Introduction
A computer algebra system (CAS) is a software program that facilitates symbolic mathematics. The core functionality of a CAS is manipulation of mathematical expressions in symbolic form. Usually, to perform such manipulations, the original data are represented as syntax trees and then they are transformed using some rules. The main aim of this project is to provide flexible and comfortable way to specify such transformation rules.
Many CAS systems are developed either small research projects and enterprise software. However, no one is implemented in .NET framework, which is a modern programming technology, widely used for research, education and software development. To our knowledge, only one .NET solution exists, named Math.NET. However, it could hardly considered as a full-fledged computer algebra system. Transformation rules are not programmed as a separate entity, and are substituted by Visitor pattern that processes nodes in a tree according to its function. This decision hampers the system’s expanding, because addition of new operations demands alterations in the existed code. Moreover, even operations like the differentiation of the exponential function are still not implemented.
To develop a computer algebra system, we need to build convenient and reliable framework for rules definition and application. Such frameworks are the core part of all existed CAS. In this work, we present our solution for this task, based on .NET framework. We do not have an objective to write enterprise computer algebra software, because the market already has many solutions. However, we believe that our solution will be useful in research area, because it gives an opportunity to work with symbolic computations with a modern and effective programming languages. Also, as we will see below, .NET framework and C# language provides several syntax features, which facilitate definition of transformational rules. The usage such features for transformation rules programming gives a fresh look on symbolic computations, and could be resulted in new approaches to computer algebra systems.
Rule definition
Application of the rule can be subdivided into the three stages. In sampling stage, the system that applies rules (which will be called driver below) selects some tree-like structure from the syntax tree, and presents its nodes as a tuple. In selection stage, the driver sort out the tuples that do not meet the specified criteria. In third stage, called modification, the driver transforms the tree according to the rule. In the most widespread case, the rule processes one tree. For such unary rules, the original tree is copied, and then the copy is rearranged according to rule. In some cases, the rule processes more than one tree. For example, in logical interference modus ponens rule accepts two trees A → B and A and produces B. In this case, new tree is to be created and built with nodes copies from selected tuple. Since the driver always copies the nodes before manipulation, the correctness of initial trees is preserved.
Sampling
To perform the sampling stage, we should specify the tree-like structure we search in a tree. Also, we need to map the nodes in the structure into a tuple of nodes. We used query strings of our own syntax to do that. Let us demonstrate the syntax of query string with the following example. Consider syntax tree in the Figure 1. In the Table 1, we present various query string, along with corresponded selections and comments.

Figure 1: Syntax tree
Table 1: Query string examples| Query String | Tuples | Comment |
|---|
| A | (1) | The root of the tree |
| ?A | (1),(2),(3),(4),(5),(6) | An arbitrary node in a tree |
| ?A(B) | (5,6) | An arbitrary node, that has only one child, and this child |
| ?A(B,C) | (1,2,5), (2,3,4) | An arbitrary node in a tree with its two children in fixed order |
| ?A(.B,.C) | (1,2,5), (1,5,2), (2,3,4), (2,4,3) | An arbitrary node with its two children in unconditioned order |
| ?A(.B) | (1,2), (2,3), (2,4), (5,6) | An arbitrary node with its one child |
| ?A(?B) | (1,2), (1,3), (1,4), (1,5), (1,6), (2,3), (2,4), (5,6) | An arbitrary node with its arbitrary descendant |
| ?A(?B(?C)) | (1,2,3), (1,2,4), (1,5,6) | An arbitrary node, its descendant and descendant of the descendant |
| ?A(?B(C,D)) | (1,2,3,4) | An arbitrary node that has a descendant with two child |
The sampling algorithm is a depth-search algorithm that builds a correspondence between a given tree and a parsed tree of query string. To encode the rule, we should specify the query string in the program. It could be done by coding of query as a constant string. However, it is not convenient due to possible mistakes in query syntax, such as wrong brackets match or incorrect letters. To eliminate such errors, we implement query strings definition with square brackets overriding. So now, you can encode the rule, using following syntax:
Select(AnyA[ChildB, ChildC]);
Selection
The selection stage can be further subdivided into type selection and custom selection. Type selection checks the types of nodes in the selected tuple and rejects the tuple in the case of mismatch. Custom selection can check additional condition, e.g. value of the constant. Type selection must be performed prior to custom selection, because the possibility of custom selection depends of the node’s type. For example, to check that the constant value is zero, we have to be sure that the node corresponds to a constant, and not to an operator.
When programming selection, a challenge emerges of how to provide the tuple to selection condition. We cannot store selected nodes in array or list structures, because it does not allow to specify different types for elements. With array representation, selection could only performed as this:
( array => array[0] is Plus && array[1] is Constant && (array[1] as Constant).Value==0 );
Of course, constant casting and addressing is a potential cause of type errors. We have developed an elegant solution for selection with the aid of generic-methods and code generation. For this functionality responds method Rule.SelectWhere, which takes array of INode, generates IEnumerable<SelectOutput> and passes this enumeration to delegate where with type Func<SelectOutput,WhereOutput>. This delegate verify the matching of the tuple to the filter and generates WhereOutput object, corresponding to the filtered tuple.
Modification
When selection stage is over, we obtain several tuples that could be modified in the modification stage. However, only one of them will be actually processed, because application of the rule may invalidate other tuples. Therefore, modification stage processes only one of the selected tuples. We have developed a "clean" modification, which does not affect the initial trees. Instead, in the modification stage we create a copy of selected trees, and perform modification on the copy. To do that, we must find the roots of nodes, presented in a given tuple, clone them, and further process a newly created tuple with a corresponding clones of nodes.
For this functionality responds method Rule.Apply, which takes WhereOutput object. Than it makes copy of this object through method WhereOutput.MakeSafe and passes this copy to delegate apply, where modification performs.
Creating new rule
Full rule definition looks like this:
Rule
.New("+0", StdTags.Algebraic, StdTags.Simplification, StdTags.SafeResection)
.Select(AnyA[ChildB, ChildC])
.Where<Arithmetic.Plus<double>, Constant<double>, INode>(z => z.B.Value == 0)
.Mod(z => z.A.Replace(z.C.Node));
This rule looks for subtrees X+0 or 0+X and replaces them with X. We have already defined a few collections of rules to implement some functionality and further we will tell you what exactly you can do with the system to date.
Simplification and Differentiation
You can find rules for simplification and differentiation in classes AlgebraicRules and DifferentiationRules accordingly. To simplify an expression with existing rules use the method ComputerAlgebra.Simplify like this:
Expression<del4 /> expression = (x, y, z, u) => (x+42)/1 + y*0/(z-0) + 43 - Math.Pow(x, 0) * Math.Pow(u, 1)/(0+5);
var result = ComputerAlgebra.Simplify(expression);
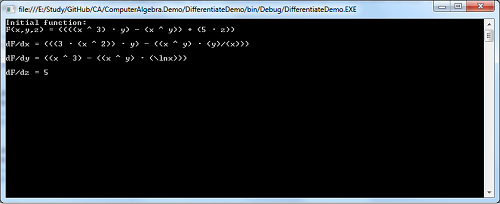
To find the partial derivatives of a function use method ComputerAlgebra.Differentiate:
Expression<del3 /> function = (x, y, z) => Math.Pow(x, 3)*y - Math.Pow(x, y)+5*z;
var result = ComputerAlgebra.Differentiate(function, variable: "z");
Here you must define the variable of differentiation. In our example it is z.
You can find examples of this functionalities in projects SimplificationDemo, DifferentiateDemo, and in the test classes SimpleTests, DifferentiationTest.
Regression
The first aim of our research was symbolic regression task, where we used simplification rules to improve the existed solutions of evolutionary symbolic computations. In symbolic regression, genetic algorithm processes expressions with mutation and crossover, and gradually creates the expression that fits experimental data. Constants in expressions are found also by mutation. We improve this part of algorithm with standard well-known numerical regression. Suppose the algorithm has found function F(x1,...,xn) as the potential solution. Let Φ(x1,...,xn,c1,...,cm) be a function F where constants are replaced with arguments ci. Let E(c1,...,cm) be an error function:
where the set is the experimental data. With differentiation rules, we can calculate and improve ci with gradient descent so Φ fits experimental data better. This technique is experimentally tested and proved to be better than finding constants with genetic algorithm.
We have decided to split evolutionary algorithms and symbolic computation, so now you can use numerical regression regardless of the genetic algorithm. To do that you should create new instance of RegressionAlgorithm class and call method Run(). The constructor of RegressionAlgorithm takes expression, experimental data, accurance, and initial step for gradient descent. You can find the examples of this in RegressionDemo project and RegressionTests class.
Resolution
The resolution technique is very simple:
- Find two clauses containing the same predicate, where it is negated in one clause but not in the other.
- Perform a unification on the two predicates. (If the unification fails, you made a bad choice of predicates. Go back to the previous step and try again.)
- If unbound variables which were bound in the unified predicates also occur in other predicates in the two clauses, replace them with their bound values (terms) there as well.
- Discard the unified predicates, and combine the remaining ones from the two clauses into a new clause, also joined by the ∨ operator.
All predicates must be in Skolem normal form, therefore we need some tool to define the quantifier-free part of such predicates. To do that we have generated several methods and constants. So now, we can define formulas in the following form:
Expression<del2> clause = (x, y) => P(a, x, f(g(y))) | !Q(x) | R(b);
The algorithm of unification is implemented in the UnificationService class. It's very simple, so we will not describe it here.
The main part of this technique, the resolution rule, is implemented as a standard rule of this system:
Rule
.New("Resolve", StdTags.Inductive, StdTags.Logic, StdTags.SafeResection)
.Select(A[ChildB], C[ChildD])
.Where<Logic.MultipleOr, SkolemPredicateNode, Logic.MultipleOr,
SkolemPredicateNode>(z => UnificationService.CanUnificate(z.B, z.D) &&
(z.B.IsNegate || z.D.IsNegate))
.Mod(Modificator);
Where the Modificator method performs a unification on the two predicates and combine the remaining ones from the two clauses into a new clause.
To get the list of possible resolvents of the two predicates you must use the method ComputerAlgebra.Resolve like this:
Expression<del1 /> node1 = (x) => P(x) | !Q(x);
Expression<del1 /> node2 = (x) => !P(x) | Q(x);
var result = ComputerAlgebra.Resolve(Expressions2LogicTree.Parse(node1),
Expressions2LogicTree.Parse(node2));
And, as usual, you can find examples in the project ResolutionDemo and in the test class ResolutionTests.
Further development
This project is fully research: all further development will be performed by the next generation of students. If they get some interesting results, they surely will write new article.
If you find this topic interesting, we will be glad if you will use our system for your own research.
History
- 9 June, 2013 -- Original version posted.
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 










