Introduction
This article is aimed at trying to put together a practical guide for .NET architects, managers and developers for:
- Scaling .NET Web applications
- Architecting large .NET projects
- Managing .NET development teams
- Performance optimising .NET applications
Background
This is my first CodeProject article. I've been a long-time reader but as is often the case with software development, most of the articles I would know enough to write about have already been written! I have been writing lots of different .NET Web applications for some time now, but due to our startup company Zignals (which produces online investment software such as stock charts and market alerts), recently getting funding, I suddenly found myself having to start to seriously consider the problem of scaling these Web apps, both in terms of managing larger Visual Studio projects, managing a development team rather than just my own projects, and in terms of numbers of potential users and the bandwidth and processing implications thereof. Having gone through lots of different websites in all areas, I thought I'd condense what I've learnt (in as far as possible!) to an article for anyone else who finds themselves having to scale projects, or manage teams or squeeze extra speed out of their Web apps.
General Architecture Considerations for Scaling
Multiple IIS Servers (Hot swappable)
There are a number of reasons why having multiple Web servers for a Web application is desirable. The more Web servers available to answer user requests, the faster users requests can be processed and the higher the throughput of requests (i.e. more requests can be responded to within a given timeframe). There are also the inherent stability benefits of automatic failover, i.e. if one Web server fails there is always another available to answer any requests.
I'm going to focus on the practical aspects from a .NET development and project management perspective and I'm not going to go into the Admin side of this process as this can often be handled by your hosting company. The basic architecture involves a Network Load Balancer (NLB) to route requests equally between the Web servers, all of which talk to the same database server, e.g.:
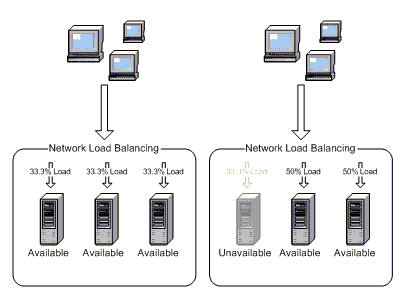
This has been taken from here.
If you want more detail on the sys admin side of things for this process, see an in-depth article here.
Practical Implications
So, given the obvious benefits of having more than one Web server available to handle Web users, what are the practical implications?
(There is a budgetary implication depending on what Web server you are using. If it’s IIS for example, as in this case, then each Web server will require its own copy of a Windows server operating system, e.g. Windows Server 2003 which has a licensing cost that may need to be factored in. In this article, I am only concerned with the technical aspects of the problem, so I will not be going into any cost benefit analysis etc. on this point).
So, from a technical perspective, the main implication of multiple Web server architecture revolves around how Session variables (and by extension server-side caching & persistence) are handled in your application. If you use the standard Session object in ASP.NET, then you have a problem. e.g.:
Session("SomeKey") = someObject
This line of code adds the object someObject to the ASP.NET session, which in the normal Web configuration is dependent on the current Web Server the users Request is being processed on. If all subsequent requests by the same user are going to be processed by the same Web server (as in the single server model) then this is not a problem. But a second Web server will not natively have access to the Users Session information that was created on the first Web server.
There are a number of ways to address this problem. You can use the <sessionState> attribute in the web.config to make IIS use a "StateServer" or "SqlServer" for maintaining state (see here). We've adopted a dual approach, where we handle our own persistence for objects that we want to persist indefinitely and consistently, while using the SQLServer mode to handle general "temporary" Session information. You will ultimately have more control over object persistence in the long term by handling them with your own classes. For example, if you use the state server method, you lose all the session information every time you restart the server. The same is true of the native implementation of the "SQL server" mode (although you can address this with some fiddling: see here). The reason we use SQLServer mode above the StateServer mode for temporary persistence is due to the inherent Single-Point-Of-Failure with StateServer. If the SQLServer goes down (which is a site-wide issue anyway), you can at least rollover the Sessions tables to the backup DB server, not so with the StateServer mode.
(As an aside, there doesn't seem to be a way to "catch" an error caused by a failure of a StateServer, as we experimented with this in the hopes of being able to use a StateServer with any errors due to state server failure forcing temporary Sessions over into our own persistence classes. But since the actual saving of the session information doesn't happen until after the postback has completed, we couldn't find a good place for a try catch block that would catch StateServer failure. We thought this approach would be the best of all worlds in terms of performance and reliability, but since we couldn't catch errors in the StateServer storage functions, this proved impossible. If someone else has found an answer to this, please let me know!)
To persist data across multiple visits and/or for longer than a standard session, we use our own persistence classes:
string CreatePersistantStorage(ip)
void PeristObject(string sessionId, string key, object value)
object GetPersistentObject (string key)
So wherever we would normally call Session(“Key”) = Value, and you want control over object persistence, we would now call:
PeristObject(persistentSessionId, "key", value)
And, correspondingly, all:
value = Session("key")
are now:
value = GetPersistentObject(persistentSessionId, "key")
Not much to it really.
Since both IIS servers will be pointing to the same database server, both will always have access to the same persistent information. The persistentSessionId parameter is generated upon the creation of the session and passed back to the client as a cookie:
string persistentSessionId = Persistence.CreateNewPersistentSession(ip);
Response.Cookies["Persistent_Session"].Value = persistentSessionId;
Response.Cookies["Persistent_Session"].Expires = DateTime.Now.AddDays(365);
Personally, I would recommend managing Persistence “manually” for a number of reasons:
- All information persists for as long as you want it to, regardless of whether the webserver or DB server is restarted.
- You have total control over the expiry of information.
- You can hold user data across multiple visits easily (e.g. "keep me logged in")
- You can add custom functionality (like compressing large persistent objects)
- It makes handling of database backups and auto-failover easier (e.g. all persistent sessions are not lost during DB server failover)
- And it’s pretty easy, so there’s no real development overhead.
We only store strings in our PersistentSessions table, as we have our own persistent Caching classes where we can store whatever data we want (discussed later). But if you want to store objects other than strings in your Session you can use something like this:
public static void AddItem(string itemKey, object item, bool doItemUpdate)
{
byte[] itemBytes = ZUtility.Serialize(item);
string query = string.Empty;
string sproc = string.Empty;
if (HasItem(itemKey))
{
if (doItemUpdate)
{
sproc = "dbo.p_UpdateObjectInSession";
}
}
else
{
sproc = "dbo.p_AddToSession";
}
if (!string.IsNullOrEmpty(sproc))
{
SqlQueryParam[] parameters =
{
new SqlQueryParam("@CacheKey", itemKey),
new SqlQueryParam("@CacheBytes", itemBytes, SqlDbType.Image)
};
SqlQuery.Execute(sproc, parameters,
SqlResultType.AffectedRows, CommandType.StoredProcedure);
}
}
Note: This requires the object to be marked as Serialisable (though this is true of the SQLSession state mode of IIS also). If you use this method of handling longer term object persistence, adding an additional Web server to the website simply involves copying the compiled projects (e.g. the inetpub\wwwroot) to the new server, setting up IIS to match the other servers, and adding it to the cluster.
If you don't want to persist objects longer than a standard Session, you still have the problem of handling Sessions over multiple webservers, so you need to look at the StateServer and SQLServer session modes in .NET. A brief article discussing the normal methods of handling sessions can be found here.
A final practical point on a Web farm environment is the DB server. You can have lots of Web servers easily, but multiple SQL servers is more tricky. There are technical articles out there on how to achieve this, so all I'll say is that 1 SQL server on a fast machine can handle a lot of traffic if configured correctly. The main issue, until you get to millions of daily requests, is the "single point of failure" issue. We have a second SQL Server machine running in parallel to the first on a replication & failover basis and the bonus of handling persistence manually in SQL Server is that SQL server failure does not mean losses of persistent data, as the second server has a copy of all of this data.
And if you are willing to stretch the rules when it comes to mirroring and failover slightly, this second backup server can be your DB cache & persistence server and you then have a backup server that is also actively helping boost site performance.
Visual Studio Project Structure for Large Web Applications
Having a good project structure is the best way to make large Web applications manageable, both for individuals and especially for development teams. And having functionality encapsulated within .NET DLL projects is a vital part of any Web application, and I recommend starting all new Web applications with this in mind. It is especially important for large Web projects that may be multi-faceted, have numerous separate user interfaces or be worked on by a large team, or teams. To best deal with this issue, the project structure we use in Zignals is:

Framework.dll
This stores all the low level classes and functions that will be common to all Web projects. For example, our framework has:
- Session.cs: Handles all Web application Session logic
- Logging.cs: Handles all error and information logging
- SqlWrapper.cs: Handles all low-level interaction with the database
- ZUtilities.cs: All utility functions
- Security.cs: All encryption & security functions
Etc. Basically anything that is project independent. If you are building just one large Web project, you could have your business logic in this DLL to save hassle with multiple references/namespaces, but if you want to re-use your common functions across multiple sites, you should have a separate project for the business logic.
BusinessLogic.dll
Holds all the functionality common among the various Visual Studio projects that are built for the current website. Having your business logic here allows developers of different project types (e.g. Windows services, Web services, Web applications) use the same underlying business logic. In our case for example, we allow a user to Simulate an investment strategy online (Web application). We also have a complex algorithm that automatically builds a strategy. Because of processing requirements, this algorithm runs as part of a Windows service that allows processing to queue while waiting for a free CPU. Once the strategy is auto-built, it also needs to be simulated over a historical time period to assess performance. Since we have the “SimulateStrategy” function in the Strategy class in the BusinessLogic.dll, both the Windows Service project and the Web Application project can simply reference the BusinessLogic.dll project output and always use the most up-to-date version.
CustomWebControls.dll
This project holds any ASCX files that we use. The reason for having these in a separate project is so we can have developers building controls independently of the developer consuming them. It also means that we can re-use these controls across multiple Web projects. It also allows us to dynamically add these controls from C# code. For a detailed look at creating User Control Libraries, see here.
CustomControls.dll
We have a custom controls project for any custom objects that we want to be able to store in the database (e.g. serialized into our DB cache). The reason for a separate project and solution is because of the fact that recompilation of a DLL will create a different signature for the object and you won't be able to de-serialise objects stored in the database after re-compilation. Since you re-compile your Web projects for every new line of code, this would make serializing and storing objects in the database impossible, hence the CustomControls library. Incidentally, we generally only have very basic objects in this library so there is very little call for recompilation.
WebApplication1
Whatever Web application you would normally have produced.
Web Application2
If required. We have multiple Web applications because of the division of labour (e.g. different developers or development teams can have “autonomous” responsibility for their own project), and because having hundreds of ASPX files or directories in one project is cumbersome.
All these projects can be opened as part of one Visual Studio solution and you can set a build order that makes the framework compile first, then the business logic, and so on all the way up to the Web applications. In the example above, taken from our main Visual Studio solution, you can see the Framework and BusinessLogic projects and the two Web projects (Dashboard and ZignalsTools). The CustomWebControls project is called WidgetControls for our site.
You will also need to copy all the *.ascx files for the CustomWebControls project into a directory of which ever Web applications are using them. This is done by setting the pre-build event of the Web project consuming the CustomWebControls to something like:
copy "$(SolutionDir)"CustomWebControls\*.ascx "$(ProjectDir)"UserControls\
You will also want to make sure that each project higher up the chain has a reference to the project output of the projects lower in the chain. E.g. BusinessLogic.dll has a reference to the project output of Framework.dll. This is done by right-clicking on “Add Reference” in the business logic project and selecting the “Projects” tab in the dialog box and selecting the relevant project.
Caching on Web Servers with .NET
Web application performance can be greatly increased by caching frequently used data that would usually come from the database. This performance enhancement is further exaggerated if the Web application has to perform some complex operations on the raw data prior to displaying it (financial calculations, graphing, etc.) or if the data is coming from a 3rd party data source, such as an RSS feed from another site, or an XML Web service call, where the network latency associated with acquiring the data can be a significant delay.
There are a number of different ways of caching data available in both IIS and .NET that can be useful for different purposes. In .NET, there are the cache classes HttpRuntime.Cache and HttpContext.Current.Cache that can be used to cache objects. There are minor differences between the two, but a good argument for using the HttpRuntime.Cache can be found here.
So, now you have your in-built caching class, what’s wrong with calling...
HttpRuntime.Cache.Insert("SomeKey", someObject)
... for all your cacheable Web objects?
Similar to the Sessions problem above, the issue lies in what happens when you move your application from a single Web server environment to a dual server, multi-server or Web farm environment. The output of data requests made to one server will be cached on that server, but there is no guarantee that the next request made for the same data will be made to the same Web server in the Web farm, which will mean another trip to the database and a re-caching of the data on the new server, and so on.
Our solution is to have 2 levels of caching, the ASP.NET memory cache implemented using the HttpRuntime.Cache class and a DBCache, which serialises objects and stores them in our Cache database.
By having a dual layer approach, we can access the raw data in our database for the first time we use the object, then we can add the resulting object into the DBCache and the MemoryCache. If the users next request for the same object happens on the same webserver as before, they get the object directly from the IIS inProc cache (HttpRuntime). If the same request happens on a different Web server in the server farm, the users request will come pre-generated from a de-serialisation of the object in the DBcache (faster than re-computing the object from the raw data in the main database). This Web servers Application cache is now populated with the same object so next time it is requested at this webserver the response is direct from the memory cache.
We generally use this dual caching for generated objects shared by many users. This means that the first user request will be cached and all further requests by any user will be served from the caches.
An example in our case would be for when a user requests a 14 day moving average of Microsoft stock (MSFT) for the last 5 years. The first request takes the raw Price data from our Prices table and computes an array of doubles representing the MA value for each day over the last 5 years. It is very likely that another user will want to calculate the same values (or a portion thereof, but how we handle that from our cache is a different story!) so we serialise the double array and store it in the caches. A subsequent request for the same calculation will not require a trip to the large Price data table or any computation, the only question is whether or not the request is fulfilled by the IIS cache on the Web server or from our DB cache.
We store all the DB Cache data on our CacheServer, which is a separate physical server running a copy of SQL Server (i.e. independent of our main SQL Server). Incidentally, you don't need a full enterprise edition of SQL Server for the Cache server as SQL Express edition has more than enough power and capacity for the needs of the cache, and it’s free.
This approach also has the added benefit of allowing us to persist our cache for as long as we want. The cache is not destroyed when a Web server restarts for example, and we can add on additional Web servers very easily, with the knowledge that they will have instant access to a long history of cached objects generated from the Web applications that have been running on the other Web servers.
One thing to be aware of about our method is that it is effectively a read-only cache, as in all the objects we want to cache are ultimately created from raw data in our DB server and not created or modified by user input. This is an important point, as if you want to have a read/write cache, where the users input might override the cache entries, then you will need to use a different approach. One I'd recommend, and one we've implemented and are experimenting with at the moment, is based on the approach discussed here. This method can also be used in place of our read only cache, but we don't have enough statistics yet to say whether or not the ratio of speed boost to memory usage is an efficient one (e.g. if every user on any webserver creates data that is passed across the Web farm network and stored in every other Web server, then it is important to know that this data is re-used often enough to make this operation effective)
LRU Policy
Finally, we have an LRU policy for the DB Cache (the LRU policy is natively implemented by the IIS cache, though it’s not obvious from the documentation). We have a cache monitoring service that runs on our cache server and will automatically remove any items that are past their “expiry” date. Upon addition of new items, if there is not enough “room” in the cache, then the least recently used item is removed from the cache. The LRU policy on the SQL server cache is handled by storing the keys in the cache table ordered by how recently they were used. We have a column in the cache table that is always ordered from least recently used to most recently used. E.g. Upon accessing a row in the cache table:
So, removing the least recently used item means deleting the row at position 1, and decrementing the LRU column in remaining rows by 1. (In practice when we hit an LRU operation, we delete a large number of rows to prevent us constantly having to update rows on insertion of new items).
Performance of Web Applications
There are a lot of things that can be done to a Web application, both on the front end and on the back end, to make it run faster, use less bandwidth and utilise less server processing power. In some cases, the results can be dramatic to the end user, and in other cases the results can be dramatic to the number of concurrent users a server/bandwidth will support. In all cases, it is a very useful and productive exercise. We spent quite a lot of time trawling around the Web and various forums and user groups trying to put together a standard list of performance enhancements that have a low overhead for implementation, are repeatable and easy for developers to put into general practice without headache, and which produce measurable improvements. I'll summarise the paired down list here, but for anyone keen to extract every last processing cycle from their servers, I've listed a “top 10” set of links at the end of this article to some of the performance articles we found most illuminating, all of which contain very useful information. And although it’s not aimed at .NET applications specifically, if you just pick one to explore, I really recommend the Yahoo performance best practices list.
JavaScript Single File Combination/Minification
Replace multiple JavaScript files on a Web page with one large (minified) file. Copy every JavaScript file that is used for a particular webpage into one single master JavaScript file called say AllScript.js. Then replace the <script /> tags that reference these files with one single script reference for the AllScript.js file. This script reference should be placed as close as possible to the bottom of the webpage so that visual content is loaded first without JS files slowing down the loading of content such as CSS files and images/media. All JavaScript within a page should be transferred to the external JS file.
The master JavaScript file can be further minified be using a handy program called JSMIN which removes whitespace from input file and returns minified file on output. This minified version can be referenced just the same by referencing it like AllScript_min.js at bottom of ASPX file. This file can also be referenced in the asp:ScriptManager/ToolScriptManager control by setting the ScriptReference tag's Path attribute to the path of the file. If the attribute LoadScriptsBeforeUI is set to false then any referenced JS files are placed at the bottom of the webpage when rendered. Using the Firebug tool for Firefox, we can inspect all the JS files that are requested and downloaded to the browser as the page runs. When the AjaxControlToolkit is used, the client-side JS files that it uses are named ScriptResource.axd are dynamically referenced and downloaded to the browser. This results in a large number of separate requests (which we want to avoid) so an option exists where these files can be combined into one single HTTP request. This can be done by setting the CombineScripts attribute on the ToolScriptManager control to true. ToolScriptmanager inherits from the ScriptManager control so it is fine to substitute for the ScriptManager control in ASPX pages.
CSS Single File Combination/Minification
CSS files should be referenced in the head section of the HTML/ASPX page as we want the visual to load before the script files. Similar to the above JS single file combination/minification process, we can combine all referenced CSS files required for a particular page into a single master CSS file called say AllCSS_min.css and just reference this in the <link />tag inside the header. The CSS files can be simply copy/pasted into master CSS file and a tool called CSSMIN minifies these into one single CSS file.
Now you may be thinking not to bother with the above 2 steps because all the JS and CSS files will be cached on the browser after the first visit since they are static content. Well I was surprised on this one also, but there are a good statistics that suggest that 40-60% of all daily visitors to a given site arrive with an empty browser cache. And making the experience as fast as possible for the first time users is almost more important than for the everyday users. Also, if 40-60% of daily traffic is from an empty cache, and you expect a lot of daily users, then the server load will be a lot heavier as there could be 10x as many page requests.
IIS 6.0 Compression
Enabling compression is a must. On IIS 6.0 (e.g. Windows 2003 server) compression of files are on by default for static compression. To allow for dynamic compression, this can be activated by running a script or activating it through IIS 6.0. This article explains the procedure in detail.
CSS Sprites/Multiple Image Combination
For each image referenced for a particular page in your website, a separate HTTP request is issued to download it to the browser. If you have a large number of images, this can use a lot of bandwidth and is not so efficient. Images can instead be combined into one larger image and this can be downloaded as one HTTP request. On the browser sections of the webpage that want to display an image such as <img /> elements can all reference the same master images by setting the src attribute to for example sprites1.png and supply offsets for the background-position property to “pick out” the image required from the master image. This process is made easier by a 3rd party tool called CSS Sprites Generator. Simply upload all the images used on a particular webpage and hit generate and this website automatically combines all images into one single image supplying offsets as shown:
.info {background-image<span class="code-none">:url(sprites1.png)<span class="code-none">;
background-position<span class="code-none">:-66px -66px<span class="code-none">;
<span class="code-none">}
.lightning <span class="code-none">{
background-image<span class="code-none">:url(sprites1.png)<span class="code-none">;
background-position<span class="code-none">:-66px -246px<span class="code-none">;
<span class="code-none">}
.magnify <span class="code-none">{
background-image<span class="code-none">:url(sprites1.png)<span class="code-none">;
background-position<span class="code-none">:-66px -510px<span class="code-none">;
<span class="code-none">} </span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span></span>
NOTE: Elements that use the CSS attribute repeat for images cannot be used in this process. Also animated *.gifs will not work either. And to add new images to the master image you need to upload all the previous images in the master image in the same order again to keep same offset values.
It is important to keep a record of the offsets for each image within the master image for reference.
Web.config/Machine.config Optimal Settings
For production websites, it’s important to remember to set the <Compilation debug =”false” /> setting in Web.config. This ensures no unnecessary debug code is generated for release version of website. If you are not using some of the ASP.NET modules such as Windows Authentication or Passport Authentication etc. then these can be removed from the ASP.NET processing pipeline as they will be unnecessarily loaded otherwise. Below is an example of some modules that could be removed from the pipeline:
<httpModules>
<remove name="WindowsAuthentication"/>
<remove name="PassportAuthentication"/>
<remove name="AnonymousIdentification"/>
<remove name="UrlAuthorization"/>
<remove name="FileAuthorization"/>
<remove name="OutputCache"/>
</httpModules>
ASP.NET Process Model configuration defines some process level properties like how many number of threads ASP.NET uses, how long it blocks a thread before timing out, how many requests to keep waiting for IO works to complete and so on. With fast servers with a lot of RAM, the process model configuration can be tweaked to make ASP.NET process consume more system resources and provide better scalability from each server. The below settings can help performance (a cut down version from an excellent article here):
<processModel
enable="true"
timeout="Infinite"
idleTimeout="Infinite"
shutdownTimeout="00:00:05"
requestLimit="Infinite"
requestQueueLimit="5000"
restartQueueLimit="10"
memoryLimit="60"
responseDeadlockInterval="00:03:00"
responseRestartDeadlockInterval="00:03:00"
maxWorkerThreads="100"
maxIoThreads="100"
minWorkerThreads="40"
minIoThreads="30"
asyncOption="20"
maxAppDomains="2000"
/>
Caching 3rd Party Data & Generated Images
If you are acquiring data from 3rd party sites (e.g. RSS feeds, mashup data, Web services, etc.) then it can be a good idea to cache this data for short periods (depending on how “real-time” the data needs to be). It can make a significant difference in page loading time when there are many remote requests for this sort of data. In our case for example, we allow users to specify RSS feeds that they are interested in monitoring. Since many users can specify the same popular feeds, we can cache the RSS data returned from remote site as XML and store it in the Database for a short period (e.g. 10 mins). By doing this, only the first person to request the RSS feed will have to experience the delay whereby our server has to send off a request to the remote server where the RSS data resides. All subsequent users during the cache period will receive their data directly from our Cache, negating the latency and bandwidth requirements associated with contacting the remote server.
We also use a 3rd party charting control that generates an image (*.png/*.jpeg) on the server when it creates a chart. We cannot cache these images where users specify user-specific parameters to generate them, but when images are generated which are the same for each user, (e.g. default chart images that only update on a daily basis), then we can cache them for 1 day and avoid the expensive process of recreating this chart image every time a user requests one of these “default” type images.
Further Reading
Many other authors have gone into much more detail than the above summary, and while 10% of the suggested improvements can yield 90% of the performance benefits, I would recommend the following links for anybody interested in implementing the fastest possible Web applications:
- Best Practices for Speeding Up Your Web Site
- Speed Up Your Site with the Improved View State in ASP.NET 2.0
- 10 Tips for Writing High-Performance Web Applications
- ASP.NET Ajax in-depth performance analysis
- Improving ASP.NET Performance
- 10 ASP.NET Performance and Scalability Secrets
Of the many detailed items I left out of my above summary, the main one that I would recommend is using a Content Delivery Network (CDN). I only left it out because we haven't implemented this yet, so I would only be guessing at the performance improvement, but it stands to reason that it would be significant for large, global websites.
Finally
It's been quite a journey from small local Web applications to large, scalable and potentially global applications developed by teams rather than individuals - I hope the documenting of the processes I went through will be of use to other developers or project managers who are facing similar projects.
The attached project files are the overall solution architecture and the persistence classes discussed at the start of the article. If there is any interest in the code associated with some of the other areas discussed, let me know and I'll see what I can make available.
History
- 21st October, 2008: Initial version

