Introduction
Developing consistent and meaningful benchmark results for code is a complex
task. In my first article (Celero - A C++ Benchmark Authoring Library),
I discussed how to use Celero to measure the performance of algorithms in C++. Here, I will discuss how to use Celero
to understand how a given algorithm scales with respect to its problem size.

This article assumes a basic knowledge of Celero and intermediate knowledge of
C++.
Background
It has been noted many times that writing an algorithm to solve small problems
is relatively easy. "Brute force" methods tend to function just as well as
more graceful approaches. However, as the size of data increases, truly
effective algorithms scale their performance to match.
Theoretically, the best we can hope for with an algorithm is that is scales
lineally (Order N, O(N) complexity) with respect to the problem size.
That is to say that if the problem set doubles, the time it takes for the
algorithm to execute doubles. While this seems obvious, it is often an
elusive goal.
Even well performing algorithms eventually run into problems with available
memory or CPU cache. When making decisions within our software about
algorithms and improvements to existing code, only through measurement and
experimentation can we know our complex algorithms perform acceptably.
Using the code
While Celero offers simple benchmarking of code and algorithms, it also
offers a more complex method or directly producing performance graphs of how the
benchmarks change with respect to some independent variable, referred to here as
the Problem Set.
Within Celero, a test fixture can push integers into a ProblemSetValues
vector which allows for the fixture's own SetUp function to scale a problem set
for the benchmarks to run against. For each value pushed into the
ProblemSetValues vector, a complete set of benchmarks is executed. These
measured values are then stored and can be written out to a CSV file for easy
plotting of results.
To demonstrate, we will study the performance of three common sorting
algorithms: BubbleSort, SelectionSort, and std::sort. (The source code to
this demo is distributed with Celero, available on
GitHub.) First, we
will write a test fixture for Celero.
class DemoSortFixture : public celero::TestFixture
{
public:
DemoSortFixture()
{
const int totalNumberOfTests = 12;
for(int i = 0; i < totalNumberOfTests; i++)
{
this->ProblemSetValues.push_back(static_cast<int32_t>(pow(2, i+1)));
}
}
virtual void SetUp(const int32_t problemSetValue)
{
this->arraySize = problemSetValue;
for(int i = 0; i < this->arraySize; i++)
{
this->array.push_back(rand());
}
}
virtual void TearDown()
{
this->array.clear();
}
std::vector<int> array;
int arraySize;
};
The constructor defines the experiment size, totalNumberOfTests This number can be changed at will to adjust how many values are pushed into
the ProblemSetValues array. Celero uses this array internally when calling the fixture's SetUp() virtual function.
The SetUp() virtual function is called before each benchmark
test is executed. When using a ProblemSetValues array, the
function will be given a value that was previously pushed into the array within
the constructor. The function's code can then decide what to do with it.
Here, we are using the value to indicate how many elements should be in the
array that we intend to sort. For each of the array elements, we simply
add a pseudo-random integer.
Now for implementing the actual sorting algorithms. For the baseline
case, I implemented the first sorting algorithm I ever learned in school:
Bubble
Sort. The code for bubble sort is straight forward.
BASELINE_F(DemoSort, BubbleSort, DemoSortFixture, 0, 10000)
{
for(int x = 0; x < this->arraySize; x++)
{
for(int y = 0; y < this->arraySize - 1; y++)
{
if(this->array[y] > this->array[y+1])
{
std::swap(this->array[y], this->array[y+1]);
}
}
}
}
Celero will use the values from this baseline when computing a base lined
measurement for the other two algorithms in the test group "DemoSort".
However, when we run this at the command line, we will specify an output file.
The output file will contain the measured number of seconds the algorithm took
to execute on the given array size.
Next, we will implement the Selection Sort algorithm.
BENCHMARK_F(DemoSort, SelectionSort, DemoSortFixture, 0, 10000)
{
for(int x = 0; x < this->arraySize; x++)
{
auto minIdx = x;
for(int y = x; y < this->arraySize; y++)
{
if(this->array[minIdx] > this->array[y])
{
minIdx = y;
}
}
std::swap(this->array[x], this->array[minIdx]);
}
}
Finally, for good measure, we will simply use the Standard Library's sorting algorithm:
Introsort*.
We only need write a single line of code, but here it is for completeness.
BENCHMARK_F(DemoSort, stdSort, DemoSortFixture, 0, 10000)
{
std::sort(this->array.begin(), this->array.end());
}
Results
This test was ran on a 4.00 GHz AMD with four cores, eight logical
processors, and 32 GB of memory. (Hardware aside, the relative performance
of these algorithms should be the same on any modern hardware.)
Celero outputs timing and benchmark references for each test automatically.
However, to write to an output file for easy plotting, simply specify an output
file on the command line.
>celeroDemo results.csv
While not
particularly surprising std::sort is by far the best option with any meaningful
problem set size. The results are summarized in the following table output
written directly by Celero:
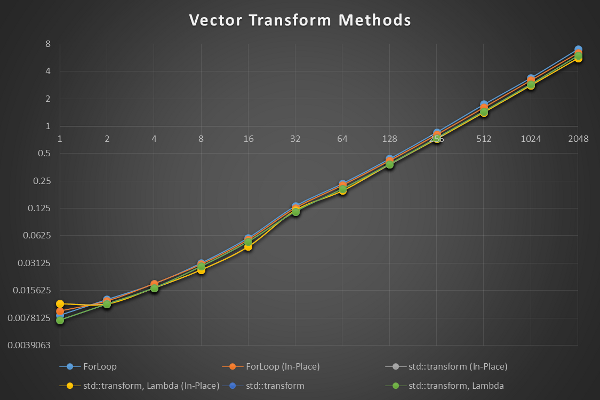
DemoTransform,,,,,,,,,,,,
,1,2,4,8,16,32,64,128,256,512,1024,2048
ForLoop,0.0084,0.0125,0.0186,0.0315,0.0595,0.133,0.2353,0.439,0.8607,1.7392,3.4112,7.0522
SelfForLoop,0.0093,0.012,0.0186,0.0304,0.0567,0.1265,0.225,0.4194,0.8096,1.6094,3.2035,6.4252
SelfStdTransform,0.0112,0.0113,0.0167,0.0265,0.0478,0.119,0.1953,0.3788,0.7257,1.4189,2.8082,5.5696
SelfStdTransformLambda,0.0112,0.0111,0.0167,0.0264,0.0474,0.119,0.1953,0.3822,0.7257,1.4192,2.8078,5.5707
StdTransform,0.0074,0.0111,0.0167,0.0288,0.0539,0.1153,0.2046,0.3832,0.7411,1.4555,2.8884,5.9487
StdTransformLambda,0.0074,0.0111,0.0167,0.0288,0.0539,0.1153,0.2046,0.3832,0.7411,1.4556,2.8915,5.9451
The data shows first the test group name. Next, all of the data sizes are output. Then each row shows
the baseline or benchmark name and the corresponding time for the algorithm to
complete measured in useconds. This data, in CSV format, can be directly
read by programs such as Microsoft Excel and plotted without any modification.
Note the table uses a log(2) scale for both axis.
The point here is not that std::sort is better than more elementary sorting
methods, but how easily measureable results can be obtained. In making
such measurements more accessible and easier to code, they can become part of
the way we code just as automated testing has become.
Test early and test often!
Points of Interest
* Because I like explicitness as much as the next programmer, I want to note
that the actual sorting algorithm used by std::sort is not defined in the
standard, but references cite Introsort as a likely contender for how an STL
implementation would approach std::sort. http://en.wikipedia.org/wiki/Introsort.
When choosing a sorting algorithm, start with std::sort and see if you can
make improvements from there.
Don't just trust your experience, measure your code!
Source Code Repository
The source code to this demo is distributed with Celero, available on GitHub.
John Farrier is a professional C++ software engineer that specializes in modeling, simulation, and architecture development.
Specialties:
LVC Modeling & Simulation
Software Engineering, C++11, C++98, C, C#, FORTRAN, Python
Software Performance Optimization
Software Requirements Development
Technical Project and Team Leadership





