Introduction

| Text TakeOut takes out data from any messy ASCII document and exports it, after some defined fields from the user, into a Comma Separated Values (CSV) file. If you need something quick and easy to get some very useful data form a source (HTML, Text (txt), etc.) document, then Text TakeOut will work for you. The ExtractSet and CSV class may be useful for an application that needs an object to store a string Start, End, Value, and FieldName. The CSV is used to create a CSV file using a System.Collections.Generic.List<ExtractSet> object.
Background
I decided to create this project after being emailed an HTML document of over 100 external Trouble Tickets for one of our business applications. I bet I am not the only one to receive such a file, and I needed to make use of the data contained within it. Defining the fields I needed and exporting it into a common format was something I was looking for. Text TakeOut can be a powerful solution in some situations.
|
Using the Code and Using the Utility Application
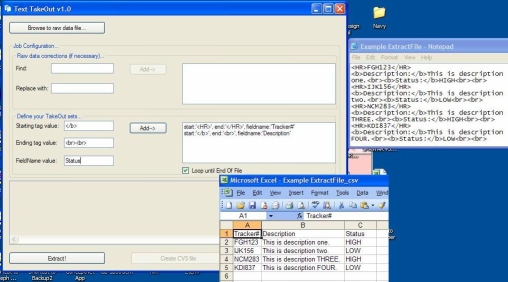
The ExtractSet and CSV classes are the wheels of this car. ExtractSet stores the data which works well using a System.Collections.Generic.List or any other object that is easily iterated through. startvalue holds the beginning string tag of where the data you wish to 'TakeOut'/extract. endvalue holds the ending string tag of the desired data. For example, using the sample file which is included in the project's main source folder, 'Example ExtractFile.txt' has a repeating value we wish to grab, but the current format is "<HR>FGH123</HR>", "<HR>IJK156</HR>", etc. The first ExtractSet will be startvalue="<HR>", endvalue="</HR>", then we will define a fieldname that summarizes the data in-between these two points in the string, fieldnamevalue="Trouble Ticket#". Next, in the actual raw document is the description of the trouble ticket#, it is surrounded as follows: startvalue="</b>", endvalue= "<br>", then we define the fieldnamevalue="Description". In the utility app, the "Add->" button will not be enabled until you have all of the fields that are necessary to create the ExtractSet.
|
|
The Find and Replace With features in the utility application will prepare the full string before iterating through your ExtractSet definitions. The application actually uses a List<ExtractSet> to store the user defined Find and Replace With sets. I found this useful for broken HTML tag sets that I needed to keep together so that when the iteration began, no data would be missed. For example, on one raw document I was working with, I had to perform a prep on the main string:
tempcopy = tempcopy.Replace("Date \r\n Entered:", "Date Entered:");
tempcopy = tempcopy.Replace("Date \r\n Entered:", "Date Entered:");
tempcopy = tempcopy.Replace("Date \r\n Entered:", "Date Entered:");
tempcopy = tempcopy.Replace("Date \r\n Entered:", "Date Entered:");
Text TakeOut can automate this when the user creates sets as follows:
Find:"Date \r\n Entered:"
Replace With:"Date Entered:"
Find:"Date \r\n Entered:"
Replace With:"Date Entered:"
Find:"Date \r\n Entered:"
Replace With:"Date Entered:"
Find:"Date \r\n Entered:"
Replace With:"Date Entered:"
The basic steps to use the application are as follows:
- Click on the 'Browse to raw data file...' button, and select the file you wish to extract your data from.
- Create your Find Replace Sets to prep the main string.
- Create your main Extract Sets to extract and define the data you need from the main document.
- Click the 'Extract!' button.
- Click the 'Create CSV File' button to create the .csv file in the same location as your main.
Conclusion
Text TakeOut still needs some fine tuning, but it can get a lot of useful, sometimes critical, data from some pretty ugly sources into a very common format. You can do almost anything you need to do with CSV. The ExtractSet and CSV class may be useful for an application that needs an object to store a string Start, End, Value, and FieldName. The CSV is used to create a CSV file using a System.Collections.Generic.List<ExtractSet> object.
Updates
2/11/07
- Article and Text TakeOut version 1.0.0.0 posted.
2/13/07
- Updated Text TakeOut version 1.1.0.0 uploaded.
- Automatically removes "\r\n" and "\n" from the extracted value.
- Exception handling and user explanation if extraction error occurred during extraction.
1/13/09
- Fixed download link text.

