Contents
Introduction
In this installment of the Relationship Oriented Programming series, I'm going to explore some possibilities for automatically generating a "user" UI
for entities in a relationship model. The purpose here is to dynamically generate a friendly UI, complete with navigation links to defined relationships. Changing the model
should of course be reflected in a change to the UI, essentially immediately and without recompiling code.
Being somewhat bored with the Romeo and Juliet model at this point, and having come across Dylan Morley's
lounge post about Open Source Agile tools, I thought, hmmm, why not make a real-life, hopefully somewhat usable, application for Agile project management?
As you read through this lengthy article, you will notice that I am designing and implementing as I go. I like this approach for article writing, as it gives you,
the reader, a better understanding of my thought processes and, in my opinion, is more "alive" than writing about a polished piece of code.
Agile Project Management
Having perused numerous websites on this concept, I can definitively state that I have no idea what exactly Agile Project Management (APM) actually is. It seems everyone has
different ideas for implementing an APM application, but nobody actually has a specification for what an APM Application (APMA) should provide to the end-user. Maybe this
is the nature of the APM, theoretically being itself written in an agile project development effort. It would seem to me that the best way to describe the specifications
for an APMA would be to actually use Agile practices, but nobody seems to have done that! So here goes.
It does seem that every APMA focuses around three things:
- User Stories (a.k.a. features)
- Tasks (a.k.a. real work)
- Iterations (a.k.a. the user story has changed, or a.k.a. "this is all you get now")
Beyond that, there are some additional concepts:
- Projects
- People who take on performing tasks
- Acceptance Tests (a.k.a. Unit Tests)
- Bugs (what, Agile development results in bugs?)
And then there's a set of loosey-goosey concepts:
- User feedback
- Work in Progress (a.k.a. Kanban)
- Sprint
And finally, reports:
- Velocity
- Iteration Burndown
- Release Burndown
- Scope Creep
- Burn-up
If further development is of any interest to me or other people, I could be talked into generating reports, but not right now.
The Ubiquitous Spreadsheet
Spreadsheets are the ultimate answer to everything. Not 42. Excel. And an APMA is no exception to this - basically, if you have a spreadsheet,
you are capable of APM. Frankly, if you have a pen and paper, you are capable of APM, but we'll keep that secret to ourselves.
If you watch Burn Notice, read the following in the "Michael Westen" voice:
The fact that an APM can be modeled in a spreadsheet is a good indicator that we can easily implement the same concepts with the developer's one-tool-fits-all,
the Data Grid. So, while using a data grid is easy, it's also boring and sometimes not the best solution when you have data that doesn't fit nicely into
a 150 pixel wide field, like a description. For that, we need to be smarter and implement discrete controls.
[End Michael Weston's voice.]
My APMA User Stories (APMAUS)
At this point, my cat's paw hit some function key in FrontPage and I lost about 30 minutes of text. So, starting again, here's my user stories for my APMA:
- I've got a lot of projects going at the same time (not necessarily all programming projects), and unlike Microsoft, where projects are solutions and items
in the solution are projects, I like to think in terms of projects. Most likely, a customer isn't going to come to you,
like Caiaphas in Jesus Christ Superstar with "We need a ... solution to our problem"
but rather "I have a project."
- A Project, at a minimum, has a Name and a Short Description.
- Projects consist of User Stories. This is the techy new age replacement for "Specifications" and "Requirements".
In some ways, user stories are actually better because they can capture how the user wants to interact with the application, whereas a technical specification
or application requirements usually captures details at a lower level, describing features rather than usage.
- I should be able to look at user stories related to a project.
- I should be able to look at user stories related to several projects, or all projects.
- Unfortunately, User Stories suffer from the opposite of a good requirements document. They are too loosey-goosey, being more about how to do things rather than what needs to be done.
- A User Story should be capable of being drilled into, refining the pie-in-the-sky fantasy to something actually more concrete. This requires a good level
of customer involvement and even worse, it might require the coordination and consensus of several people. The manager will have a completely different idea
of how the software should work from the secretary that actually will be using the application on a daily basis. And if you get an accountant involved, forget it!
- Drilling into User Stories, and more importantly, assigning ownership of a story to a user, is important.
- It answers the "why the heck did you implement it this way?" question.
- It answers the "why is this costing so much?" question.
- A User Story needs an Owner and a Description field, and has the ability to have sub-stories, perhaps from different owners. Start learning
your Non-Violent Communication techniques now.
- Bringing clarity to a User Story increases the chances of success that you will deliver to the customer what he needs. Funny, I've never read that anywhere
in all of the Agile websites I've visited.
- Once the User Story has been recursed (curse that user story!) from fantasy into actionable work, we can create tasks.
- A Task entity belongs to a User Story.
- Tasks don't have to be programming tasks. They might be "Get more information from the customer." for a vague User Story.
- A Task has a short name, a description, a reference to a User Story, and according to everyone, a task should have an estimation of completion in some
unit of measure. That's the vague part. Hours, days, weeks?
- Developers aren't good at defining tasks, any better than the customer is at initially defining user stories. So, tasks start off rather vague with wild estimates
and need to be broken down into smaller tasks. The smaller the task, the better the estimation for its completion (I've never read that either in all
of the Agile websites I've visited).
- One of bizarre things about estimation is that the vague task might have an estimation that is not the sum of the sub-task estimations. This is a very important
thing (also something I've never read on any of those Agile development websites!).
- The program shouldn't just add up the sub-task estimates to automatically calculate the super-task estimates.
- It should allow the top-level task's estimate to be independent.
- This is an incredibly useful way of discovering several things:
- If my high level task estimate is higher than the sub-task estimates, then it's an indicator that I haven't figured out all of the sub-tasks, because intuitively,
I know the super-task has more work involved than what I've defined as its sub-tasks.
- If my high level task estimate is lower than the sub-task estimate, then it's an indicator that I am discovering complexity that I didn't consider when first estimating
the super-task. Gee, we never experience that, do we?
- If my high level task estimate matches the sub-task estimates, then I've done something wrong. I'm serious. This is an indication that someone is fitting
the sub-task estimates into the super-task estimate. There's nothing wrong with being wrong, especially at the stage of task estimation. Allow yourself to be wrong,
because it is a useful metric for bringing further clarity to the task! (You've never read that either, have you?)
- Showing both estimations and calculated (rolled up) estimations is useful!
- I mentioned that User Stories are on the other side of the pendulum's swing (requirements being on the other end).
- We need to be able to identify requirements, rules, specifications, and so forth, that aren't part of a User Story. A User Story isn't likely
to say "implement in SQL Server". A User Story might say "we need to support 1000 concurrent users" but the technical details
of how that is going to be done simply isn't there.
- That's why we need the ability to associate things like requirements, rules, technical specifications, features, etc., to a User Story.
- And also a Task!
- Documents! Everything can have a document (or two) associated with it: projects, user stories, tasks.
- Even documents can have documents (revisions, further reading, etc.).
- Documents can come in many forms: Word, Excel, pictures, movies, URLs, books, a particular paragraph in a book, a piece of paper in a file cabinet (like a contract).
- You are probably noticing at this point that this sounds more like a hierarchy rather than a grid, and you are right. A tree control is the other
"one-tool-fits-all" tool in the developer's toolbox, but it's actually a corollary to the spreadsheet, as you can easily implement hierarchical
information in Excel. Not so easy with a grid, and we definitely don't want to talk about a DataSet since our relationships are not rigid in the way a DataSet wants.
- Up to this point, it might be useful to visualize the project, user stories, tasks, and requirements in a tree form, but a grid has its uses too, so we'll see.
- This brings up an interesting point about user stories: sometimes, we just don't know what the best implementation is until we can actually test drive the darn thing.
- For purposes of design, it might be useful to have the concept of an Approach. This is something else I've never read about in Agile development.
- An Approach is an implementation concept to something that you don't know is a good way of doing something until you try it. Maybe several different
approaches (visualizations, algorithms, etc.) are actually what's needed. Maybe we just want a placeholder to evaluate the tasks and requirements to different
approaches. Maybe we want to do some prototyping and show them to the customer. Sell the harder one, more money that way. Right?
- An Approach is something that can be attached to a User Story.
- An Approach can have tasks!
- Iterations. What are these? Well, one concept is, it's a window of time between now and the next "release" (another loosey-goosey term in APM). You and the customer
can decide on the iteration schedule and then figure out what can fit in that schedule.
- An iteration contains tasks.
- An iteration has a duration.
- It should probably also have a Name.
- An iteration should have a flag to indicate that it is an internal iteration, or maybe it's something we want to show the customer, and maybe
it comprises an official release, patch, revision, whatever, to the user/website, etc.
- Tasks are assigned to iterations.
- If we have tasks from different approaches, we need to be careful in picking the task. Have we decided on a particular approach, and therefore tasks
from the other approaches should be "deprecated?" Are we allowing people to work on tasks from different approaches? This needs to be considered when
assigning tasks in an iteration.
- One of the variations of Agile development is Lean Development, in which you'll sometimes see the word Kanban bandied about, which is nothing more than three columns:
- a backlog of work
- work in progress
- work completed
- The three columns of a Kanban fall under the purview of a report, as we should at any point be able to query for unassigned tasks, assigned tasks but not complete, and completed tasks.
- Besides tasks, another useful Kanban chart is a backlog of user stories, user stories in progress, and completed user stories.
- Did I mention I'm not going to generate any reports in this iteration of the article series?
- This itself is a concept not well handled in an APM: future versions.
- A User Story should be able to map out the application's "arc". We all have great ideas for what an application should do,
but we want to be able to tease apart all our gloriosky ideas into categories like "must have immediately" and "a nice feature
to put into version 10". People should not be picking tasks from version 10 when the team is working on version 1!
- So, a User Story should have a Version associated with it. My deferred report stories probably might be in Version 20.
- Who does the work? Well, people do, and sometimes tools do.
- People are easy. We have a Person entity, with a name and some contact information.
- Tools though are another concept Agile ignores, and APMs ignore as well.
- A tool is used in a Process, which probably ought to be documented. It can include things like "running the obfuscator", "use NetZ to package
all the assemblies", "create a branch in SVN". It's important to identify the automated processes that achieve a Task. It's important to look
at tasks and think about whether the Task can be automated!
- A Process can be assigned to Tasks.
- Tools are described - they have a name and probably other information. When you revisit the application 5 years from now to make a change,
wouldn't it be nice to have a list of tools needed to rebuild the application? Wouldn't it be nice to know what the automated processes are, and how to use them?
- A process doesn't just mean something automated. It can also mean "get signoffs from the department heads".
- So, tools and processes are an important part of how you do your work and how you succeed in providing something to the customer. Documenting
those tools and processes for tasks is useful!
- People take on tasks. We want to know what tasks each person is doing, and what they've finished doing.
- At some point, we might want to look at a person's work load. Do they have some free time? Do we need to change priorities? Is this person killing themselves with work?
- Tasks need to be able to be prioritized! That's the real world - something comes up that requires immediate attention.
- Testing. Test Driven Development. Acceptance Tests. Unit Tests. Buzzwords for stuff nobody likes to do, and doing these things take as much
time as writing reports or writing the application itself. Really. If anyone tells you differently, they are lying. Testing is important to you, the developer,
because it's a way of measuring the achievement of a milestone which is often tied to payment. Testing is important to the customer because it's a way of determining
that good quality work is being done and whether or not to make that milestone payment. But nobody wants to do it. None-the-less:
- Tasks should have some kind of test, usually the Unit Test, but possibly also a simple Acceptance Test.
- User stories should have an Acceptance Test, to be performed by the user, and the user's AT should be different than the developer's AT, because they are usually testing different things.
- A test might be automated. Ah ha. It might require a Tool. It might have a Process (like initialize the database with test data).
- Tools and Processes can be associated with tests!
- A test needs a name, a description, and the association of a Test Run with a Task or User Story should have a pass/fail criteria.
- Bugs. Bugs are anything that doesn't work the way we want it to work.
- A failed Test is a Bug.
- But bugs are found outside of formal tests. So, bugs are associated with a Task, a User Story, or even the Project. A Bug doesn't necessarily fit into
a User Story. If the bug is "the application hangs when two people use it concurrently" there might not be a user story for "must handle user load
of two people". We want to document the bug, associate it to the project, and later identify what the missing user story is, and then we can associate the bug with the user story.
- Bugs have tasks. After all, we need to fix the bug, right? Wrong! (Another thing you don't read about in Agile Development!) A bug might
have a workaround (ah, a useful piece of information) or might be delegated to some future release (an association!). One person's bug might be another person's
requirement, and so the task might be "user training". Think about it: even when you put in an error message because a web service has failed, the user
will still say "your application isn't working", and what they need is training in understanding who is responsible (ownership) for the failure,
no matter how many helpful messages you display. My favorite message to date is in Oracle 9, that claims that a deadlock condition "is not
a bug in Oracle but in your application". Something like that, I kid you not (which is subsequently fixed in Oracle 10!).
- The user will view any problem as a bug, the developer will not. It might be useful to keep two sets of "books", if you will.
Enough already!
I could go on, but I imagine you've already skipped most of the above, even with my efforts at humor and sarcasm to keep you, the gentle reader, entertained. But, as you can
see from the above description of my Gloriosky APMA (GAPMA), user stories are not neat little packages. One user story affects other user stories. User stories should be
able to reference other user stories (which is in itself a user story - and you thought I was done!).
Now, you're probably thinking, holy cow, this is going to take weeks to implement. Ridiculous! This will take a couple hours, using my nifty one-tool-fits-all can opener,
the Relationship Oriented Programming Tool (ROPT). Ah, but look, nowhere in my user stories do I say anything about using this tool as a requirement
for building the GAPMA. You can see immediately why I created the idea of a Requirement that can be attached to anything. Using the ROPT is a requirement
to implementing the GAPMA. Say that 10 times real fast. Meditate on it. Believe it. I want you to be brainwashed into thinking that this
is The One Way, The True Way, The Only Way!
The Model
One of the points of ROP is that you can start simple and create the entities, attributes, and relationships as needed, without having to architect the whole thing
up front. Now that's Agile! So, let's get started with a basic model and some simple relationships. The first group of entities I want to model are:
And the relationships are:
- A Project has User Stories
- A Project has Tasks
- A User Story has Tasks
- User Stories can have User Stories
- Tasks can have Tasks
Basically, because of the drill down nature of many of the entities, the recursable entities all reference a Project. Using the ROPT:
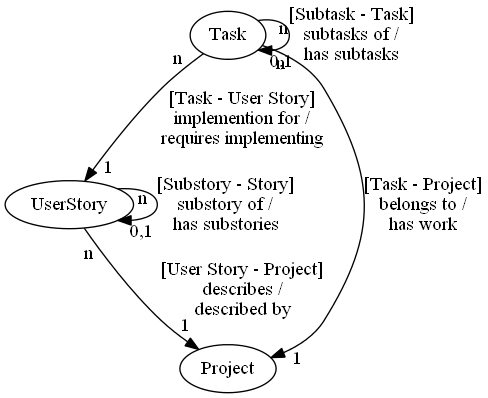
Or, in Schema form:

And we get a basic "super-user" UI to start with (this one shows the Task entity):
However, this isn't what we want to provide to the user of the GAPMA.
- We don't want to show ID fields.
- Lookups to other entities should have nice headers, not "...ID".
- The description field is allocated more than 4000 characters! Do we really want to use a 150 pixel wide field for this? I think not!
- The "parents" (User Story, Task and Project, for the Task entity) should be displayed in some other manner.
But This Isn't the Model That We Want!
Furthermore, what I've created above is a physical model (tables, fields, relationships between tables). The above model is definitely useful
and we should continue to maintain it as a document of the physical model (actually, the ROPT should be able to generate this physical model at any time,
I just haven't gotten around to implementing the visualization), but what we really want is a meta-model, using the ROP physical model that I created
in the previous article. The meta-model describes the GAPMA physical model, but at a meta-level, which gives us:
- the ability to add fields and create new relationships without having to fix up the physical model
- the ability to make the relationships between the entities first class citizens. This is the whole point.
- By using the meta-model, we can with ease track relationship changes, navigate between entities, create new relationships, inspect what entities
are in relationship with other entities, and so forth. These are all valuable things to do in "mining" the growing complexity of relationships
between user stories, tasks, bugs, tests, documents, and so forth as they are added to a complex Agile project!
- This is what meta-modeling achieves: abstracting entities and their relationships so that you aren't writing ad-hoc custom visualizers and reports for every table with a foreign key.
- Since an attribute type like "Name" is used by all sorts of entities, you can do crazy things like "what are the Names of everything, regardless
of what the associated entity?" Sounds silly, but it might be useful in data mining for "all things with the Name 'foo'".
This is What We Want
This is all created in the ROPT using the rop.model file, which is our meta-modeling schema (which sounds better than "our meta-modeling model).
First, we have a short set of attribute types (notice there are no ID attributes. We don't need this anymore at the meta-model level - foreign keys have
been abstracted out using the relationship instance.
Our three entity types:
A description of our entity attributes:
And a description of our relationships types:
We could now populate the meta-model with instance information using the super-user UI built into the ROP - here's an example of the screen for defining a physical
value to an entity attribute instance:
but this is even further removed from what we want the end-user to see! So, we need to create a user interface (similar to the one above) not from the physical model,
but from the meta-model. Aye, there's the rub.
By the way, here's an interesting point: note how the meta-model describes both the schema (the ...Type elements) and the instances (the ...Instance elements)
in the same DataSet. This is an important point, that the schema (describing type and relationships) and the data are in the same "package". Why this is important
is a bit hard to describe, but it sounds good!
Dynamic User Interfaces From The Meta-Model
So, we finally get to the point of this article, which is the dynamic generation of a user-friendly UI from the meta-model. It would be fairly straightforward
to create a UI for the physical model (after all, that's what the first screenshot showed), so this is a clue as to how to go about creating the UI for managing
an entity instance from the meta-model. Let's start first with the Project entity. With all entities, we want to collect two things:
- The attribute types of the entity (for viewing and editing data)
- The relationship types of the entity (for navigating relationships)
We also want some control over the behavior of the "data management" portion of the UI - the part where the user can view and manage (edit, delete, create)
the data. There are three things that I can think of as basic options:
- Grid only
- Grid along with discrete controls
- Discrete controls only
It'll be important to describe the order of attributes, so I've added "Ordinality" to the EntityTypeAttributes definition in the ROP model,
which will help us order fields in the form:
Also, we need some more information regarding the AttributeType itself, so I added DataType and Length attributes to the AttributeType entity:
Also, I added the following menu item:
which brings up a basic form for selecting an entity type and some initial simple choices for how we want to render the UI:
A Project UI
Let's start with creating something simple, the UI for the Project entity. I'm also going to start with a basic grid, as there are several pieces that need to get implemented:
- Creating the UI itself
- Creating the underlying
DataTable. This requires rotating the entity-attributes, which are rows, into columns - Populating the underlying DataTable with data. Similarly, this requires rotating the entity instance data, represented as discrete attribute-value pairs,
into columns, where all the attributes of an entity instance represent one row in the underlying table.
- Doing the reverse for managing the ROP representation of an entity instance. For this, I'm going to use my Data Table Transaction Logger that I wrote about a few years back.
- Creating the usual suspects: a
DataView and a BindingSource (which will also be used for working with discrete controls)
Lastly, the question is, how to generate the UI? Should I do this by creating the controls at runtime on a blank form? Should I generate code instead,
similar to the way Visual Studio's form designer works? Should I create an XML object graph of the UI? Why yes, me being me, that seems the most useful
approach! I can create the XML, generate the UI with MyXaml, and it's a document that is easily persisted as well as extended. Ideally, the resulting XML
object graph should contain all the pieces necessary to work with the UI, independent of the ROP tool. These sound like user stories, don't they?
However, there are complexities that are probably best discovered by actually putting together a very simple proof of concept first, getting some of the core underlying code right,
figuring out what rules we might want to expose that will control the behavior of the UI generation (at some point maybe even the ability to use templates
for certain look & feel aspects) and identifying the dependencies that need to be resolved if we are going to create a truly stand-alone UI capability. Sounds like iterations
and lots of refactoring once I get a better idea of what I'm doing.
Creating the Basic Form
To start with, we need a Form, created like this:
XDocument xdoc = new XDocument();
XNamespace nsswf = "System.Windows.Forms, System.Windows.Forms, " +
"Version=2.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089";
XElement controls;
xdoc.Add(
root = new XElement(nsswf + "MyXaml",
new XAttribute(XNamespace.Xmlns+"def", "Definition"),
new XAttribute(XNamespace.Xmlns + "ref", "Reference"),
new XElement(nsswf + "Form",
new XAttribute("Text", "Project"),
new XAttribute("Size", "800, 600"),
controls = new XElement(nsswf + "Controls"))));
string xml = xdoc.ToString();
Clipboard.SetText(xml);
Parser p = new Parser();
Form form = (Form)p.InstantiateFromString(xml, "*");
form.Show();
which gives us a blank form:
And the XML looks like this (don't worry, I'm not going to show you the XML every single time):
<MyXaml xmlns:def="Definition"
xmlns:ref="Reference"
xmlns="System.Windows.Forms, System.Windows.Forms, Version=2.0.0.0,
Culture=neutral, PublicKeyToken=b77a5c561934e089">
<Form Text="Project" Size="800, 600">
<Controls />
</Form>
</MyXaml>
Creating a Basic DataGridView Control
This does nothing more than create grid control:
protected void RopGrid(XNamespace ns, XElement controls,
List<AttributeInfo> attributes, ref int x, ref int y)
{
XNamespace nsdef="Definition";
controls.Add(new XElement(ns + "DataGridView",
new XAttribute(nsdef + "Name", "grid1"),
new XAttribute("Location", x + "," + y),
new XAttribute("Size", "600, 400"),
new XAttribute("Anchor", "Top, Bottom, Left, Right")));
y += 150;
}
Which gives us a basic anchored grid control:
Creating the Underlying DataTable Columns
The columns for the underlying DataTable are determined from the attribute types assigned to the entity type:
protected List<AttributeInfo> GetEntityTypeAttributes(int entityTypeID)
{
List<AttributeInfo> attributes =
(from eta in dataSet.Tables["EntityTypeAttributes"].AsEnumerable()
where eta.Field<int>("EntityTypeID") == entityTypeID
join at in dataSet.Tables["AttributeType"].AsEnumerable()
on eta.Field<int>("AttributeTypeID") equals at.Field<int>("ID")
orderby eta.Field<int>("Ordinality")
select new AttributeInfo
{
ID=at.Field<int>("ID"),
Name = at.Field<string>("Name"),
DataType = at.Field<string>("DataType"),
Length = at.Field<int>("Length"),
}).ToList();
return attributes;
}
And, with some really brute force code:
DataTable dt = new DataTable("mydt");
int cnum=0;
foreach (AttributeInfo ai in attributes)
{
DataColumn dc = new DataColumn("col" + cnum++);
dc.Caption = ai.Name;
dc.MaxLength = ai.Length;
dt.Columns.Add(dc);
}
dt.Columns.Add(new DataColumn("ID", typeof(int)));
DataView dv = new DataView(dt);
BindingSource bs = new BindingSource();
bs.DataSource = dv;
dgv.DataSource = bs;
for (int i = 0; i < dt.Columns.Count; i++)
{
dgv.Columns[i].HeaderText = dt.Columns[i].Caption;
}
dgv.Columns[dt.Columns.Count - 1].Visible = false;
we get this:
Progress!
Logging Transactions
As mentioned above, I'm going to log transactions with the DataTableTransactionLogger (DTTL) and then persist the changes, en masse, to the ROP model,
which requires converting the concrete DataTable implementation back to the meta-model, manipulating the EntityInstance and EntityAttributeInstance tables.
protected DataTableTransactionLog CreateTransactionLogger(DataTable dt)
{
DataTableTransactionLog dttl = new DataTableTransactionLog(dt);
return dttl;
}
Since transactions won't be persisted immediately, we need to implement a "Save" button.
protected void RopSaveButton(XNamespace ns, XElement controls)
{
controls.Add(new XElement(ns + "Button",
new XAttribute("Location", "220, 10"),
new XAttribute("Size", "70, 25"),
new XAttribute("Text", "&Save"),
new XAttribute("Anchor", "Top, Right"),
new XAttribute("Click", "{App.OnSave}")));
}
In some future version (excuse me, iteration) we can add undo/redo features which the DTTL supports, and which is one of the reasons I'm not using
.NET's native tracking of changed records (other reasons include being able to send the changes from my logger to a middle-tier rather than being stuck
in the 2-tier paradigm. Please don't mention the Entity Framework - if I hear the acronym ORM one more time I'm going to...)
The following code (remember, this is proof of concept) saves the transactions in the meta-model. This involves converting the horizontal physical
structure (rows and fields) to a vertical structure (entity instances and entity instance attribute values):
protected void OnSave(object sender, EventArgs eventArgs)
{
List<DataTableTransactionRecord> log = gridInfo.Logger.Log;
DataTable dtEntityInstance = dataSet.Tables["EntityInstance"];
DataTable dtEntityAttributeInstance =
dataSet.Tables["EntityAttributeInstance"];
int entityID = -1;
foreach (DataTableTransactionRecord dttr in log)
{
switch (dttr.TransactionType)
{
case DataTableTransactionRecord.RecordType.NewRow:
{
DataRow newEntityRow = dtEntityInstance.NewRow();
newEntityRow["EntityTypeID"] = entityTypeID;
dtEntityInstance.Rows.Add(newEntityRow);
entityID = newEntityRow.Field<int>("ID");
gridInfo.Logger.SuspendLogging();
dttr.Row["ID"] = entityID;
gridInfo.Logger.ResumeLogging();
break;
}
case DataTableTransactionRecord.RecordType.ChangeField:
{
string fieldName = gridInfo.DataTable.Columns[dttr.ColumnName].Caption;
int attributeTypeID = dataSet.Tables["AttributeType"].Select(
"Name='" + fieldName + "'")[0].Field<int>("ID");
DataRow[] rows = dtEntityAttributeInstance.Select(
"EntityID=" + entityID + " and AttributeTypeID=" + attributeTypeID);
bool recordExists = (rows.Length > 0);
if (recordExists)
{
rows[0]["Value"] = dttr.NewValue;
}
else
{
DataRow newAttrInst = dtEntityAttributeInstance.NewRow();
newAttrInst["AttributeTypeID"] = attributeTypeID;
newAttrInst["EntityID"] = entityID;
newAttrInst["Value"] = dttr.NewValue;
dtEntityAttributeInstance.Rows.Add(newAttrInst);
}
break;
}
case DataTableTransactionRecord.RecordType.DeleteRow:
{
foreach(DataRow row in dtEntityInstance.Select("ID = " +
dttr.ColumnValues["ID"]))
{
row.Delete();
}
break;
}
}
}
gridInfo.Logger.ClearLog();
dtEntityInstance.AcceptChanges();
dtEntityAttributeInstance.AcceptChanges();
}
Now, when we create some entries in our user-friendly UI:
We can see those entries in the super-user meta-model data set:
and further more, we can drill into each of the "Project" entity instances to see the instance attribute values by selecting a row and navigating to the detail records:
revealing (for the first entity instance with ID 0):
Thus we can inspect and verify our user-friendly concrete backing table, transaction logging, and meta-model updates. At any time. Because this dialog is modeless,
you can see the changes to an instance entity happening in real time.
Loading the Concrete DataTable
Loading the concrete backing DataTable with the entity instances of the selected type is straight forward. It's the reverse of the save process, here taking the vertical
entity instance and entity instance attribute values and converted them to a horizontal row-field physical table. Notice populating the hidden ID column value,
so we can support updating and deleting existing records. Later on I discover the need to also preserve the EntityID value!
protected void LoadTable()
{
DataTable dtEntityInstance = dataSet.Tables["EntityInstance"];
DataTable dtEntityAttributeInstance = dataSet.Tables["EntityAttributeInstance"];
DataTable dtAttributeType = dataSet.Tables["AttributeType"];
DataRow[] entityInstances =
dtEntityInstance.Select("EntityTypeID=" + entityTypeID);
foreach (DataRow entityInstance in entityInstances)
{
DataRow row = gridInfo.DataTable.NewRow();
int entityID = entityInstance.Field<int>("ID");
row["ID"] = entityID;
DataRow[] attributeValues =
dtEntityAttributeInstance.Select("EntityID=" + entityID);
foreach (DataRow attrVal in attributeValues)
{
int attributeTypeID = attrVal.Field<int>("AttributeTypeID");
string name = dtAttributeType.Select("ID=" +
attributeTypeID)[0].Field<string>("Name");
row[nameColumnMap[name]] = attrVal["Value"];
}
gridInfo.DataTable.Rows.Add(row);
}
}
The Project UI as a Hybrid Screen
Dynamically creating discrete controls is an art, not a science. I'm not talking about the technology, rather the rules for creating
an intelligent layout. This is not something I want to explore here (and in fact, ideally, I think the user should be given the ability to adjust the layout
to their own hearts content) so what you are going to see is some proof of concept implementation (which is the gentle way of saying brute force and ugly as sin). To begin with:
case Mode.Hybrid:
{
RopGrid(nsswf, controls, attributes, ref x, ref y, "Top, Left, Right");
CreateDiscreteControls(nsswf, controls, attributes, ref x, ref y);
break;
}
with a very simple implementation:
protected void CreateDiscreteControls(XNamespace nsswf, XElement controls,
List<AttributeInfo> attributes, ref int x, ref int y)
{
int n = 0;
foreach (AttributeInfo attrInfo in attributes)
{
RopLabel(nsswf, controls, attrInfo, ref x, ref y);
RopTextBox(nsswf, controls, attrInfo, ref x, ref y, "ctrl" + n++);
x = 10;
y += 5;
}
}
Yes, everything is a TextBox for the moment. Like I said, proof of concept.
And of course, the controls need to be bound to the binding source:
protected void BindControls(Parser p, BindingSource bs, List<AttributeInfo> attributes)
{
int n = 0;
foreach (AttributeInfo attrInfo in attributes)
{
string ctrlName = "ctrl" + n;
string colName="col"+n;
n++;
Control ctrl = (Control)p.GetReference(ctrlName);
ctrl.DataBindings.Add("Text", bs, colName);
}
}
Note the hardcoded control names and column names. On the todo list is to clean this up. Once I get the GAPMA minimally functional,
I am going to add these todo items as tasks! Anyways, the initial result is:
Wohoo. Don't be overly impressed.
One of the problems though is, adding a new record. If I click on a new row in the grid and then click on one of the discrete text boxes, the grid goes
out of its "new row" state and the reverts back to the previous existing row. Not what we want. This necessitates a "New" button that simply
creates a blank row (which brings up questions like "what if a value is required?", ah, tasks in future iterations!)
protected void OnNew(object sender, EventArgs eventArgs)
{
DataRow row = gridInfo.DataTable.NewRow();
gridInfo.DataTable.Rows.Add(row);
int id = row.Field<int>("ID");
int pos = -1;
foreach (DataRowView drv in gridInfo.DataView)
{
++pos;
if (drv.Row.Field<int>("ID") == id)
{
break;
}
}
gridInfo.BindingSource.Position = pos;
}
Resulting in the correct behavior (note the sorted Name column):
The Project UI as Discrete Controls
In this case, we want the Save and New buttons as well as a BindingNavigator to assist in navigating the records in a non-grid display:
case Mode.Discrete:
{
bindingNavigatorOffset = 25;
RopBindingNavigator(nsswf, controls, ref x, ref y);
CreateDiscreteControls(nsswf, controls, attributes, ref x, ref y);
break;
}
and initialize the BindingNavigator:
if (renderMode == Mode.Discrete)
{
BindingNavigator nav = (BindingNavigator)p.GetReference("nav1");
nav.AddStandardItems();
nav.BindingSource = bs;
}
giving us a useable initial pass at the discrete control version:
Simple enough. At one point though, I got an exception after adding a record, which I haven't been able to recreate.
By the way, one interesting thing you can do is open the "Model -> View Data" form and the "Model -> Render Entity Type UI" form
at the same time. As you save changes in the entity UI, you can see the meta-model data (for example, if you have "EntityInstanceAttributes" selected)
updating simultaneously. This was useful for me to discover that multiple deletes was not working. This led to the annoying discovery that the record just
added is not taken out of "edit" mode until the user navigates off the record, necessitating a call the EndEdit in the save routine:
protected void OnSave(object sender, EventArgs eventArgs)
{
gridInfo.BindingSource.EndEdit();
And We Now Can Create All Our Entity Type UIs
The above code isn't specific to just Project entity types - it works for any of our entity types (to the degree that I've implemented supporting controls up to this point,
of course!). One minor modification of the code is necessary to display the appropriate entity type in the form caption:
string entityTypeName = dataSet.Tables["EntityType"].Select("ID=" + entityTypeID)[0].Field<string>("Name");
...
new XAttribute("Text", entityTypeName),
and we now can start using the GAPMA to enter data for our agile projects!
Working With Relationships
Something I noticed with my meta-model is that the RelationshipType could really benefit by referencing the entity A and B types. In my previous article,
the RelationshipType instance was defined as:
and we defined the relationship types simply by naming them:
This is insufficient information to provide navigational support for the UI. To fix this problem:
I created two new attributes: EntityATypeID and EntityBTypeID:
I then added these attributes to the RelationshipType entity definition:
And finally, defined the relationship of these two fields to the EntityType entity:
Which now allows me to define the entity types in the relationship types:
Simple, eh? That makes for a good demonstration of modifying the model, creating new relationships, and updating the model data immediately
to reflect the new attributes and relationships. We have to thank the DataSet deserializer for not throwing exceptions when the XML defining the schema doesn't
match the schema the XML is being loaded into. The process above relies on the fact that deserializing an existing XML dataset will work when new fields are present
in the dataset schema but not in the XML. The reverse (dataset schema missing fields defined in the XML schema) is of course not supported, but that's good, as far as I'm concerned.
So far, I have the following entity type relationships:
Associating Entity Instances
So, now that we've got that out of the way, we need to give the user the ability to associate an entity with an "allowed" parent - similar to a foreign key
referencing a primary key record in another (or the same) table. With ROP, anything can be associated to anything else, however we are restricting the list
of associations to those defined by the relationship types, which was the point of the exercise above.
At this point, I've also added "Bug" and "Resolution" entity types and entered some data into the system which is currently unassociated:
I'm actually starting to use the GAPMA!
There are three basic ways we can make an association:
- Provide a field in the grid or as a discrete control from which to pick the parent record
- With the a parent record, display zero or all child records and, when the user adds a new child record, automatically associate it to the parent
- Provide a separate list of allowed parent and child entities and allow the user to create either a child-to-parent association or a parent-to-child association.
Technically, all three version should be supported, but for the moment, and to keep life simple, I'm going to implement only the third version for the following reasons:
The first option starts to get ugly when there's a lot of possible associations. Furthermore, it doesn't capture the possibility that something
can have multiple associations to different instances of the same parent type. Often enough, working on my product suite, I have a task that needs
to be performed on several components of the product suite. With the first option, how do I designate that the task is associated to multiple projects or user stories?
The second option is viable but constrains the user into a "top-down" way of thinking. There are obviously some good points to this,
such as data entry--for example, the line items on a invoice. On the other hand, this can be an artificial constraint that reduces the user's flexibility in using the application.
The third option removes these constraints, allowing the user to work in both a top-down and bottom-up manner. I like this approach better for
the purposes of what I'm trying to demonstrate, however, in actual practice, it is a little difficult to get used to.
Rules
A few rules in displaying parent/child records:
- A basic rule of this approach is that an entity cannot be in relationship to itself, therefore, we always exclude the selected entity instance from the list of parent/child instances.
- A second rule is, an entity instance can only be in relationship with the another entity instance once. Therefore, entity instances already in relationship
to the selected entity are excluded.
- An entity instance cannot be the parent and the child of an entity instance of the same type. For example, a sub-task (being the child of a task) cannot also
be the parent of the parent task, which would make the parent task a sub-task of its own child.
- Similarly, an entity instance cannot be the parent and the child of an entity instance of a different type. For example, a task cannot be the child of a user
story and be the parent of that same user story.
- Certain relationships are actually required. For example, because of the hierarchical nature of user stories and tasks, these entities should always
be associated with a project. This doesn't mean that the user is forced to make the association immediately - rather, a "check" should be performed
to inform the user of violations in the relationship requirements.
At the point of this writing, I'm not going to implement these rules in this iteration!
Selecting Parent/Child Entities and Entity Records
We need a couple combo boxes to select the allowed parent and child entity types. The concept is that, in the RelationshipType entity, EntityA is always
the child an EntityB is always the parent. "A" and "B" are such bad names! Better add a task:
First, let's get the lists with which we need to populate the comboboxes:
protected List<Association> GetParentEntityTypes(int entityTypeID)
{
List<Association> ret =
(from rt in dataSet.Tables["RelationshipType"].AsEnumerable()
where rt.Field<int>("EntityATypeID") == entityTypeID
join et in dataSet.Tables["EntityType"].AsEnumerable()
on rt.Field<int>("EntityBTypeID") equals et.Field<int>("ID")
orderby rt.Field<string>("Name")
select new Association
{
EntityTypeID = rt.Field<int>("EntityBTypeID"),
EntityTypeName = et.Field<string>("Name"),
}).ToList();
return ret;
}
protected List<Association> GetChildEntityTypes(int entityTypeID)
{
List<Association> ret =
(from rt in dataSet.Tables["RelationshipType"].AsEnumerable()
where rt.Field<int>("EntityBTypeID") == entityTypeID
join et in dataSet.Tables["EntityType"].AsEnumerable()
on rt.Field<int>("EntityATypeID") equals et.Field<int>("ID")
orderby rt.Field<string>("Name")
select new Association
{
EntityTypeID = rt.Field<int>("EntityATypeID"),
EntityTypeName = et.Field<string>("Name"),
}).ToList();
return ret;
}
Second, create the comboboxes (yes, I know, hideous hard coded values, remember, proof of concept!!!):
List<Association> parentEntityTypes = GetParentEntityTypes(entityTypeID);
List<Association> childEntityTypes = GetChildEntityTypes(entityTypeID);
p.AddReference("parentEntityTypes", parentEntityTypes);
p.AddReference("childEntityTypes", childEntityTypes);
RenderParentEntityTypePickList(nsswf, controls, 10, y+25);
RenderChildEntityTypePickList(nsswf, controls, 400, y+25);
protected void RenderParentEntityTypePickList(XNamespace nsswf, XElement controls, int x, int y)
{
RopCombobox(nsswf, controls, "Child Of:", "parentEntityTypes",
"EntityTypeID", "EntityTypeName", x, y);
}
protected void RenderChildEntityTypePickList(XNamespace nsswf, XElement controls, int x, int y)
{
RopCombobox(nsswf, controls, "Parent Of:", "childEntityTypes",
"EntityTypeID", "EntityTypeName", x, y);
}
And the code to render the combobox in XML:
protected void RopCombobox(XNamespace nsswf, XElement controls, string label,
string listName, string valueField, string displayField, int x, int y)
{
RopLabel(nsswf, controls, label, x, y);
controls.Add(new XElement(nsswf + "ComboBox",
new XAttribute("Location", (x + 60) + ", " + y),
new XAttribute("Width", "150"),
new XAttribute("ValueMember", valueField),
new XAttribute("DisplayMember", displayField),
new XAttribute("DataSource", "{" + listName + "}")));
}
Yields something usable, as demonstrated by rendering the User Story entity type, which has, as allowable parents, a Project and another User Story,
and can be the parent of Task or another User Story.
Displaying Parent/Child Records
On the next iteration's todo list is filtering parent and child records by some global criteria, such as the project. Also, this is where the
rules described above apply, but I'm not implementing either at the moment!
Given three methods (two for the events for buttons I didn't show above) and one for populating the grid, we can now display parent and child records for a selected entity type:
protected void OnShowParentData(object sender, EventArgs eventArgs)
{
int entityTypeID = (int)cbParentEntities.SelectedValue;
ShowEntityInstances(entityTypeID);
}
protected void OnShowChildData(object sender, EventArgs eventArgs)
{
int entityTypeID = (int)cbChildEntities.SelectedValue;
ShowEntityInstances(entityTypeID);
}
protected void ShowEntityInstances(int entityTypeID)
{
List<AttributeInfo> attributes = GetEntityTypeAttributes(entityTypeID);
BindingSource bs;
DataView dv;
DataTable dt = CreateUnderlyingDataTable(attributes, out bs, out dv);
grid2.DataSource = bs;
Fixup(grid2, dt);
LoadTable(dt, entityTypeID);
grid2.AllowUserToAddRows = false;
grid2.AllowUserToDeleteRows = false;
grid2.ReadOnly = true;
}
Resulting in:
A label describing what the grid is showing would be nice. As it stands right now, I have to explain that the bottom grid is showing the possible parent projects of the User Story.
Making the Association!
Here we are about to achieve a major milestone - creating the relationship between the selected records in the top grid and the selected records
in the "associate with" grid. Note that I use the plural - there's no reason we can't do multiple associations at the same time.
The code is straightforward - here's the work done to perform the child-to-parent association:
foreach (DataGridViewRow child in gridInfo.Grid.SelectedRows)
{
foreach (DataGridViewRow parent in grid2.SelectedRows)
{
int childID = (int)((DataRowView)child.DataBoundItem)["EntityID"];
int parentID = (int)((DataRowView)parent.DataBoundItem)["EntityID"];
int relationshipTypeID = GetRelationshipTypeID(childID, parentID);
DataRow row = dtRelationshipInstance.NewRow();
row["EntityAID"] = childID;
row["EntityBID"] = parentID;
row["RelationshipTypeID"] = relationshipTypeID;
dtRelationshipInstance.Rows.Add(row);
}
}
We need the relationship type ID as well, which uses this fancy query:
protected int GetRelationshipTypeID(int entityAID, int entityBID)
{
var id = from row in dataSet.Tables["RelationshipType"].AsEnumerable()
join entityA in dataSet.Tables["EntityInstance"].AsEnumerable()
on row.Field<int>("EntityATypeID") equals entityA.Field<int>("EntityTypeID")
where entityA.Field<int>("ID") == entityAID
join entityB in dataSet.Tables["EntityInstance"].AsEnumerable()
on row.Field<int>("EntityBTypeID") equals entityB.Field<int>("EntityTypeID")
where entityB.Field<int>("ID") == entityBID
select row.Field<int>("ID");
return (int)id.First();
}
The result--for example of associating the "Rules for displaying parent/child data" to the GAPA project--is (in super-user mode):
I want to associate the actual rule stories to the higher level rule story I just created, as well as the unrelated tasks to the project for now,
as there are no user stories for these tasks and the bugs I've noted so far and how to resolve them. The result, if I inspect the entities involved
with the "rules for display..." entity, looks like this (using the ROPT to visualize the relationship instances):
and the whole gloriosky relationship graph at the moment looks like this (horizontally compressed):
Crazy, being able to visualize our dynamic relationships in this way!
User Feedback
Interestingly, there really isn't any feedback to clicking this button. I added a message box to provide an acknowledgement. Ideally, once the rules above are implemented,
the list would no longer display the parent/child records to which associations already exist, which would provide the user with much more meaningful feedback.
One-To-One Relationships
A 1:1 relationship is a unique case in which often, the underlying schema has separated two concepts physically (like Task and CreateInfo)
but logically, the information should be displayed in a joined state. This is left for the next iteration!
Physical Entities vs. Logical Entities
One of the interesting artifacts of the ROP is that there isn't even a physical separation of entities attributes. For example, if there were a CreateInfo entity
with attributes like CreatedOn and CreatedBy, those attributes are in the same collection of attributes for every entity. In a typical schema, we would probably include
those fields in each entity, like the Task, Project, UserStory entities. To search for "all tasks and user stories for a date range" would
not be trivial. Creating a separate CreateInfo table is possible but would require a foreign key in each entity table, again making it difficult to search
date ranges across entity types. Furthermore, it isn't possible in a traditional database to say that the CreateInfo table has a foreign key field
to one of: Task, Project, and User Story entities. This means that the FK has to be in the parent table, which is a bit backward (acceptable in a 1:1 relationship,
but doesn't work in a 1:n relationships.) The ROP model overcomes these limitations.
In the ROP model, we could create a logical entity "CreateInfo", but that isn't even necessary. We might do so for clarity, but technically, the attributes
CreatedOn and CreatedBy could be in all required entities and we could still search across entities because the values are persisted to a single "pool"
of attribute values which can easily be mapped back to entity instances and types.
So, why create a separate entity? The best reason is maintainability. If we have a CreateInfo entity that consists of CreatedOn and CreatedBy attributes,
and later we want to add another attribute, say "ApprovedBy" (technically review and approval should be a separate entity, but go with the example here, please),
then all entities with relationship to CreateInfo automatically get use of this new attribute. If we had added CreatedOn and CreatedBy attributes to each Task,
User Story, and Project entity, then we would have to go back and add ApprovedBy to each of those entities, which would be more work. Eventually, this would create
an unwieldy mess of attributes, similar to the disasters I've seen in traditional schemas that have been tweaked over the years to fit new requirements, to the point where
fields that used to mean "A" now are used to mean "B"!
Unrelated Entities
One of the unique features of ROP is that entities are not required to be in relationship. For example, we can a Task that is not associated to a Project
or User Story. We can specifically query for unassociated entities regardless of entity type. This relaxes the constraint on the user to work within
a predefined set of relationship rules which require that entities be associated, allowing the user to fix up these unrelated entities later.
Relationship State
I still haven't implemented the rules for managing relationship state. One of the primary rules is, does the relationship type allow more than one active
relationship of that type (marriage is an example, though even the "married to only one person" rule varies by culture and religious persuasion.) Also, how is a relationship
designated as completed - for example, a job began at a certain date and ended on another date. These are issues to explore in what
I realize is the next installment (excuse me, iteration!)
Deleting Relationships
Relationships can be deleted with the super-user UI. From the perspective of the user, and as I mentioned in the previous article, relationships are not normally
deleted, they are "expired", "terminated", "completed", etc. In the GAPMA, relational information isn't usually time-state sensitive
as it is with say, a person-residence relationship. None-the-less, the user should be able to delete a relationship because, after all, everyone makes mistakes. And because
the ROP model is so flexible, it does mean that mistakes are more likely to happen.
Filtering Records
Obviously, we usually want to filter user stories, tasks, and so forth by the project in which we are interested. Notice an interesting
quirk though - the "Resolution" entity is related only with a Task, not with a Project. This limits our filtering capability - we can only view
"all resolutions" (across all projects) or "resolutions associated with a task(s)". Ideally, we would want the ability to automatically
join to parent records and leverage their filtering capability - for example, filtering resolutions by user stories via tasks associated
to user stories. This is left for another iteration!
Navigating Existing Relationships
Navigating relationships involves an implicit filter. When navigating from a child to a parent, we are implicitly qualifying the parent's primary key value
by the foreign key value of the child. When navigating from a parent to a child, we are implicitly qualifying the child's foreign key by the primary key value
of the parent. You will note that we are providing the same functionality that the super-user has, but this time in the "user friendly" mode.
A bare-bones approach looks like this (enough code, here's just a UI example of navigating from the project to the user story and drilling into a specific user story
to reveal the sub-stories.
Since a new modeless form is generated, there's no particular point in implementing a "Back" button, as one simply can close the form or select
the previous form. Note also that there is no consideration (as in, user feedback) taken for navigating relationships for which there are no target entity instances.
A feature for another iteration!
Also, there is no explicit feedback that the user is looking at a filtered view of the data. This would be useful! Finally, the user might think that,
if he/she adds a record in this filtered view, it is automatically put into relationship with the parent entity. This is not the case and can lead to confusion,
so at some point this needs to be taken care of as well.
Using the ROPT and GAPMA: A Walkthrough
Here's an example of adding some new entities types, creating the relationships, and entering some data into the GAPMA. What we're going to do is
add an "Iteration" entity to the model so we can categorize tasks and user stories under iterations as well. I also want to add a "Sprint" entity,
to which tasks can be associated, with the eventual idea in mind that the "velocity" of the Agile development can be tracked by measuring how well the tasks are
being achieved in each sprint.
First, open the "rop.model" file from the File -> Open menu:
Next, open the "gapma - save.data" file from the Model -> Open DataSet menu:
This is the version of GAPMA without the Iteration and Sprint entities.
Next, view the model in super-user mode by selecting the Model -> View Model Data (super-user mode) menu item. Select the EntityType:
Enter 2 new entity types: Iteration and Sprint:
Next, select the EntityTypeAttributes entity in the Current Entity combobox and enter the attributes "Name" and "Short Description"
and the ordinality for the newly created Iteration and Sprint entity types.
Next, select the RelationshipType entity in the Current Entity combobox and enter relationship types that associate the Iteration and Sprint entities to a Project entity:
Also, associate a Task to a Sprint and a User Story to an Iteration:
Close the Model Data Viewer and select Model -> Save DataSet from the menu to save the dataset.
Now you can open the "user" model data viewer from the Model -> View Model Data (normal user mode) menu item and select, say, Iteration in grid view mode:
- Enter a couple iterations
- Click the Save button to get the data into the ROP dataset model.
- Click on the "Show Data" button for the parent "Project" entity type.
- Select the iterations you created, select a project, and click on "Association"
You've now associated the iterations with a project.
- Go back to the main application for and click on Model -> View Model Data (normal user mode) menu item, this time select Project in grid view mode
- select the GAPMA project
- select Iteration from the "To Child" combobox and click on Go.
and you'll get the iterations associated with the project:
Don't forget to save the dataset when you're done! Now, for example, all tasks within a user story associated with an iteration can be drilled into! If we supported reporting,
we could generate a report of tasks in an iteration, or tasks in a sprint, or tasks not assigned to a sprint for an iteration, etc., etc., etc. Lots of food for thought
for what a reporting tool would need to support.
Visualizing Our Entity Type Relationships
Verify that you've created the relationships correctly by graphing the entity type relationships from the Model -> Graph Entity Type Relationships. You should get:
Notice we can't associate tasks to bugs. That's good, because first, we never have any bugs, and second, if we do, we never fix them!
Visualizing Our Entity Instances in a Relationship
And the real fun part is, now that I've created the relationships between various entities in my GAPMA, I can visualize them, which is a great way
to see if my Agile project is coming together in the right way. An example of that was given above, where I looked at the entity instances in relationship
to my "Rules" user story.
Other Applications - What About Bug Tracker
Another great application for this approach is bug tracking, separate from the concept of Agile development. One of my constant complaints
about bug trackers is the inability to add the fields that I want (at best, bug trackers have the ability to reduce the number of fields when displaying bugs)
as well as to establish relationships to other entity types that are specific to my application domain. Using the ROPT, these problems are completely
eliminated. As a super-user, I can create new entities and relationships, and as the user, I can populate the data and create the relationships that
I want rather than what the designer of the bug tracker thinks I want. One obvious situation is tying in a sophisticated bug tracker with GAPMA.
Interconnecting DataSets
This of course begs the question, can I connect a data model for a bug tracker to, say, my GAPMA data model? I have no idea, but I do know that this idea is worthy of exploration!
Conclusion
There is still a lot of work to do, but to a large extent, the hard work is done...the rest is spit and polish. That'll be the topic of the next article
in this series, making this a more refined application development tool. If you run the program, you will notice that the "user friendly"
UI is terrible. Lots of work to be done there, but I'm relegating that to a major code cleanup and getting the form to behave more autonomously. Not sure what that means yet,
but I'll figure that out later. Obviously, more data types need to be supported, and I really want to get away from the hideous .NET controls, so in the next article you will
probably see the move to DevExpress controls.
Lots of Tasks Identified
If you've read the text, you'll have noticed that I left a lot of things for future iterations. More articles!
Is Anyone Out There?
Is there anyone out there interested in contributing to this project? Ultimately, I'd like this to become a RAD product for developing applications of this nature,
complete with an n-tier back end and multi-user support. If so, I can give you access to the SVN repository and we can create our own sprints!
References

