sha256sum: 018750ea93e4b79791d97d1e746b64dedd0f7ded711b440c5ba2932ceb15dbaf
sha256sum: 863fa5f825fcd818c431590006517d8f572104b1c2f398490fb6531a32ac11b5
Introduction
Many disciplines depend on linear regression for understanding data. Most often, practitioners turn to packaged programs to do the math. These applications are rich and useful. However, when you create a program that requires these computations in an ancillary way, interfacing your programs with these applications is often heavy-handed or awkward. Sometimes, they also have the disadvantage of hiding the underlying algorithms in closed-source code.
This article introduces a basic set of Java classes that perform matrix computations of use in solving least squares problems and includes an example GUI for demonstrating usage.
Background
My primary reference for developing my Java classes is:
Matrix Computations 3rd Edition by Gene H. Golub and Charles F. Van Loan (Johns Hopkins University Press, Baltimore, 1996) (Golub)
Mathematically, our objective will be to obtain a vector x given a known matrix A and a vector b, such that:
Ax=b, where A is an m x n matrix, x is a vector of length n, and b is a vector of length m
The case where m = n is called a determined system. When m < n, we have an underdetermined system and when m > n, we have an overdetermined system.
Linear Regression
Consider a system of simultaneous equations:

If we assign the coefficients to a matrix A, then the system can be represented as:
Determined systems have a unique solution. Overdetermined systems have an infinity of solutions. Underdetermined systems have either no solutions or an infinity of solutions. We want our solution to be a least squares solution. In some cases (e.g., overdetermined, rank deficient systems), there are infinitely many least squares solutions and we may further want to select one that also minimizes a specific norm, e.g., the Euclidean norm.
Linear regression is most useful when either the columns of A are suitably independent or a mechanism for reckoning with dependent columns is implemented. How can we evaluate column dependence? We can compute the matrix condition of A, which is the ratio of the highest/lowest singular values. A condition of 1 is perfect. High numbers indicate column dependence and, if we want a useful regression equation, we need a way to detect dependence at a reasonable threshold. When unacceptable dependence occurs, we consider the matrix to be rank deficient and, provided our method accounts for rank deficiency, we can still obtain useful results.
A Few Methods
Gaussian Elimination (LU Factorization)
class: MatrixLU.java
We can use the LU factorization followed by back calculation to solve determined systems. Gaussian elimination does not account for rank deficiency. Where there is unacceptable column dependency, the solutions are very sensitive to small variations (perturbations) in A. It is also hampered by rounding errors, which can often be mitigated with a pivoting strategy. It is computationally inexpensive and is useful with systems of acceptable condition and known immunity to floating point errors.
Normal Equations
class: NormalEquations.java
The normal equations method works for full rank systems.* It is fast but the accuracy is adversely affected by column dependence. It does not reveal, nor account for, rank deficiency.
*As implemented in the class NormalEquations.java, it will not work for underdetermined systems because the Cholesky factorization that it uses requires a positive definite matrix. The method can be modified by explicitly forming Inverse(A-transpose)(A)) at the hazard of rounding error.
QR with Column Pivoting
class: MatrixQR.java
QR factorizations with column pivoting can be implemented in a way that detects rank deficiency at a specified threshold (see the parameter τ in Golub Algorithm 5.4.1). When rank < n, the offending elements of the x vector are set to 0. The parameter τ (tau) can be set as low as machine precision (~ 10-15 on my PC), but this is very often too low to usefully detect rank deficiency in real-world problems.
Complete Orthogonal Decompositions
class: MatrixQR.java
With rank deficient systems, there are infinitely many least squares solutions. In some applications, the practitioner doesn't care which one they get as long as the function fits the data. In other cases, it is preferable to use the least squares result that is also a minimum Euclidian norm solution. A complete orthogonal decomposition provides such a solution.
The Singular Value Decomposition
class: MatrixSvd.java
Both the QR with pivoting and complete orthogonal approaches require choices for the rank-determining threshold value: τ. The appropriate choice for τ is an application-specific challenge. The question is: at what point does the lack of column independence interfere with the usefulness of the result? The singular value decomposition does not answer that question but examination of the vector of singular values it produces provides fine-grained, rank-revealing insight (Golub 5.5.8). Ultimately, our question can only be answered with a knowledge of the system being studied and the purpose the regression equation will serve.
Setting Up a Problem, an Example
My favorite example is from: Crow, et. al., Statistics Manual with Examples Taken from Ordnance Development, Dover Publications Inc., NY, 1960.
(I am convinced that this example was originally worked in an afternoon with a pencil and slide rule.)
| v1 | v2 | v3 | | y (product diameter) |
| 11 | 58 | 11 | | 126 |
| 32 | 20 | 13 | | 92 |
| 14 | 22 | 28 | | 108 |
| 26 | 55 | 28 | | 119 |
| 9 | 41 | 21 | | 103 |
| 30 | 18 | 20 | | 83 |
| 12 | 56 | 20 | | 113 |
| 29 | 40 | 26 | | 109 |
| 7 | 38 | 9 | | 130 |
| 28 | 57 | 10 | | 106 |
| 10 | 19 | 19 | | 104 |
| 31 | 37 | 18 | | 92 |
| 12 | 21 | 10 | | 94 |
| 33 | 40 | 11 | | 95 |
| 9 | 42 | 27 | | 109 |
| 12 | 57 | 29 | | 103 |
| 10 | 21 | 12 | | 82 |
| 33 | 40 | 19 | | 85 |
| 30 | 58 | 29 | | 104 |
Our job is to provide a formula that best predicts product diameter based on process variables v1, v2, and v3.
Specifically, we are asked to provide the constant coefficients C, x1, x2, and x3 that best fit the data using an equation of form:
y = C + (x1)v1 + (x2)v2 + (x3)v3
In our matrix representation, Ax=b, the b vector is the sequence of product diameters (m=19). It is tempting to think that the A matrix consists of the three columns containing v1, v2, and v3. That's close, but in our target equation, we require a constant and that requires that we have an n=4 matrix where the first column is filled with 1s and the remaining columns consist of v1, v2, and v3 (a Vandermonde matrix):
The result is:
y = 95.74 - 0.5973v1 + 0.5151v2 - 0.0486v3
nth-Order Regression Solutions
Sometimes, the regression equation we want is an nth-order univariate polynomial rather than an n-dimensional multivariate polynomial. For example, a cubic equation:
y = a + (b)x + (c)x2 + (d)x3
Consider:
In this case, the A matrix is a Vandermonde matrix where the 2nd, 3rd, and 4th columns are x , x2, and x3 respectively. The solution in this case is a non-linear regression:
y = 1.1 - 1.2x + 1.3x2 -1.4x3
Transformations
Suppose you want to see how well the data fits an equation of form:
y = exp(c0 + c1x + c2x2)
You can use the Vandermonde approach to solve Ax =ln(b):
ln(y) = c0 + c1x + c2x2
How would you transform the data to fit: y = αeβx ?
Using the Demonstration
You will need Java installed on your machine. The demo has been tested on Linux and Windows. Be sure your Java is up to date. Depending on your OS, running Java.jar files is usually as simple as a double-click.
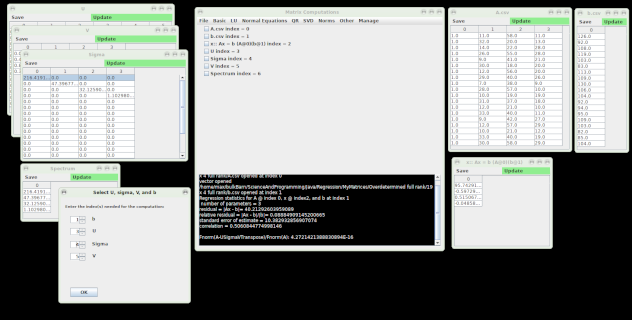
The demo comes with a few example systems in the zip file. You can open these from the file menu and experiment. The file format is a standard comma separated value structure. When you open a file, notice that it is indexed on the main form. In the menus, use the index to specify the item(s) you want to use as parameters in the operation(s). Note that before you can solve for Ax=b using the LU, QR, and SVD menus, you must first perform the corresponding factorization. Here's an example:
- Menu -> File -> Open -> Matrix - then find and pick the A.csv file in Examples/Overdetermined full rank/6 x 4 Rank 3
- Menu -> File -> Open -> vector - then find and pick the b.csv file in the same folder.
- Note on the main form that
A is index 0 and b is index 1. - Menu -> SVD -> U,Sigma,V::A
- Choose
0 for the matrix index in the window that pops up, then click OK - Note on the main form that
b is in index 1, U is in 2, Sigma is in 3, and V is in 4 - Menu -> SVD ->
x::Ax = b - set the indices as shown in the previous step, being sure to match the indices on the pop up with the proper ones shown on the main form. (1, 2, 3, 4) - Menu -> Other -> Fit Statistics - Set the indices (
0, 5, 1) and set k to 3 (k is typically set to the matrix rank but is set to rank -1 when using a Vandermonde matrix (as you can see by inspecting the first column of A) - Menu -> SVD -> Singular vector shows that the
A matrix is rank deficient. - You can close matrices from the Manage menu. Clear all but
A and b and try the QR menu using the default value for tau. Watch the text in the black console area and see that assigns a rank of 3 to A.
Complex numbers should have the format: ### [+/-]i###
- Example:
5 +i2 (mind the spacing) - The real part may be absent but prefer
0 [+/-]i### - You can use
j instead of i - You can put
i or j at the end: ### [+/-]###i
The great thing about matrix computations is that you can always check your results. You can synthesize your own systems using Excel or LibreOffice, saving your matrices and vectors as csv files. Always test your results.
Using the Code
The project zip is a complete Eclipse Java project (Version: 4.10.0). The source code is IDE and platform independent. There is a license file: License.txt. The classes in the project are listed below. Each class has a class responsibility comment near the top that summarizes its purpose.
Computational Classes
There are eight computational classes:
- ComplexCalc.java
- ComplexNumber.java
- MatrixLU.java
- MatrixOps.java
- MatrixQR.java*
- MatrixSvd.java
- NormalEquations.java
- Statistics.java
In your real world applications, only these computational classes are needed, perhaps only a few of them. For example, if you have a double[ ][ ] array containing matrix A and a double[ ] array containing vector b, then a one-shot function could be constructed that, say, computes x using a QR pivot approach:
public double[] GetX(double[][] A, double[] b) {
List<Object> oQR = MatrixQR.HouseholderCompactQRPivot(A, 0.00000000000001);
double[][] QR = (double[][]) oQR.get(0);
int rank = (int) oQR.get(1);
int[] p = (int[]) oQR.get(2);
double[] beta = (double[]) oQR.get(3);
double[] x = MatrixQR.HouseholderCompactQRSolveX(QR, beta, p, rank, b);
return x;
}
The matrices are row major arrays. In the example below, A has 3 rows and 2 columns ( m = 3, n = 2 ):
double[][] A = new double[][] { { 0.1961, 0.3922 }, { 0.5883, 1.1767 }, { 0.7845, 1.5689 } };
*There are return parameters for the QR methods (also inputs for the QR Ax=b methods) that may seem unusual, specifically, the beta vectors. Beta is not a required element of a QR Pivot factorization because it can be re-calculated as needed from the compact QR, but consuming this vector may eliminate the overhead of re-computing the values in multiple, subsequent functions (see Golub 5.1.6).
Demo Classes
The classes for the graphical demonstration are:
- EventListener.java
- FileOps.java
- InputForm.java
- MainForm.java
- Master.java
- MatrixForm.java
- Operation.java
- ParameterForm.java
- StringUtils.java
The MainForm.java class is the entry point GUI JFrame. It is a topmost form that has menus and displays the active matrices and vectors together with a unique index number for each. It also has a text area (txtrConsole) that posts feedback from events originating from an EventListener interface (e.g., details of a file open operation) or from txtrConsole.append commands located in the MainForm class (e.g., statistics results).
The MatrixForm.java class is a JFrame container for individual matrices and vectors. The Master.java class holds the collection of all existing MatrixForms in the running application (ArrayList<MatrixForm>) and also includes the methods that implement the various computations that are requested from MainForm using MatrixForm objects as arguments. These objects are indexed. When an operation is picked from the MainForm menu, the ParameterForm is displayed where the user specifies the indices of the matrices/vectors pertinent to the problem.
The operations available in the demo are enumerated in Operations.java. The StringUtils.java class is used for casting matrices/vectors to csv strings.
Points of Interest
My brother did a high school science project in 1964 entitled: Mathematical Evidence for the Existence of Transuranium Elements. I watched as he programmed a normal equations solution into a punch tape computer, a remarkable implementation that used jump statements. I started regression programming in the 1970s with Fortran IV on an IBM mainframe and punch cards. Later, I moved to microcomputers interfaced with laboratory instruments, primarily using HP-RPN or Pascal. At home, I used the Vic 20. In the 21st century I switched to .NET and Java.
In 2003, I bought Golub/Van Loan, Matrix Computations and began exploring the rich world of matrix computations, with a particular interest in solving linear systems. Needless to say, I am a linear algebra enthusiast and, I might add, I am lots of fun at cocktail parties because of it.
I had the privilege of corresponding with Gene Golub on several occasions before his death in 2007. Matrix math has enriched my life and the book, Matrix Computations, made that possible.
A Few References
- Bjorck, Ake, Numerical Methods for Least Squares Problems, Society for Industrial and Applied Mathematics, Philadelphia, PA, 1996.
- Golub, Gene H., Charles F. Van Loan, Matrix Computations 3rd Edition, The Johns Hopkins University Press, Baltimore, MD, 1996.
- Pollock, D.S.G., A Handbook of Time-Series Analysis, Signal Processing and Dynamics, Queen Mary and Westfield College, The University of London, Academic Press, 1999.
- Serber, George A. F., Alan J. Lee, Linear Regression Analysis, 2nd Edition, Wiley and Sons, Inc., Hoboken, NJ, 2003.
- Watkins, David S., Fundamentals of Matrix Computations, 2nd Edition, John Wiley and Sons, Inc., New York, NY, 2002.
History
- January 2019: Article submitted

