A short introduction to instruction level parallelism (ILP), then how not to do benchmarking, followed by a simple and reliable way to benchmark optimized code. Using this, I identify some interesting machine code generated by Visual C++ that demonstrates ILP in practice.
To build the example code, you need the Visual C++ compiler and the boost libraries from https://www.boost.org/.
Introduction
In this article, I present a simple and reliable mechanism for benchmarking the performance of an optimized piece of code. Then there is a detailed walkthrough related to some impressive machine code generated by Visual C++ for std::string.
One of the primary reasons to write C++ code is to create high performance software, and for this to happen, we need a good understanding of how the optimizer works: What it does well, what it cannot do, and when it seems to get confused. Each compiler has its own quirks: Some things can work well for clang, and not for gcc or cl – and the behavior of the optimizer can even be radically different between different versions of a compiler.
It helps to understand how the CPU works, how memory is accessed, and a good mental model of how the code is supposed to work.
Instruction Level Parallelism
The original the 8086 CPU evaluated one instruction at a time. It read the instruction pointed to by the Instruction Pointer (IP) register from memory, decoded it, executed it, and then retired it before moving on to the next instruction. Intel added many exciting features to the 80186, 80286 and 80386 architectures such as virtual memory, instruction- and data-cache, and much more. With the 80486 Intel introduced a 5-stage pipeline, and this more than doubled the performance compared to the 80386. Instead of evaluating one instruction at the time, each stage of the pipeline could have one instruction moving through it at the same time.
The first stage retrieved an instruction from the cache, the second stage decoded the instruction, the third stage translated memory addresses and displacements needed for the instruction, the fourth stage executed the instruction, and finally the fifth stage retired the instruction by writing results back to registers or memory.
For the Pentium Intel added a second separate superscalar pipeline, capable of running simple instructions, such as integer math, in parallel.
Next, in 1995, came the Pentium Pro, introducing speculative execution and an out-of-order execution processing core. The pipeline now had 12 stages and the CPU also included a super-pipeline where many instructions could be processed in parallel. The decoding stage was also modified, allowing the Pentium Pro processor to decode up to three instructions per cycle.
Since then, Intel has continued to add capabilities to the x86/x64 architecture that improves the ability of the processor to merge instructions into single micro-ops and to execute micro-ops in parallel, and what has emerged is a microarchitecture that is capable of analyzing small sequences of instructions, and dynamically optimize the machine-code at runtime to achieve higher throughput.
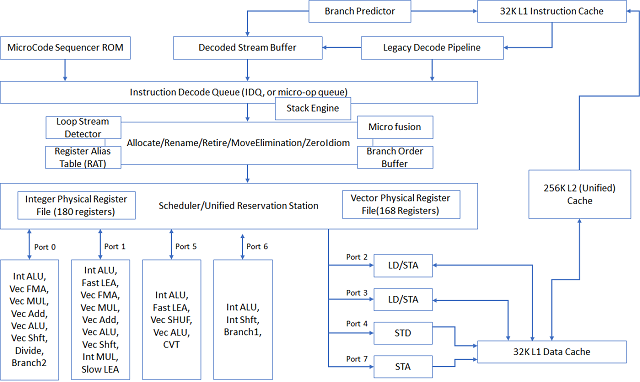
Modern Intel processors use many techniques to improve instruction level parallelism:
Instruction Pipelining
Instruction pipelining tries to keep the processor busy by dividing the execution of an instruction into steps that can be performed sequentially by different units of the processor in parallel.
Superscalar Execution
Superscalar execution allows the processor to execute multiple instructions in parallel by dispatching the instructions to different execution units.
Out-of-Order Execution
When the processor must wait to execute an instruction because the input data for that instruction is not yet available, it can locate later instructions that are ready for execution. The processor must verify that the input data for the instructions will be ready when the instructions are to be executed, and instructions that depend on the output of previous instructions form a dependency chain and must be executed in order.
Register Renaming
Allocates physical registers for the logical registers. Each logical register, such as RAX, can have a set of physical registers associated with it. This eliminates false data dependencies caused by the reuse of logical registers for instructions that have no data dependencies.
Speculative Execution
Speculative execution allows the processor to execute instructions belonging to one or more execution branches before it actually knows which branch is the one it will actually take. Once a branch is chosen, the effects of the branches not taken must be rolled back.
Branch Prediction
Branch prediction is used by the processor to guess the most likely branch will be chosen for a conditional, and schedule that for speculative execution.
Macro Op Fusion
An arithmetic or logic instruction is fused with the next instruction, if that is a conditional jump instruction, into a single micro-op.
Micro Op Fusion
In order to get more instructions through the register renaming and retirement stages, some operations that were split into two micro ops, are joined together and share a single micro-op in most of the pipeline and a single entry in the reorder buffer. This single micro-op represents two operations that must be executed by two different execution units. The fused micro-op is dispatched to two different execution ports but is retired as a single unit.
Benchmarking
To be able to say something about how well the optimizer is working, I need to benchmark the performance of my code and getting this right can be tricky. There is a simple, reliable, solution – and we will get back to that soon – but first, let us consider why benchmarking can be tricky.
When the compiler and linker have a complete view of all that is going on, it can perform rather significant transformation on a piece of code. Even statically linked code may get evaluated and reordered during link-time optimization. In C++, this is called the as-if rule and it allows any code transformations that do not change the observable behavior of the program. Normally this is nice, and all I want is to find a simple mechanism that provides me with reliable timing information.
Here is the output of a too simple benchmark:
__declspec( noinline ) By ref 10000000000 in 0.000000 seconds
__declspec( noinline ) By value 10000000000 in 0.000000 seconds
By ref 10000000000 in 0.000000 seconds
By value 10000000000 in 0.000000 seconds
When executing the benchmark, it clear that it does not execute in zero time. Below is the implementation – feel free to scroll right past it, this is not an exciting piece of code – it is here just to convince you that the 0 seconds reported above cannot be right for all the four cases – although it is right for two of them:
__declspec( noinline ) Int64 AddOneByRefNI( const Int64& duration )
{
return duration + 1;
}
_declspec( noinline ) Int64 AddOneMillionByRefNI( const Int64& duration )
{
Int64 result = duration;
for ( size_t i = 0; i < 1000000; ++i )
{
result = AddOneByRefNI( result );
}
return result;
}
__declspec( noinline ) Int64 ByRefTestNI( const Int64& duration )
{
Int64 result = 0;
for ( size_t i = 0; i < 10000; ++i )
{
result += AddOneMillionByRefNI( duration );
}
return result;
}
Int64 AddOneByRef( const Int64& duration )
{
return duration + 1;
}
Int64 AddOneMillionByRef( const Int64& duration )
{
Int64 result = duration;
for ( size_t i = 0; i < 1000000; ++i )
{
result = AddOneByRef( result );
}
return result;
}
Int64 ByRefTest( const Int64& duration )
{
Int64 result = 0;
for ( size_t i = 0; i < 10000; ++i )
{
result += AddOneMillionByRef( duration );
}
return result;
}
__declspec( noinline ) Int64 AddOneByValueNI( const Int64 duration )
{
return duration + 1;
}
__declspec( noinline ) Int64 AddOneMillionByValueNI( const Int64 duration )
{
Int64 result = duration;
for ( size_t i = 0; i < 1000000; ++i )
{
result = AddOneByValueNI( result );
}
return result;
}
__declspec( noinline ) Int64 ByValueTestNI( const Int64 duration )
{
Int64 result = 0;
for ( size_t i = 0; i < 10000; ++i )
{
result += AddOneMillionByValueNI( duration );
}
return result;
}
Int64 AddOneByValue( const Int64 duration )
{
return duration + 1;
}
Int64 AddOneMillionByValue( const Int64 duration )
{
Int64 result = duration;
for ( size_t i = 0; i < 1000000; ++i )
{
result = AddOneByValue( result );
}
return result;
}
Int64 ByValueTest( const Int64 duration )
{
Int64 result = 0;
for ( size_t i = 0; i < 10000; ++i )
{
result += AddOneMillionByValue( duration );
}
return result;
}
BOOST_AUTO_TEST_CASE( Int64ByRefOrValueTest )
{
using Seconds = std::chrono::duration<double, std::chrono::seconds::period>;
printf( "Starting stopwatch\n" );
auto start = std::chrono::high_resolution_clock::now( );
auto byRefResultNI = ByRefTestNI( 0LL );
auto end = std::chrono::high_resolution_clock::now( );
auto byRefDurationNI = Seconds( end - start );
printf( "__declspec( noinline ) By ref %lld in %f seconds\n",
byRefResultNI, byRefDurationNI.count() );
start = std::chrono::high_resolution_clock::now( );
auto byValueResultNI = ByValueTestNI( 0LL );
end = std::chrono::high_resolution_clock::now( );
auto byValueDurationNI = Seconds( end - start );
printf( "__declspec( noinline ) By value %lld in %f seconds\n",
byValueResultNI, byValueDurationNI.count( ) );
start = std::chrono::high_resolution_clock::now( );
auto byRefResult = ByRefTest( 0LL );
end = std::chrono::high_resolution_clock::now( );
auto byRefDuration = Seconds( end - start );
printf( "By ref %lld in %f seconds\n", byRefResult, byRefDuration.count( ) );
start = std::chrono::high_resolution_clock::now( );
auto byValueResult = ByValueTest( 0LL );
end = std::chrono::high_resolution_clock::now( );
auto byValueDuration = Seconds( end - start );
printf( "By value %lld in %f seconds\n", byValueResult, byValueDuration.count( ) );
}
The thing is that the arithmetic performed by the test above is not observable, even at the timing level, and this is a fact that penetrates all the layers of the computer. This goes for the compiler, the runtime, and even the hardware. If it were to be observable, it would significantly limit the ability of the compiler and linker to generate optimized code, and when the code is executed, even the CPU will try to optimize the instructions and reorder them dynamically to achieve better performance – so the compiler would have to generate code that prevents this behavior too.
A Simple Solution
The std::chrono::high_resolution_clock::now( ) uses the _Query_perf_counter() function which is implemented in a separate DLL, prohibiting the compiler and linker from optimizing the implementation of this function when building the test executable. This is just the behavior I want for the benchmarks. So, the simple solution to the problem is to move the implementations of the functions I want to benchmark out of the test executable and into a separate DLL. Now, the compiler is free to generate the best code it can while building that DLL, and I only need to implement the timing inside the test executable:
template<typename F, typename ...Args>
void PerformanceOf( const char* preamble, F testFunction, Args&&... args )
{
using Seconds = std::chrono::duration<double, std::chrono::seconds::period>;
auto start = std::chrono::high_resolution_clock::now( );
auto testResult = testFunction( std::forward<Args>( args )... );
auto end = std::chrono::high_resolution_clock::now( );
auto testDuration = Seconds( end - start );
printf( "%s %lld in %f seconds\n", preamble, testResult, testDuration.count() );
}
BOOST_AUTO_TEST_CASE( Int64ByRefOrValueTest )
{
PerformanceOf( "__declspec( noinline ) By ref", ByRefTestNI, 0 );
PerformanceOf( "__declspec( noinline ) By value", ByValueTestNI, 0 );
PerformanceOf( "By ref", ByRefTest, 0 );
PerformanceOf( "By value", ByValueTest, 0 );
PerformanceOf( "0 by ref", ByRef0Test );
PerformanceOf( "0 by value", ByValue0Test );
}
Since the compiler, now, cannot determine if there is any dependency between possible side effects of _Query_perf_counter() and any of the functions I am benchmarking, it must preserve the order of execution between the functions.
I also added two new functions that I would like to know the performance of to the DLL:
Int64 ByRef0Test( )
{
return ByRefTest( 0 );
}
Int64 ByValue0Test( )
{
return ByValueTest( 0 );
}
Executing this new test generates the following output:
__declspec( noinline ) By ref 10000000000 in 12.164413 seconds
__declspec( noinline ) By value 10000000000 in 0.001167 seconds
By ref 10000000000 in 0.000003 seconds
By value 10000000000 in 0.000005 seconds
0 by ref 10000000000 in 0.000000 seconds
0 by value 10000000000 in 0.000000 seconds
Since the machine code for the functions we are benchmarking is not visible to the compiler and linker, we can now be sure that the compiler is not moving things around in ways that trips up the timing, but we are still seeing zero execution time for something that is called 10 000 000 000 times in the code.
0x2540BE400 == 10000000000
All but the first function seems to execute unreasonably fast – and the cool thing is that this is caused by the Visual C++ optimizer.
By setting a breakpoint inside the ByRef0Test( ) function, executing the test, and then switch to disassembly view when the breakpoint is hit; I can inspect the generated optimized machine code:
mov rax,2540BE400h
ret
The optimizer was able to fully evaluate the implementation of the function at compile-time and inline the result.
The ByValue0Test( ) gets the same treatment, while the code generated for ByValueTest( const Int64 duration ) is slightly more complicated:
lea rdx,[rcx+0F4240h]
xor eax,eax
mov ecx,2710h
xchg ax,ax
ByValueTest+10h:
add rax,rdx
sub rcx,1
jne ByValueTest+10h
ret
Since 0x0F4240 == 1000000, we see that the effect of lea rdx,[rcx+0F4240h] is the same as the expected result of AddOneMillionByValue( duration ). The compiler also moved this out of the loop since the result will be the same for each iteration. It would have been nice if the compiler eliminated the loop entirely, but it seems that this is one of those surprising quirks we currently must live with.
It is not that the compiler is unable to perform this optimization, we have already seen that it did so as part of the code evaluation/generation for the ByRef0Test( ) function, but for some reason, it was unable to do so this time around.
std::string
std::string is, along with std::vector, one of the most popular template classes in the standard template library. So, it is interesting to get an idea about what kind of code the Visual C++ optimizer will generate for std::string.
The performance of passing around strings is perhaps the most important aspect of a string class, closely followed by taking the length of the string and comparing it with another string. Simple operations that are executed often, and usually spread all over the codebase.
The C++ core guidelines states that:
For “in” parameters, pass cheaply-copied types by value and others by reference to const
and provides the following example:
void f2(string s);
How bad is bad? I guess it surprises no one that this depends on the length of the strings. More importantly: Why is passing by reference good, and how good is good? It turns out that good is rather an understatement, with a pretty cool explanation.
Running the following test case:
BOOST_AUTO_TEST_CASE( StringByRefOrValueTest )
{
std::vector<std::string> emptyStrings{ "","","","","" };
std::vector<std::string> shortStrings{ "Lorem","ipsum","dolor","sit","amet" };
std::vector<std::string> longStrings
{
"Lorem ipsum dolor sit amet",
"consectetur adipiscing elit",
"sed do eiusmod tempor incididunt ut labore et dolore magna aliqua",
"Ut enim ad minim veniam",
"quis nostrud exercitation ullamco laboris "
"nisi ut aliquip ex ea commodo consequat"
};
PerformanceOf( "Empty strings by ref", ByRefTest, emptyStrings );
PerformanceOf( "Empty strings by value", ByValueTest, emptyStrings );
PerformanceOf("Short strings by ref", ByRefTest, shortStrings );
PerformanceOf( "Short strings by value", ByValueTest, shortStrings );
PerformanceOf( "Long strings by ref", ByRefTest, longStrings );
PerformanceOf( "Long strings by value", ByValueTest, longStrings );
}
Generates this output:
Empty strings by ref 0 in 1.783655 seconds
Empty strings by value 0 in 6.593396 seconds
Short strings by ref 22000000000 in 1.766007 seconds
Short strings by value 22000000000 in 6.623428 seconds
Long strings by ref 222000000000 in 1.776283 seconds
Long strings by value 222000000000 in 254.736168 seconds
Which, unsurprisingly, demonstrates that passing std::string by reference outperforms passing by value. Even when small string optimization is performing its magic, passing by reference is about 377% faster than passing by value.
The real difference between the two implementations is that:
size_t GetLengthByRef( const std::string& s )
{
size_t length = s.length( );
return length;
}
takes its argument by reference, while...
size_t GetLengthByValue( const std::string s )
{
size_t length = s.length( );
return length;
}
...takes its argument by value. The rest is pretty much identical:
size_t CalcLengthsAMillionTimesByRef( const std::vector<std::string>& strings )
{
size_t result = 0;
for ( size_t i = 0; i < 1000000; ++i )
{
for ( const std::string& s : strings )
{
result += GetLengthByRef( s );
}
}
return result;
}
size_t ByRefTest( const std::vector<std::string>& strings )
{
size_t result = 0;
for ( size_t i = 0; i < 1000; ++i )
{
result += CalcLengthsAMillionTimesByRef( strings );
}
return result;
}
With the above code in mind, think carefully about this output:
Short strings by ref 22000000000 in 1.751123 seconds
The argument vector contains 5 strings, and the code above fetches the length of each of those 5 strings and add that to the result 1 000 000 000 times during a run of ByRefTest.
Here is a slightly cleaned up version of the compiler generated assembly for CalcLengthsAMillionTimesByRef:
mov r9, QWORD PTR [rcx]
xor eax, eax
mov rdx, QWORD PTR [rcx+8]
mov r8d, 1000000
npad 1
for1000000:
mov rcx, r9
cmp r9, rdx
je SHORT endOfStrings
npad 8
forStrings:
add rax, QWORD PTR [rcx+16]
add rcx, 32
cmp rcx, rdx
jne SHORT forStrings
endOfStrings:
sub r8, 1
jne SHORT for1000000
ret 0
The optimizer determined that the result strings.begin() and strings.end() will not change during the execution of the function, and move those two operations to the beginning of the function, the rest is nice and tight assembly code.
The inner loop is executed (5 x 1 000 000 000) / 1.751123 = 2 855 310 564 times per second, while the outer loop is executed 571 062 113 times per second. By counting the number of instructions, and multiplying accordingly, it seems like the CPU is capable of executing 14 276 552 818 instructions per second on a single core.
The Windows task manager reports that the CPU is running at 4.24 GHz, which translates to 4 210 000 000 Hz, or clock cycles per second – and I am running the benchmarks on a system with a Xeon E-2176M CPU.
Apparently, the CPU is executing about 3.4 instructions per cycle - a clear indication that the instruction level parallelism capabilities of the processor is doing its magic.
With a bit of reasoning using the information provided above, it is possible to provide an educated guess about how this works out. So, getting back to the assembly for the inner loop:
forStrings:
add rax, QWORD PTR [rcx+16]
add rcx, 32
cmp rcx, rdx
jne SHORT forStrings
For the first iteration of the loop, the two first instructions are independent of each other and can be executed in parallel, and the cmp and jne instructions will be fused into a single micro-op. At the same time, the CPU is executing the micro-op for the fused cmp+jne, the branch predictor has decided to use speculative execution to execute the two add instructions for the next round of the loop in parallel. The first add depends on the second add from the previous iteration, as does the second add, while the fused cmp+jne depends on the second add from the current iteration, but once the loop gets started, everything can be executed in parallel – allowing each iteration of the loop to be executed in a single cycle. The CPU can also evaluate:
endOfStrings:
sub r8, 1
jne SHORT for1000000
in parallel with the evaluation of the inner loop. When it comes to the start of the outer loop:
for1000000:
mov rcx, r9
cmp r9, rdx
je SHORT endOfStrings
The mov and cmp instructions are independent of each other, and the cmp instruction will be fused with the je instruction, allowing this part of the outer loop to be executed in a single cycle too.
At this point, it is clear that the Visual C++ optimizer generates machine code that works really well with the instruction level parallelism features of the processor.
By passing an object by reference, we tell the compiler that there really is an object at this address, which is something that compiler can use to its advantage while inlining the code.
The code for the by value case is not really bad either: 6.524365 seconds is fast, particularly in the light of how much more that code has to be able to do. The generated assembly listing contains 274 lines of assembly code, which is quite a bit more than the 17 lines that was generated for the by reference case.
History
- 25th August, 2020 - Initial posting









 General
General  News
News  Suggestion
Suggestion  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin