Introduction
What do a GIF image, an HTML page, and a shopping list have in common? They all are or contain lists that don't require a specific order of elements. The colours in the GIF image's palette can have any order, just as the attributes in an HTML tag, or the words on your shopping list on the kitchen table.
In every list with count elements, we can hide count-1 bits just by sorting the items. No tricks, no complicated formulas. Let us begin with a simple list of words, then proceed to GIF image palettes, and at last to HTML documents. The algorithm is always the same, because all lists are the same.
The first step is to force the list items into a specific order, which can be alphabetically, or a customized sorting. Then the sorted list is re-sorted, depending on the bits of the secret message.
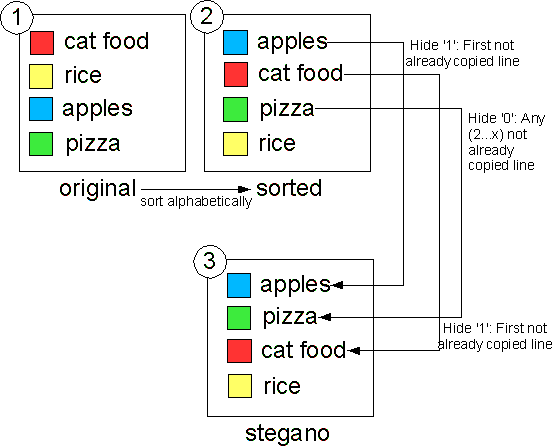
If you know the default sorting, you can sort the list again and compare the stegano-list with the sorted list. The differences tell you everything about the message-bits that produced the word order:

Line by Line
You don't really need a computer for list-steganography. Take a piece of paper and a pencil, and write down nine animals. No, this is not the beginning of a psycho test, it is a carrier document. The words need a standard sorting we can refer to when re-sorting, so we sort them alphabetically:
- Bird
- Cat
- Dinosaur
- Dog
- Fish
- Horse
- Rabbit
- Sheep
- Unicorn
Without any mathematical tricks, nine list entries can hide 9-1 = 8 bits of information, for example, the ASCII character 'c' (99 or 01100011). Each list item (except the last one) represents one bit. For each 1 bit, we move the first item from the original list into the new list, for 0 bits, we move one of the other list items into the new list. Starting with the highest bit, the process works like that:
Original List New List
Bird ---
Cat ---
Dinosaur ---
Dog ---
Fish ---
Horse ---
Rabbit ---
Sheep ---
Unicorn ---
Hide '0' - Move any item but the first one
Bird Dinosaur
Cat ---
--- ---
Dog ---
Fish ---
Horse ---
Rabbit ---
Sheep ---
Unicorn ---
Hide '1' - Move the first item
--- Dinosaur
Cat Bird
--- ---
Dog ---
Fish ---
Horse ---
Rabbit ---
Sheep ---
Unicorn ---
Hide '1' - Move the first item
--- Dinosaur
--- Bird
--- Cat
Dog ---
Fish ---
Horse ---
Rabbit ---
Sheep ---
Unicorn ---
Hide '0' - Move any item but the first one
--- Dinosaur
--- Bird
--- Cat
Dog Rabbit
Fish ---
Horse ---
--- ---
Sheep ---
Unicorn ---
... ... and so on ... ...
Hide '1' - Move the first item
--- Dinosaur
--- Bird
--- Cat
--- Rabbit
--- Unicorn
--- Fish
--- Dog
Sheep Horse
--- ---
No not-first item for a zero-bit left,
that means, no capacity for more bits.
Copy the last item, anyway.
--- Dinosaur
--- Bird
--- Cat
--- Rabbit
--- Unicorn
--- Fish
--- Dog
--- Horse
--- Sheep
The new list contains the same items as the original list and an additional sub-content which only we know about. The hidden byte can be read again, if we work through the same process the other way round.
Sorted List Carrier List
Bird Dinosaur
Cat Bird
Dinosaur Cat
Dog Rabbit
Fish Unicorn
Horse Fish
Rabbit Dog
Sheep Horse
Unicorn Sheep
'Dinosaur' is not the first item in the sorted list, so the hidden bit was '0'.
Note that down, and remove the item from both lists.
Bird ---
Cat Bird
--- Cat
Dog Rabbit
Fish Unicorn
Horse Fish
Rabbit Dog
Sheep Horse
Unicorn Sheep
'Bird' from the carrier list is the first item in the sorted list => '01'.
--- ---
Cat ---
--- Cat
Dog Rabbit
Fish Unicorn
Horse Fish
Rabbit Dog
Sheep Horse
Unicorn Sheep
'Cat' from the carrier list is the first item in the sorted list => '011'.
--- ---
--- ---
--- ---
Dog Rabbit
Fish Unicorn
Horse Fish
Rabbit Dog
Sheep Horse
Unicorn Sheep
'Dinosaur' is not the first item in the sorted list => '0110'.
... ... and so on for all animals ... ...
The Latin alphabet is not a good default sorting, because everybody would try that one first. I suggest you mix up the letters and write a customized alphabet, before you sort your list. We can do the same sorting thing in C#:
public StringCollection Hide(String[] lines, Stream message, String alphabet)
{
StringCollection originalList = Utilities.SortLines(lines, alphabetFileName);
StringCollection resultList = new StringCollection();
int messageByte = message.ReadByte();
bool messageBit = false;
int listElementIndex = 0;
Random random = new Random();
while (messageByte > -1) {
for (int bitIndex=0; bitIndex<8; bitIndex++) {
messageBit = ((messageByte & (1 << bitIndex)) > 0) ? true : false;
if (messageBit) {
listElementIndex = 0;
}else{
listElementIndex = random.Next(1, originalList.Count);
}
resultList.Add(originalList[listElementIndex]);
originalList.RemoveAt(listElementIndex);
}
messageByte = message.ReadByte();
}
foreach (String s in originalList) {
resultList.Add(s);
}
return resultList;
}
Given a list and an alphabet, reverting the process is easy:
public Stream Extract(String[] lines, String alphabet)
{
BinaryWriter messageWriter = new BinaryWriter(new MemoryStream());
StringCollection carrierList = new StringCollection();
carrierList.AddRange(lines);
carrierList.RemoveAt(carrierList.Count - 1);
StringCollection originalList = Utilities.SortLines(lines, alphabetFileName);
String[] unchangeableOriginalList = new String[originalList.Count];
originalList.CopyTo(unchangeableOriginalList, 0);
int messageBit = 0;
int messageBitIndex = 0;
int messageByte = 0;
foreach (String s in carrierList) {
if (s == originalList[0]) {
messageBit = 1;
}else{
messageBit = 0;
}
originalList.Remove(s);
messageByte += (byte)(messageBit << messageBitIndex);
messageBitIndex++;
if (messageBitIndex > 7) {
messageWriter.Write((byte)messageByte);
messageByte = 0;
messageBitIndex = 0;
}
}
messageWriter.Seek(0, SeekOrigin.Begin);
return messageWriter.BaseStream;
}
Colourful Bits
Every indexed bitmap contains a list that can be abused just that way. These two palettes belong to the same GIF picture, one is the original, the other one carries a hidden text of 31 characters:
Again, the first thing we need is a palette with a default sorting. In this example, we will sort the colours by their ARGB values.
public Bitmap Hide(Bitmap image, Stream message)
{
int[] colors = new int[image.Palette.Entries.Length];
for (int n = 0; n < colors.Length; n++) {
colors[n] = image.Palette.Entries[n].ToArgb();
}
ArrayList resultList = new ArrayList(colors.Length);
ArrayList originalList = new ArrayList(colors);
originalList.Sort();
Many pixels are linked to the palette entries, and we will have to change those, too. So, whenever we move a colour to the new palette, we should map the old index to the new index.
SortedList oldIndexToNewIndex = new SortedList(colors.Length);
Now that the lists are finished, we can dive into the message and move one colour for each bit...
Random random = new Random();
int listElementIndex = 0;
bool messageBit = false;
int messageByte = message.ReadByte();
while (messageByte > -1) {
for (int bitIndex = 0; bitIndex < 8; bitIndex++) {
messageBit = ((messageByte & (1 < bitIndex)) > 0) ? true : false;
if (messageBit) {
listElementIndex = 0;
}else{
listElementIndex = random.Next(1, originalList.Count);
}
...but don't forget from which position in the original palette the entries came! There are thousands of pixels waiting for updated colour indices.
int originalPaletteIndex = Array.IndexOf(colors,
originalList[listElementIndex]);
if( ! oldIndexToNewIndex.ContainsKey(originalPaletteIndex)) {
oldIndexToNewIndex.Add(originalPaletteIndex, resultList.Count);
}
resultList.Add(originalList[listElementIndex]);
originalList.RemoveAt(listElementIndex);
}
messageByte = message.ReadByte();
}
foreach (object obj in originalList) {
int originalPaletteIndex = Array.IndexOf(colors, obj);
oldIndexToNewIndex.Add(originalPaletteIndex, resultList.Count);
resultList.Add(obj);
}
Bitmap newImage = CreateBitmap(image, resultList, oldIndexToNewIndex);
return newImage;
}
The corresponding Extract method works very similar to a combination of the Hide and the Extract methods for text lists. It sorts the palette, reconstructs the message, and then removes the message from the image (returns an image with a palette, in default sorting). This is the palette from the example above the code, after the message has been extracted and removed:
Tags full of Text Lists
An HTML document itself is no sortable list, the tags must stay in their order. But inside the tags, there are attributes, and they can be sorted. That means, every tag in an HTML page can store Attributes.Count-1 bits. Most tags have just enough attributes for one or two bits, but we can distribute the message's bits over all tags of the page.
public void Hide(String sourceFileName, String destinationFileName,
Stream message, String alphabet) {
HtmlTagCollection tags = FindTags(htmlDocument);
foreach (HtmlTag tag in tags) {
insertTextBuilder.Remove(0, insertTextBuilder.Length);
insertTextBuilder.AppendFormat("<{0}", tag.Name);
String[] attributeNames = new String[tag.Attributes.Count];
for (int n = 0; n < attributeNames.Length; n++) {
attributeNames[n] = tag.Attributes[n].Name;
}
From here, the code is nearly the same as in the other Hide methods:
StringCollection originalList = Utilities.SortLines(attributeNames, alphabet);
StringCollection resultList = new StringCollection();
if (tag.Attributes.Count > 1) {
for (int n = 0; n < attributeNames.Length - 1; n++) {
bitIndex++;
if (bitIndex == 8) {
bitIndex = 0;
if (messageByte > -1) {
messageByte = message.ReadByte();
}
}
if (messageByte > -1) {
messageBit =
((messageByte & (1 << bitIndex)) > 0) ? true : false;
if (messageBit) {
listElementIndex = 0;
}else{
listElementIndex = random.Next(1, originalList.Count);
}
}else{
listElementIndex = 0;
}
resultList.Add(originalList[listElementIndex]);
originalList.RemoveAt(listElementIndex);
}
}
if (originalList.Count > 0) {
resultList.Add(originalList[0]);
}
The sorted attributes have to be written back into the document. Most of the code has been copied from the previous article in this series, the one only about HTML attributes.
HtmlTag.HtmlAttribute attribute;
foreach (String attributeName in resultList) {
attribute = tag.Attributes.GetByName(attributeName);
insertTextBuilder.Append(" ");
if (attribute.Value.Length > 0) {
insertTextBuilder.AppendFormat("{0}={1}",
attribute.Name, attribute.Value);
}else{
insertTextBuilder.Append(attributeName);
}
}
}
Have you noticed that the three Hide methods do nearly the same? The Extract methods are just as similar. Please look them up in the complete source code, if you don't have a binary allergy, yet. ;-)
The Demo Application
The application consists of three "half duplex dialogs". You can either enter an empty carrier as a message for hiding, or a carrier for extracting. For text lists and images, you can see the result immediately.
In the dialogs for text lists and HTML documents, you can select an "alphabet file". That is a text file with a customized alphabet. See testdata/demo.txt for a possible custom alphabet.
For any other IDE than Visual Studio 2005/C# Express or SharpDevelop, please unzip the .NET 1.1 version, open an empty project, and add all code files.
Corinna lives in Hanover/Germany and works as a C# developer.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 







![Rose | [Rose]](https://codeproject.global.ssl.fastly.net/script/Forums/Images/rose.gif)
 Dass ich da nicht selbst drauf gekommen bin...
Dass ich da nicht selbst drauf gekommen bin... Ah well ... the good old days.
Ah well ... the good old days. Hey, I'm sure everybode here knows GIF Shuffle.
Hey, I'm sure everybode here knows GIF Shuffle.

