, this already exists, rainbow tables.
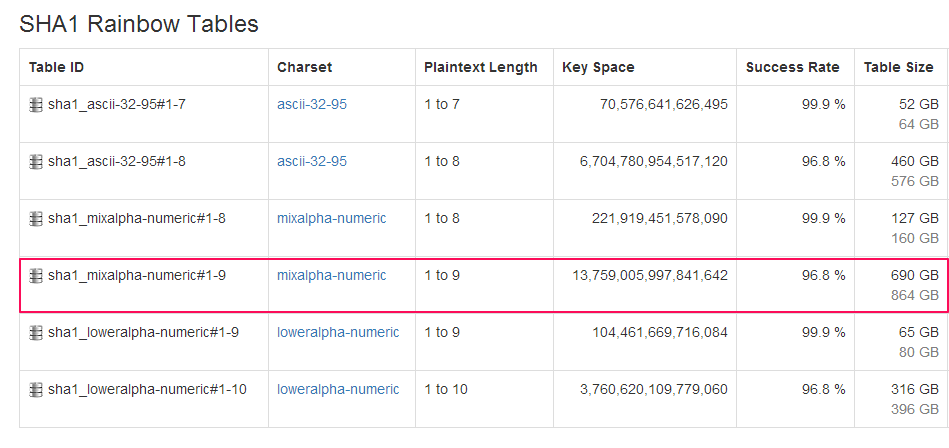
Rainbow tables provide pre-generated hashes that can be compared to (for instance) a hashed password. Rainbow tables delivers a cost/time tradeoff (assuming someone else has already spent time and money to generate the hashes); For the rainbow table user, it’s only a matter of comparing the hashes to find matches. But it’s not quite as rosy as it sounds. Rainbow tables come with their own cost, mainly that of storage. To get an understanding of those costs, here are some stats:
Yes, you are reading that correctly. To simply cover lower and uppercase letters and digits would require 864 GB of space for 100% success rate (no special characters). But all’s not lost, there is an antidote.
Spice it up
So why would we consider using a cryptographic hash function to hash user passwords if an attacker can pre-compute values to compare until a match is found and crack the underline password? Because we can add a bit of spice to our users’ passwords before we run them through a hashing algorithm in the form of randomness in order to generate a unique hash. We do this by adding what is technically referred to as the salt.
A salt is some unique value that can be added to the original password to ensure the hashed value is unique. A salt is only as good as its uniqueness. The higher the value of randomness, the higher chances a salt will be unique. By adding a unique salt value to our password, the output hash value will always be a unique hash value, even when different users use the same password.
But here is the key; the hash is only as good as the uniqueness of the salt. If a salt is reused, you have defeated the entire purpose of the salt, which is to provide uniqueness to the produced hash value.
So what does that mean for something like rainbow tables? It means the end. The storage necessities for the required rainbow tables make it obsolete. However, that doesn’t mean we are safe. The inexpensive computer computational power that can be obtained from sources such as cloud providers or parallelism afforded by GPU allows anyone the capabilities to do far more. Coda Hale illustrates:
Rainbow tables, despite their recent popularity as a subject of blog posts, have not aged gracefully. CUDA/OpenCL implementations of password crackers can leverage the massive amount of parallelism available in GPUs, peaking at billions of candidate passwords a second. You can literally test all lowercase, alphabetic passwords which are ≤7 characters in less than 2 seconds. And you can now rent the hardware which makes this possible to the tune of less than $3/hour. For about $300/hour, you could crack around 500,000,000,000 candidate passwords a second.
Yes, you read right, that’s B as in billions per second. What kind of counter measures can we implement if someone can simply acquire the necessary and affordable hardware for generating billions of hashes on the fly for comparison? One word: Time.
Time is on our side
So far we have seen that the attackers hold all the chips. They can acquire the hardware at an affordable cost to overcome the limitations of rainbow tables and brute-force attack our properly salted hashed passwords. That is where password-based key derivation functions come into play.
In addition to salting and hashing a password, password-based key derivation functions such asbcrypt, scrypt and PBKDF2 also add one more ingredient to proper hashing of passwords and that is time. They do this through a method called key stretching (which is slightly different than key strengthening). I’ve already demonstrated a implementation of the PBKDF2 in .NET before if you’re looking for a full implementation.
Key stretching deliberately slows down the hashing process by forcing the data (in this case password) through numerous iterations of the hashing process. Therefore, if an attacker wants to generate a matching hash, they must also put the password guess through the same number of rounds of hashing in order to obtain a match. If it takes 1 millisecond to generate a hash, at 1000 rounds of hashing, it would now require 1 second to generate the hash produced by the key derivation function.
Pulling it all together
I would be irresponsible to suggest that we should consider rolling out our own authentication framework and implementing a password-based key derivation function in our web application. How many times have you heard it repeated – web security is tough, proper cryptography of sensitive data is even harder. So, rolling your own authentication system is being anignoramus. Instead, we need to rely on highly tested frameworks/libraries that have made their way through extensive testing and use. Therefore, let’s take the ASP.NET team’s implementation in an ASP.NET MVC application created using the Visual Studio MVC template.
For example creating an ASP.NET MVC application and selecting an Authentication scheme will roll out the latest ASP.NET Identity 2.0 system:
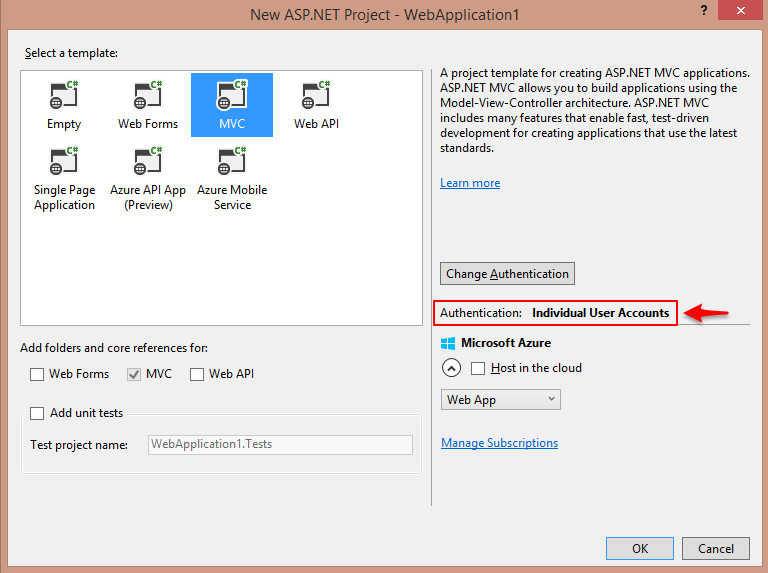
The ASP.NET Identity 2.0 security library is version 2 of their replacement to the original membership system from back in .NET 2.0. You can read more about getting started with Identity 2.0 system here. Despite the fact that this is not a post on authentication systems, the ASP.NET MVC template gives you d all the plumbing to allow users to register accounts and authenticate:
A lot has changed, but in the new authentication system, passwords are handled as we outlined above utilizing the password-based key derivation function (PBKDF2) in the Rfc2898DeriveBytes class. Here we can see in the Crypto class Identity 2.0’s implementation of hashing a new user’s password:
A lot has changed, but in the new authentication system, passwords are handled as we outlined above utilizing password-based key derivation function we outlined (PBKDF2) in the Rfc2898DeriveBytes class. Here we can see in the Crypto class Identity 2.0’s implementation of hashing a new users password:
namespace Microsoft.AspNet.Identity
{
Internal static class Crypto
{
private const int PBKDF2IterCount = 1000; // default for Rfc2898DeriveBytes
private const int PBKDF2SubkeyLength = 256/8; // 256 bits
private const int SaltSize = 128/8; // 128 bits
/* =======================
* HASHED PASSWORD FORMATS
* =======================
*
* Version 0:
* PBKDF2 with HMAC-SHA1, 128-bit salt, 256-bit subkey, 1000 iterations.
* (See also: SDL crypto guidelines v5.1, Part III)
* Format: { 0x00, salt, subkey }
*/
public static string HashPassword(string password)
{
if (password == null)
{
throw new ArgumentNullException("password");
}
// Produce a version 0 (see comment above) text hash.
byte[] salt;
byte[] subkey;
using (var deriveBytes = new Rfc2898DeriveBytes(password, SaltSize, PBKDF2IterCount))
{
salt = deriveBytes.Salt;
subkey = deriveBytes.GetBytes(PBKDF2SubkeyLength);
}
var outputBytes = new byte[1 + SaltSize + PBKDF2SubkeyLength];
Buffer.BlockCopy(salt, 0, outputBytes, 1, SaltSize);
Buffer.BlockCopy(subkey, 0, outputBytes, 1 + SaltSize, PBKDF2SubkeyLength);
return Convert.ToBase64String(outputBytes);
}
As outlined in the code comments, PBKDF2 uses the SHA-1 hashing algorithm, with 1000 rounds of hashing. The .NET class provides a Salt property which provides the unique salt to be applied to the password. Finally, they are storing the password hash with the salt which will allow applying the same salt and number of iterations against any password guess to validate a correctly provided password.
The Identity 2.0 system generates a lot smaller footprint of user account based database tables:
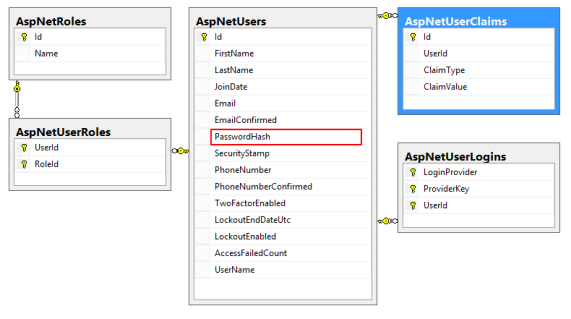
Below we can see that the final outcome when a user’s password has been hashed through the above Crypto.cs class in Identity 2.0 is the outcome record generated by the ApplicationUserManager.

You saw that too?
Now, you might have observed if you read the PBKDF2 documentation, that when it was derived in 2000 the recommended number of iterations was 1000. If you apply Moore’s Law, you would probably conclude like many that hardware has significantly increased 8+ fold since the original draft. Unfortunately, we’re still deploying the original 1000 iteration count without any capability of overriding this value (at least for a higher number of rounds).
There are other authentication frameworks that use other password-based key derivation functions such as bcrypt and scrypt which implement the blowfish cipher and in some cases allow the rounds of hashing to be specified. But whatever framework you use, make sure that it is well tested and the tires have been more than kicked.
So we’re good right?
So, we’re leveraging a well-oiled framework, painfully and purposely slow authentication system such as ASP.NET Identity 2.0, our passwords are secure now, right? Not quite (cue parade rain!). Why? Because there is one more element to this whole circus of password storage – that’s the passwords themselves. Whatcha talkin bout Willis?
The simple fact is that the strength of the password makes a significant impact on the capabilities of an attacker. Stealing directly from Jeff Atwood’s great demonstration, see for yourself:
- Grab a random password such as ML9Y6#pM
- Slap it into the GRC password crack checker
- Check the “Massive Cracking Array” only to see it only would take 1.12 minutes
Yes, that’s correct, slightly more than 1 minute to crack an 8 character, uppercase, lowercase, numbers including special characters. The interesting part is that if it is increased to 10 characters it jumps to 1 week. If you bounce that up to 12 characters (that’s twelve as in just 2 more than 10) it jumps up to 1.74 centuries.
The topic of good passwords can be a post itself and has been numerous times, but when we see easily obtainable GPU cluster rigs which spit out the password guess in the millions and billions per second and cloud computing capabilities I referenced earlier, we need to force better password requirements.
To belabor this even more, which of the two do you think would be stronger?
- One ring to rule them all!
- _B3n!dle#1
I won’t even bother to ask you which would be easier to remember. But, needless to say, the second one would only take ~2 hrs, while the first one is unfeasible.
Conclusion
Password storage is tricky business. Its starts with the design of your application, determining the password strength restrictions you are willing to force your users to abide by. Then ensure that you’re using a framework that is well tested, updated and maintained that incorporates a well known, purposely slow hashing algorithm (preferably allowing the adjustment of the work load).
In part 2 of OWASP’s #6 Sensitive Data Exposure: we’ll look at encrypting data at rest and in transit.
Food for thought
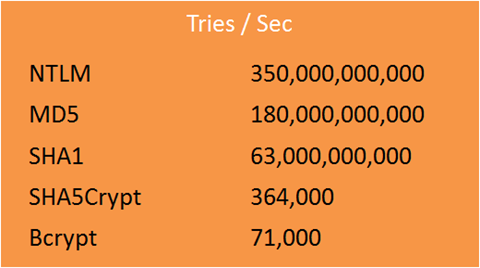
Here are some numbers to chew on that were pulled together by Jeremi Gosney’s 25 GPU cluster rig, built some time ago:
OWASP #6 Preventing Sensitive Data Exposure - Part 1 first appeared on LockMeDown.com.

Ever wonder what a narrative story telling meets technology podcast would sound like? Well, look no further, the Lock Me Down podcast is unlike any other technology podcast you have heard. Mysterious, intriguing and captivating stories? Check. Informative and instructional web security information for developers? Check. Crazy company security snafus? Yep.