|
Here's a little test for you.
Does this code compile?
public interface IStorage{
int Save();
}
public interface IPersist{
int Save();
}
public class SaveImplementor : IStorage, IPersist{
public int Save(){
return 1;
}
}
I'm implementing two interfaces which contain the same virtual method signature.
Well, it seems a little odd to me.
Obviously, if you want the separate implementations you have to write them explicitly.
Like this:
public class SaveImplementor : IStorage, IPersist{
int IStorage.Save(){
return 1;
}
int IPersist.Save(){
return 2;
}
}
IMPORTANT NOTE: Notice that in the first example you HAVE to include the public modifier on the method implementation.
HOWEVER, on the second example where you explicitly implement the Interface method you CANNOT include the public modifier.
I'm filing this one under weird.
But, I guess I accept it. I have to, or else the C# compiler doesn't accept me. 
Answer - The first example does indeed compile.
EDIT
Oh, and after I posted that, I went back and new'd up a SaveImplementor() and then I couldn't figure out how to call either of those explicit methods.
Hmm... It's got me thinking now.
EDIT 2
Here's the simple example that explains the explicit implementation: Explicit Interface Implementation - C# Programming Guide - C# | Microsoft Learn[^] .
modified 19hrs ago.
|
|
|
|
|
raddevus wrote: Oh, and after I posted that, I went back and new'd up a SaveImplementor() and then I couldn't figure out how to call either of those explicit methods.
Hmm... It's got me thinking now.
((IPersist)saveImplementor).Save()
((IStorage)saveImplementor).Save()
If I'm remembering correctly, saveImplementor.Save() raw won't work in the second EII example, you'd have to ALSO have a public int Save() {}. I believe this is because EII implementations are ad-hoc polymorphic, the implementation differs depending on the type-view/cast of the object - as opposed to the standard implicit ones which are parametric polymorphic, so its the same implementation for every type-view/cast of the object.
Honestly it's been a long time since I've seen EII used because of this weird behavior. It makes it so you can have an object that seems to completely change it's class/behavior with a simple cast, AND all that new behavior is completely hidden from all other casts of the SAME object.
|
|
|
|
|
... after a frustrating week, this could be taken as a general rant at the quality of open-source software with applications to particular pieces.
Given enough eyeballs, where are those eyeballs looking? Surely not at libpng[^] - the reference implementation for the PNG format. It is a smallish library of about 20 kLOC but the configuration file with all the possible options has over 200 different options. That makes for 200x200 = 40k potentially different ways you could build the library. Either that or some of the options are redundant.
The code quality is atrocious. I understand that it's a project started in the '90es but that's no excuse for not cleaning it up from time to time. You cannot let one test program get to 12000 lines in a single file. And those 12000 lines are full of miracles like parameters and structure members called this! Don't you worry! At the beginning of the file there is this fragment:
#ifdef __cplusplus
# define this not_the_cpp_this
# define new not_the_cpp_new 
Also, if the byzantine compile time configuration options make it impossible for the program to run would you think of throwing an error using a #error directive? NO, good quality open-source code just wraps the whole program in an #if block with the #else clause, 12000 lines below:
#else /* write or low level APIs not supported */
int main(void)
{
fprintf(stderr,
"pngvalid: no low level write support in libpng, all tests skipped\n");
return SKIP;
}
#endifRemember: these are compile time conditions; why would you fail at run time?
Have you heard of semantic versioning? Well, check this out (straight from the LIBPNG) web site:
Quote: At present, there are eight branches:
master (actively developed)
libpng16 (equivalent to master)
libpng17 (frozen, last updated on 2017-Sep-03)
libpng15 (frozen, last updated on 2017-Sep-28)
libpng14 (frozen, last updated on 2017-Sep-28)
libpng12 (frozen, last updated on 2017-Sep-28)
libpng10 (frozen, last updated on 2017-Aug-24)
libpng00 (frozen, last updated on 1998-Mar-08)
These translate in version numbers as 1.6.x, 1.7.x, 1.5.x, and so on. So, let me get this straight: version 1.7 is frozen and version 1.6 is actively developed? Have you guys ran out of numbers? And, guess what, in code you find many tests like these:
#if PNG_LIBPNG_VER >= 10700
if (!for_background && image->bit_depth < 8)
image->bit_depth = image->sample_depth = 8;
#endif???
I will stop here although, after a week of frustrations, I could go on and on.
There is a well-known commencement speech: Make your own bed - University of Texas at Austin 2014 Commencement Address - Admiral William H. McRaven - YouTube[^]. As a developer, and specially as an open-source maintainer, before writing a single line of new code, do everyone a favour: clean the project you are working on; make your own bed!
Mircea
modified 4 days ago.
|
|
|
|
|
Thanks for the amusing rant!
You're saying the implementation of the PNG format is only 20 KLOCs and is a hacked together PoS written in C? I'm stunned no one has rewritten it. That was something that regularly gave me joy! But let me guess. Obscure corners of the spec for which no test images exist? People who'd scream about a breaking change that forced them to revisit magic settings for 200 options? Or just, "if it ain't broke, don't fix it"--which makes sense if it's not seeing new development, but it sounds like it is. And that many developers contributing to it over a long period of time were fearful of breaking it, so most (or all, because of a "policy") enabled their new code with a new option?
|
|
|
|
|
C:\development\png\src>cloc *.c
15 text files.
15 unique files.
0 files ignored.
github.com/AlDanial/cloc v 2.00 T=0.11 s (134.0 files/s, 275793.4 lines/s)
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
C 15 4626 5400 20838
-------------------------------------------------------------------------------
SUM: 15 4626 5400 20838
-------------------------------------------------------------------------------
Greg Utas wrote: is a hacked together PoS written in C?
I wouldn't go to call it a PoS, but certainly in dire need of a cleanup.
Mircea
|
|
|
|
|
There's actually a reasonable number of comments and blanks!
|
|
|
|
|
|
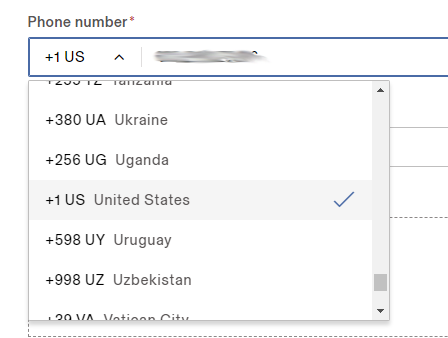
...or the similar ones that don't have a scroll thumb (just arrows), but being "nice to people", open at the default of USA.
Australian sites, for ![Elephant | [mastadon]](https://codeproject.global.ssl.fastly.net/script/Forums/Images/elephant.gif) sake. click, click, click, click.... sake. click, click, click, click....
Software rusts. Simon Stephenson, ca 1994. So does this signature. me, 2012
|
|
|
|
|
Also think about the poor Canadians
|
|
|
|
|
I want to see the data storage for this ui... Do you have to join two tables to get the full phone number. This will be a piece of code they look back on and hopefully say, what was I thinking!
Table: Address
int CountryCodeID
string PhoneNumber
Table: CountryCode
int CountryCodeID
string CountryCode
Hogan
|
|
|
|
|
PIEBALDconsult wrote: Requiring the country code seems unusual (for a site in the U.S.)
What do you mean - is there anything outside the USA? Do they have telephones as well? Really?? 
-- but what would prompt a web developer to make it an elephanting drop-down?! I guess that even a lot of Europeans do not know the phone country code of their homeland. I guess that a lot of USA citizens, if they had to call home when on a dangerous vacation trip to The Primitive World outside USA, would go straight ahead with their US number, unaware that they have to prefix it with +1. On a landline phone, that might be 001, or 0951 (that's in Norway, up until 20-30 years ago), or something else. Even when told about the '+1', many would not know the meaning of the 1, but view the whole prefix as a deficiency of the country's phone system.
So, I think this drop down list, displaying both the code, so that users learn it, and the name of the country, for those who are not sure about the code, is a really good idea. It is not possible to see from the screenshot if you are allowed to type the code directly without using the pulldown list. Users who know their country code with 110% certainty would most likely prefer that - but maybe their memory has a bit error, or they make a typing mistake, so they specify an unused code or the code of a completely different country. The pulldown list is one way for the software to ensure that a valid number is entered. And, the selected value can display the country: Users from other countries might leave a '+1' untouched without noticing. They are much more likely to notice '+1 (US)': But I am not in the US!
The UI isn't really that bad, in my eyes. I think what I saw yesterday was far worse: I sent a notice through the web pages of the Norwegian Automobile Owners Association. The form had entries for name, email, and membership number: The membership number field was a spin control starting at -1. I did not let it spin up to my number (a value for the field was not mandatory) 
Religious freedom is the freedom to say that two plus two make five.
|
|
|
|
|
The other day I wrote an SQL function with a bug of the following form:
DECLARE @i INTEGER = 0
WHILE ( @i < foo )
BEGIN
IF
BEGIN
SET @i = @i + 1
END
END
I expected the function to be inefficient, but not infinite the first time the test returns false. 
|
|
|
|
|
if your condition is never met (or not met "foo" times), your loop control will never increment (or not increment enough to break on the condition), thus the loop will be infinite.
".45 ACP - because shooting twice is just silly" - JSOP, 2010
-----
You can never have too much ammo - unless you're swimming, or on fire. - JSOP, 2010
-----
When you pry the gun from my cold dead hands, be careful - the barrel will be very hot. - JSOP, 2013
|
|
|
|
|
I think its a bad idea. SQL is the wrong place to perform that type of logic. If you can't perform it in a set type of operation, then move it out of SQL. Working with this limitation has made my SQL skills stronger and encouraged me to think differently about modifying data.
I get that there are exceptions and if you have to do it in SQL, it already has cursors.
Hogan
|
|
|
|
|
Absolutely. I'm a huge proponent of not doing the kinds of thing I'm doing at the moment in SQL*, but I'd rather have it for when it makes some sense.
snorkie wrote: think differently about modifying data
Which isn't what I'm doing in this particular case.
snorkie wrote: it already has cursors
Certainly, but still not applicable to this particular case.
* This is just a quick-and-dirty little investigation into some data analysis. I might re-write these functions in C#, but it's really not worth the effort.
|
|
|
|
|
I worked at a company who preferred to do as much as possible in SQL Server.
A stored procedure, as they claimed, is easy to change in production and you can write business logic in the one place where every user action ultimately ends up in: the database.
The client applications were all WinForms.
Of course, all of this is a fallacy.
Yes, it's easy to change a view or stored procedure in production (we could make the change and hit F5), but the question is why wouldn't software be easy to update?
This was about 10 to 14 years ago, but this company did not have DevOps practices and every deployment was manual work, which also required users to restart the software (which was of course pretty common at the time).
That last part is a nuisance which really can't be helped at this point (unless you use stored procedures), but having a difficult and manual deployment process can be helped and should be helped.
Which would remove a part of the need for stored procedures and logic in your database.
The second reason, having everything in one place, can of course be solved by using services in a server-client, service-oriented and/or microservices architecture.
And when you have services doing all the logic, you don't have to restart client applications either.
Now, instead of using stored procedures and views you can use a service instead.
A service is easy to debug, easy to put in source control and easy to automatically deploy, unlike SQL code.
And you never have the risk of updating the wrong thing either (which happened from time to time) because you're simply not messing around in production environment "on the fly".
So, I've made a choice to let a database do what it does best, store data, and keep it as "dumb" as possible.
Everything else is handled by applications and services 
|
|
|
|
|
Sander Rossel wrote: easy to change in production
That's my main argument against putting code in the database.
Auditing what code is where becomes difficult. I've had to write systems for comparing procedures and functions between environments to ensure that what we thought was in production actually was.
It would also be true of other systems where you don't deploy compiled executables -- e.g. Python.
Sander Rossel wrote: a choice to let a database do what it does best, store data, and keep it as "dumb" as possible.
Totally agree.
But, I still argue for having tools. What I'm working on is just an idle curiosity.
|
|
|
|
|
PIEBALDconsult wrote: comparing procedures and functions between environments to ensure that what we thought was in production actually was.
Been there, done that 
|
|
|
|
|
Like with so much, I think it's a bit more of an "it depends".
Database engines are very good at retrieving complex indexed data structures quickly.
I don't know if there are any tests out there but I reckon for very large datasets, with multiple joins, a database engine probably still beats using something like Entity Framework - happy to be shown to be wrong on this.
So I think for small simple datasets - yes, placing all the logic inside the service probably does make sense.
“That which can be asserted without evidence, can be dismissed without evidence.”
― Christopher Hitchens
|
|
|
|
|
Yeah, but EF can just as well generate queries and let the database handle the retrieval.
But you're right, in some cases writing a stored procedure could be more performant.
Although EF has been getting better in that regard (like there are built-in DeleteAsync and UpdateAsync methods).
|
|
|
|
|
GuyThiebaut wrote: I don't know if there are any tests out there but I reckon for very large datasets, with multiple joins, a database engine probably still beats using something like Entity Framework
Not a standard test by any means, but definitely proven in my applications where I've used stored procedures as against queries within the software.
Happiness will never come to those who fail to appreciate what they already have. -Anon
And those who were seen dancing were thought to be insane by those who could not hear the music. -Frederick Nietzsche
|
|
|
|
|
It's kind of a nasty alternative, admittedly, but I'm used to it because of a c pattern I employ all the time
while(count--) { ... }
I think because I'm so used to dealing with that I spotted your bug right away.
These days I prefer to generate SQL, DML and DDL code because it's so sloppy, like JS. Really it should be transpiled from something more modern and cohesive.
Check out my IoT graphics library here:
https://honeythecodewitch.com/gfx
And my IoT UI/User Experience library here:
https://honeythecodewitch.com/uix
|
|
|
|
|
honey the codewitch wrote: It's kind of a nasty alternative, admittedly, but I'm used to it because of a c pattern I employ all the time
C++
while(count--) { ... }
Or, for a slightly more readable (but slightly less efficient) code construct, you can use the fake 'down to' / 'tends to' operator -->. It works in C, C#, JavaScript and other C derived languages but it does not actually exist as an operator. e.g.
while (count --> 0) { ... } as it is just an unusually laid out version of
while ((count--) > 0) { ... } and the test for > 0 is redundant as when count is positive the result is already true and when 0 it is already false.
One useful feature of the --> operator is that it allows counting down to non-zero endpoints as well as just down to zero.
|
|
|
|
|
I had used Windows since 3.0 (ca 1991) before I switched to main usage of Linux in 2019 so please don't make fun of me for this too much.
I've been working on setting up my .NET Core WebAPIs (hosted under various domains but running on one copy of a DigitalOcean droplet (running Debian)) and setting up the services and forwarding via Nginx and all that. It's all command-line there are a lot of steps that I forget often.
1. set up a service file in /etc/systemd/system/
2. build the WebAPI and deploy it under a folder in /var/www/
3. configure nginx to point at your webAPI
4. create link to the nginx config ln -s /etc/nginx/sites-available/<apiName> /etc/nginx/sites-enabled/
There's a bunch of things and I would lose the commands and forget things I should do.
And, I be forever up-arrowing to get to old commands that I had used.
.bash_history
Then I stumbled upon the .bash_history file and noticed I can open it up in an editor (nano, of course, because I am vim-weak and don't know how to exit vim  ) )
Wow, that is really cool that all those commands are just sitting in there like that so I can now pull them out and save them to a file with some documentation.
Thank you, Linux, it seems like you get better all the time.
I bet you already knew about .bash_history didn't you? Well, try not to laugh at me too hard for only finding it now.
|
|
|
|
|
A couple of pointers:
!$ is the last argument of the last command e.g.
$ cat foo.bar
$ nano !$
!! repeats the last command
CTRL+r does a reverse search through your history so
$ CTRL+rfoo
searches backwards through your history for the most recent command with "foo" somewhere in it, so it might match
nano foo.bar or setfoobar able baker charlierepeating [CTL-R] searches to the next previous, etc.
There's a whole bunch of other things you can do, but those are the ones I use most often
"A little song, a little dance, a little seltzer down your pants"
Chuckles the clown
|
|
|
|
|




 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 









{kind=link}