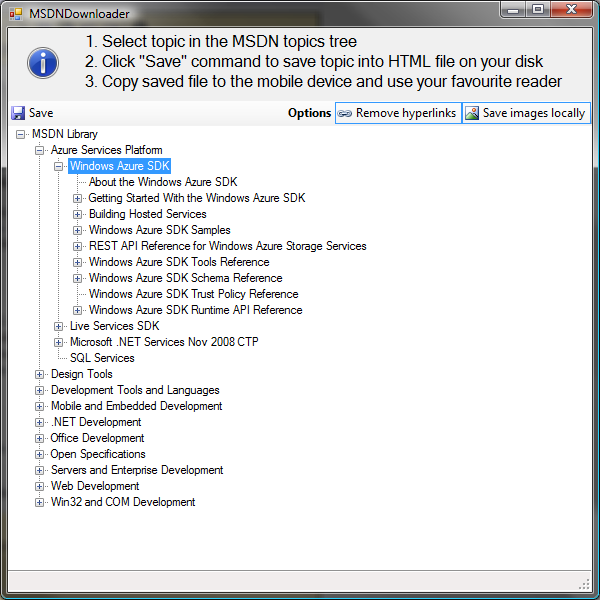
Introduction
I needed to read MSDN while I'm on train using my Windows Mobile 6 device. I found a decent reader which can read HTML files, but I had no HTML file to read.
This tool uses WinForms and the WebBrowser control to show the MSDN topics tree. You can select a topic and save it with all the subtopics into a single HTML file. The tool will extract important content from each topic and can do some optional reformatting. The output file can be read offline on mobile devices.
Background
Direct reading from web was not an option for me. I decided to download content from MSDN. But, it is presented as many small pages; downloading manually was not an option too. Using web site downloaders was not a good idea either because they do not understand the MSDN topics structure and they will download whole pages, while I was only interested in the content (without the headers or footers).
I was interested in quick development, so I didn't bother making a multithreaded application or splitting the app into many abstract layers.
Using the tool
To use the tool, just run it and read the instructions on the top. Beware, attempting to save the whole MSDN may take a very long time...
Using the code
First of all, we must present to the user a tree of MSDN topics. I'm not aware about any web service that can give such information, so I decided to host a webBrowserSelector web browser control, open MSDN home page there, and extract the table of contents from the page. After looking at an MSDN page in HTML, I noticed that the table of contents started on the element with id=tocVectorTreeId.
void webBrowserSelector_DocumentCompleted(object sender,
WebBrowserDocumentCompletedEventArgs e)
{
...
AddChildren(treeViewToc.Nodes,
webBrowserSelector.Document.GetElementById("tocVectorTreeId"));
...
}
The AddChildren() method adds children to the tree node and binds them with subtopics found in the browser. When the user clicks on the Expand Node button, we must do a similar click in our hidden web browser to expand the subtopics and copy them to the tree view:
void treeViewToc_BeforeExpand(object sender, TreeViewCancelEventArgs e)
{
if (e.Node.Nodes.Count == 1 &&
e.Node.Nodes[0].Tag == null)
{
e.Node.TreeView.BeginUpdate();
e.Node.Nodes.Clear();
AddGrandchildren(e.Node, true);
e.Node.TreeView.EndUpdate();
}
}
Each topic node in the MSDN HTML has this structure:

If the IMG element has class='LibC_c', then this is a topic that might have children, but they are not loaded yet. To load them, we must simulate a user click on it:
foreach (HtmlElement child in
from HtmlElement element in topicElement.Children
where
"IMG".Equals(element.TagName,
StringComparison.InvariantCultureIgnoreCase) &&
"LibC_c".Equals(element.GetAttribute("className"),
StringComparison.InvariantCultureIgnoreCase)
select element)
{
child.InvokeMember("click");
}
When the user is ready to save a topic to the file, we must:
- Present a File Save dialog.
- Programmatically expand the topic's children (to make sure we can get the full list of topics).
- Build a list of URLs to download and merge.
- Start the first URL download.
void saveTopicToolStripMenuItem_Click(object sender, EventArgs e)
{
...
saveFileDialog1.FileName = node.Text;
if (saveFileDialog1.ShowDialog(this) != DialogResult.OK)
return;
treeViewToc.BeginUpdate();
node.ExpandAll();
node.Collapse();
treeViewToc.EndUpdate();
TopicsUrlList.Clear();
foreach (HtmlElement item in topicElement.GetElementsByTagName("a"))
{
TopicsUrlList.Enqueue(item.GetAttribute("href"));
}
if (TopicsUrlList.Count > 0)
{
...
StartNextTopicDownload();
...
}
...
}
StartNextTopicDownload() simply navigates to the next URL in the queue using another hidden webBrowserLoader web browser. Once the document is downloaded, we can extract the content that is interesting to us (which has the "mainSection" ID) and merge it into an internal StringBuilder object. I have chosen to keep all the download results in memory and flush to a file once all the downloads are completed, but it is easy to store it in a file as you are getting it from the web.
There are two optional features, which can be turned off on the toolbar: removing hyperlinks, and saving images locally. Hyperlinks removal helps improve your mobile reading experience (if you tap on a processed hyperlink, the reader won't follow it):
void RemoveHyperlinks(HtmlElement mainSection)
{
foreach (HtmlElement a in mainSection.GetElementsByTagName("a"))
{
a.SetAttribute("href", "");
a.OuterHtml = string.Format("<strong>{0}</strong>", a.OuterHtml);
}
}
The local images copy optional feature is used to preserve images within the generated HTML. The approach is very similar to what IE does - save images in a subfolder and change references to point to the files in the subfolder. There are two tricks, however, to keep the images count and size as small as possible:
- images from the same URL will use the same file
- images with different URLs, but with same content will use the same file
You can find the logic in the CopyImagesToLocalFolder() method inside the sources.
Points of interest
Missing exceptions
I found it annoying that exceptions are hidden if they happen inside the web browser control event handlers. Therefore, I'm using BeginInvoke() with anonymous delegates to run my code after the event handler is done.
Load on demand in .NET TreeView
The native Windows TreeView control has the facility to indicate that a tree node may have children. Such nodes have an expand button even if they have no children. This helps to do load-on-demand in trees.
Unfortunately, the .NET version does not have such a feature - all children must be created in order to show an expand button. I'm using a trick to overcome this limitation; when I know that a parent might have children, but I have no children yet, I add an empty child node. All valid nodes have a Tag property filled with the related HtmlElement, but these empty children have a null value in Tag. I'm intercepting the BeforeExpand() event, and if I detect that this parent needs to load children, I'm removing the empty node and loading the children.
Accessing class HTML attribute from HtmlElement
HtmlElement has a GetAttribute() method, but it won't work if you specify a class attribute. A bit unexpected, but after some MSDN reading, I found that className must be specified to read the class attribute. All other attributes can be read under their own names.
Efficiently reusing downloaded images
MSDN pages have many images on them. Sometimes these images look the same, but have different URLs to retrieve them. I'm using two dictionaries to efficiently reuse loaded images, both dictionaries map to the file names. If we fail to find a file name in the dictionaries, then we must create a new file and add its info to the dictionaries. The first dictionary uses a URL as a key, the second uses an MD5 hash of the downloaded image content. The hash is converted to a Base64 string to make the dictionary key.
var hash = Convert.ToBase64String(md5.ComputeHash(data));
History
- November 4 - Article created.
Sergey likes doing programming every day for the last 15 years started with Basic, ASM, Pascal, C++, X++ and ended with C# these days. User Interface design, usability, communications, parallel and asynchronous programming, game development and 3D graphics - all these areas makes him excited.
MCPD Windows, Web and Enterprise


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





 and have no internet connection...
and have no internet connection...