|
Would it be oh-so-much trouble to explain what these club card points are/do/buy/win ?
In US, most supermarkets have a club card - it's primary purpose (most of the year) is to gather information about your buying habits by making scanning it a requirement for the best discounts (typically advertised as "with card" in small print near the price).
Now occasionally, like those which just passed, some cards accumulate spending totals between certain dates (excluding certain items, like beer, cigarettes) and give you some large food item if you spend enough (often tiered, as well). I've no use for a dead turkey or pig's buttocks, so I don't every get that award.
But what do you get for 1000 club points that would make you get up and change out of your work-from-home garb (Unless you normally dress as a hun)?
| Ravings en masse^ |
|---|
| "The difference between genius and stupidity is that genius has its limits." - Albert Einstein | | "If you are searching for perfection in others, then you seek disappointment. If you seek perfection in yourself, then you will find failure." - Balboos HaGadol Mar 2010 |
|
|
|
|
|
The Club card itself is - just as yours are - an info gathering system, but each time you use it to buy groceries, or fuel, or insurance, or ... whatever the supermarket provides ... the bill total gets added to a total, which is converted to points at a ratio of £1 spent == 1 point (except fuel where it's £2 spent == 1 point). Every three months those points are converted to a cash-equivalent voucher which can be deducted from a shopping bill (at a rate of 100 points == £1 discount). With the average family shop coming out are around £600 per month and with fuel costs, it can mean some good "not-quite-cash back".
1000 Club Card points is £10.
What can I say? I work cheap for a costume! 
"I have no idea what I did, but I'm taking full credit for it." - ThisOldTony
"Common sense is so rare these days, it should be classified as a super power" - Random T-shirt
AntiTwitter: @DalekDave is now a follower!
|
|
|
|
|
I work most of those cash-back points through my credit cards. It's normally at 1% of monthly net spending - but it can include enhancements.
Yahoo Visa: 3% at Yahoo, 2% for Gas Stations (fuel, repairs), Groceries, and pharmacies; 1% elsewhere
Freedom Visa: 1% but quarterly rotating categories for 5%;
Discover Plus (like Freedom Visa, but I cancelled them for being idiots).
Bank of America Mastercard and Visa: 1%, but 3% in a category you can change once/month (any day you wish during month) for 3%;
Other places offer their own version, but the "points->$" conversion is only for in-store purchases (like Costco). Sound's like yours. For Costco, to make it worse, you not only have to be a paid-member, but they only award your points annually, in February. Screw them.
Now, today, I'm actually getting a new card delivered - a Bank of America card - which gives me $200 cash back if I spend $1000 in the first three months. I'll pay my car insurance, due in a few days, with it and I have 20,000 of their points plus the normal 1% back (ca. 1400 more points).*
So - you see - if I can spend enough money I can live off the savings !
(*Logical Extrapolation: you'd wear a sequined tutu for that kind of money!)
| Ravings en masse^ |
|---|
| "The difference between genius and stupidity is that genius has its limits." - Albert Einstein | | "If you are searching for perfection in others, then you seek disappointment. If you seek perfection in yourself, then you will find failure." - Balboos HaGadol Mar 2010 |
|
|
|
|
|
W∴ Balboos, GHB wrote: you'd wear a sequined tutu for that kind of money!
What?
Again?
"I have no idea what I did, but I'm taking full credit for it." - ThisOldTony
"Common sense is so rare these days, it should be classified as a super power" - Random T-shirt
AntiTwitter: @DalekDave is now a follower!
|
|
|
|
|
I've now entered bizarro land, and I'm programming without conditional branching in code.
That means no ifs, no whiles, no dos.
Superscalar architectures use branch prediction to get way out in front of your instructions - basically it executes ahead - which is cool when it gets it right, but costly when it realizes it has been executing the wrong code this time around.
So one way to prevent branch mispredictions is to ... wait for it! avoid branching.
so instead of say, writing
if(0!=foo)
printf("foo\r\n");
else
printf("bar\r\n");
you do like
const char* szfoo="foo";
const char* szbar="bar";
printf("%s\r\n",(szfoo*!!foo)+(szbar*!!(!foo)));
or something to that effect.
printf() probably branches anyway, but I'm just trying to illustrate a concept.
The weird thing is, it generates more, and slower code, because you have to do a bunch of calculations any time you want to simulate branching.
However, they have SIMD which loves branchless code, and can often be used to "pay for" the extra overhead of those computations.
It's funny when you think about it, because effectively, to let the CPU get way out ahead you have to perform a bunch of extra multiplies and adds, that you essentially waste, but it doesn't matter because you're doing 4 of them at a time, and wasting 2 or 3.
So you break even cycle per cycle on the branchless code, but the CPU still executes it faster because of branch prediction, prefetching, and all of that.
Or at least that's how i understand it so far. I'm learning a lot from the simdjson developers.
Fun times.
Real programmers use butterflies
|
|
|
|
|
Yesterday I stumbled across this[^], about C++20 adding [[likely]] and [[unlikely]] to give compilers hints about this kind of thing. The proprietary language in which I worked for many years introduced the tags <usual> and <rare> in the early '90s for this purpose.
|
|
|
|
|
I think that seems like it has more to do with how the compiler arranges its jump tables, than how the CPU predicts branches, but I could be wrong, or could be talking about the same thing without realizing it.
I'm still new to this myself. I did a little SIMD before, but only for DSP stuff and you already don't need ifs for that.
Real programmers use butterflies
|
|
|
|
|
honey the codewitch wrote: I think that seems like it has more to do with how the compiler arranges its jump tables, than how the CPU predicts branches, but I could be wrong
Yep, that's exactly what it does. With MSVC you would use the _mm_prefetch intrinsic to ask the cpu to cache a memory address.
Probably best to avoid it. 
|
|
|
|
|
for my part, I'm avoiding those kinds of things, preferring to rely on optimizations present in (usually, and for reasons) the C stdlib like string.h's strpbrk() and math.h's max() function
however, in order to make those branchless implementations really work effectively i still have to avoid branching in my own code. I expect the compiler to take my branchless code and apply SIMD instructions to its implementation of it.
Real programmers use butterflies
|
|
|
|
|
I never got into the details but simply recall that, at least on that system, it allowed the mainline path to avoid branching, which made the code run faster.
|
|
|
|
|
likely & unlikely are used so the optimiser can reorder code around conditional branches to suit the CPU best - this blog post gives some background & some performance measurements.
Java, Basic, who cares - it's all a bunch of tree-hugging hippy cr*p
|
|
|
|
|
yeah, that's what i thought. basically, so it can build better jump tables and such.
Real programmers use butterflies
|
|
|
|
|
No, it affects the code sequences generated by the compiler. Consider these two functions:
unsigned count;
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
unsigned f1(unsigned x) {
if (likely(x > count)) {
++count;
} else {
--count;
}
return count;
}
unsigned f2(unsigned x) {
if (unlikely(x > count)) {
++count;
} else {
--count;
}
return count;
}
The use of likely vs unlikely causes different code to be generated for the two functions (this is with clang 11, with the -O3 flag). In f1, there's a branch to the --count case, while in f2, there's a branch to the ++count case - in each case, there's a branch to the code considered to be 'unlikely', whereas the control flow just falls through the branch instruction to the 'likely' case. No jump tables here.
f1(unsigned int): # <a href="https://www.codeproject.com/Members/F1">@f1</a>(unsigned int)
mov ecx, dword ptr [rip + count]
cmp ecx, edi
setb dl
mov eax, 1
test dl, 1
je .LBB0_1
add eax, ecx
mov dword ptr [rip + count], eax
ret
.LBB0_1:
mov eax, -1
add eax, ecx
mov dword ptr [rip + count], eax
ret
f2(unsigned int): # <a href="https://www.codeproject.com/Members/f2">@f2</a>(unsigned int)
mov ecx, dword ptr [rip + count]
cmp ecx, edi
setb al
test al, 1
jne .LBB1_1
mov eax, -1
add eax, ecx
mov dword ptr [rip + count], eax
ret
.LBB1_1:
mov eax, 1
add eax, ecx
mov dword ptr [rip + count], eax
ret
count:
.long 0 # 0x0
You can find this on Compiler Explorer.
Java, Basic, who cares - it's all a bunch of tree-hugging hippy cr*p
|
|
|
|
|
I mean, to me that's still a jump table, just with two entries - one of which falls through. I wonder how the compiler would generate code for more cases?
Admittedly, I'm using the term maybe loosely, as I tend to think very abstractly, so if something feels like a jump table then i have no problem calling it that.
My point in making the distinction anyway, is my comment to Greg Utas i was making the distinction between code like this (whether an actual "jump table" or just two possibilities) nd what i was initially talking about, which is enabling branch prediction - a different animal. i don't think likely and unlikely directly impact branch prediction (although they likely do indirectly) - they affect the order the jumps come in, as your code basically demonstrates.
Adding, I probably should have said jump order, and part of the reason i didn't is i first learned about it in the context of switch/case
Real programmers use butterflies
modified 4-Jan-21 13:15pm.
|
|
|
|
|
I'm not really sure if he knows what the jump table is. There are two instructions in his example that would be added to the jump table.
But to be fair... programmers don't necessarily need to know these things.
|
|
|
|
|
Well I've only recently had occasion to learn about this stuff in a concrete sense. I mean, I understood some of the basic concepts of superscalar architectures with branch prediction and SIMD, but nothing specifically about actually coding against them effectively.
But it seems to me like the order of the jumps doesn't (or shouldn't?) impact the branch prediction much if at all.
That's why I said that likely/unlikely probably effect jump order rather than branch prediction (though maybe it impacts it indirectly, if jump order actually matters to the CPU for something more than evaluation order)
I'm saying this to you now, because clearly you know about this stuff. So please correct me if I'm wrong.
Real programmers use butterflies
|
|
|
|
|
honey the codewitch wrote: But it seems to me like the order of the jumps doesn't (or shouldn't?) impact the branch prediction much if at all.
The order in which your compiler emits jump instructions absolutely matter. The optimizing pass attempts to determine which branches are most likely to be used and reorders instructions. The likely and unlikely keywords now allow the programmer to have some control over that.
honey the codewitch wrote: That's why I said that likely/unlikely probably effect jump order rather than branch prediction (though maybe it impacts it indirectly, if jump order actually matters to the CPU for something more than evaluation order)
yeah, by adjusting the jump order it has an affect on branch prediction.
|
|
|
|
|
That's good to know. I guess that means unoptimized jump orders in C++ code *really* hurts, instead of just kind of.
That's sort of unfortunate though, because there are many cases in a codepath where an if will be evaluated most often true with one use case, and most often false with another. Assuming what you're saying is true, the CPU is going to suck at one of these.
Real programmers use butterflies
|
|
|
|
|
honey the codewitch wrote: That's sort of unfortunate though, because there are many cases in a codepath where an if will be evaluated most often true with one use case, and most often false
I mean... some of this is just common sense. Imagine that you have a switch statement with 100 cases. 99 of those cases occur 0.1% of the time, the other case occurs 99.9% of the time. In the old days (on old hardware before pipelining and branch prediction) we had to remember to optimize our switch statements so the most common case is at the top.
It's not as relevant today because the address of the most used case will most likely be present in the instruction pipeline. In fact it will have probably already been fetched and speculatively executed.
|
|
|
|
|
Ah, that makes sense. There's sure a lot of thinking around corners required when it comes to understanding what the CPU is doing with your instructions on a superscalar architecture.
Real programmers use butterflies
|
|
|
|
|
honey the codewitch wrote: Ah, that makes sense.
Can you tell me why the most used case will already be present in the instruction pipeline? And also why that address will most likely have been speculatively executed? (The 100 case switch statement)
Yes, this is a quiz to check if you really understood. 
|
|
|
|
|
If I understand your question, and the problem correctly, then because of locality. The code would be in the cache. And based on what you said before, it uses history to predict, but most recently you also said it would rely on branch order - i am a little unclear on that, but right now I'm assuming you mean it uses both, which seems likely.
Real programmers use butterflies
|
|
|
|
|
honey the codewitch wrote: it uses history to predict
Yeah, the 'jump table' would most likely have that address with a weighted score.
honey the codewitch wrote: but most recently you also said it would rely on branch order - i am a little unclear on that
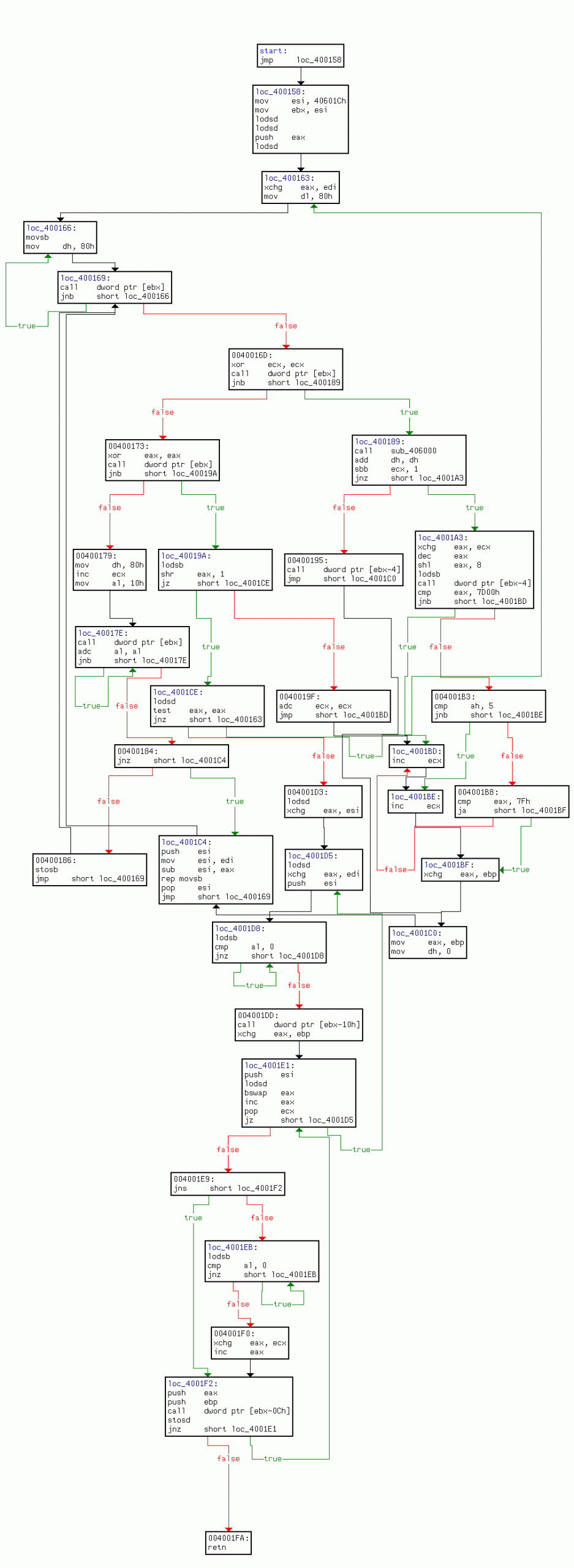
I think looking at executables as a visual graph[^] make it easier to understand. The cpu does not have any control over branch ordering. Your compiler/linker controls this. This entire conversation was about how likely and unlikely keywords affect that ordering. And how that influences branch prediction.
Anyway, I am falling behind in my work, gotta go
|
|
|
|
|
Randor wrote: The cpu does not have any control over branch ordering. Your compiler/linker controls this.
Yeah, I understand that. What I'm saying is you seemed to be saying that the CPU relies on the order those branches appear in the instruction stream in order to predict. I heard you as saying it would favor the first one it encountered. Maybe I misunderstood you.
Randor wrote: Anyway, I am falling behind in my work, gotta go
Don't work too hard.
Real programmers use butterflies
|
|
|
|
|
Stuart,
We are discussing jump tables in the CPU related to branch prediction. There are two address locations in the example you have given that would be added to the jump table. Both the je and jne would result in a jump table entry. It's actually extremely easy to understand:
Branch prediction basically works like this: (note that this is a simplification and each vendor does it differently)
- As your program is executing the CPU tracks each and every time a jump instruction has executed. It keeps a table of the address of these jumps and increments an internal counter each time that jump instruction is executed.
- As executable code is being loaded and cached, the cpu attempts to predict which path will be executed. It uses that internal counter as a 'weight'. In other words previous taken paths have a higher probability of being chosen. If it incorrectly predicts a path... this is known as a branch misprediction. After a misprediction the cpu has to throw away everything it just computed and go back and predict the path again until it gets it right.(This is actually the core problem with the spectre vulnerability[^]) as you can look at the timing and use very small intervals of time to know what is inside the cpu cache.
The likely and unlikely keywords effect the ordering of the jump instructions in such a way so that branch prediction will be more accurate.
Best Wishes,
-David Delaune
modified 5-Jan-21 3:48am.
|
|
|
|
|




 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 








{kind=link}