Introduction
Organizations today encounter textual data (both semi-structured and unstructured) while running their day to day business. The source of the data could be electronic text, call center logs, social media, corporate documents, research papers, application forms, service notes, emails, etc. This data may be accessible but remains untapped due to the lack of awareness of the information wealth an organization possesses or the lack of methodology or technology to analyze this data and get the useful insight.
Any form of information that an organization possesses or can posses is an asset and can get insight about its business by exploiting this information for decision making. This data could hold information about their customer, partners and competitors. The data about customers could give them insight about how to provide better services to its customers and increase their customer base. The data about its partners can provide insights about how to maintain better relationships with its partners and forge new and valuable relationships. The data about its competitors can help them stay ahead of its competitors. However, not all the data that an organization possesses is tapped to get these insights. The reason being that major portion of this data is not in the structured form and it is difficult to process this data the way structured data is processed(using traditional methods) to get the useful and desired insight. Further the sea of this data, having potential commercial, economic and societal value, is expected to grow at a faster pace in near future. Therefore it becomes extremely important to use techniques that can exploit this potential by uncovering hidden value from this data. This is where text mining/analytics techniques find its value and can be helpful in discovering useful and interesting knowledge from this data. Businesses use such techniques to analyze customer and competitor data to improve competitiveness.
Abstract
Text mining is gaining importance due to problem of discovering useful information from the data deluge that the organizations are facing today. This white paper intends to present a broad overview of text mining and its components and techniques and their use in various business applications. This paper gives a description about text mining and the reasons for its increased importance over the years. This is followed with presenting a generic process framework for text mining and describes its different components and sub-components, business applications, and brief description of text mining tools available in the market.
Text mining is often considered to have originated from data mining; however a few of the techniques have come from various other disciplines like information science and information visualization. Text mining strives to solve the information overload problem by using techniques from data mining, machine learning, natural language processing (NLP), information retrieval (IR), Information extraction (IE) and knowledge management (KM). Text mining involves the preprocessing of document collections (text categorization, feature/term extraction, etc.), the storage of the intermediate representations, the techniques to analyze these intermediate representations (such as distribution, analysis, clustering, trend analysis, and association rules), and visualization of the results.
What is Text Mining?
Simply put text mining is the knowledge discovery from textual data or textual data exploration to uncover useful but hidden information. However, many people have defined text mining slightly differently. The following are a few definitions:
“The objective of Text Mining is to exploit information contained in textual documents in various ways, including …discovery of patterns and trends in data, associations among entities, predictive rules, etc.” (Grobelnik et al., 2001).
“Another way to view text data mining is as a process of exploratory data analysis that leads to heretofore unknown information, or to answers for questions for which the answer is not currently known.” (Hearst, 1999).
Text mining also known as text data mining or text analytics is the process of discovering high quality information from the textual data sources. The application of text mining techniques to solve specific business problems is called business text analytics or simply text analytics. Text mining techniques can facilitate organizations derive valuable business insight from the wealth of textual information they possess.
Text mining transforms textual data into structured format through the use of several techniques. It involves identification and collection of the textual data sources, NLP techniques like part of speech tagging and syntactic parsing, entity/concept extraction which identifies named features like people, places, organizations, etc., disambiguation, establishing relationship between different entities/concepts, pattern and trend analysis and visualization techniques.
Text Mining Framework
Figure 1 below depicts a generic text mining framework. The textual data is obtained from the various textual data sources. Preprocessing techniques, centered on identification and extraction of the features from the textual data, are then used to transform the unstructured data from the textual data sources into a more explicitly structured intermediate format. Text mining also uses techniques and methodologies from other computer science disciplines concerned with managing natural language text like information retrieval and information extraction. Knowledge discovery component generally includes the application pattern discovery and trend analysis algorithms to discover valuable information from the intermediate format textual data. Presentation layer component includes GUI for pattern browsing facility and also includes tools for creating and viewing trends and patterns.
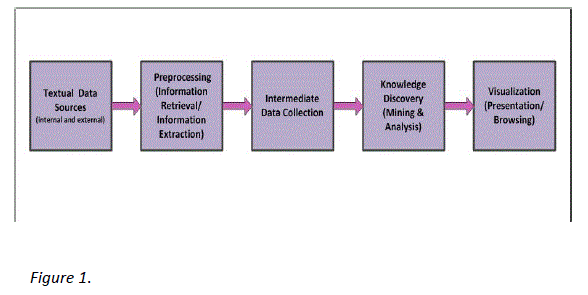
Text Mining Framework Components
The different stages in the text mining framework are described below:
1. Textual Data Sources
The textual data is available in numerous internal and external data source like electronic text, call center logs, social media, corporate documents, research papers, application forms, service notes, emails, etc.
2. Preprocessing
Preprocessing tasks include methods to collect data from the disparate data sources. This is the preliminary step of identifying the textual information for mining and analysis. Preprocessing tasks apply various feature extraction methods against the data. Preprocessing tasks include different types of techniques to transform the raw, unstructured, original format data into structured, intermediate data format. Knowledge discovery operations are conducted against the structured intermediate data.
For the preparation of unstructured data into a structured data format, different techniques are needed than those of traditional data mining systems where the knowledge discovery is done against the structured data sources. Various preprocessing techniques exist and can be used in combination to create structured data representation from raw textual data. Therefore different combinations of techniques can be used based on the type of the raw textual data.
a. Text Cleansing
Text cleansing is the process of cleansing noisy text from the textual sources. Noisy textual data can be found in SMSes, email, online chat, news articles, blogs and web pages. Such text may have spelling errors, abbreviations, non-standard terminology, missing punctuation, misleading case information, as well as false starts, repetitions, and special characters.
Noise can be defined as any kind of difference in the surface form of an electronic text from the original, intended or actual text. The text used in the in short message service (SMS) and on-line forums like twitter, chat and discussion boards and social networking sites is often distorted mainly because the recipients can very well understand the shorter form of the longer words and also reduces the time and effort of the sender. Most of the text is created and stored so that humans can understand it, and it is not always easy for a computer to process that text. With the increase in noisy text data generated in various social communication media, cleansing of such text has become necessary and also because the of-the-shelf NLP techniques generally fail to work because of several reasons like sparsity, out-of-vocabulary words and irregular syntactic structures in such texts.
A few of the cleaning techniques are:
Removing stop words (deleting very common words like "a", "the", "and", etc.).
Stemming (ways of combining words that have the same linguistic root or stem).
i. Removing stop words
Stop words are words which are filtered before or after processing of textual data. There is not one definite list of stop words which all tools use, if even used. Some tools specifically avoid removing them to support phrase search. The most common stop words found in the text are “the”, “is”, “at”, “which” and “on”. These kinds of stop words can sometimes cause problems when looking for the phrases that include them. Some search engines remove some of the most common words from the query on order to improve performance.
ii. Stemming
Stemming is the process for reducing inflected (or sometimes derived) words to their stem, base or root form, generally a written word form. The stem need not be identical to the morphological root of the word; it is usually sufficient that related words map to the same stem, even if this stem is not in itself a valid root. Algorithms for stemming have been studied in computer science since 1968. Many search engines treat words with the same stem as synonyms as a kind of query broadening, a process called conflation.
A stemmer for English, for example, should identify the string "cats" (and possibly "catlike", "catty" etc.) as based on the root "cat", and "stemmer", "stemming", "stemmed" as based on "stem". A stemming algorithm reduces the words "fishing", "fished", "fish", and "fisher" to the root word, "fish". On the other hand, "argue", "argued", "argues", "arguing", and "argus" reduce to the stem "argu" (illustrating the case where the stem is not itself a word or root) but "argument" and "arguments" reduce to the stem "argument".
Stemming programs are commonly referred to as stemming algorithms or stemmers. There are several types of stemming algorithms which differ in respect to performance and accuracy and how certain stemming obstacles are overcome.
b. Tokenization
Tokenization is the process of breaking piece of text into smaller pieces like words, phrases, symbols and other elements which are called tokens. Even a whole sentence can be considered as a token. During the tokenization process some characters like punctuation marks can be removed. The tokens then become an input for other processes in text mining like parsing.
Tokenization relies mostly on simple heuristics in order to separate tokens by following a few steps:
- Tokens or words are separated by whitespace, punctuation marks or line breaks
- White space or punctuation marks may or may not be included depending on the need
- All characters within contiguous strings are part of the token. Tokens can be made up of all alpha characters, alphanumeric characters or numeric characters only.
Tokens themselves can also be separators. For example, in most programming languages, identifiers can be placed together with arithmetic operators without white spaces. Although it seems that this would appear as a single word or token, the grammar of the language actually considers the mathematical operator (a token) as a separator, so even when multiple tokens are bunched up together, they can still be separated via the mathematical operator.
Tokenization is the first step in processing the text. It is very difficult to extract useful high level information from the text without identifying the tokens. Each token is an instance of a type, so the number of tokens is much higher than the number of types. As an example, in the previous sentence there are two tokens spelled “the.” These are both instances of a type “the,” which occurs twice in the sentence. Properly speaking, one should always refer to the frequency of occurrence of a type, but loose usage also talks about the frequency of a token. It would be easier for a person, familiar with the language, to identify the tokens in the stream of characters. But on the other hand it would be difficult for a computer to do so due to lack of understanding of the language. This is because some characters are sometimes considered as token delimiters and sometimes not based on the application. The characters space, tab, and newline we assume are always delimiters and are not counted as tokens. They are often collectively called white space. The characters ( ) < > ! ? " are always delimiters and may also be tokens. The characters . , : - ’ may or may not be delimiters, depending on their environment. A period, comma, or colon between numbers would not normally be considered a delimiter but rather part of the number. Any other comma or colon is a delimiter and may be a token. A period can be part of an abbreviation (e.g., if it has a capital letter on both sides). It can also be part of an abbreviation when followed by a space (e.g., Dr.). However, some of these are really ends of sentences. The problem of detecting when a period is an end of sentence and when it is not will be discussed later. For the purposes of tokenization, it is probably best to treat any ambiguous period as a word delimiter and also as a token. The apostrophe also has a number of uses. When preceded and followed by non-delimiters, it should be treated as part of the current token (e.g., isn’t or D’angelo). When followed by an unambiguous terminator, it might be a closing internal quote or might indicate a possessive (e.g., Tess’). An apostrophe preceded by a terminator is unambiguously the beginning of an internal quote, so it is possible to distinguish the two cases by keeping track of opening and closing internal quotes. A dash is a terminator and a token if preceded or followed by another dash. A dash between two numbers might be a subtraction symbol or a separator (e.g., 555-1212 as a telephone number). It is probably best to treat a dash not adjacent to another dash as a terminator and a token, but in some applications it might be better to treat the dash, except in the double dash case, as simply a character.
c. POS tagging
Part-of-speech tagging also known as grammatical tagging or word-category disambiguation is the process of assigning a word in the text corresponding to a particular part of speech like noun, verb, pronoun, preposition, adverb, adjective or other lexical class marker to each word in a sentence. The input to a tagging algorithm is a string of words of a natural language sentence and a specified tagset (a finite list of Part-of-speech tags). The output is a single best POS tag for each word.
Tags play an important role in Natural language applications like speech recognition, natural language parsing and information retrieval.
Part-of-speech tagging is harder than just having a list of words and their parts of speech, because some words can represent more than one part of speech at different times, and because some parts of speech are complex or unspoken. This is very common in natural languages as compared to the artificial languages where a large portion of word forms are ambiguous. For example, ‘dogs’, thought to be plural nouns can also be a verb: “The sailor dogs the barmaid”.
Performing grammatical tagging will indicate that "dogs" is a verb, and not the more common plural noun, since one of the words must be the main verb, and the noun reading is less likely following "sailor". "Dogged", on the other hand, can be either an adjective or a past-tense verb. Just which parts of speech a word can represent varies greatly.
Hidden Markov Models (HMMs) is one of the earliest models used to disambiguate part of speech.
d. Syntactical Parsing
Syntactical parsing is the process of performing syntactical analysis on a string of words, phrase or a sentence according to certain rules of grammar. Syntactical parsing discovers structure in the text and is used to determine if a text conforms to an expected format. It involves breaking of text into different elements and identifying syntactical relationship between different elements. The basic idea behind syntactical analysis is to create a syntactic structure or a parse tree from a sentence in a given natural language text to determine how a sentence is broken down into phrases, how the phrases are broken down into sub-phrases, and all the way down to the actual structure of the words used. In order to parse natural language text two basic grammars are used:- the constituency and dependency grammars.
Constituency grammars help create the syntactical structure by breaking the sentences into repetitive phrases or sequence of syntactically grouped elements. Many constituency grammars make a distinction between noun phrases, verb phrases, prepositional phrases, adjective phrases, and clauses. Each phrase may consist of zero or smaller phrases or words according to the rules of the grammar. Each phrase plays a different role in a syntactical structure of a sentence, for example, a noun phrase may be labeled as the subject of the sentence.
Dependency grammars, on the other hand, help create the syntactical structure of a sentence based on the direct one-to-one relation between different elements or words. Dependency relation views the verb as the center of the syntactical structure and all other words elements or words dependent on the verb directly or indirectly.
e. Information Extraction
Information extraction identifies the key phrases and relationships within the textual data. This is done by a process called pattern matching which looks for predefined sequences in the text. Information extraction infers the relationships between all the identified people, places and time from the text to extract the meaningful information. For handling huge volumes of textual data Information extraction can be very useful. The meaningful information is collected and stores in the data repositories for Knowledge discovery, mining and analysis. A few of the information extraction techniques are described below:
i. Topic tracking
Topic tracking system keeps track of the users and their profiles and the documents a particular user views and thereby finds out the similar documents which may be of interest to the user. This system can be helpful in letting the users identify particular categories they may be interested in and can also identify user’s interest based on their reading history.
Topic tracking finds application in many business areas in the industry. With topic tracking system in place organization can find out the news related to their competitors and their products, which helps them keep track of competitive products and the market conditions as well as keep track their own business and products. In the medical industry topic tracking can help medical professionals find out new treatments for illnesses and advances in the medicine.
iii. Summarization
Text summarization, as one can make out, is to create a summary of the detailed text. The most important part of summarization is to reduce the size of the text without distorting the overall meaning and without eliminating the essential points in the text. This helps in getting the useful information from only summarized portion of text.
In summarization one of the most commonly used techniques is sentence extraction, which extracts the essential sentences from the text by adding a weight to the sentence and also finds out the position of a particular sentence by identifying the key phrases.
Text summarization is very helpful in trying to figure out whether or not a lengthy document meets the user’s needs and is worth reading for further information. Generally, when humans summarize text, we read the entire selection to develop a full understanding, and then write a summary highlighting its main points. With large texts, text summarization software processes and summarizes the document in the time it would take the user to read the first paragraph.
iii. Categorization
Text Categorization also known as text classification is the task of grouping a set of free-text documents into predefined categories. This is done by identifying the main topics in the text documents. The text documents can be classified based on the subject and other attributes like document type, author, genre etc.
Categorization does not process the actual information that is contained in the text documents. However it counts the words that appear on the text and from the counts it identifies the main topics that the text document covers. Domain specific dictionaries are used in categorization to identify the relationships by looking for synonyms and related terms. Categorization also ranks the text documents based on the documents having most content on a particular topic.
Categorization can be applied in many business areas. For example companies having customer support units, which is meant to answer the customer queries on different topics, can use categorization to classify the text documents by topics and thereby would access the relevant information much more quickly and answer the user queries quickly.
iv. Feature/Term Selection
A major difficulty of text categorization is high dimensionality of the feature space. The feature selection methods can be used to reduce the dimensionality of the datasets by removing the features that are not required for text categorization or classification. Feature selection is an essential part of text categorization or classification. The feature space consists of the unique terms (words or phrases) that occur in text documents. Text document collections have a lot of such unique terms, which can be tens or hundreds of thousands of terms for even moderate sized text collection. Having a lot of such terms are not considered useful for text classification. Reducing the set of terms can make classification more effective and can improve generalization error.
Thus feature selection methods can be advantageous in reducing the size of the feature space and producing smaller datasets and thereby letting text classification algorithms work on lesser computational requirements.
v. Entity Extraction
Entity Extraction also know as Named Entity Recognition or Named Entity Extraction is a subtask of Information extraction that is used to identify and classify atomic elements in text into predefined categories like people, places, organizations and products. These are generally proper nouns and constitute ‘who’ and ‘where’. However there may be other named entities which can be interesting like dates, addresses, phone numbers and website url’s. Ability to extract these kind of named entities can essential based on what you are trying to achieve.
You can use a system which will have a statistical model to find out the entities you are looking for, like people, places or organizations. For example organization name and an individual’s name are proper nouns and systems can make good guesses to find out the type a particular name is, whether it is a place (Hilton Head), a person (Paris Hilton), or an organization (Hilton Hotels).
vi. Concept extraction
Concepts answer the question: ‘What are the important concepts that are being used? Concept is a word or a phrase contained in the text by which you can identify the context of the text collection. Identification of the concepts in the text is one of the ways of classification/ categorization. Social media, technology, business are examples of concepts which can be identified in the text. For example, you can identify a conversation in text talking about ‘technology’ or a collection of text discussing 'politics’. To find out whether a piece of text is actually about a particular concept or it just describes something related to that concept, concept classifiers have scores associated with them.
There is a parent child relationship between categories and concepts. A category can have many concepts associated with it. For example, if the “Chemistry” is a category then atomic structure, chemical bonding, gases, etc., would be the concepts associated with the category “Chemistry”. So, by identifying the concepts you can carry out an analysis of your company and find out the broader context in which your company is being talked about, for example, ‘technology’.
vii. Theme extraction
Themes are the main ideas in a document. Themes can be concrete concepts such as Oracle Corporation, jazz music, football, England, or Nelson Mandela; themes can be abstract concepts such as success, happiness, motivation, or unification. Themes can also be groupings commonly defined in the world, such as chemistry, botany, or fruit.
Themes are the noun phrases or words in the text with contextual relevance scores. Theme extraction tells you the important words or phrases being used in the text. Themes once extracted are then scored for contextual relevance. Themes differ from the classifiers in the sense that themes tell you exact phrases or words being used while as classifiers identify the broad topics.
Themes are useful for discovery purposes. Themes will allow you to actually see that there is a new aspect to the conversation that may be important to consider, which your classifiers won’t be able to catch.
Themes do a very good job in uncovering the actual context in the text. With the addition of contextual scoring information themes are even more useful in finding out important context from the text and also comparing across similar pieces of text over a period of time.
viii. Clustering
Clustering is defined as the process of organizing objects together into groups and the objects in each group have similarity with the other objects in some way or the other. Therefore a cluster is a collection of objects which are similar between them and dissimilar to the objects in the other clusters. Clustering help identify a structure in a collection of unlabeled text.
Clustering technique is used to group similar documents in a collection but is different from categorization in the way that it clusters documents on the fly rather than using predefined topics.
The clustering tools help users to narrow down the documents rapidly by identifying which documents are relevant and which are not.
Clustering can be done by using various algorithms that differ significantly in their notion of what constitutes a cluster and how efficiently to find them.
3. Knowledge Discovery (Mining and Analysis)
Preprocessing (Information retrieval and Information extraction) is an essential component in text mining for discovering knowledge, as can be understood from the previous section on Preprocessing (Information retrieval and Information extraction). With information extraction we can uncover knowledge from the identified entities and the relationships between different entities from the text collection with considerable accuracy. However, the information extracted can be further analyzed by using traditional mining techniques/algorithms to discover more useful information. If the knowledge to be discovered is expressed directly from the text collection to be mined, then information extraction alone can serve as an effective approach to discover knowledge from the text collection. However, if the text collection contains data pertaining to reality rather than conceptual knowledge, then it may be useful to use information extraction to transform the data into structured form and store in a database and then use traditional mining tools to identify the trends and patterns in the extracted data.
Preprocessing tasks play an important part in transforming the raw unstructured textual data from document collection into a more manageable concept-level representation, the core functionality of a text mining system resides in the analysis of concept co-occurrence patterns across documents in a collection. Text mining systems rely on algorithmic and heuristic approaches to consider distributions, frequent sets, and various associations of concepts at an inter-document level in an effort to enable a user to discover the nature and relationships of concepts as reflected in the document collection as a whole. For example, from various news articles, you can find many articles on politician X and “scandal”. This obviously indicates a negative image of the politician X and therefore alerts his managers who then can go for a new public relation campaign. As another example, you might encounter many articles on company Y and their product Z which may indicate a shift of focus in company Y’s interests. This shift in focus might be worth noting by its competitors. In another example, a potential relationship can be identified between two proteins P1 and P2 by the understanding the pattern of
a) several articles mentioning the protein P1 in relation to the enzyme E1,
b) a few articles describing functional similarities between enzymes E1 and E2 without referring to any protein names, and
c) several articles linking enzyme E2 to protein P2.
In all three of these examples, the information is not provided by any single document but rather from the totality of the collection. Text mining methods of pattern analysis seek to discover co-occurrence relationships between concepts as reflected by the totality of the corpus at hand.
In text mining trend analysis relies on date-and-time stamping of text documents within a collection so that comparisons can be made between a subset of documents relating to one period and a subset of documents relating to another. Trend analysis across document subsets attempts to answer certain types of questions.
For instance,
- What is the general trend of the news topics between two periods (as represented by two different document subsets)?
- Are the news topics nearly the same or are they widely divergent across the two periods?
- Can emerging and disappearing topics be identified?
- Did any topics maintain the same level of occurrence during the two periods?
As can be seen in the questions above, individual ‘news topics’ are specific concepts in the document collection. Different types of trend analytics attempt to compare the frequencies of such concepts (i.e., number of occurrences) in the documents from different time period document sub collections. Several other types of analysis, derived from data mining that can be used to support trend analysis are ephemeral association discovery and deviation detection.
Mining process in text mining systems is built around algorithms that facilitate the creation of queries for discovering patterns in text document collections. Mining component includes many ways of discovering patterns of concept occurrence within a given text document collection or subset of a document collection. The three most common types of patterns encountered in text mining are distributions (and proportions), frequent and near frequent sets, and associations.
Text mining systems also provide the capability of discovering more than one type of pattern so that the users are able to toggle between displays of the different types of patterns for a given concept or set of concepts and there providing the richest possible exploratory access to the underlying textual data collection.
4. Presentation/Visualization
Browsing is one of the key functionalities supported by a text mining system. Many text mining systems support both dynamic and content-based browsing due to the reason that browsing is guided by the actual textual content in a particular document collection and not by anticipated or pre-specified structures. Browsing facilitates a user by providing a graphical presentation of the concept patterns in the form of a hierarchy to help organizing concepts for investigation and analysis.
Browsing should also be navigational. Text mining systems provide a user with extremely large sets of concepts extracted from large collections of text documents. Therefore, text mining systems must provide a user the facility to move across these concepts so that a user is able to choose either a “big picture“ view of the collection or to drill down on specific and possibly very sparsely identified concept relationships.
Text mining systems use visualization tools to facilitate navigation, exploration of concept patterns and graphical representations to express complex data relationships. Text mining systems toady heavily rely on highly interactive graphic representations of data that allow a user to drag, pull, click, or otherwise directly interact with the graphical representation of concept patterns.
The presentation layer in a text mining system serves as a front end for executing knowledge discovery algorithms and therefore significant attention is given in providing friendlier presentation user interface to the user with more powerful methods for executing these algorithms. Such methods can necessitate developing dedicated query languages to support the efficient parameterization and execution of specific types of pattern discovery queries.
Furthermore, text mining systems now-a-days are designed to provide users the direct access to their query language interfaces. Text mining front ends may also provide a user with the facility to cluster concepts by using clustering tools where a user can create customized profiles for concepts or concept relationships in order to create a richer knowledge environment for interactive exploration.
Finally, some text mining systems provide users with the facility to create and manipulate refinements constraints which will aid in generating more manageable and useful result sets for browsing and also in creation, shaping, and parameterization of queries. The use of such refinement constraints can be made much more user-friendly by incorporating graphical elements such as pull-downs, radio boxes, or context or query-sensitive pick lists.
5. Domains and Background Knowledge
Concepts in a text mining systems belong not only to the descriptive attributes of a particular document but generally also to domains. Domain, in relation to text mining, can be defined as a specialized area of interest where dedicated ontologies, lexicons, and taxonomies of information may be developed. Domains can include very broad areas of subject matter (e.g., biology) or more narrowly defined specialism’s (e.g., genomics or proteomics). In addition to this, there are other application areas of domains for text mining which include financial services (with significant subdomains like corporate finance, securities trading, and commodities.), world affairs, international law, counterterrorism studies, patent research, and materials science. Many text mining systems can use information from formal external knowledge sources for these domains to improve upon the elements of their preprocessing, knowledge discovery, and presentation layer operations to a great extent. In the text mining preprocessing tasks, domain knowledge can be used to enhance concept extraction and validation activities. Access to background knowledge can play an important role in the development of more meaningful, consistent, and normalized concept hierarchies. Advanced text mining applications, by relating features by way of lexicons and ontologies, can create fuller representations of document collections in preprocessing operations and support enhanced query and refinement functionalities. In fact, in a text mining system different components can make use of the information contained in the background knowledge. Background knowledge is an important add-on to classification and concept-extraction methodologies and can also be leveraged to enhance core mining algorithms and browsing operations. In addition, domain-oriented information serves as one of the main bases for search refinement techniques. Furthermore background knowledge may be used to construct meaningful constraints in knowledge discovery operations. Likewise, background knowledge may also be used to formulate constraints that allow users greater flexibility when browsing large result sets.
Business Applications
Text mining can be used in the following business sectors:
- Publishing and media.
- Telecommunications, energy and other services industries.
- Information technology sector and Internet.
- Banks, insurance and financial markets.
- Political institutions, political analysts, public administration and legal documents.
- Pharmaceutical and research companies and healthcare.
We will describe a few of the business application widely used in specific business areas.
a. Knowledge and Human Resource Management
The following are a few applications in this area:
i. Competitive Intelligence
Organizations today are very keen to know about their performance in the market with respect to the products and services they offer to its customers. They want to collect information about themselves in order to find out if there is any need to reorganize and restructure their strategies according to market demands and also to the opportunities that the market presents. In addition to this they are also interested in collecting the information about the market and their competitors. They also have to manage huge collection of data, process and analyze this data to get useful insights and make new plans. The goal of Competitive Intelligence is to extract only relevant information from various relevant data sources. Once the material is collected, it is classified into categories to develop a database, and analyzing the database to get answers to specific and crucial information for company strategies.
The typical queries concern the products, the sectors of investment of the competitors, the partnerships existing in markets, the relevant financial indicators, and the names of the employees of a company with a certain profile of competencies. Organizations, prior to having a text mining system, would have a department that would dedicatedly look into the continuous monitoring of information (financial, geopolitical, technical and economic) and answer the queries coming from the different business areas by the use of manual operation. The process of manually compiling documents according to a user's needs and preferences and into actionable reports is very labor intensive, and is greatly amplified when it needs to be updated frequently. With the introduction of text mining systems the return on investment was evident when compared to results previously achieved by manual operators.
ii. Human resource management
Text mining techniques are also used to manage human resources strategically, mainly with applications aiming at analyzing staff’s opinions, monitoring the level of employee satisfaction, as well as reading and storing CVs for the selection of new personnel. In the context of human resources management, the TM techniques are often utilized to monitor the state of health of a company by means of the systematic analysis of informal documents.
b. Customer Relationship Management (CRM)
Text mining in CRM domain is most widely used in the areas related to the management and analysis of the contents of client’s messages. This kind of analysis often aims at automatically rerouting specific requests to the appropriate service or at supplying immediate answers to the most frequently asked questions. Services research has emerged as a green field area for application of advances in computer science and IT.
CRM practices, particularly contact centers (call centers) in our context, have emerged as hotbeds for application of innovations in the areas of knowledge management, analytics, and data mining. Unstructured text documents produced from a variety of sources in today contact centers have exploded in terms of the sheer volume generated. Companies are increasingly looking to understand and analyze this content to derive operational and business insights. The customer, the end consumer of products and services, is receiving increased attention.
Business analytics applications revolving around customers have led to emergence of areas like customer experience management, customer relationship management, and customer service quality. These are becoming critical to competitive growth, and sometimes even, survival. Applications with such customer focus are most evident in services companies especially CRM practices and contact centers.
c. Market Analysis
Text mining in Market Analysis is used mainly to monitor customer’s opinion to identify new potential customers, analyze competitors and determine the organization’s image by analyzing press reviews and other relevant sources. Most of the organization indulge in tele-marketing and e-mail activities to acquire new customers. With the introduction of text mining systems organizations are able to answer the queries related to more complex market scenarios.
Data mining technology have helped us in extracting useful information from various databases. Data warehouses turned out to be successful for numerical information, but failed when it came to textual information. The 21st century has taken us beyond the limited amount of information on the web. This is good in one way that more information would provide greater awareness, and better knowledge. The knowledge of marketing information is available on the web by means of industry white papers, academic publications relating to markets, trade journals, market news articles, reviews, and even public opinions when it comes down to customer requirements.
Text mining technology can help marketing professionals to use this information to get useful insights.
Market Analysis includes the following:
Where are the data sources for analysis?
Credit card transactions, loyalty cards, discount coupons, customer complaint calls, plus (public) lifestyle studies.
Target marketing:
Find clusters of “model” customers who share the same characteristics: interest, income level, spending habits, etc.
Determine customer purchasing patterns over time:
Conversion of single to a joint bank account: marriage, etc.
Cross-market analysis:
- Associations/co-relations between product sales
- Prediction based on the association information
- Finance planning and asset evaluation
d. Warranty or insurance claims, diagnostic medical interviews, etc.
In certain business areas, the bulk of the information available is in an undefined textual form. For example, during warranty or insurance claims, claimant will be interviewed by an insurance agent and he will take note of all the details related to the claim in the form of a brief description. Similarly during patient medical interviews, the attendant will take down a brief description of the patient’s health issues or when you take your vehicle for repairs to the service station, the attendant will take down some notes about the issues you highlight and what needs to be repaired. These notes are then collected electronically and are input into the text mining systems. This information can be exploited to identify common cluster of problems and complaints on certain vehicles, etc. Similarly in the medical field useful information can be extracted from the collected open-ended descriptions about patient’s disease symptoms, which could be helpful in actual medical diagnosis.
e. Sentiment Analysis
Sentiment analysis or opinion mining is a natural language processing or information extraction tasks that helps extract pro or anti opinions or feelings expressed by a writer in a document collection. In general, the goal of the sentiment analysis is to obtain the writers outlook about several topics or overall contextual polarity contained in a document. The writer’s outlook may be because of the knowledge he or she possess, his or her emotional state while writing or the intended emotional touch the writer wants to present to the reader.
The sentiments in sentiment analysis can be obtained at document level by classifying the polarity of the expressed opinion in the text of a document, at the sentence or entity feature level to find out if the opinion expressed is positive, negative or neutral. Further sentiment classification can also be done on the basis of the emotional state expressed by the writer like (glad, dejected, and annoyed). Sentiment analysis can also be done on the basis of objective or subjective opinions expresses by a writer. Sentiment Analysis identifies the phrases in a text that bears some sentiment. The author may speak about some objective facts or subjective opinions. It is necessary to distinguish between the two. SA finds the subject towards whom the sentiments are directed. A text may contain many entities but it is necessary to find the entity towards which the sentiments are directed. It identifies the polarity and degree of the sentiment. Sentiments are classified as objective (facts), positive (denotes a state of happiness, bliss or satisfaction on part of the writer) or negative (denotes a state of sorrow, dejection or disappointment on part of the writer).
Another way of capturing sentiments is by using scoring method where sentiments are given a score based on their degree of positivity, negativity or objectivity. In this method a piece of text is an analyzed and subsequent analysis of the concepts contained in the text is carried out to understand the sentimental words and how these words relate to concepts. Each concept is then given a score based on the relation between the sentimental words and the associated concepts.
Sentiment analysis also called voice of customer plays a major role in customer buying decisions. Internet usage has seen an exponential rise in the past few years, and the fact that a large no of people share their opinions on the internet, is a motivating factor for using sentiment analysis for commercial purposes. Consumers often share their attitudes, reactions or opinions about businesses, products and services on the social networking sites. Consumers naturally get influenced by the opinions expressed on the online resources like review sites, blogs, and social networking sites to make buying decisions. Sentiment analysis can therefore be used in marketing for knowing consumer attitudes and trends, consumer markets for product reviews and social media to find out general opinion about recent hot topics.
Algorithms/Models for business applications
This section describes various algorithms/models used for some of the business applications.
a. Clustering algorithms
Clustering models can be used for customer segmentation, analyze behavioral data, identify the customer groups and suggest a solution based on the data paterns. Clustering algorithms include:
i. K-mean
This is an efficient and perhaps the fastest clustering algorithm that can handle both long (many records) and wide datasets (many data dimensions and input fields). It is a distance-based clustering technique The number of clusters to be formed is predetermined and specified by the user in advance. Usually a number of different solutions should be tried and evaluated before approving the most appropriate. It is best for handling continuous clustering fields.
ii. TwoStep
As its name implies, this scalable and efficient clustering model, processes records in two steps. The first step of pre-clustering makes a single pass through the data and assigns records to a limited set of initial sub-clusters. In the second step, initial sub-clusters are further grouped, through hierarchical clustering, into the final segments. It suggests a clustering solution by automatic clustering: the optimal number of clusters can be automatically determined by the algorithm according to specific criteria.
iii. Kohonen network/ self organizing maps
Kohonen networks are based on neural networks and typically produce a two-dimensional grid or map of the clusters, hence the name self-organizing maps. Kohonen networks usually take a longer time to train than the K-means and TwoStep algorithms, but they provide a different view on clustering that is worth trying.
b. Acquisition models
Acquisition models can be used to identify profitable prospective customers who have similar characteristics to those of the already existing valuable customers.
c. Cross-sell and up-sell models
These models can be used to identify existing customers who have the purchasing potential to buy recommended similar or upgraded products. Attrition models can be used to identify the customers who are highly likely to leave the relationship.
d. Classification algorithms
Classification algorithms can be used for acquisition/Cross-sell/up-sell/attrition models, which include:
i. Neural networks
Neural networks are powerful machine learning algorithms that use complex, nonlinear mapping functions for estimation and classification.
These models estimate weights that connect predictors (input layer) to the output. Input records, with known outcomes, are presented to the network and model prediction is evaluated with respect to the observed results. Observed errors are used to adjust and optimize the initial weight estimates.
ii. decision trees
Decision trees operate by recursively splitting the initial population. For each split they automatically select the most significant predictor, the predictor that yields the best separation with respect to the target field. Through successive partitions, their goal is to produce ‘‘pure’’ sub-segments, with homogeneous behavior in terms of the output. They are perhaps the most popular classification technique. Part of their popularity is because they produce transparent results that are easily interpretable, offering an insight into the event under study.
iii. logistic regression
This is a powerful and well-established statistical technique that estimates the probabilities of the target categories. It is analogous to simple linear regression but for categorical outcomes. It uses the generalized linear model and calculates regression coefficients that represent the effect of predictors on the probabilities of the categories of the target field. Logistic regression results are in the form of continuous functions that estimate the probability of membership in each target outcome.
iv. Bayesian networks
Bayesian models are probability models that can be used in classification problems to estimate the likelihood of occurrences. They are graphical models that provide a visual representation of the attribute relationships, ensuring transparency, and an explanation of the model’s rationale.
e. Association models
Association models can be used to identify the related products which are typically purchased together and also identifying the products that can be sold together. By using association analysis customers can be offered associated products if they buy a particular product. Association alorithms include:
i. A priori
A priori is a classic algorithm for learning association rules. A priori is designed to operate on databases containing transactions (for example, collections of items bought by customers, or details of a website frequentation). The purpose of the A priori Algorithm is to find associations between different sets of data and is to extract useful information from large amounts of data. For example, the information that a customer who purchases a particular product also tends to buy an associated product at the same time is acquired from the association rule.
ii. sequence models
Sequence modeling techniques are used to identify associations of events/ purchases/attributes over time. Sequence models take into account the order of actions/purchases and can identify sequences of events like when certain things happen in a specific order, a specific event has an increased probability of occurring next. The techniques can also be used as a means for predicting the next expected ‘‘move’’ of the customers.
Text mining tools
In this section we will present the features, techniques used and business applications of some the commercial and open source text mining tools available in the market.
a. Commercial text mining tools
| Text Mining Tools | Features, Techniques and Applications |
| Angoss | Angoss uses techniques such as entity and theme extraction, topic categorization, sentiment analysis and document summarization. This tool merges the output of unstructured, text-based analysis with structured data to provide additional predictive variables for improved predictive models and association analysis. Angoss helps businesses discover valuable insight and intelligence from their data while providing clear and detailed recommendations on the best and most profitable opportunities to pursue to improve sales, marketing and risk performance. Its application areas include: Customer Segmentation, Customer Acquisition, Cross-Sell / Upsell Next-Best Offer, Channel performance, Churn / Loyalty to improve customer retention and loyalty, Sales Productivity improvement etc. |
| Attensity | This tool has the capability to extracts facts, relationships and sentiment from unstructured data and provides social analytics and engagement applications for Social Customer Relationship Management. This tool uses natural language processing technology to address collective intelligence in blogs, online forums and social media, the voice of the customer in surveys and emails, Customer Experience Management, e-services, research and e-discovery risk and compliance and intelligence analysis. |
| Autonomy | This tool uses clustering, categorization and pattern recognition (centered on Bayesian inference) techniques. Application areas include enterprise search and knowledge management |
| Basis | This tool uses the techniques like words/tokens/phrases/entity search, entity extraction, entity translation and NLP techniques for information retrieval, text mining and search engines. This tool uses artificial intelligence techniques to understand text written in different languages. Basis tools are widely used in forensic analysis and help identify and extract clues from data storage devices like hard disks or flash cards, as well as devices such as smart phones. |
| Clarabridge | Clarabridge uses techniques like natural language (NLP), machine learning, clustering and categorization. This tool is widely used for CRM and sentiment analysis. |
| Cogito | Cogito suite of products owned by Expert systems use techniques such as natural language search, automatic categorization, data/metadata extraction and natural language processing. Application areas include CRM, Product development, marketing etc. |
| IBM SPSS | IBM SPSS text analytics tool uses advanced NLP based techniques like multi-lingual sentiment, event and fact extraction, categorization etc. SPSS is widely used for statistical analysis for social science. Its application areas include market research, health research, surveys, marketing etc. |
| Inxight(SAP) | Inxight uses natural language processing, Information retrieval, categorization and summarization and clustering techniques. This tool has the capability to indentify stems, parts of speech, and noun phrases. It also identifies entities and grammatical patterns, such as facts, events, relations, and sentiment from text. Inxight is used in the analysis of customer interactions in call centers and online customer chat sessions, This analysis can uncover customer dissatisfaction and product and pricing issues earlier, resulting in faster, proactive product changes and customer communications. Inxight’s text analytics is also being used to uncover risk areas in email, such as private or sensitive data leaving an organization in violation of internal or externally mandated policy. |
| Lexalytics | Lexanlytics uses natural language processing techniques to extract entities (people, places, companies, products, etc.), sentiment, quotes, opinions, and themes (generally noun phrases) from text. Lexalytics text analytics engine is used in Social Media Monitoring, Voice of Customer, Survey Analysis, pharmaceutical research and development and other applications. |
| Megaputer | Megaputer provided techniques like linguistic and semantic information retrieval, clustering and categorization of documents, summarization, entity extraction, visualization of patterns. Megaputers application areas include: survey analysis, call center analysis, complaint analysis, competitive intelligence, market segmentation, cross sell analysis, fraud detection, risk assessment etc. |
| SAS Text Miner | SAS Text Miner is an add-on for the SAS Enterprise Miner environment. SAS uses information retrieval, information extraction, categorization and summarization techniques to extract useful information from text. SAS Text miner’s capabilities include: stemming; automatic recognition of multi-word terms; normalization of various entities such as dates, currencies, percentages, and years; part-of-speech tagging; extraction of entities such as organizations, products, Social Security numbers, time, titles, etc.; support for synonyms; language-specific analysis. SAS text miner’s application areas include: filtering e-mail; grouping documents by topic into predefined categories; routing news items; clustering analysis of research papers in a database, survey data and customer complaints and comments; predicting stock market prices from business news announcements; predicting customer satisfaction from customer comments; predicting costs based on call center logs. |
| VantagePoint | VantagePoint is desk top Text Mining Software for Discovering Knowledge in virtually any Structured Text Database. It uses natural language processing techniques to extract words/phrases from the established relationships between them. It uses Co-word Bibliometrics/Co-occurrence statistics to find relationships. VantagePoint enables you to quickly find WHO, WHAT, WHEN and WHERE, enabling you to clarify relationships and find critical patterns—turning your information into knowledge. |
| DiscoverText | DiscoverText is a cloud-based, collaborative text analytics solution which has the capability to generate valuable insights about customers, products, employees, news, citizens, and more. With dozens of powerful text mining features, the DiscoverText software solution provides tools to quickly and accurately make better decisions. DiscoverText’s concept extraction and unique active-learning can handle a sea of social media, thousands of survey responses, streams of customer service requests, e-mail, or other electronic text. |
| Eaagle | Eaagle is a software company providing leading text mining technology to CRM, Marketing and Research professionals. Eaagle is an online service that automatically and objectively analyzes and categorizes verbatim, without any pre requisites and creates automatic reports like charts, words cloud, and an exclusive mobile browser compatible report that your clients will discover on their iPad or Smartphone. Eaagle Full Text Mapper automatically MAPS data and enables you to analyze sets of full text data by topics, and also to generate customized report. |
b. Open source text mining tools
| Text Mining Tools | Features, Techniques and Applications |
| Gate | GATE (General Architecture for Text Engineering) is an open-source toolbox for natural language processing and language engineering. Gate uses information extraction and machine learning techniques to extract useful information from text. Gate’s information extraction component called ANNIE consists of tokenizer, a gazetteer, a sentence splitter, a part of speech tagger, a named entities transducer and a coreference tagger. A few of the application areas include drug research, cancer research, recruitment and decision support. |
| RapidMiner | RapidMiner’s Text Extension adds all operators necessary for statistical text analysis. You can load texts from different data sources or from your data sets, transform then by a huge set of different filtering techniques, and finally analyze your text data. The Text Extensions supports several text formats including plain text, HTML, or PDF. It also provides standard filters for tokenization, stemming, stopword filtering, or n-gram generation. |
| OpenNLP | The Apache OpenNLP library is a machine learning based toolkit for the processing of natural language text. It supports the most common NLP tasks, such as tokenization, sentence segmentation, part-of-speech tagging, named entity extraction, chunking, parsing, and coreference resolution. |
| Carrot2 | Carrot2 is an open source search results clustering engine. It can automatically cluster small collections of documents, e.g. search results or document abstracts, into thematic categories. Apart from two specialized search results clustering algorithms, Carrot2 offers ready-to-use components for fetching search results from various sources. |
| NLTK | NLTK (The Natural Language Toolkit) is a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for the Python programming language. NLTK includes graphical demonstrations and sample data. NLTK is intended to support research and teaching in NLP or closely related areas, including empirical linguistics, cognitive science, artificial intelligence, information retrieval, and machine learning. NLTK has been used successfully as a teaching tool, as an individual study tool, and as a platform for prototyping and building research systems. |
| The programming language “R” | The programming language “R” provides a framework for text mining applications in the package tm. |
References
1. The Text Mining Handbook—Advanced Approaches in Analyzing Unstructured Data – Ronen Feldman, James Sanger.
2. Tapping into the Power of Text Mining – Weiguo Fan, Linda Wallace, Stephanie Rich, and Zhongju Zhang.
3. A Survey of Text Mining Techniques and Applications -- Vishal Gupta, Gurpreet S. Lehal.
4. Unsupervised cleansing of noisy text – Danish Contractor, Tanveer A. Faruquie, Venkata Subramaniam.
5. Text Analytics – Beginner’s Guide – Agnoss.
6. Text Analytics – Sentiment Extraction – Measuring the Emotional Tone of Content – Agnoss.
7. Experiments with artificially generated noise for cleansing noisy text – Phani Gadde, Rahul Goutam, Rakshit Shah, Hemanth Sagar, L. V. Subramaniam.
8. A comaparative study of Feature Selection in Text Categorization – Yiming Yang, Jan O. Pedersen.
9. http://searchbusinessanalytics.techtarget.com/definition/t ext-mining.
10. http://guides.library.duke.edu/content.php?pid=383688&s id=3143978.
11. http://en.wikipedia.org/wiki/Stop_words.
12. http://en.wikipedia.org/wiki/Stemming.
13. http://consultingblogs.emc.com/manjunathasubbarya/arc hive/2011/03/04/stemming-and-lemmatization.aspx.
14. http://www.techopedia.com/definition/13698/tokenizatio n.
15. http://en.wikipedia.org/wiki/Tokenization
Conclusion
Text mining is a growing technology area that is in its early days and having its own inherent complexities, similar to any emerging technology before the terms and concepts related to it are standardized. There is no accepted/definite depiction of what it should cover because of the fact that it covers different techniques to handle different problems in the text under consideration. Likewise, different text mining tools available in the market vary widely and take a slightly different path. Some fundamental text mining techniques like entity extraction, relationship between the entities, categorization, classification, summarization etc., have undergone a plenty of research and study and are apt at uncovering useful information from plain text. However, with a lot of information available on the internet presents more challenges and opportunities and more research and study needs to be done in this area. Since text mining is also considered a sibling of data mining some of the major vendors, already having data mining capabilities, are clubbing text mining with data mining to extend the value of knowledge discovery from the data. Automatic text mining techniques have a long way to go before they equal the ability of people to discover the knowledge from textual data, even without using any specific domain knowledge.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




