Learn 30 Windows Multithreading Mistakes and Solutions to Avert Them To Make Your Program More Resilient
Table of Contents
Introduction
The motivation for writing this article came from a dentist visit. I had an intense toothache and had to take a 3D facial CT scan to diagnose it. The scan was running halfway. Then it stopped. And hanged. At this point, I wondered if the X-ray was still blasting onto my body, causing damage. The dentist commented the machine was from Germany as if mentioning German-origin technology absolves it of its fault.
A deadlock in multi-threading could have caused the hang. I then vowed to make a list of every multi-threading mistake. The intended audience is both novice and expert. Experts should be familiar with most mistakes, but they can still read the article for the knowledge gaps. Writing error-free threading code remains a challenge for most developers. Threading bugs are hard to reproduce reliably.
As the saying goes, prevention is the best cure. This article does not only help prevention. With knowledge from the article, developers can review their code again to narrow down and identify the root cause. This article focuses on C++ and Windows development. Every item is written so that the reader can understand the concept without getting lost in the minutiae of details. Prerequisites include a familiarity with C++ multi-threading and Windows Development.
1. Stack
A process is an instantiation of a program. A process cannot execute code by itself. It needs to have at least one thread to do so. Every thread comes with the default stack size of 1 megabyte. Some developers deem the amount as wasteful. We are taking a closer look at this topic in the item below.
1.1 Setting Stack Size Less Than 20 KB
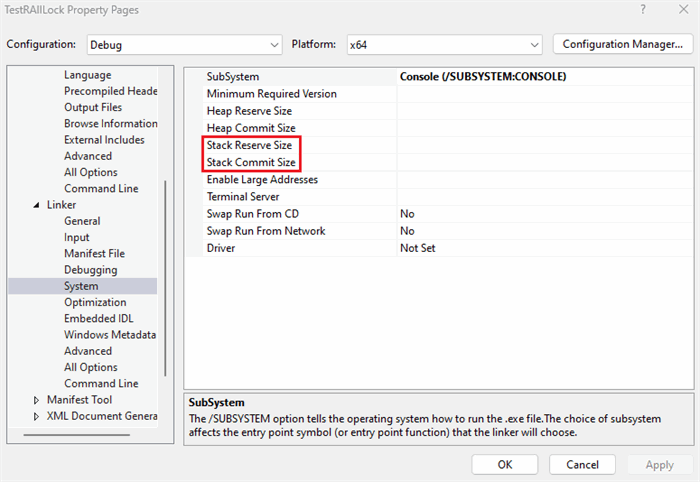
The default stack value can be adjusted in Visual Studio by going to the Project->Property Page->Linker->System->Stack Commit Size/Stack Reserve Size.
More often than not, the stack size is modified via dwStackSize parameter of CreateThread, CreateRemoteThread and CreateFiber. If zero is specified, the default size of the executable is used. When STACK_SIZE_PARAM_IS_A_RESERVATION is not in the dwCreationFlags parameter, dwStackSize is the commit size, not the reserved size. Only committed memory uses physical memory. Reserving memory informs Windows not to allocate in this address range as this range might be committed in the future. When the committed size is exceeded, more memory from the reserved range is committed. 95% of the default 1MB is reserved, so they do not touch the physical memory.
HANDLE CreateThread(
LPSECURITY_ATTRIBUTES lpThreadAttributes,
SIZE_T dwStackSize,
LPTHREAD_START_ROUTINE lpStartAddress,
LPVOID lpParameter,
DWORD dwCreationFlags,
LPDWORD lpThreadId
);
HANDLE CreateRemoteThread(
HANDLE hProcess,
LPSECURITY_ATTRIBUTES lpThreadAttributes,
SIZE_T dwStackSize,
LPTHREAD_START_ROUTINE lpStartAddress,
LPVOID lpParameter,
DWORD dwCreationFlags,
LPDWORD lpThreadId
);
LPVOID CreateFiber(
SIZE_T dwStackSize,
LPFIBER_START_ROUTINE lpStartAddress,
LPVOID lpParameter
);
Setting 20KB for both commit and reserved size is unadvisable. Your thread calls other code that may unexpectedly use more stack memory (example: a large local array) or recursion. Stack overflow can happen because the maximum it can expand is 20KB. Beware: When compiled with AddressSanitizer, there is an increased chance of stack overflow. If you want to limit stack size, at least choose a sensible 100KB.
If you are interested in the process of a stack’s reserved memory converting to committed memory, look no further than this blog post by Raymond Chen.
2. Data Corruption
The multi-threaded program exhibits strange behavior when data is corrupted. Because in a single-threaded program, code is executed sequentially versus concurrently in a multi-threaded program. These bugs can be hard to trace. Here, we examine corruption bugs.
2.1 Using Out-Of-Scope Local Variable Passed to the Thread
When the address or reference of a local variable declared on the stack is passed to the worker thread, the local variable may go out of scope before the thread starts. This is an intermittent problem. The solutions are listed below.
- Use a member variable but it can constitute data race when two threads are created in an instant and their variable value varies.
- Allocate the variable on the heap but do remember to deallocate it inside the thread after use.
- Capture the variable by copy to the lambda
I experienced this bug first-hand on my slide-show application. The video-encoding thread crashes once after every few runs. However, the GUI looks fine. Initially, I dismissed it as a glitch. Then, it crashed a few more times. I took a closer look and was able to nail down the problem to an out-of-scope string.
2.2 Using Boolean as a Synchronization Primitive
This is a classic beginner mistake. The C++ compiler can reorder the write instructions before or after the boolean guard because there is no memory barrier or fence erected for boolean. The solution is always synchronize using the mutex or atomic variable.
2.3 Forget to End the Threads Before Program Exits
When the program ends, it terminates all its worker threads. Corruption occurs if any of them are writing to a file or registry at this point. The solution is to signal the threads with the Win32 event and wait for them to end before exiting.
2.4 Calling TerminateThread or TerminateProcess
TerminateThread stops the threads abruptly without cleaning up; Resource Acquisition Is Initialization (RAII) does not have a chance to clean up. Rule of thumb: Do not call TerminateThread. By extension to the first rule, do not call TerminateProcess as it calls TerminateThread on every thread.
2.5 Thread Started With _beginthread, Ended With ExitThread
This item is only applicable to a C program where a thread must be started with either _beginthread or _beginthreadex to initialize the C runtime. They must be paired with a call to _endthread or _endthreadex to reclaim the C thread allocated resources. Calling ExitThread is a mistake.
3. Graphic User Interface (GUI)
This section deals with updating GUI from a worker thread.
3.1 Updating GUI From a Worker Thread
For a program with a graphic user interface (GUI), there is a main thread that drives the UI. A worker thread is sometimes created to run a long-running task to keep the UI responsive. The thread updates the UI with the results at the end of task processing. This is a mistake, as the UI and worker threads update the UI simultaneously without synchronization. All UI updates must be made from UI thread.
For Microsoft Foundation Classes (MFC) applications, a custom message identifier can be defined to send messages from the non-UI thread to the UI thread using PostMessage. SendMessage is not suitable for it bypass the message queue and sends messages directly to the Windows handle to be processed before returning. In contrast, PostMessage puts the message in the message queue and returns immediately, and the message is retrieved from the UI thread to be processed.
In MFC project, define your custom message ID from an offset from WM_APP.
#define FSM_MESSAGE WM_APP+200
In the UI class header, define this function. A meaningful name can be chosen.
afx_msg LRESULT OnFsmMessage(WPARAM wparam, LPARAM lparam);
In the UI class cpp’s message map macro, insert the ON_MESSAGE entry
BEGIN_MESSAGE_MAP(CSendMsgToParentExampleDlg, CDialogEx)
…
ON_MESSAGE(FSM_MESSAGE, &CSendMsgToParentExampleDlg::OnFsmMessage)
…
END_MESSAGE_MAP()
This is the body of OnFsmMessage:
LRESULT CSendMsgToParentExampleDlg::OnFsmMessage(WPARAM wparam, LPARAM lparam)
{
CString* pStr = reinterpret_cast<CString*>(wparam);
switch (lparam)
{
case 268:
m_edtText.SetWindowTextW(*pStr);
}
delete pStr;
return 0;
}
You can post the FsmMessage from UI or worker thread.
CString* pStr = new CString(msg);
GetParent()->PostMessage(FSM_MESSAGE, (WPARAM)pStr, 268);
This is the MFC example of message posting. You can download the demo at GitHub or here. The approach is easily adaptable to classic Windows API project.
4. Deadlocks and Hangs
In this section, deadlock is the focus. Deadlock can manifest as stalled operation. The problem is hard to reproduce consistently.
4.1 Dead Lock
Deadlocks happen when two threads acquire two or more locks in opposite order; each of them acquires one lock and tries to acquire the next lock, which is already acquired by the other thread, and neither thread can proceed, hence deadlocked as illustrated by the diagram.

Deadlock can be prevented by always taking the locks in the same order. Unlocking can be done in any order. Since a lock has a unique unchanging memory address and addresses can be ordered numerically by comparing them. For RAII2CSLock class, Windows’ CRITICAL_SECTION is used as a lock. You can download the class here.
#include "CriticalSection.h"
class RAII2CSLock
{
public:
RAII2CSLock(CriticalSection& a_section, CriticalSection& b_section)
: m_SectionA(a_section)
, m_SectionB(b_section)
{
if (&m_SectionA < &m_SectionB)
{
m_SectionA.Lock();
m_SectionB.Lock();
}
else if (&m_SectionB < &m_SectionA)
{
m_SectionB.Lock();
m_SectionA.Lock();
}
else {
m_SectionA.Lock();
}
}
~RAII2CSLock()
{
if (&m_SectionA == &m_SectionB)
{
m_SectionA.Unlock();
return;
}
m_SectionA.Unlock();
m_SectionB.Unlock();
}
private:
RAII2CSLock(const RAII2CSLock&);
RAII2CSLock& operator=(const RAII2CSLock&);
CriticalSection& m_SectionA;
CriticalSection& m_SectionB;
};
The number of comparisons exploded exponentially for more than two locks, degrading performance. Only use this approach when you have two locks. Good news for C++17 users: C++17 offers scoped_lock as an alternative for lock_guard that provides the ability to lock multiple mutexes using a deadlock avoidance algorithm.
std::mutex mutA;
std::mutex mutB;
...
{
std::scoped_lock lock(mutA, mutB);
...
}
The benchmark of scoped_lock and RAII2CSLock is as follows and can be downloaded here. RAII2CSLock which is based on CriticalSection has a slight edge over scoped_lock that is based on C++11 mutex.
Std Locking timing: 3417ms
scoped_lock locking timing: 3412ms
RAII2MutexLock locking timing: 3301ms
RAII2CSLock locking timing: 2853ms
Do not mix scoped_lock usage with RAII2CSLock. Just stick to one. Using scoped_lock everywhere gives the deadlock avoidance algorithm the visibility of all locks to do its work and the ability to temporarily unlock one of them to let one thread go ahead.
4.2 Live Lock
Live lock happens whenever the thread tries to acquire a lock and when that fails, it does some idle processing. During that time, the lock becomes available but it is busy doing idle work and later, it tries to acquire again, but the lock is once again unavailable. Because lock acquisition is a blocking process, some developers think CPU time is wasted while waiting. This is not the case; when the lock fails to acquire and goes into blocking mode, the thread gives up its remaining time slice and no processing time is wasted from OS perspective. The cure for this problem is always acquire and never try to acquire and create a separate dedicated thread for idle processing.
4.3 Processing Packets in Network Threads
I made this mistake in the past which I processed my packet in the packet receiving thread and sent another TCP request that blocked until the packet was received and inadvertently hanged the thread because the network thread was blocked by me from receiving the packet. In network processing, there should be a dedicated thread to receive the packets and another thread to process them.
4.4 DllMain Loader Lock Deadlock
When LoadLibrary is called to load your DLL, a loader lock is acquired during the DllMain call and if this DllMain indirectly loads a DLL and acquires the loader lock (but failed) in another thread, your current DLL load can block as a result. What code can cause a DLL to load indirectly? The answer is nobody knows for sure. Opening a file can cause your Anti-virus to load its DLLs for scanning. I was running a demo application that loads a non-licensed DLL that its DllMain pops up a nagging dialog which then hangs on my PC on the first run. I gave feedback to the DLL author, and he never encountered this problem. I deduce it is my Anti-virus. Beware this hang problem might not surface on your development machine but client's machine.
Microsoft recommends not putting complex initialization and cleanup code inside DllMain. Allocating and deallocating memory is fine. Create your own DLL functions for initialization and cleanup and have the application call them.
5. Mutex
In this section, we explore the problems that can plague the misuse of mutex.
5.1 Using Mutex When Atomic Variable Is Sufficient
The counting code below takes a mutex lock whenever count is incremented. An atomic count is sufficient in this case. You can ignore is_valid; it is to prevent optimizer from deducing what I am trying to do and optimizing away my code.
bool is_valid(int n)
{
return (n % 2 == 0);
}
...
int count = 0;
std::mutex mut;
std::for_each(std::execution::par, Vec.begin(), Vec.end(),
[&mut, &count](size_t num) -> void
{
if (is_valid((int)(num)))
{
std::lock_guard<std::mutex> guard(mut);
++count;
}
});
You can accomplish the same thing more efficiently with atomic variable.
std::atomic<int> count = 0;
std::for_each(std::execution::par, Vec.begin(), Vec.end(),
[&count](size_t num) -> void
{
if (is_valid((int)(num)))
++count;
});
If you are not using C++11, you can use Windows Interlocked primitives.
LONG count = 0;
std::for_each(std::execution::par, Vec.begin(), Vec.end(),
[&count](size_t num) -> void
{
if (is_valid((int)(num)))
::InterlockedIncrement(&count);
});
The benchmark results are as follows.
inc mutex: 3136ms
inc atomic: 1007ms
inc win Interlocked: 1005ms
You can download the benchmark code from the top of the article.
5.2 Using Global Windows Mutex for Single Instance Application
This mutex here refers to Windows Mutex, not C++11’s mutex class. Windows Mutex is an interprocess kernel object that can be used to implement a single instance application using an unique global name. Anyone can find your global mutex listed in Process Explorer or WinObj and close it and voila, a second instance of your application can be launched. This Youtube video illustrates the problem. The solution is a private mutex and the code is more involved. I’ll expand on it in another separate article.
5.3 Abandoned Mutex
An abandoned mutex is whereby the mutex is acquired but the thread exited without releasing it because an exception is thrown and is not caught and handled. C++‘s Resource Acquisition Is Initialization (RAII) can help to solve this by releasing the mutex in its destructor. If you are using C++11, you need not reinvent the wheel and use lock_guard. lock_guard acquires the mutex and releases it in the constructor and destructor respectively.
std::mutex mut;
...
std::lock_guard<std::mutex> lock(mut);
If you are using CRITICAL_SECTION as your mutex, you can make use of these two classes written by Jonathan Dodds. The member functions, Enter and Leave are renamed to Lock and Unlock.
#include <Windows.h>
class CriticalSection
{
public:
CriticalSection()
{
::InitializeCriticalSection(&m_rep);
}
~CriticalSection()
{
::DeleteCriticalSection(&m_rep);
}
void Lock()
{
::EnterCriticalSection(&m_rep);
}
void Unlock()
{
::LeaveCriticalSection(&m_rep);
}
private:
CriticalSection(const CriticalSection&);
CriticalSection& operator=(const CriticalSection&);
CRITICAL_SECTION m_rep;
};
This is the RAII class that will unlock the CriticalSection in its destructor. You can download the two classes here.
#include "CriticalSection.h"
class RAIICSLock
{
public:
RAIICSLock(CriticalSection& a_section)
: m_Section(a_section) {
m_Section.Lock();
}
~RAIICSLock()
{
m_Section.Unlock();
}
private:
RAIICSLock(const RAIICSLock&);
RAIICSLock& operator=(const RAIICSLock&);
CriticalSection& m_Section;
};
If you are using Windows mutex, you can detect abandoned mutex whenever WaitForSingleObject returns WAIT_ABANDONED or WaitForMultipleObjects returns WAIT_ABANDONED_0 to (WAIT_ABANDONED_0 + nCount– 1). Please refer to MSDN documentation for more information.
5.4 Using Semaphore Of One Count As Mutex
Some developers mistook the semaphore of one count as equivalent to a mutex. But it is not. A mutex has thread ownership, meaning only the thread that acquires it can release it, while a semaphore has no such requirement. Beware that this is a common trick question for low-latency trading job interviews.
6. Thread Safety
A threadsafe function can be called safely from threads. In this section, we look at how to make your function threadsafe.
6.1 Using Global or Static Variable in Thread
To make your function safe to be called from multiple threads, it cannot use global variables or static local variables to store its state. Static variable initialization is threadsafe but its access is not reentrant.
6.2 Using Non-Threadsafe Functions in Thread
In addition to not using global and static variables, ensure your functions not to call non-threadsafe code such as string splitting function like strtok. strtok stores its current state for the next call. To make strtok thread-safe, C language has introduced a reentrant version called strtok_s. Replace your non-threadsafe function calls with their threadsafe counterparts.
6.3 Not All Access to Shared Variable Is Protected
A memory shared between threads must be protected with a lock. Exercise extra caution when dealing shared state. During code reviews, check every access is done under synchronization.
7. Priority
Every thread is associated with priority that determines its scheduling. Higher priority means it gets more CPU processing time. Setting higher or lower priority can be detrimental to your application, as we shall see in this section.
7.1 Setting Realtime Thread Priority
Do not ever set real-time priority for your thread as it would starve other threads. It should be reserved for processing that need real-time attention such as audio. Note: It is not possible to set to real-time priority using Windows API because thread priority can only be bumped up to two priority from the process priority but this limitation can be bypassed using a kernel driver.
7.2 Setting Lower Thread Priority
Priority inversion is whereby a high-priority thread is waiting on synchronization primitive held by a low-priority thread and execution could not proceed as low-priority thread is not awakened enough to do processing to release the lock. This is exactly what happened to Mars PathFinder. Whenever Windows detects a thread has not been run for 4 seconds, it is given a priority boost. I rather prefer Windows not mitigate this with a priority boost as it can lead the thread starvation undetected during development. The solution to avoid this is not to set low priority and also not set high priority because high priority implies there is relative low priority.
Threading performance misconceptions and improvements are discussed in this section.
8.1 Double-checked Locking
Double-checked Locking is typically used to improve the singleton performance. But the first check is subjected to data race, rendering this optimization useless.
class Singleton
{
public:
static Singleton *instance (void)
{
if (instance_ == 0)
{
std::lock_guard<std::mutex> guard (lock_);
if (instance_ == 0)
instance_ = new Singleton;
}
return instance_;
}
private:
static std::mutex lock_;
static Singleton *instance_;
};
C++11 Standard provides the threadsafe access for static variable by stating If control enters the declaration concurrently while the variable is being initialized, the concurrent execution shall wait for completion of the initialization. The GetInstance function with static local Singleton shall suffice.
Singleton& GetInstance() {
static Singleton s;
return s;
}
8.2 False Sharing
Data is usually placed as close as possible to be cache-friendly but this policy run counter-intuitive to multithreading performance where each thread writes its data on the same cache line causing thrashing whereby each thread is informed its data in cache is invalidated by other thread and has to be fetched from main memory whereas thread is not operating on the changed data and therefore has no interest in it whatsoever.
To get over this problem, the data in the struct should be aligned with cacheline size using C++17’s hardware_destructive_interference_size to force data onto different cacheline. Do note this size is defined at compile time as 64bytes and does not update itself when running on a machine with different cacheline size. And the value could have been more aptly named. The keep_apart struct is an example from C++ Reference on how to align hardware_destructive_interference_size with alignas keyword to avoid false sharing.
struct keep_apart
{
alignas(std::hardware_destructive_interference_size) std::atomic<int> cat;
alignas(std::hardware_destructive_interference_size) std::atomic<int> dog;
};
To be on the safe side, you can set a dummy array of 128 bytes between your data of interest. 128 bytes is the maximum cache line size.
8.3 Coarse Grained Locking
Coarse-grained locking means holding a lock over a large block of code. Performance can be improved by taking lock only when needed. This can be accomplished by RAII using curly braces to limit the scope of lock_guard. See the CoarseGrainedLockingFunc below.
std::mutex mutA;
void CoarseGrainedLockingFunc()
{
std::lock_guard<std::mutex> lock(mutA);
A->DoWork();
A->DoAnotherWork();
}
See how FineGrainedLockingFunc improves by locking the mutex only whenever A is used.
std::mutex mutA;
void FineGrainedLockingFunc()
{
{
std::lock_guard<std::mutex> lock(mutA);
A->DoWork();
}
{
std::lock_guard<std::mutex> lock(mutA);
A->DoAnotherWork();
}
}
8.4 Setting Processor Core Affinity
Setting a thread affinity can be counter-productive because that processor core runs your thread and other threads. When other core is ready to run your thread but scheduler cannot select your thread to run because of its thread affinity. Thread affinity proponents are betting that thread data is still in the cache when the thread is run again. On the other hand, the data could be already evicted. You experiment it to see if it pays off.
8.5 Spinning
Spinning is not recommended to acquire a lock in user mode application because your thread can be pre-empt by other threads and spinning deprives other threads from doing useful work. Spinning drain laptop batteries fast and generate much heat in data center without doing real work. Spinning only makes sense in kernel code because they are at higher priority than thread scheduler which cannot pre-empt them. But note kernel code can be interrupted by hardware/software interrupt.
If spinning is desired in user mode for perf reason, you can spin CRITICAL_SECTION temporarily with InitializeCriticalSectionAndSpinCount to initialize with a spin count. This spin count is ignored on single processor system. Whenever EnterCriticalSection is called, the thread spins: it enters a loop which iterates spin count times, checking to see if the lock is released. If the lock is not released before the loop finishes, the thread goes to sleep to wait for the lock to be released.
BOOL InitializeCriticalSectionAndSpinCount(
LPCRITICAL_SECTION lpCriticalSection,
DWORD dwSpinCount
);
8.6 Too Much Locking
To improve performance, we can reduce the amount of synchronization. For example, look at this code from the above mutex section, it requires synchronization whenever the count is incremented.
int count = 0;
std::mutex mut;
std::for_each(std::execution::par, Vec.begin(), Vec.end(),
[&mut, &count](size_t num) -> void
{
if (is_valid((int)(num)))
{
std::lock_guard<std::mutex> guard(mut);
++count;
}
});
We can modify the code to increment a temp_count inside the for loop and add the temp_count to the count at the end of lambda, only this section needs mutex synchronization. The number of mutex locks is equal to number of processor core which is identified by threads variable.
const size_t threads = std::thread::hardware_concurrency();
std::vector<size_t> vecIndex;
for (size_t i = 0; i < threads; ++i)
vecIndex.push_back(i);
int count = 0;
std::mutex mut;
std::for_each(std::execution::par, vecIndex.begin(), vecIndex.end(),
[&mut, &count, threads](size_t index) -> void
{
size_t thunk = Vec.size() / threads;
size_t start = thunk * index;
size_t end = start + thunk;
if (index == (threads - 1))
{
size_t remainder = Vec.size() % threads;
end += remainder;
}
int temp_count = 0;
for (int i = start; i < end; ++i)
{
if (is_valid((int)(Vec[i])))
{
++temp_count;
}
}
{
std::lock_guard<std::mutex> guard(mut);
count += temp_count;
}
});
The naive code mutex takes 3136ms while the one with less mutex lock takes 33ms, almost a 100x improvement.
inc mutex: 3136ms
inc less mutex lock: 33ms
9. Task-Based Threading
In this section, we look at mistakes of task-based threading using the Intel Threading Building Blocks (TBB).
9.1 Using Thread Local Storage in Tasks
When you are converting your existing thread to use task, be prepared to remove the thread local storage (TLS). In task-based processing, a thread is reused to process different tasks. If that next task also accesses TLS, it may be accessing the information meant for another task.
9.2 Waiting Inside Task for Another Task
Inside the current task, do not create a task and wait for it. Task-based processing works by placing a task in the thread queue. Your new task can be in the same queue as your current task and the current thread is blocked from processing by waiting for the new task completion. When they are in different queues, no blocking problem. This is an intermittent problem which is tricky to detect. The blocking problem can be averted by not waiting for a new task to complete or not creating a new task inside a task.
10. Parallel Patterns Library
The Microsoft Parallel Patterns Library (PPL) parallel_for has a memory leak problem and an alternative comes from C++17.
10.1 Using Parallel Patterns Library Leaks Memory
The PPL's parallel_for leaks memory and I reported it and was told it was global memory but the leaks keep increasing with more parallel_for invocations. The Microsoft recommendation is to use C++17 parallel for_each().
11. Windows API
In this section, we look at two Windows API to get process and thread handles.
11.1 GetCurrentProcess and GetCurrentThread Returns Pseudo Handle
Beware GetCurrentProcess and GetCurrentThread functions return a pseudo handle of -1 and -2 respectively. In the code below, the ptrdiff_t cast is used to convert the unsigned HANDLE to signed integer according to the platform bitness so that the negative numbers can be observed. The below code can be downloaded here.
std::cout << "GetCurrentProcess(): " <<
(std::ptrdiff_t)::GetCurrentProcess() << "\n";
std::cout << "GetCurrentThread(): " <<
(std::ptrdiff_t)::GetCurrentThread() << "\n";
This is the output:
GetCurrentProcess(): -1
GetCurrentThread(): -2
This does not present a problem if you intend to use the handle in the current process or thread but if there is a need to pass the handle to another process or thread, call DuplicateHandle to get the real handle. You can read more on Bruno van Dooren’s The Current Thread Handle.
12. COM Threading
In this section, we explore the usage of COM interface pointer in another thread.
12.1 Using COM Interface Pointer in Another Thread Without Marshalling
This is the 31st mistake on the list. Since it does not seem to pose a problem, I did not include it in the list. When using a COM interface pointer created on another thread, it has to be marshalled. Because the new worker thread did not call CoInitialize()/CoInitializeEx() to initialize the COM apartment, the COM interface pointer could not realize it was being called from another thread, and thus, no error was thrown. The correct practice is to marshal the COM object. The easiest way to accomplish this is through the Global Interface Table. Only IStream pointer is not required to be marshalled across threads.
Problem with Shared State
Many threading problems stem from having shared state. Shared state requires synchronization and therefore is a performance killer: Increasing the number of threads from one to two can reduce the performance by 20% or even more. Take this multi-threaded shared atomic incrementing example from the above section.
std::atomic<int> count = 0;
std::for_each(std::execution::par, Vec.begin(), Vec.end(),
[&count](size_t num) -> void
{
if (is_valid((int)(num)))
++count;
});
It takes 1007ms to complete. While this multi-threaded non-shared incrementing where each thread as its own counter takes 73ms. This loop::parallel_for is a new library I am writing but it has a lower performance than C++17 parallel for_each due to every lambda invocation, it has to pass an extra thread index argument.
struct CountStruct
{
CountStruct() : Count(0)
{
memset(buf, 0, sizeof(buf));
}
int Count;
char buf[128]; };
...
int threads = std::thread::hardware_concurrency();
std::vector<CountStruct> count(threads);
loop::parallel_for(threads, (size_t)(0), (size_t)(VEC_SIZE),
[&count](int threadIndex, int index) -> void
{
if (is_valid(Vec[index]))
++(count[threadIndex].Count);
});
int total = 0;
for (auto& st : count)
total += st.Count;
However, 99.99999% of the time, things are not as simple as giving every thread its counter or object. Synchronization can be avoided by making copies of data to the thread but that usually involves heap memory allocation. Heap allocation (and deallocation) has considerable overheads that may not be amortized. Performance gain can fail to materialize. There is also the inherent risk of operating on stale data. As complexity grows uncontrollably in pursuit of share-free code, the bugs can creep in. Making your code share-free is a massive undertaking and is a decision that should not be made lightly. Do note some resource such as network bandwidth and database connections are inherently shared even though no explicit locks are taken.
Summary of the counting benchmark is as follows. The result is surprising that taking lesser mutex lock is faster than taking no lock, though I have taken care to eliminate false-sharing. The reason should be the no lock version has additional parameter called threadIndex in every lambda invocation.
inc mutex: 3136ms
inc atomic: 1007ms
inc win Interlocked: 1005ms
inc no lock: 73ms
inc single_thread: 86ms
inc less mutex lock: 33ms
Download the MultithreadedCount benchmark here.
You can compile the benchmark on Linux with these commands. Remember to copy timer.h and parallel_for_each.h to your Linux folder. The Linux build automatically excludes the Windows Interlocked primitive function.
g++ MultithreadedCount.cpp -O3 -std=c++17
clang++ MultithreadedCount.cpp -O3 -std=c++17
Wrapping Up
Four years have passed since my dentist visit in 2020. As I deepened my research on the subject, the list of mistakes increased from 5 to the final 30 items. To keep the scope manageable, I only cover C++ Standard Library and Windows. Graphic processing units (GPU) and other Operating Systems, such as Linux and MacOS, are left out in the discussion. Lock-free data structures are also not discussed because I lacked fluency in this subject.
At the end of this journey, I have become adept at writing bug-free multi-threading code. By writing this article, I hope to raise awareness of multi-threading pitfalls and the solutions to avert them. I plan to compile a similar exhaustive list on memory mistakes.
If you like my article or it has helped you, please consider giving the article an upvote and follow me on CodeProject for more simple, succinct articles.
References
- Concurrent Programming on Windows by Joe Duffy
- Windows Internals, Part 1 by Pavel Yosifovich, Mark E. Russinovich, Alex Ionescu, David A. Solomon
- Windows Internals on Pluralsight by Pavel Yosifovich
- Essential COM by Don Box
History
- 15th February, 2024: Updated all the source code downloads except the
TestGetCurrentThread - 12th February, 2024: Updated the
RAIICSLock and PostMessage source code downloads - 11th February, 2024: First release


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 









