Sometimes, the collections available cannot meet your requirements and you have to write your own. This article explains how to write your own collection in detail, covering some advanced topics. The implemented collection works like a SortedDirectory, but allows for 2 keys per item and only the combination of the 2 keys needs to be unique. This is helpful when for example items should be stored and retrieved per day when they were created.
Introduction
I'm writing an accounting software for my own use and needed to store some financial transactions per day. An easy way to store them would be Dictionary<DateTime, FinanceTransaction>, but this allows to store only one transaction per day, however I need to store several transactions a day. This can be achieved by using Dictionary<DateTime, List<FinanceTransaction>>, which has one big disadvantage, it would create thousands of Lists, since I need to use many of these collections, not just one.
I wrote SortedBucketCollection<TKey1, TKey2, TValue> instead. I imagine that there is a bucket for each TKey1 and each bucket can contain several items with unique Tkey2. However, there is not actually a bucket, just a linked list, which doesn't need any memory space like a List does.
For my finance application, I use it like this: SortedBucketCollection<DateTime, int, FinanceTransaction>. TKey1 is the date of the transaction and Tkey2 is the transaction number. Using just the transaction number as key, which is unique, is not good enough, it would be too time consuming to search or sort all transactions whenever the transactions of one day are needed.
This article covers several aspects:
- How to use
SortedBucketCollection - Design and code of
SortedBucketCollection - Things to consider when writing your own collection
Using SortedBucketCollection
Here is the complete code of how to use SortedBucketCollection:
using System;
namespace SortedBucketCollectionDemo {
public record FinanceTransaction
(int No, DateTime Date, string Description, decimal Amount);
class Program {
static void Main(string[] args) {
var transactions =
new SortedBucketCollection<DateTime, int, FinanceTransaction>
(ft=>ft.Date, ft=>ft.No);
var date1 = DateTime.Now.Date;
transactions.Add(new FinanceTransaction(3, date1, "1.1", 1m));
transactions.Add(new FinanceTransaction(1, date1, "1.2", 2m));
transactions.Add(new FinanceTransaction(0, date1, "1.3", 3m));
var date2 = date1.AddDays(-1);
transactions.Add(new FinanceTransaction(1, date2, "2.1", 4m));
transactions.Add(new FinanceTransaction(2, date2, "2.2", 5m));
Console.WriteLine("foreach over all transactions");
foreach (var transaction in transactions) {
Console.WriteLine(transaction.ToString());
}
var transaction12 = transactions[date1, 1];
transactions.Remove(transaction12!);
Console.WriteLine();
Console.WriteLine("foreach over transactions of one day");
Console.WriteLine(date1);
foreach (var transaction in transactions[date1]) {
Console.WriteLine(transaction.ToString());
}
}
}
}
Creating a SortedBucketCollection
Definition of SortedBucketCollection class:
public class SortedBucketCollection<TKey1, TKey2, TValue>:
ICollection<TValue>, IReadOnlySortedBucketCollection<TKey1, TKey2, TValue>
where TKey1 : notnull, IComparable<TKey1>
where TKey2 : notnull, IComparable<TKey2>
where TValue : class {
The SortedBucketCollection supports two keys. The first is used to group the stored items of type TValue together. The second key is used to uniquely identify an item within that group (bucket).
SortedBucketCollection supports ICollection and can be used as any other collection. Unfortunately, it is not possible to implement IList<>, which allows access of an item based on its position within the list. SortedBucketCollection cannot implement this efficiently.
The constructor of SortedBucketCollection looks like this:
public SortedBucketCollection(Func<TValue, TKey1> getKey1, Func<TValue, TKey2> getKey2) {}
It takes two parameters, the delegates getKey1 and getKey2. I never liked that in Dictionary<> and SortedList<> both the key and the item need to be passed, because most of the time, the key is already a property of the item. To improve this, I added these two delegates which allow to find Key1 and Key2 in the item.
Using the constructor:
var transactions =
new SortedBucketCollection<DateTime, int, FinanceTransaction> (ft=>ft.Date, ft=>ft.No)
In the demo, a FinanceTransaction has a date and a transaction number, which are used as the two required keys.
public record FinanceTransaction(int No, DateTime Date, string Description, decimal Amount);
Adding an Item to SortedBucketCollection
Adding an item becomes very simple:
transactions.Add(new FinanceTransaction(uniqueNo++, date, "Some remarks", 10.00m));
No key needs to be given as a separate parameter. SortedBucketCollection knows how to find the keys already. It takes the first key, a date and checks if there is already any item with the same date. If not, it just adds the new item under that date. If there is already one, SortedBucketCollection checks if the new item should come before or after the existing item. After Add() is completed, the two items are stored in a properly sorted linked list.
Note: SortedBucketCollection needs to increase its storage capacity only for the single SortedDirectory, which happens seldom. With the Dictionary<DateTime, List<FinanceTransaction>> approach, thousands of lists have to increase their capacity constantly (i.e., copy the internal array into a bigger array).
Looping Over All Items in a SortedBucketCollection
Nothing special here, as any other collection, SortedBucketCollection supports IEnumerable(TValue):
foreach (var transaction in transactions) {
Console.WriteLine(transaction.ToString());
}
The output is as follows:
FinanceTransaction { No = 1, Date = 07.11.2021 00:00:00, Description = 2.1, Amount = 4 }
FinanceTransaction { No = 2, Date = 07.11.2021 00:00:00, Description = 2.2, Amount = 5 }
FinanceTransaction { No = 0, Date = 08.11.2021 00:00:00, Description = 1.3, Amount = 3 }
FinanceTransaction { No = 1, Date = 08.11.2021 00:00:00, Description = 1.2, Amount = 2 }
FinanceTransaction { No = 3, Date = 08.11.2021 00:00:00, Description = 1.1, Amount = 1 }
The items are not in the sequence as they were added, as would be the case with a List<>, but sorted first by date and then by No.
Accessing One Particular Item
var transaction = transactions[new DateTime(2021, 11, 07), 1];
Removing an Item
transactions.Remove(transaction);
In a Dictionary<>, one would use the key to remove the item. SortedBucketCollection can figure out the key based on the item given.
Accessing All Items of One Day
var date1Transaction1 = transactions[date1];
This is where SortedBucketCollection truly shines. One could store all transactions in a List<> and use Linq to find all transactions with a certain date and then sort them according to transaction.No. This would be a rather time consuming operation. When writing my financial application, I found out that I needed to access transactions per day very often and that is the reason I wrote SortedBucketCollection.
Implementation of SortedBucketCollection
It is seldom that one needs to write his own collection, meaning that is a skill which not many have. In this chapter, I show all the important aspects one has to consider when writing a collection. Of course, this requires writing about many details. If you feel this is boring, stop reading here.
Is a New Collection Really Needed?
DotNet and Github already offer plenty of collections. Check Stackoverflow if there is one catering for your needs.
In the case of SortedBucketCollection, I found two suggestions:
- Use
SortedList<TKey1, SortedList<TKey2, TValue>>. The problem with this is that it needs too much memory. In my case, each of the 100 financial accounts in my application has its own SortedBucketCollection and I want to be able to cover 1000 days. Using this approach, I would need over 100'000 SortedLists, which is way too much overhead. - Linq offers the
Lookup collection, which can store many values under one key. Unfortunately, it is readonly. To create a Lookup collection, one has to pass an IEnumerable as parameter in the constructor and that is all the data the Lookup will ever contain. It is not possible to add or remove items afterwards.
What Will the Generic Parameters Be ?
Most collections in .NET have only 1 key, but I wanted 2 keys, one for grouping values together and another to identify one particular item within that group. This is required if deletion of a single item is needed.
public class SortedBucketCollection<TKey1, TKey2, TValue>:
ICollection<TValue>, IReadOnlySortedBucketCollection<TKey1, TKey2, TValue>
where TKey1 : notnull, IComparable<TKey1>
where TKey2 : notnull, IComparable<TKey2>
where TValue : class {
The keys are used for sorting, therefore they need to implement IComparable and cannot be null.
I prefer TValue to be a class, not a struct to avoid unnecessary copying of its content.
Which Interfaces to Implement?
I would have liked to implement something like IDictionary<TKey,TValue>, but that is not really an option, because I need two keys. How about IList<T> ? Also not possible, because it allows something like transactions[date]=xyz; I don't want to allow that. So the best interface I could find was ICollection<T> which is based on IEnumerable<T>.
As you might have noticed, I wrote a new Interface IReadOnlySortedBucketCollection<TKey1, TKey2, TValue>, containing the properties and methods which can only read data from SortedBucketCollection. In my application, I wanted to make it very clear that only the class holding the collection can change its content, the other classes can only read. My Account class gives access to the collection to other classes like this:
public IReadOnlySortedBucketCollection<DateTime, int, Ledger> Ledgers => ledgers;
readonly SortedBucketCollection<DateTime, int, Ledger> ledgers;
Internal Data Structure
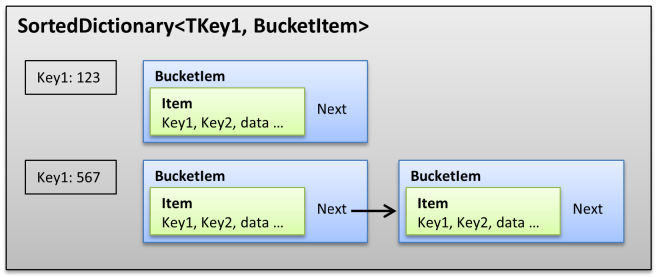
All data is stored in just one collection, a SortedDirectory, which holds BucketItems:
private class BucketItem {
public readonly TValue Item;
public BucketItem? Next;
public BucketItem(TValue item, BucketItem? next) {
Item = item;
Next = next;
}
}
A BucketItem has an Item of type TValue, which is the data actually stored and has a link to the next BucketItem with the same Key1 but different Key2. Note that there is actually no Bucket object.
readonly SortedDictionary<TKey1, BucketItem> buckets;
buckets holds for each unique TKey1 value a BucketItem, which is the head of a linked list if there are several items with the same TKey1 value.
Which Properties Are Needed?
Count is required for IList. It tells how many items are stored without enumerating them all. IsReadOnly is also required by that interface, I set it always to false. I added Key1Count, which tells how many different Key1 are used.
SortedBucketCollection provides two indices:
public IEnumerable<TValue> this[TKey1 key1] gives access to all items having Key1==key1. Note that it returns an enumerable, not a list, to avoid spending time and memory to create one.public TValue? this[TKey1 key1, TKey2 key2] returns 1 item, if it exists for that key combination.
Which Methods Are Needed?
If your collection implements an interface, VS will add all the required methods for you. In my case, they are:
ICollection requires:
public void Add(TValue item) {'''}
public bool Remove(TValue item) {
public void Clear() {
public bool Contains(TValue item) {...}
public void CopyTo(TValue[] array, int arrayIndex) {...}
Sometimes, an interface demands that there is a certain method which we might not want to use for our collection. We cannot just leave it away, but we can raise throw new NotSupportedException(); as I did for CopyTo().
IEnumerable requires:
public IEnumerator<TValue> GetEnumerator() {...}
I added inspired from IDictionary:
public bool Contains(TKey1 key1) {...}
public bool Contains(TKey1 key1, TKey2 key2) {..}
How to Implement IEnumerable<>
IEnumerable<> is defined like this:
public interface IEnumerable<out T>: IEnumerable {
IEnumerator<T> GetEnumerator();
}
public interface IEnumerator<out T>: IEnumerator, IDisposable {
T Current { get; }
}
public interface IEnumerator {
object Current { get; }
bool MoveNext();
void Reset();
}
In the early days of .NET, implementing IEnumerable for a collection was complicated and required writing one additional class like SortedBucketCollectionEnumerator which implements IEnumerator<TValue> and then would be returned by GetEnumerator().
With the introduction of the C# keyword yield, things got easier, but still rather confusing, because one can use yield only to create a method returning IEnumerator<TValue>. Most of us might have never done this and are therefore not familiar with yield.
Here is how to code looks like to write a GetEnumerator() implementation:
public IEnumerator<TValue> GetEnumerator() {
var versionCopy = version;
foreach (var keyValuePairBucketItem in buckets) {
var bucketItem = keyValuePairBucketItem.Value;
yield return bucketItem.Item;
if (versionCopy!=version) {
throw new InvalidOperationException();
}
while (bucketItem.Next is not null) {
bucketItem = bucketItem.Next;
yield return bucketItem.Item;
if (versionCopy!=version) {
throw new InvalidOperationException();
}
}
}
}
Notice that GetEnumerator() returns an IEnumerator<TValue>, but none gets created in the code!
The compiler translates the body of GetEnumerator() into a new, hidden class, let's name it SortedBucketCollectionEnumerator. It implements IEnumerator<TValue>.
Basically, my GetEnumerator() contains two loops:
foreach (var keyValuePairBucketItem in buckets) {
var bucketItem = keyValuePairBucketItem.Value;
while (bucketItem.Next is not null) {
}
}
A collection needs usually only one loop, enumerating all keys. Since SortedBucketCollection uses two keys, one needs to loop first through every TKey1 and inside that loop through every TKey2 in the bucket.
For every key found, the following statement is programmed:
yield return item;
SortedBucketCollection.GetEnumerator() gets consumed like this:
foreach (var transaction in transactions) {
Console.WriteLine(transaction);
}
The C# compiler translates this into something like this:
using(var sortedBucketCollectionEnumerator = transactions.GetEnumerator()) {
while (sortedBucketCollectionEnumerator.MoveNext()) {
Console.WriteLine(sortedBucketCollectionEnumerator.Current);
}
}
When sortedBucketCollectionEnumerator.MoveNext() is called for the first time, it runs the code generated based on the body of SortedBucketCollection.GetEnumerator() until it finds the first yield statement, stops there and returns that item. When sortedBucketCollectionEnumerator.MoveNext() gets called again, it continues with the next line after the yield statement and runs again until the next yield, stops there and returns that item. This gets repeated until no more yield statement is found, upon which the foreach is completed.
If you understand all this, my congratulations. If not, it helps to run and single step through the code.
Multithreading Safety
.NET collections are usually not multithreading safe, meaning two threads cannot simultaneously manipulate the collection. But they usually detect if one thread is enumerating over the collection and another or the same thread is changing the collection's content at the same time. This is done with the version field. Each time an item gets added or removed, version gets incremented. As you can see in GetEnumerator(), at the start the current version gets saved and after each yield, there is a test to ensure that version has still the same value.
Unit Testing
For most code you write, you should also write a unit tests. In VS, add a MSTest Test Project to your solution. Please Google how to write unit tests in VS, just remember to call every method and after every call, check if all the properties have the expected values.
Performance SortedBucketCollection vs. SortedDirectory
Once coding and testing is done, one should do some performance testing. How to do that, see: benchmarkdotnet.org
In this case, it is interesting to compare SortedBucketCollection<date, int, item> with SorteDirectory<date, SortedDirectory<int, item>. I created about 100'000 items and then compared how much time and memory it takes to fill them into the two collections:
| Method | Time | Memory |
|------------- |------------:|------------:|
| DataOnly | 233.9 us | - |
| SortBuckets | 10,108.9 us | 2,352,161 B |
| Dictionaries | 12,530.6 us | 4,536,112 B |
The first row DataOnly is a test which just loops through all already created items. The test has to be compiled for Release, meaning a loop just reading items might be optimised to not reading at all. To be sure that the compiler cannot do that, I summed up all the item.Key2. Since this test is only reading, no heap memory was needed.
The speed difference between SortBuckets and Dictionaries is only 20%, I was hoping that my collection would be faster. But SortBuckets needs only half the memory of Dictionaries.
I guess one way to increase the speed of SortedBucketCollection would be to make BucketItem a struct instead of a class, put them into one big array which grows over time like List<> does internally and reuse BucketItems which are no longer needed, which would remove in the test above about 100'000 object creations. However, the present speed is acceptable, so I didn't spend more time on speed improvements.
Code of SortedBucketCollection
I have attached the source code of SortedBucketCollection to this article. It is basically one file containing the SortedBucketCollection and another file showing how to use it:
You can find the SortedBucketCollection source code also on Github:
Storage is a library I wrote for single user applications to replace any database with a storage system which:
- Stores data in plain text files
- The developer needs to create only classes with properties,
Storage then adds all the code needed to store, retrieve and delete instances of that class. - All data is stored in RAM, which makes it extremely high performance, like reading 100 MBytes data from disk in 2 seconds or processing over 100'000 transactions per second including permanent storage on disk. Queries are scaringly fast, because all data is in RAM
- Transactions support commit and rollback
- Linq replaces SQL
- Backup
- Automatic compacting of data files
- Runs in process, no installation needed, just link the Storage.dll, which is open source C#
Biggest Advantage
The developer needs to write much less code and everything is in C#. There is no need to use anything like the sometimes slow Entity Framework nor any database administration. The data files can be easily read by any Editor or Excel and the maintenance of the data becomes extremely easy. I am using Storage since years for a financial application and never ever had any issue.
Give Storage a try if you need to write a single user application with high performance, high reliability and permanent data storage on a local disk.
History
- 12th November, 2021: Initial version


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 







