Abstract
We explore the approaches that current security frameworks take in software development. Some approaches are too basic to be useful in more complex applications. After identification of the requirements of a more advanced framework, a conceptual framework is developed with the distinct feature that a role is bound to a context within a hierarchy. It resembles the security frameworks found in traditional file systems. This design provides a fine-grained and flexible control of permissions. An implementation is developed in Microsoft SQL Server 2005 based on this conceptual framework. The implementation is extended with extra features for fast performance. A full specification of the implementation is available.
Please note that this online article is an extraction of the original article. The provided source code is complete, though. However, for more information please make sure you also read the full article provided in the download, or look here.
Introduction
Every application that grows beyond your own personal domain will at some point face the need to deal with security issues. With the arrival of the internet and the movement of moving applications online, this has only become more important. The security framework is one of the foundations of an application and must be considered in all stages of the software development process. An implementation should be embedded in any software project as early as possible. In this paper, we will explore security frameworks from a conceptual point of view first. This allows us to look at different approaches and the differences between them. In the second part of this paper, we will develop a powerful and generic security framework based on these insights and provide an implementation developed in Microsoft SQL Server 2005.
An Implementation of the Framework
Our implementation is based on Microsoft SQL Server 2005, but one should be able to transfer it to other DBMS suppliers. There is one feature however that might not be available in other database servers. These are Common Table Expressions (CTE), which can be used to execute recursive queries. An equally valid construct is available in Oracle databases. The lack of recursive queries might be a limitation, but in the next section we will optimize the framework by leaving out the CTEs in the core functionality and take a different and more vendor independent approach on traversing a tree structure.
Data Model
We start off by defining our tree structure...
Table 1 OrganisationUnit
Name Type Allows NULL
Id int (primary key, identity increment) No
ParentId int Yes
Name varchar (100) No
Table 2 Role
Name Type Allows NULL
PrincipalId int (primary key, identity increment) No
Code varchar (50) No
MinPathLevel int No
MaxPathLevel int No
OrganisationUnitId int No
...and the test data:
Test data OrganisationUnit
Id ParentId Name
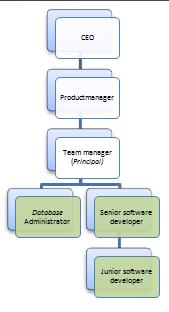
1 NULL CEO
2 1 Product manager
3 2 Team manager
4 3 Database administrator
5 3 Senior software developer
6 5 Junior software developer
Test data Role
PrincipalId Code MinPathLevel MaxPathLevel OrganisationUnitId
1 ModifyUserDetails 0 100 1
2 ViewProjectStatus 0 0 2
3 AssignTaskToUser 0 100 3
4 AskUserForPayRaise -1 -1 4
5 AssignTaskToUser 0 100 5
The meaning of the roles in the test data can be easier to understand in natural language:
- The CEO is allowed to modify user details for itself and all its descendants (that is, the whole company)
- The project manager has a traditional role to view the status of projects. This role is bound to the person itself and is not working down- or upwards. It would make no sense to do so.
- The team manager is allowed to assign tasks to itself and its descendants (the whole team).
- The database administrator is allowed to ask for a pay raise to its direct parent (the team manager).
- The senior software developer is allowed to assign tasks to itself and its descendants (the junior software developer).
The following step is to specify how an application can deduce from this data whether a given action is permitted for a given principal and a given context organization unit. First, we create a database view that will help us map the tree in such a way that we can use our regular relational SQL operations on it.
WITH OrganisationAncestor AS
(SELECT Id, Id AS ContextId, ParentId, 0 AS PathLevel
FROM dbo.OrganisationUnit
UNION ALL
SELECT a.Id, b.Id AS ContextId, b.ParentId, a.PathLevel - 1 AS PathLevel
FROM dbo.OrganisationUnit AS b
INNER JOIN OrganisationAncestor AS a ON a.ParentId = b.Id),
OrganisationDescendant AS
(SELECT Id, Id AS ContextId, 0 AS PathLevel
FROM dbo.OrganisationUnit AS c
UNION ALL
SELECT d.Id, e.Id AS ContextId, d.PathLevel + 1 AS PathLevel
FROM dbo.OrganisationUnit AS e INNER JOIN
OrganisationDescendant AS d ON d.ContextId = e.ParentId)
SELECT Id, ContextId, PathLevel FROM OrganisationAncestor AS Ancestor
UNION
SELECT Id, ContextId, PathLevel FROM OrganisationDescendant AS Descendant
This view uses two common table expressions. The first CTE is used to recursively traverse from a given organization unit to all its ancestors. The second CTE is used to recursively traverse from a given organization unit to all its descendants. The result is a list that can be interpreted as follows:
A combination of each organization unit, with all its ancestors, itself and its descendants. A relative path level is calculated with the origin (0) being the organization unit itself. Positive being downwards in the tree and negative being upwards in the tree.
The result of this view can become huge very fast in even modest tree sizes. However, you will never need the whole view and will filter out most of it, which makes the performance acceptable. This view will be a very utile tool in the authorization process. In effect, it generates the whole sub-tree for a given organization unit at runtime. With this view in place, it is time to link it with the actual authorization process. We assume there is an (authenticated) principal identifier, who wants to perform an action on the context organization unit for which a role code is needed. Written as a function:
CREATE PROCEDURE [dbo].[AllowedToPerformAction]
@principalId int,
@contextId int,
@roleCode varchar(50),
@allowed int output
AS
BEGIN
SELECT @allowed = COUNT(*) FROM
OrganisationView INNER JOIN
Role ON
OrganisationView.PrincipalId = Role.PrincipalId AND
OrganisationView.PathLevel >= Role.MinPathLevel AND
OrganisationView.PathLevel <= Role.MaXPathLevel
WHERE
OrganisationView.PrincipalId = @principalId AND
OrganisationView.ContextId = @contextId AND
Role.code = @roleCode
END
Another utility stored procedure, CoverageSetOfRole, returns all contextual organization units that are included in this role for the given principal:
CoverageSetOfRole @principalId=3, @roleCode = 'AssignTaskToUser'
The coverage set is very useful for user interfaces where one wants to show an overview of the entities it can perform the actions on. It is good practice to only show those entities for which the actions are allowed. For example, when the team manager wants to assign tasks to a user, a dropdown list can be populated with the results of the coverage set. When there are multiple roles with the same role code assigned to a principal, then the coverage sets of these roles are combined to form a single coverage set for a role code for a principal.
Also note that the role table is not fully normalized and, for most systems, it would make perfect sense to factor out some properties of the roles (role code, min path level, max path level) in a separate table and create an intermediate table that couples the organization units and roles. We have omitted this to make the model simpler and clearer.
This implementation fulfills the needs of our hierarchical role-based security framework. From this point on, it should be fairly easy to implement authorization in a system by calling the correct stored procedures before executing functions that need authorization. Although fully functional, the implementation can be improved in terms of performance and functionality. In the next section, we will explore these possibilities.
Improving the Framework
The implementation that we have built so far is fully functional and works fine for smaller hierarchies. We found, however, that it does not scale very well when the hierarchy gets larger (10.000 organization units going four levels deep). One reason for this is the use of recursive CTE to traverse the tree. In our release of SQL Server 2005 (including service pack 2), we found that with more complex queries the execution plan was sub-optimal and caused a lot of temporary intermediate lookup tables. Furthermore, we needed more information about the tree to implement load-on-demand in our user interface, which is a must-have if your tree gets larger. We have developed solutions to overcome these problems. These solutions are:
- Tree traversing in a more efficient way
- Automatic administration of depth of path and direct child count
These points are beyond the scope of this online article. Please see the full article included in the ZIP file or at this website for the solutions.
History
- 9 Oct 2007 - First code project release
I own a small dutch software developing firm: Xih Solutions (www.xihsolutions.net). We develop custom-made software solutions for small and medium-sized businesses.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





