Introduction to IntoTheCode, general C# parser library and how to use it. Demonstration of parsing structured data, expressions and a programming language.
Introduction
IntoTheCode is a text parser. It does not read genuine languages, but coding languages or data files. The type of text it can parse is called code. The syntax of the codes is defined in a grammar. The output is a tree of elements, similar to an XML-document. The structure of the output tree is also defined by the grammar.
IntoTheCode does not generate Java or C program files, like many other general parsers (so called “source code generators”). According to Wikipedia, IntoTheCode might be called a “compiler-compiler” because it does compile the grammar and create a new parser for each grammar - though the parser is only dynamic in memory.
Advantages:
- Grammars are very close to documentation style
- No generated source code to maintain
- Output is easily consumed, like XML-documents
Background
The first parser I wrote at university had plenty of recursive calls. When you learn this technique, you get an insight into how computers work and how models can be manipulated. It’s still a great educational and inspiring subject. That’s probably why there are so many parsers and compiler-compilers.
In the 90s, I was working for a company, and I had to parse a complex text file format; I used the principles again. But to make it extensible, I made the parsing functions dynamic, defined by an Extended Backus–Naur Form (EBNF) notation. Yes, if we had used XML, the job would have been so much easier. Anyway, the principles were cool, and I’ve rewritten and upgraded the code since, with object oriented design and output as tree nodes. The BNF notation is almost the same today as in my first job.
Getting Started
A little knowledge of parser techniques is maybe an advantage.
The source code consists of these Visual Studio projects:
- IntoTheCode - The library
- IntoTheCodeDoc - A project for building HTML and MarkDown documentation
- IntoTheCodeExamples - ViewModels and example code
- IntoTheCodeUnitTest - Tests
- TestApp - Application and views for the examples
Using the Code
This is the very basics of how to use IntoTheCode in a C# program. Include the IntoTheCode library to your solution and make a reference to it from your project. Write these lines of code:
string grammar = "";
string input = "";
var parser = new Parser(grammar);
CodeDocument doc = CodeDocument.Load(parser, input);
A program that uses IntoTheCode must first instantiate a Parser with the desired grammar (in a string). The parser can be used multiple times. To parse a string; call the static method CodeDocument.Load with the parser and the string. This will produce a CodeDocument instance containing the output. Unless it fails, and throws an exception. A CodeDocument has nested CodeElements to represent the input.
The Grammars
A grammar defines how input (code) is interpreted and how the output is shaped. The grammars are divided in two parts: A rules part and a settings part.
Rules
The rules part is written in an Extended Backus-Naur Form (EBNF). Rules are intended for both the parser, and for documentation purposes. The rules define how elements can be combined. Many combinations of the rules can be correct (depending of the grammar). When IntoTheCode parses code, the rules are applied. When a rule is applied it can generate an output node if it succeeds in parsing some code. Only the combination of rules that successfully parses all code will generate nodes to the output tree.
The first rule represents the whole input; this will generate the root of the output tree.
Elements
Elements can be names of other rules or the hard coded words. The words are the basic building blocks of a grammar.
This is an example of some rules that make up a grammar:
list = {person};
person = name [age];
name = string;
age = int;
Each line above is a rule, defining an element of the grammar. A rule must start with the identifier of the element, followed by an equal sign, and an expression of elements. Each rule must end with a semicolon.
The first rule above defines the root element list as a sequence (using {}) of elements person.
The next rule defines an element person as a name and an optional age. The name element is a string. The age element is an integer. string and int are pre-defined words of the parser. This syntax can be used to parse code like this:
'Rich' 40
'Guvnor'
'Carl' 10
When IntoTheCode gets the this grammar and this input code, it will generate this output (shown in markup format):
<list>
<person>
<name>Rich</name>
<age>40</age>
</person>
<person>
<name>Guvnor</name>
</person>
<person>
<name>Carl</name>
<age>10</age>
</person>
</list>
Notice that the root element is list from the grammar. Children of list are person elements. Each person has a name (string) and possibly an age (integer).
Expressions of Elements
As mentioned above, a rule has an expression of elements. This is how elements are combined to more complex rules.
Expressions of elements use these operators:
- | Alternation: The expression before or the expression after must apply
- ( ) Parentheses: Gives higher precedence to an expression
- { } Sequence: Read this expression any number of times
- [ ] Optional: The expression is optional
- Concatenation: Elements can be concatenated (separated by a space)
If alternations exist, these are applied until one of them succeeds. If no alternations apply, the rule doesn’t apply.
Example of concatenation: (name must include both firstname and lastname)
name = firstname lastname;
Example of alternation: (transport can be either train or bus)
transport = train | bus;
Example 1 of parentheses: (customer is customerId and then either person or company)
customer = customerId (person | company);
Example 2 of parentheses: (post is either a letter or packagetype and package)
post = letter | (packagetype package);
Words
Most other parsers break text into tokens (or “terminal symbols”) before assembling the tokens into elements of more abstract meaning. The tokens are atom building blocks of the text and are defined in the grammar as absolute strings or regular expressions.
IntoTheCode does not use regular expressions like many other parsers. Instead, it has pre-defined words: string, int, float, bool and identifier. These are keyword to the grammar. The advantage: You don’t have to define the digits and sign of an integer, you can just write ‘int’ in the grammar.
The words are programmed in the parser and are read ‘just in time’ when they are applied. If these words don’t fit your needs, you must alter the code or implement a new word. (In the future, there might be a type of word for regular expressions.)
White Space and Comments
Like the words, white space and comment handling are built into the parser. White spaces are the characters to separate words and sometimes format the code to be more readable. The default white space characters are space, tab, newline and return. Comments are read and inserted in the output as a special class of node. The comment style is inline, starting with double slash and ending with newline. So at the moment, white spaces and comments are rather inflexible.
Example of comment:
// this is a comment
'Rich' 40 // another comment
Settings
Sometimes, the rules of the Extended Backus-Naur form can’t stand alone. Therefore some settings are needed. A grammar for IntoTheCode is split in two sections. The Rule section described above and the settings section. The settings contain configurations for the rules, words and the parser. For example: a rule has the property ‘collapse’; If a rule is collapsed, it will not create elements of output. Instead, the rules child elements are inserted to the rules parent element. This is only relevant for the programmer who handles the output (not necessarily the programmer that writes the code to be parsed).
Example of settings:
name = firstname lastname;
settings
name collapse;
This means that the rule name will not generate any output nodes, and nodes generated by firstname and lastname will be inserted to the parent node.
Examples
The source code contains a demo application with three examples of parsers and how to consume the output.
To start the demo application:
- Get the sourcecode for IntoTheCode.
- Start the solution in Visual Studio.
- Set TestApp as the startup project.
- Click run.
- Select one of the examples in the “Menu” tab.
About the demo application architecture. The demo application is based on a pragmatic Model-View-ViewModel architecture. The TestApp project contains the views. A common UserControl contains all controls, and defines bindings and some functionality to show cursor position. A UserControl for each example uses the common control and refers to the right ViewModel. The IntoTheCodeExamples project contains a ViewModel for each example. All ViewModels have the same ancestor with common properties, and functions for parsing the grammar and parsing the input. When input is parsed successfully, the function called ProcessOutput is called on the ViewModel, with a CodeDocument as parameter. This is where the output is consumed.
All examples look alike, except for the code in the textboxes. Here is a screenshot from the CSV data example:
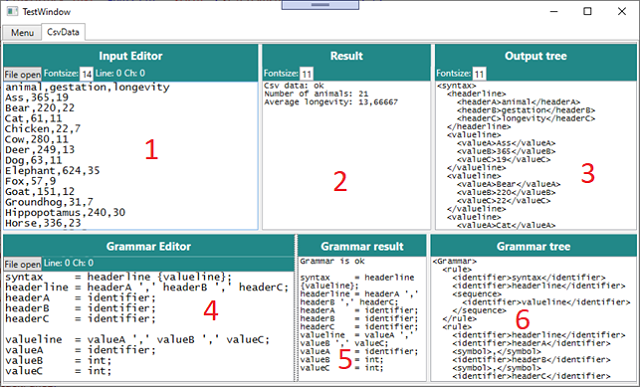
Explanations of user interface:
- Input Editor: Input data
- Result: Output from
ViewModel if input is readable or an error message - Output tree: Output from parser as markup, if input is valid
- Grammar Editor: Grammar
- Grammar result: Error message, or the text ‘Grammar is ok’ and the formatted grammar
- Grammar tree: This is the metaparser output as markup, if grammar is valid.
You can change the input. After each change, the input is parsed.
You can change the grammar. After each change, the grammar is parsed. If the grammar is ok, the input is parsed. If the input matches the grammar, then the ‘Output tree’ does work, though the ViewModel result may not work.
“CSV data” Example
This is an old fashioned datafile. The ViewModel counts the number of valuelines and makes an average of the ValueC (longevity).
Try to alter some of the element names and see what happens to the output tree and result.
Calculator Expressions Example
This example reads calculator expressions like: 1 + 2 * (4 - 1). The term “Calculator expression” is to be distinguished from “Expression of elements” explained above.
IntoTheCode has a special way to treat calculator expressions with binary operators. This grammar defines expressions with multiplication and addition:
expression = multiplication | addition | number;
multiplication = expression '*' expression;
addition = expression '+' expression;
number = int;
Definition of calculator expressions: The calculator expression rule must be a set of alternatives (the name is not significant). And the first alternative must be in the ‘operator’ form: “expression symbol expression”. When the parser is instantiated with this ‘form’ in a grammar, it will automatically transform the rule to a calculator expression with a set of binary operators and values.
Each alternative with the ‘operator’ form will define a new binary operator.
You might say that the alternatives can parse the same code. But the alternatives do not have precedence or association logic.
When the grammar is transformed, configuration can be set for precedence or association logic (in the settings section). Two operators can have the same precedence and an operator can be right associative. If no configuration is set, the first alternative has highest precedence, the next has lower precedence and so on. Operators are default left associative. Alternatives that do not fit the ‘operator’ form stay unchanged and are regarded as values to the calculator expression.
The output tree is nested operator elements; An operator has two values. A value can be a new expression or one of the other alternatives.
The example also contains code to consume the calculator expression and calculate a mathematical result.
This is the full grammar from the example:
input = [exp];
exp = power | mul | sum | div | sub | par | number;
mul = exp '*' exp;
div = exp '/' exp;
sum = exp '+' exp;
sub = exp '-' exp;
power = exp '^' exp;
number = int;
par = '(' exp ')';
settings
exp collapse;
mul Precedence = '2';
sum Precedence = '1';
div Precedence = '2';
sub Precedence = '1';
power RightAssociative;
Programming Language Example
As promised in the beginning, here is a general programming language implementation. It is aimed for making a domain language. The language has:
- Variable types:
int, string, real and bool - Expressions of different types
- Compile time type check
- Recursive functions
- Input parameters
- Custom functions
The syntax of the language is inspired from C# (as everything in IntoTheCode). The set of operations is reduced, just to demonstrate the principles. The language is called “C the Light”. The example both demonstrates a grammar for designing a programming language and (if downloaded), an implementation of runtime environment (a compiler).
Grammar
This is the whole grammar of C the Light (without settings). I won’t explain every rule, but for the experienced grammar reader, it might be interesting.
program = scope;
body = operation | '{' scope '}';
scope = {functionDef | variableDef | operation};
operation = assign | if | while | funcCall ';' | return;
functionDef = declare '(' [declare {',' declare}] ')' '{' scope '}';
variableDef = declare '=' exp ';';
declare = (defInt | defString | defReal | defBool | defVoid) identifier;
defInt = 'int';
defString = 'string';
defReal = 'real';
defBool = 'bool';
defVoid = 'void';
assign = identifier '=' exp ';';
return = 'return' [exp] ';';
if = 'if' '(' exp ')' body ['else' body];
while = 'while' '(' exp ')' body;
funcCall = identifier '(' [exp {',' exp}] ')';
exp = mul | div | sum | sub | gt | lt | eq | value | '(' exp ')';
mul = exp '*' exp;
div = exp '/' exp;
sum = exp '+' exp;
sub = exp '-' exp;
gt = exp '>' exp;
lt = exp '<' exp;
eq = exp '==' exp;
value = float | int | string | bool | funcCall | identifier;
The production rules can be separated in two:
- Operations that can run
- Expressions that can be calculated
The declare rule is not an operation in itself, but just nice to have. It is used in multiple places with the same syntax. The type elements rules (defInt, defString,…) are necessary for IntoTheCode because elements are not inserted in the output without a rule.
The syntax for expressions exp is common for all data types. Naturally, the if and while operations can only take a bool expression and other operations must have certain types of expressions, but this is not handled in the grammar/parser. The type check is left for the compiler.
The Runtime Environment
If possible, each syntax rule is compiled to a corresponding class. Basically, each class has properties corresponding to the elements of the rule. The ProgramBuilder and ExpressionBuilder classes read one element from the CodeDocument (parser output), create the right class and set the properties by repeating the process.
The operations inherit from the OperationBase class, and has a Run function.
The expressions inherit from the ExpTyped<T> class, and has a Compute function.
For example: Each scope has the possibility to define functions, variables and operations. First, all functions are built and put in the Scope.Function property. The variables and operations are built and put respectively in the Scope.Vars and Scope.Operations properties. Function calls are resolved at compile time and functions from parent scopes are accessible. The variables are created both at compile time to do type checking and at runtime to enable recursive calls.
All the compilation and execution are implemented by these basic principles and just a little more details. (Especially the type checking has some details.)
About the Custom functions: You can add functions as lambda expressions to the program that allows the program to call functions from the outside (the ViewModel in this case). Only void function that takes a string is implemented but new signatures can easily be added. This is how the Write function can write to the output view.
Have Fun
You have reached the end of this description of IntoTheCode. Now, go to GitHub or the top of this article, to get the source code. Then, have fun making your own grammars and code!
History
- 17th June, 2020: Initial version
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




