Introduction
This code was an experiment and a bit of research, on how to do random access data virtualisation for a Windows Store app, to allow displaying potentially enormous lists of data, from asynchronously accessed sources like web services.
This started out as a learning exercise for myself, to get into a number of concepts at once. I wanted to be able to learn Windows Store app development and the WinRT APIs, and also learn Reactive Extensions (aka Rx).
Note that this does not attempt to address all the details of data virtualisation and fluid UI, such as placeholders and the like.
I am sharing this for two reasons. One is perhaps to offer an avenue towards a solution for anyone who might have a need for it, and the other is to attract some feedback on the topic to help learn further. Any comments on alternative approaches, frameworks, errors, or other ways of doing it are more than welcome!
Download VirtualizingCollection-noexe.zip
Background
I started off with the goal of consuming a movie database web service to display in a navigable list, where the number of movies in the list was uncertain and potentially very high. I wanted to be able to allow the user to have at their fingertips tens of thousands of items or more in the list . The scenario is fairly contrived. Normally users do not want to have such high volumes of data available, but I could imagine situations where the flexibility might be desirable and wanted to explore the technical challenge for learning purposes. I wanted to be able to do this in a Windows Store app, using C# and XAML.
To achieve a smooth, high performance list that is not memory intensive, Microsoft recommendations can be followed, such as these:
https://msdn.microsoft.com/en-us/library/windows/apps/hh994637.aspx
The two key concepts there are:
- UI Virtualisation
- Data Virtualisation
A list of movie descriptions where the data source had tens or hundreds of thousands of records would result in hundreds of thousands of UI elements being generated, consuming memory and other resources, potentially causing an application failure.
UI Virtualisation addresses this by ensuring that only a certain number of UI elements are created in the list, new ones being created as they get scrolled in, and old ones being removes.
To do this in Windows 8.1 XAML seems to be fairly trivial, by ensuring that the ItemsPanel of the ListView is one that supports UI virtualisation (ItemsWrapGrid):
<ListView.ItemsPanel>
<ItemsPanelTemplate>
<ItemsWrapGrid Orientation="Horizontal" />
</ItemsPanelTemplate>
</ListView.ItemsPanel>
The more challenging problem is how to deal with a backend data source that may have one or more of the following attributes:
- Very large number of records
- Only accessible by specifying a page number and page size (a private webservice that does not allow the whole record set to be downloaded at once for example)
- Items/pages load asynchronously
The MS docs above describe two approaches to this, both generally called Data Virtualisation:
- Incremental data virtualisation
- Random access data virtualisation
Incremental data virtualisation is a method where the number of records increases as the user pans towards the end of the list. This is similar to a common technique in web development where scrolling down results in new items being added to the HTML page. In both cases, if there is a scroll bar, the scroll bar changes size as the new items are incrementally loaded.
Random access data virtualisation is where the user can jump to any point in the collection. The user should be quickly able to skip to the end of the list, the middle or anywhere else, and the collection serves up some records demanded by the UI. From the UI's point of view, the collection is a prepopulated list accessed by index, but the collection is only virtual. It 'pretends' to have the records but is actually proxying for some other source.
I chose to use the second option, and Microsoft declare the following about how to do that:
This is where the fun began.
Understanding the code
To me, the concepts behind MS's recommendations look something like the following:
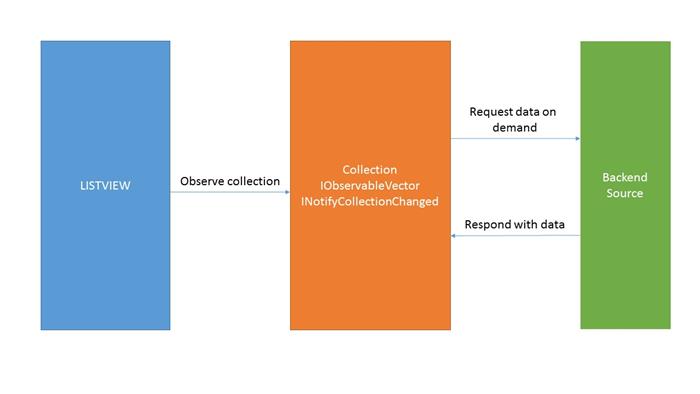
The collection is accessed by index whenever the UI-virtualised ListView requests some elements, and the collection should respond with the data. Should there be a delay or change, the ListView is observing notifications to that effect.
The first thing that was confusing for a newbie like me to this area, was the following point of interest:
ObservableCollection has nothing to do with IObservableVector
IObservableVector is a WinRT type. There is quite a bit of slightly confusing documentation on the web that could lead one to think that somehow ObservableCollection and IObservableVector are related concepts, but as far as I can see they are not. It took me quite a while to realise that web searches that threw up info related to ObservableCollection did not have any use in this case.
Leaving that behind, after considering those concepts and researching the topic, I came to the conclusion that 'the truth' is probably more along the following lines (or at least, I came to prefer this different conceptual arrangement):

To explain why I prefer this way of looking at it, consider the following sequence of steps:
- The ListView, with UI virtualisation, is skipped to show records 1000 to 1020
- The ListView accesses the Collection using [1000]...[1019] indexes
- The Collection does not have that data yet. It calculates that the backend source, which may have a different paging scheme for example, should serve page 25 (for example) with a minimum page size of 50. It returns empty or placeholder items to the ListView
- The Collection issues a request to the Backend Source for the correct data
- The Collection asynchronously receives the data later
- The Collection notifies its observers (the ListView) via VectorChanged event that items 975 to 1025 have been updated
If for example 2 ListViews were observing the same Collection, then there would be a problem. Both ListViews could be accessing different areas of the virtual collection, but both would be notified of each other's asynchronously received data in step 6. Tests I did show that notifications from the IObservableVector can result in the creation of corresponding UI elements. It seems that it is better to have a one to one relationship between Collection and ListView. A second ListView does not need to be informed about data it did not request.
To me, at the time of writing, it seems to make more sense to look at the IObservableVector as an "ObservingVector" that is responding to its ListView through its Indexer. In other words, the Indexer can be considered as a kind of source of events invoked by the ListView, triggering an asynchronous stream of requests and responses flowing via the backend onwards to the ListView through notifications (VectorChanged).
This is when I decided to try and work Reactive Extensions into the mix. At this point all I really knew about Rx was that it was good for working with asynchronous streams. This was an opportunity to learn. For anyone who hasn't checked out Rx, I highly recommend it. The essence of it is as follows:
In .NET we have IEnumerable and IEnumerator. Linq queries can be composed over these to filter sequences of records. From the Rx documentation:
- The
IEnumerable<T> interface exposes a single method GetEnumerator() which returns an IEnumerator<T> to iterate through this collection. The IEnumerator<T> allows us to get the current item (by returning the Current property), and determine whether there are more items to iterate (by calling the MoveNext method).
Rx considers this the "pull model". Your Linq query for example if pulling data out of the IEnumerable(s) using IEnumerators. What Rx does is provide a set of extensions offering a "push model," that allow you to do exactly the same thing over two other interfaces, namely IObserver and IObservable. Again from the Rx docs:
- The push model implemented by Rx is represented by the observable pattern of
IObservable<T>/IObserver<T>. The IObservable<T> interface is a dual of the familiar IEnumerable<T> interface. It abstracts a sequence of data, and keeps a list of IObserver<T> implementations that are interested in the data sequence. The IObservable will notify all the observers automatically of any state changes. To register an interest through a subscription, you use the Subscribe method of IObservable, which takes on an IObserver and returns an IDisposable. This gives you the ability to track and dispose of the subscription. In addition, Rx’s LINQ implementation over observable sequences allows developers to compose complex event processing queries over push-based sequences such as .NET events, APM-based (“IAsyncResult”) computations, Task<T>-based computations, Windows 7 Sensor and Location APIs, SQL StreamInsight temporal event streams, F# first-class events, and asynchronous workflows. For more information on the IObservable<T>/IObserver<T> interfaces, see Exploring The Major Interfaces in Rx. For tutorials on using the different features in Rx, see Using Rx.
This allows a different world-view or programming model to be applied to problems. For example, we could consider the set of all mousemove events as an IObservable, an area of the screen as a set of enumerable points, and by defining a LINQ query that describes the intersection of the two as black dots, you would have a program that responds to mouse events and draws points on a filtered area of the screen. With Rx, and LINQ, this kind of thing just works almost as if by magic.
So, with Rx, and the above sequence of events, I defined my VirtualisingCollection in the following way:
First, there is the concept of a Subject. This is a bit out of scope, so if you are interested in Rx take a look at various discussions and docs on it, but suffice to say that this represents a particular 'topic' that can both be observed and also notified by the program. In the code, I treat the VirtualisingCollection indexer as a Subject. It is something that is 'invoked' by index accesses, and also represents a stream of events:
private Subject<int> indexAccesses=new Subject<int>();
public object this[int index]
{
get
{
indexAccesses.OnNext(index);
int pageIndex = index / pageSize;
int pageOffset = index % pageSize;
if (_pages.ContainsKey(pageIndex))
{
if (_pages[pageIndex] == null)
return default(T);
if (_pages[pageIndex].Items == null)
return default(T);
if (_pages[pageIndex].Items.Count <= pageOffset)
return default(T);
return _pages[pageIndex].Items[pageOffset];
}
else
return default(T);
}
set
{
throw new NotSupportedException();
}
}
The above is showing that a Subject called indexAccesses exists, and that whenever the index is accessed, it is treated as the next item in a sequence of index access events, by raising OnNext. The index accessor is now a kind of event.
We also have a "page provider", which separates the asynchronous data and count load logic out from the collection. In the example code, this looks like this:
public interface IPageProvider
{
Task<IList<T>> RefreshPage(int pageNum,int pageSize);
Task<int> GetCount();
}
The RefreshPage is executed asynchronously, representing steps 4 and 5 in the above sequence.
Using the above code, the required behaviour is embodied in a small Rx Linq query in the constructor:
Func<int, IObservable<IList<T>>> pageRefresh = page => Observable.FromAsync(() => pageProvider.RefreshPage(page,pageSize));
var pageRefreshes = (from access in indexAccesses
where PageIsNew(access)
let pageNumber = (access / pageSize)
from refreshedPage in pageRefresh(pageNumber)
select new Page()
{
Items = refreshedPage,
Touched = DateTime.Now,
PageNumber = (pageNumber)
});
pageAdditionSubscription = pageRefreshes.ObserveOnDispatcher().Subscribe(
page =>
{
UpdatePage(page);
},
ex =>
{
Debug.WriteLine(ex.ToString());
}
);
The indexAccesses is treated as a queryable sequence, filtered for if the requested page does not already exist (where PageIsNew...) , then SelectMany combined with a query over the stream of asynchronous responses from the backend (from refreshedPage in pageRefresh), where pageRefresh is an Observable created from an Async call (Observable.FromAsync()).
The UI dispatcher is used to Observe by subscribing to the query (pageRefreshes.ObserveOnDispatcher().Subscribe.....) , which updates the page by raising VectorChanged events.
Conclusion
There are other aspects to the code, such as cleaning up pages, and changing the count, but that is the core of it.
Basically the indexer is being accessed whenever the UI demands new data and this is treated as a stream of events, represented as an Rx observable, which is combined as an intersection in a Linq query with the stream of asynchronous backend request responses (as an Observable), to invoke an UpdatePage method, which uses the VectorChanged event to tell the UI to redraw.
I do wonder how random access data virtualisation should be tackled. The method above seems contrary to the conceptual model put forward by MS (and the code attached is in no way a finished solution either!) so I would be keen to see how others would tackle the problem.
Points of Interest
During the above I noted the following points of interest:
- There are two types of data virtualisation, incremental and random access
ObservableCollection has nothing to do with IObservableVector- Rx can be used to describe the asynchronous event logic using LINQ
- IObservableVector<T> does not work for data virtualisation. The type supplied to the datasource of the ListView or GridView must be IObservableVector<object>
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.





