
A Generic and Advanced PDF Data List Reporting Tool
5.00/5 (10 votes)
Creating PDF reports for grouped or non-grouped data lists in C# with many custom options and configurations (providing source code with .NET Framework 4.6.1 and .NET Core 3.1)
Introduction
Many business applications need to export the data lists to PDF files. Since the PDF components are physically rendered on document pages, the best practice of obtaining a data list in PDF format is to directly generate a PDF data list report with the help of a PDF rendering tool. Uzi Granot shared his excellent and lightweight base PDF rendering class library, PdfFileWriter, with the developer communities. Using this library with a little tweak for the internal code (also with updates for the .NET Core), I have built the PdfDataReport tool to create PDF reports from C# data lists with and without record grouping. It’s generic in that creating any new or updating any existing report needs just adding or updating XML nodes in the report descriptor that matches the model class for the data source, and then calling the method with arguments of the data list and report descriptor. All major features of the tool will be demonstrated on the sample application and also discussed in this article.
Building and Running Sample Projects
The downloaded source for the .NET Core 3.1, PdfDataReport.NetCore, can only be opened with the Visual Studio 2019 version 16.4 or above. The sample application for .NET Framework 4.6.1, PdfDataReport.Net4, can be opened in the Visual Studio 2017 (with .NET Framework 4.6.1 installed) or 2019. The solution consists of four projects.

-
PdfDataReport: PDF data list report processor. It’s the main focus of this article and code discussions. -
PdfDataReport.Test: simple WPF program simulating thePdfDataReporttool consumer for testing the data report generations. -
PdfDataReport.Test.Model: containing data model classes for the sample application. ThePdfDataReporttool itself doesn’t directly use any data model class. The base type of the data list,List<T>, is passed dynamically. -
PdfFileWriter: the PDF renderer class library (version 1.26.0). I have made some modifications in the PdfDocument.cs, PdfTable.cs, PdfTableCell.cs, and TextBox.cs class files for the PDF data list needs. The code changes inside thePdfFileWriterlibrary are not the focus of this article. Audiences can search “SW:” labeled lines in these files for details if interested.
You should rebuild the solution without any dependency problem if the Visual Studio and the framework libraries are those required on your local machine. Make sure that the PdfDataReport.Test is the startup project and the default PDF display application exists on your machine (usually the Adobe Reader). For the sample application with the .NET Core 3.1, you may need to specify the PDF reader executable file path in the PdfReaderExe value of the app.config file if you don't use the default Adobe Reader DC installation (see details in the last section, .NET Core 3.1 Related Changes).
You can then press F5 to run the application in the debugging mode to show the demo page.

Each link on the demo page will call this method in the PdfDataReport.ReportBuilder class to build the PDF byte array with which the PDF data report file is derived.
Byte[] pdfBytes = builder.GetPdfBytes(List<T> dataList, string xmlDescriptor);
The first argument is a Generic List object as the data source. The PdfDataReport.Test project contains a test data source class file, TestData.cs, for generating a desired number of data records for demonstrations. The data list needs to be ordered by an object property (a.k.a., data field) if the list is grouped by the property. The second argument is an XML string for report schema definitions (called as descriptor throughout the article - see the next section for details).
Try to click the first link, Product Orders Grouped by Order Status, on the demo page. The PDF generation process starts to run for the Product Order Activity report and the resulted PDF page is shown:

Descriptors
The XML descriptor document defines the report structures, components, and data field properties. It’s the critical part to make the report tool generic. The XML document file can be placed anywhere the PdfDataReport process can access. A report node can be added into the document for generating the report from a particular data source. Below is a typical report node chunk for the Product Order Activity report in the sample descriptor report_desc_sm.xml file.
<report id="SMStore302" model="ProductOrders">
<view>
<general>
<title>Product Order Activity</title>
<subtitle></subtitle>
<group>OrderStatus</group>
<grouptitle>Order Status: {propertyvalue}</grouptitle>
</general>
<columns>
<col name="OrderId" display="Order Number" datatype="integer"/>
<col name="OrderDate" display="Order Date" datatype="datetime" />
<col name="OrderStatus" display="Order Status" group="true" datatype="string" />
<col name="CustomerId" datatype="integer" visible="false" />
<col name="CustomerName" display="Customer" datatype="string" nowrap="true" />
<col name="NumberOfItems" display="Number of Items"
datatype="integer" total="true" alignment="right" />
<col name="OrderAmount" display="Amount ($)" datatype="currency" total="true" />
<col name="ShippedDate" display="Shipped Date"
datatype="datetime" default-value="-" />
</columns>
</view>
</report>
In the above structure, there are two section nodes, general and columns, under the view node. The general node contains descriptor items for the report titles and data group info. Under the columns node, each col node defines attributes and values for what the column should be in the report display. During the starting phase of the report generation process, descriptor items and values will be transferred into these programming data caches:
- Local variables for individual elements from the
generalnode - The L
ist<ColumnInfo> colInfoListfor non-grouped columns - The
groupColumnInfoobject for the group-by column
The ReportBuiler.GetColumnInfo method is called to parse the XML nodes to populate the List<ColumnInfo> colInfoList and the groupColumnInfo object:
private List<ColumnInfo> GetColumnInfo(XmlDocument xmlDoc, ref ColumnInfo groupColumnInfo)
{
var nodeList = xmlDoc.SelectNodes("/report/view/columns/col");
var colInfoList = new List<ColumnInfo>();
ColumnInfo colInfo = default(ColumnInfo);
var idx = 0;
//Check if the list contains only one grouped column.
//Multiple grouped-column list will be treated as non-grouped data.
var isOneGroup = false;
foreach (XmlNode node in nodeList)
{
if (Util.GetNodeValue(node, "@group", "false") == "true")
{
if (isOneGroup)
{
isOneGroup = false;
break;
}
else
{
isOneGroup = true;
}
}
}
foreach (XmlNode node in nodeList)
{
//Invisible is auto excluded.
var isVisible = bool.Parse(Util.GetNodeValue(node, "@visible", "false"));
//Include needed columns.
if (isVisible)
{
colInfo = new ColumnInfo();
var colNameNode = node.Attributes["name"];
if (colNameNode == null)
{
throw new Exception("Column (" + idx.ToString() + ")
name from XML is missing.");
}
else
{
colInfo.ColumnName = colNameNode.InnerText;
}
colInfo.DisplayName = Util.GetNodeValue(node, "@display");
colInfo.DataType = Util.GetNodeValue(node, "@datatype", "string");
colInfo.IsGrouped = bool.Parse(Util.GetNodeValue(node, "@group", "false")) ||
colInfo.ColumnName.ToLower() == groupByColumn;
colInfo.IsTotaled = bool.Parse(Util.GetNodeValue(node, "@total", "false"));
colInfo.IsAveraged = bool.Parse(Util.GetNodeValue(node, "@average", "false"));
colInfo. DefaultValue = Util.GetNodeValue(node, "@default-value");
var align = node.Attributes["alignment"];
if (align == null)
{
//Default alignments based on type.
switch (colInfo.DataType.ToLower())
{
case "string":
colInfo.Alignment = "left";
break;
case "currency":
colInfo.Alignment = "right";
break;
case "percent":
colInfo.Alignment = "right";
break;
case "integer":
colInfo.Alignment = "right";
break;
case "datetime":
colInfo.Alignment = "center";
break;
default:
colInfo.Alignment = "left";
break;
}
}
else
{
colInfo.Alignment = align.InnerText.ToLower();
}
if (isOneGroup && colInfo.IsGrouped)
{
//If it's one group list.
groupColumnInfo = colInfo;
}
else
{
//Non-grouped data list or the list having more than one group column.
colInfoList.Add(colInfo);
}
}
idx++;
}
return colInfoList;
}
The XML node parser also sets a default value for any retrieved XML attribute of a col node except for the name. Thus, only the name attribute with the string data type in the descriptor is theoretically required when adding any new col node into the descriptor file. In addition, the col node has the default-value attribute with which we can specify any desired value to be displayed in the column if the delivered data value is 0 (for numeric types), null, or empty.
Setting Column Width
All data column width values need to be explicitly defined for the PDF table creation. The PdfDataReport tool supports manual or automatic column width settings. Any positive value exits for the fixed-width attribute of the col node in the descriptor will overwrite the default automatic width setting for the column. In this case, any text for which the width is longer than the fixed column width will be wrapped in the column. The below XML line example will set the Customer column to 1.8 inch (the unit of measure is set from the report config file - see the UnitOfMeasure key in the sample App.config file for details):
<col name="CustomerName" display="Customer" datatype="string" fixed-width="1.8" />
Most PDF data lists use the automatic column widths as shown in the Product Order Activity report. Setting automatic column widths needs to firstly calculate the total data character width of the column body and take the maximum value for all data rows in the column. In each loop of processing a data record, the code to detect the maximum width of the column body is like this:
currentTextWidth = bodyFont.TextWidth(BODY_FONT_SIZE, dataString.Trim());
if (textWidthForTotalCol > currentTextWidth)
currentTextWidth = textWidthForTotalCol;
if (currentTextWidth > textWidth)
textWidth = currentTextWidth;
The process then calculates the width of the longest word in the column header display and picks the larger number from those for the maximum total body character width and the longest header display word width:
var wordWidth = 0d;
var headerFontSizeForCalculation = HEADER_FONT_BOLD ?
HEADER_FONT_SIZE * BOLD_SIZE_FACTOR : HEADER_FONT_SIZE;
List<string> dspWords = colInfoList[idx].DisplayName.Split(' ').ToList();
foreach (var dspWord in dspWords)
{
//Check for some symbol column such as checkbox or star.
currentTextWidth = headerFont.TextWidth(headerFontSizeForCalculation,
dspWord == "" ? "*" : dspWord);
if (currentTextWidth > wordWidth)
wordWidth = currentTextWidth;
}
if (wordWidth > textWidth)
{
textWidth = wordWidth;
}
The calculated width data of all columns is cached in the List<double> columnWidths that will be converted to an array for calling the PdfFileWriter.rptTable.SetColumnWidth method.
rptTable.SetColumnWidth(columnWidths.ToArray());
Automatic Paper Size Selection
A printable PDF document is bound to a particular size or type of paper. For a data list report, the width of the page depends upon the total column width. The PdfDataReport tool can automatically select the paper size or orientation through calculations of the page content width (total column width plus left/right margins) based on these facts and rules:
-
Pre-defined paper size list needs to be provided from the
PaperSizeListkey in the configuration file. The sample application sets the paper sizes of 8.5x11, 8.5x14, 11x17, and 12x18 in inches by default. Most of these are commonly used paper sizes in the US. -
The portrait orientation of the first paper size (8.5x11 as in the sample application) will be picked up if the page content width doesn’t exceed the paper portrait width. Else, it will use the landscape orientation of the first paper size.
-
If the first paper landscape size doesn’t fit, all next selections will be the landscape orientation with increased paper size, for example, the landscaping 8.5x14, 11x17, and so on.
-
If the page content width exceeds the maximum width of the landscaping paper sizes pre-defined in the configuration list, the calculated real page width and the paper height of the last pre-defined page size will be set for the report display.
The code lines below show the implementation details:
//Automatic paper size and orientation selections.
var pageSizeOptionArray = PAGE_SIZE_OPTIONS.Split(',');
var pageSizeOptionList0 = new List<SizeD>();
foreach (var elem in pageSizeOptionArray)
{
var elemArray = elem.Split('x');
var item = new SizeD()
{
//Set landscape orientations in data array by default.
Height = double.Parse(elemArray[0].Trim()),
Width = double.Parse(elemArray[1].Trim())
};
pageSizeOptionList0.Add(item);
}
//Sort it in case input list is not in sequence of small to large size width.
var pageSizeOptionList = pageSizeOptionList0.OrderBy(o => o.Width).ToList();
//Now add portrait orientation for the first item.
pageSizeOptionList.Insert(0, new SizeD()
{
Width = pageSizeOptionList[0].Height,
Height = pageSizeOptionList[0].Width
});
//Pick up minimum page size based on maximum total column width plus margins
//and then update page size.
var leftMargin = MAXIMUM_LEFT_MARGIN;
var rightMargin = MAXIMUM_RIGHT_MARGIN;
var sizeMatched = false;
var totalColummWidth = columnWidths.Sum();
foreach (var item in pageSizeOptionList)
{
//Left and right margins are dynamically set between minimum and maximum values.
var spaceForMargins = item.Width - totalColummWidth;
if (spaceForMargins > MINIMUM_WIDTH_MARGIN * 2)
{
document.PageSize.Width = item.Width * document.ScaleFactor;
document.PageSize.Height = item.Height * document.ScaleFactor;
sizeMatched = true;
//If space smaller than max config values,
//set remaining space proportionally for left/right margins.
if (spaceForMargins < (leftMargin + rightMargin))
{
leftMargin = spaceForMargins * leftMargin/(leftMargin + rightMargin);
rightMargin = spaceForMargins - leftMargin;
}
break;
}
}
if (!sizeMatched)
{
leftMargin = MINIMUM_WIDTH_MARGIN;
rightMargin = leftMargin;
document.PageSize.Width = (totalColummWidth + leftMargin + rightMargin) *
document.ScaleFactor;
//Use height of the last pre-defined page size.
document.PageSize.Height = pageSizeOptionList[(pageSizeOptionList.Count - 1)].Height;
}
When clicking the link Automatic Select Paper Size or Orientation on the demo page of the sample application, the page shows in the landscape letter size (11x8.5) since the page content width is larger than the paper size in the portrait orientation (8.5x11).

Column Alignment
With the default PdfFileWriter.PdfTable settings, columns on the page are rendered in justified alignment style, i.e., aligned to both left and right margins with extra spaces distributed inside columns. This is achieved by fractionally adjusting each column width and making the total column width equal to the table width. The PdfDataReport tool can also use the left-align style in which page contents are aligned only to the left margin and the remaining empty space is extended towards the right margin. All previous PDF page screenshots have shown the left-align style which is implemented by adding a dummy column that occupies all remaining empty spaces.
//If not uisng justify page-wide layout, all remaining space needs to be a dummy column.
if (!JUSTIFY_PAGEWIDE)
{
var dummyColWidth = rptTable.TableArea.Right - columnWidths.Sum();
columnWidths.Add(dummyColWidth);
colInfoList.Add(new ColumnInfo() { ColumnName = "Dummy", ActualWidth = dummyColWidth });
}
The JUSTIFY_PAGEWIDE flag value can be set in the report configuration file. For reports created using the PdfDataReport tool, columns are left-aligned by default when the flag or its value doesn’t exist. Setting the flag to true will justify the columns to the page content width. The justified layout is demonstrated on the Test Automatic Page Selection report when clicking the Justify Display Columns to Page-Wide link on the sample application demo page.

Grouped Data Display and Page Breaks
The PdfDataReport tool can display grouped data rows and aggregated data items as shown on the first screenshot for the Product Order Activity report. To keep the report content clear and easy to read, the tool only supports grouping a data list by one field. This should meet most of the business data report needs.
To correctly display grouped data records on the PDF data report display, some design considerations and implementing approaches are important as illustrated below:
-
The C# List data source must already be sorted for the group-by field/property before it is attached to the
List<T> dataListargument of thebuilder.GetPdfBytesmethod. ThePdfDataReporttool can then process the header, body, and footer rows for individual groups.object prevValue = default(object); object currValue = default(object); foreach (var item in dataList) { currValue = item.GetType().GetProperty (groupColumnInfo.ColumnName).GetValue(item, null); //Start new group. if (!currValue.Equals(prevValue)) { //Footer row for last processed group (except first time). if (prevValue != null) { //Draw footer row for previous group here... } //Draw header row for current group here... prevValue = currValue; } //Draw body rows for current group here... } -
Adding the group-by column itself will be skipped in the processing loop since the column is excluded from the
colInfoListwhen it’s populated based on the XML descriptor. As a result, no group-by column is displayed. Instead, the group-by column data value with possible custom static text will be shown on the group header. Thegeneral/group-titlenode in the XML descriptor defines the custom static text and data placeholder. If thegroup-titlenode and its value exist, the value will overwrite the default text and format.//Set overwriting group title. groupTitle = Util.GetNodeValue(objXMLDescriptor, "/report/view/general/group-title"); . . . //Header row for current group. rptTable.Cell[0].Value = groupColumnInfo.DisplayName + " = " + currValue.ToString(); if (!string.IsNullOrEmpty(groupTitle)) { rptTable.Cell[0].Value = groupTitle.Replace("{propertyvalue}", currValue.ToString()); }; -
Any Total or Average value, if specified in the XML descriptor, and the number of total records for the group need to be shown on the group footer. The detailed code logic is in the
ReportBuilder.DrawGroupFootermethod, but here is the example of how to draw the group footer row that includes the totalled column.//Group total row if (hasTotal) { //This label at least occupies width space of first two columns //that shouldn't be totalled columns. rptTable.Cell[0].Value = " Group Total"; foreach (var colTotalIndex in colTotalIndexList) { rptTable.Cell[colTotalIndex].Value = colInfoList[colTotalIndex].GroupTotal; } rptTable.DrawRow(); } -
When there is any totalled or averaged column in the list data source, it should leave enough width space for the Group Total or Group Average label before the starting position of the first totalled or averaged column. Usually, any totalled or averaged column should be placed after first two or three columns to guarantee the correct display of the totalled or averaged number value.

-
Automatic page breaks need to occur smoothly between groups and after the last data row of the report. To pursue common rules for a well formatted data list document, particularly for the physically rendered PDF data list documents, the
PdfDataReporttool never breaks such document pages when no data row is left for the next page. In other words, the next page should begin with at least one data row for the particular group or entire report. This rule avoids showing only the header and footer on a page.The code logic to implement this rule is a little complex. But basically, the tool calculates the remaining space when processing the last row in the data group. If the space is not enough for the data row plus the group footer rows, the page will immediately break, moving the last data rows to the next page. For the last row of the entire data list, the calculated space allowance includes the report footer rows. The main parts of the code are in the
DrawGroupBreakmethod. See the comments for how code lines operate on the page breaks and also add the continue-page message display at the break point.private bool DrawGroupBreak(PdfTable rptTable, bool lastGroupItem = false, bool lastDataItem = false) { //Exclude condition where there is only entire row on page. if (rptTable.RowTopPosition == rptTable.TableArea.Top - rptTable.Borders.TopBorder.HalfWidth) return false; var room = 0d; var bottomLimit = rptTable.TableArea.Bottom + rptTable.Borders.BottomBorder.HalfWidth; //If remaining space is not enough for // 2 rows: for mid-group-row. // 3 rows: for last-group-row (with total/average). // 4 rows: for last-group-row (with total and average). // 6 rows: for last-group/report-row and report footer (with total only). if (lastGroupItem) { if (lastDataItem) { room = rptTable.RowTopPosition - rptTable.RowHeight * 6; } else { //For last-group-row scenario. if (hasTotal && hasAverage) room = rptTable.RowTopPosition - rptTable.RowHeight * 4; else if (hasTotal || hasAverage) room = rptTable.RowTopPosition - rptTable.RowHeight * 3; } } else { //For mid-group-row scenario. room = rptTable.RowTopPosition - rptTable.RowHeight * 2; } if (room < bottomLimit) { //Draw line. var pY = rptTable.RowTopPosition; // rptTable.BorderYPos // [rptTable.BorderYPos.Count - 1]; rptTable.Contents.DrawLine(rptTable.BorderLeftPos, pY, rptTable.BorderRightPos, pY, rptTable.Borders.CellHorBorder); //Draw message. var temp = ""; if (lastGroupItem) temp = "(A group record continues on next page...)"; else temp = "(Group records continue on next page...)"; //Backup style. var cellStyle = new PdfTableStyle(); cellStyle.Copy(rptTable.Cell[0].Style); //Set value and styles, and then draw continue row. rptTable.Cell[0].Value = temp; rptTable.Cell[0].Style.Font = bodyFontItalic; rptTable.Cell[0].Style.Alignment = ContentAlignment.BottomLeft; rptTable.DrawRow(); //Set style back rptTable.Cell[0].Style.Copy(cellStyle); return true; } return false; }
When clicking the link Product Orders Grouped by Order Status with End-group Page Break on the Demo page of the sample application, the Product Order Activity report will be shown with pages that break before the last row in a group.
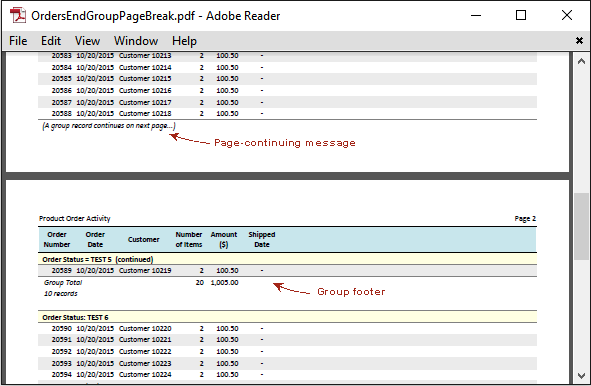
Clicking the next link, Product Orders Grouped by Order Status with End-report Page Break, on the Demo page will show the example of page break before the last row of the entire data list. In this case, there are the last data row, group footer rows, and report footer rows on the last PDF page.

Setting Background and Border Line Colors
The PdfDataReport tool provides limited pre-defined but most probably used background and border color selections for the column header, group headers, alternative rows, column header and footer lines, and group header and footer lines. The report generation process will always use the default settings if any configuration item or its value for these color settings doesn’t exist. You can easily change these color settings from the report configuration file. You can even add any new color setting into the tool for your needs with these steps:
-
By searching the
selColorvariable in thePdfDataReport.ReportBuilderclass, you can find the places for coding the existing color selection items. For example, the code for the group header background colors is like this://Group header background color. Color selColor; switch (GROUP_HEADER_BK_COLOR) { case "FaintLightYellow": selColor = Color.FromArgb(255, 255, 238); break; case "VeryLightYellow": selColor = Color.FromArgb(255, 255, 226); break; case "LightYellow": selColor = Color.FromArgb(255, 255, 214); break; case "FaintLightGray": selColor = Color.FromArgb(230, 230, 230); break; case "VeryLightGray": selColor = Color.FromArgb(220, 220, 220); break; case "LightGray": selColor = Color.FromArgb(207, 210, 210); break; default: //VeryLightYellow selColor = Color.FromArgb(255, 255, 226); break; } DrawBackgroundColor(rptTable, selColor, rptTable.BorderLeftPos, cell.ClientBottom, rptTable.BorderRightPos - rptTable.BorderLeftPos, rptTable.RowHeight); -
Add your own color item as a new
caseinto theswitchblock. -
Find the corresponding key in the
appSettingssection in your configuration file. For example, the key for the group header background colors is like this:<!--Available GroupHeaderBackgroudColor settings: "FaintLightYellow", "VeryLightYellow" (default), "LightYellow", "FaintLightGray", "VeryLightGray", "LightGray"--> <add key="GroupHeaderBackgroudColor" value=""/> -
Update the value with the
stringrepresentation of your new color setting.
Using PdfDataReport Tool in Your Own Projects
To incorporate the Visual Studio PdfDataReport project into your development environment, follow these steps:
-
Copy the physical folders of PdfDataReport and PdfFileWriter projects to your solution root folder. Then open your solution in Visual Studio and add those two projects as existing ones into your solution.
-
Set the reference to the
PdfDataReportproject from your executing project/assembly that calls the PDF report generation processes. -
Create your PDF report descriptor file that consists of definitions for resulted data list reports. Place the file to the location that your executing project/assembly can access. You may make the descriptor file path configurable using your executing project/assembly configuration file.
-
Add or update any key and value, if you would not like to use the defaults, for report format and style settings in your executing project/assembly configuration file. Refer to the App.config file in the
PdfDataReport.Testproject for details. -
In your executing project/assembly, call the
ReportBuilder.GetPdfBytesmethod with thedataListandxmlDescriptorarguments. You can then use the returned PDF byte array for creating a PDF file or directly pass it in the HTTP response to web clients for automatically opening the PDF report on browsers.
.NET Core 3.1 Related Changes
It becomes possible to port the sample application with the libraries from the .NET Framework 4.x to the .NET Core since the .NET Core 3.0 is available. I tried to upgrade the application to the .NET Core 2.2 with other third-party library tools, but it's not fully working. The .NET Core 3.1 also fixed some issues when using the Windows desktop libraries. There is no code change in the PdfDataReport library project. The upgraded work items are mostly related to the PdfFileWriter library and just a little to the PdfDataReport.Test demo project.
PdfFileWriter Project
Although some options such as Chart, Barcode, Media, etc., are not used by the PdfDataReport tool, I would still like to keep the original PdfFileWrite library intact with all available features to be upgraded to the .NET Core version. I did not test those functionalities that are not used in the sample application, though.
Here are the steps to perform the upgrading tasks:
-
Create the .NET Core 3.1 library project with the Visual Studio 2019 (version 16.4 or above).
-
Copy all class *.cs files from the existing
PdfFileWriterproject to the new .NET Core project. -
Manually update the PdfFileWriter.csproj file so that it looks like this (note the updated or added lines in bold):
<Project Sdk="Microsoft.NET.Sdk.WindowsDesktop"> <PropertyGroup> <TargetFramework>netcoreapp3.1</TargetFramework> <UseWindowsForms>true</UseWindowsForms> <UseWPF>true</UseWPF> </PropertyGroup> </Project> -
Add references of
System.Drawing.Common(v4.7.0) andSystem.Windows.Forms.DataVisualization(v1.0.0-prerelease 19218.1) from the NuGet Package Manager. -
Delete the Bitmap.cs file since the new
System.Drawingnamespace provides the built-inBitmapclass. Otherwise, you would get the conversion error. -
Save, restart, and rebuild the solution.
PdfDataReport.Test Project
The only issue on the .NET Core 3.1 code is the line to call the System.Diagnostics.Process to open the PDF file with the reader program.
The code line works for the .NET Framework 4.6.1 when directly passing the PDF document file name to the ProcessStartInfo object. In the below code, the fileName is the document file name. The code will initialize the default application for the file extension set from the Windows system.
//Start default PDF reader and display the file content.
Process Proc = new Process();
Proc.StartInfo = new ProcessStartInfo(fileName);
Proc.Start();
With the .NET Core, such code lines will render the error "The specified executable is not a valid application for this OS platform". The argument fileName is considered as the executable file name instead of the document file name. It works when assigning the executable and document file names to the properties of the ProcessStartInfo object, respectively. The configurable item is used for the executable file name in the sample application with the default value set to the default location of the Adobe Reader DC installation.
//Start default PDF reader and display the file content.
Process Proc = new Process();
var pdfReaderExe = ConfigurationManager.AppSettings["PdfReaderExe"] ??
@"C:\Program Files (x86)\Adobe\Acrobat Reader DC\Reader\AcroRd32.exe";
Proc.StartInfo = new ProcessStartInfo()
{
FileName = pdfReaderExe,
Arguments = fileName
};
Proc.Start();
You can change the PDF reader tool or use any other version of the Adobe Reader by editing the line in the app.config file.
<add key="PdfReaderExe" value="{your PDF Reader executable path}"/>
History
- 28th January, 2016
- Original post with the .NET Framework 4.0
- 10th February, 2020
- Upgraded sample application to the .NET Core 3.1. The descriptions in some sections are edited or added accordingly.
- The legacy .NET Framework source code files are also updated to the .NET Framework 4.6.1.