The Microsoft Win32 subsytem has had cryptographic support since Windows NT4.0 in the form of APIs that were exported by CryptoAPI. However, CryptoAPI has been deprecated, and was superseded by Cryptography API: Next Generation (CNG) which has been the long term supported cryptography API. Its extensibility and algorithm agnostic interface makes it easy to use at the application level. It also makes it easier for Microsoft to implement new algorithms. In this article, I show how a programmer can wrap that API for the purpose of hashing data.
Introduction
In this article, I show how you can use a wrapper class for the Cryptography API to have a convenient and reusable method for hashing data, combining ease of use with cryptographic integrity. Note that cryptography is a complex subject, and guaranteeing security in the face of attacks is a field best left to experts. My article focuses on the use of CNG. I don't expand into key management / key storage because I have no real world experience in that area and bad advice is worse than no advice.
The reason for implementing this wrapper class was that I had the need to create a hash for the purpose of using it as a checksum that would be statistically guaranteed to be unique. There are several steps involved, but most of them are boilerplate and can be hidden away.
In the process of providing a couple of helper functions for streaming data into the hash object, I also fell down the rabbit hole of C++ concepts which make it trivial to implement very specifically which types can be used with various template functions. Those implementations are explained below as well. The test application makes various hashes to demonstrate the points in this article.
Background
For another article, I needed to create a mutex with a unique name in the Global namespace. This is easily done using a GUID. However, the usecase also required the use of the executable path to be considered.
Using the path itself might cause the name of the Mutex to be too long, and the '\' character cannot be used anyway. The best way forward was to create a hash of the GUID and the executable path that would statistically be guaranteed to be unique.
This started as 'I'm almost finished with my article, I'll just implement a hash function and I'm done' which then became 'the Win32 cryptographic support for hashing data is really neat, I should write an article about it as well' and went down the 'I'll make some templates that work only for a very specific subset of types' rabbit hole and ended with 'C++20 concepts are awesome'
Using the CNG API
The Cryptographic Next Generation (CNG) API is refreshingly easy to use. It's implemented in the BCrypt.dll. You use it as shown in the following diagram:
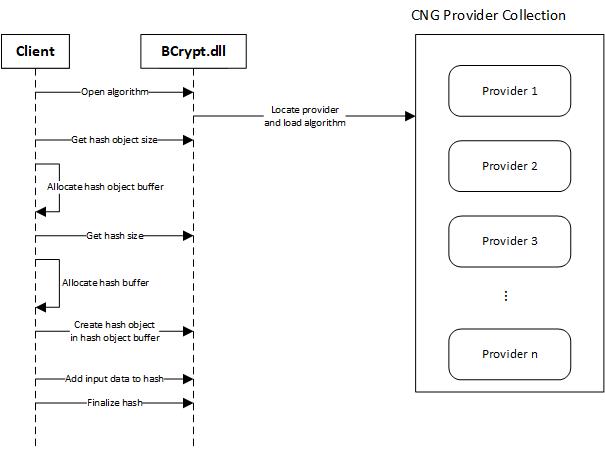
A client opens handle to a specific algorithm via BCrypt.dll, say BCRYPT_SHA256_ALGORITHM. If the client does not specify which provider to user, BCrypt will examine the collection of algorithm providers and picks the first one that supports the requested algorithm.
A hash algorithm requires two things: a buffer for storing the hash object itself (the state and configuration of that specific instance of the algorithm) and a buffer for the hash output. The size of both buffers can be retrieved from the algorithm that was loaded by BCrypt.
With these things configured, the client can supply input data which will be hashed according to the configured algorithm. Data doesn't have to be supplied in 1 go, it is possible to repeatedly add more data. This will be useful later on. And finally, the client signals that the hash can be finalized. That's it! The hash is already stored in the previously allocated buffer, ready to be used.
Implementing the Wrapper Class
The code for the wrapper class is implemented in w32_CHashObject.
class w32_CHashObject
{
private:
BCRYPT_ALG_HANDLE m_hAlg = NULL; BCRYPT_HASH_HANDLE m_hHash = NULL; NTSTATUS m_status = STATUS_UNSUCCESSFUL; DWORD m_sizeofHashObject = 0; DWORD m_sizeofHash = 0; PBYTE m_pbHashObject = NULL; PBYTE m_pbHash = NULL;
public:
w32_CHashObject(
LPCWSTR algorithmProvider = NULL,
LPCWSTR algorithmID = BCRYPT_SHA256_ALGORITHM,
PUCHAR secret = NULL,
ULONG sizeofSecret = 0);
~w32_CHashObject();
LSTATUS GetStatus(void); LSTATUS AddData(PBYTE data, ULONG numBytes); LSTATUS Finish(void);
DWORD GetHashSize(void); LSTATUS GetHash(PBYTE buffer, ULONG bufferSize); };
The use of the BCrypt hash algorithms require two handles (the algorithm and the hash object) and two buffers (the hash object and the hash) with each a buffer and a size variable. The internal status of the wrapper is the NTSTATUS value that is returned by the various API calls.
I made the decision that once the return value of one of the API calls indicates an error, this becomes the error state of the wrapper. Once something went awry, the wrapper becomes useless. The reason is that we can never be 100% sure that we fully understand the impact of that error. And if we start to mess around trying to resolve it, we cannot be certain of the impact on the has value. Using a bad / unreliable value is a very bad idea. This status can always be examined via GetStatus().
The remaining three functions are simply for adding input data to the hash object, finishing the hash operation, and retrieving a copy of the hash.
Construction and Destruction
This part requires most of the code.
w32_CHashObject::w32_CHashObject(
LPCWSTR algorithmProvider,
LPCWSTR algorithmID,
PUCHAR secret,
ULONG sizeofSecret) {
DWORD cbData = 0;
if (!NT_SUCCESS(m_status = BCryptOpenAlgorithmProvider(
&m_hAlg, algorithmID, algorithmProvider, 0))) {
return;
}
if (!NT_SUCCESS(m_status = BCryptGetProperty(
m_hAlg, BCRYPT_OBJECT_LENGTH,
(PBYTE)&m_sizeofHashObject,sizeof(DWORD), &cbData, 0))) {
return;
}
m_pbHashObject = (PBYTE)HeapAlloc(GetProcessHeap(), 0, m_sizeofHashObject);
if (NULL == m_pbHashObject) {
m_status = STATUS_NO_MEMORY;
return;
}
if (!NT_SUCCESS(m_status = BCryptGetProperty(
m_hAlg, BCRYPT_HASH_LENGTH,
(PBYTE)&m_sizeofHash, sizeof(DWORD), &cbData, 0))) {
return;
}
m_pbHash = (PBYTE)HeapAlloc(GetProcessHeap(), 0, m_sizeofHash);
if (NULL == m_pbHash) {
m_status = STATUS_NO_MEMORY;
return;
}
if ((secret != NULL && sizeofSecret == 0) ||
(secret == NULL && sizeofSecret != 0)) {
m_status = STATUS_INVALID_PARAMETER;
return;
}
if (!NT_SUCCESS(m_status = BCryptCreateHash(
m_hAlg, &m_hHash, m_pbHashObject, m_sizeofHashObject, secret, sizeofSecret, 0)))
return;
}
w32_CHashObject::~w32_CHashObject() {
if(m_hAlg != NULL)
BCryptCloseAlgorithmProvider(m_hAlg, 0);
if(m_hHash != NULL)
BCryptDestroyHash(m_hHash);
if (m_pbHashObject)
HeapFree(GetProcessHeap(), 0, m_pbHashObject);
if (m_pbHash)
HeapFree(GetProcessHeap(), 0, m_pbHash);
}
The first step is to ask BCrypt to load the request algorithm via BCryptOpenAlgorithmProvider, and then use the BCryptGetProperty function to retrieve the required sizes of the buffers. From the declaration, you can see that we allow the provider name to be empty, as well as the algorithm. Any provider will do unless you have a specific reason to ask for a specific one. If it doesn't really matter which hash algorithm is used either, I use BCRYPT_SHA256_ALGORITHM as a safe enough default value.
The hash operation is started by calling BCryptCreateHash. At first, it may seem strange that we can also leave the secret key empty. However, there are plenty of scenarios where we only require the hash as a fancy checksum for data integrity reasons instead of security / signing reasons. In that case, we not only do not have need for a secure key, but not using one allows third parties to verify the check.
Destruction is simply a matter of releasing the objects that were created in a constructor.
Calculating the Hash Value
Adding data to the hash is trivial because for the hash object, it's just an input buffer with a given size:
LSTATUS w32_CHashObject::AddData(PBYTE data, ULONG dataSize) {
if (!NT_SUCCESS(m_status))
return m_status;
if (dataSize <= 0)
return m_status;
m_status = BCryptHashData(m_hHash, data, dataSize, 0);
return m_status;
}
LSTATUS w32_CHashObject::Finish(void) {
if (!NT_SUCCESS(m_status))
return m_status;
m_status = BCryptFinishHash(
m_hHash, m_pbHash, m_sizeofHash, 0);
return m_status;
}
As you can see, we use the status as a sentinel. Once it's bad, it stays bad. When all data has been hashed, we have to finish the hash. Once we've done that, data can no longer be added
Calculating the Hash Value
Technically, we could expose the internal hash buffer to the outside for the purpose of getting the final hash, but I prefer to keep everything inside if it's touched by BCrypt.dll. Instead, we simply use two functions for getting the data out. The size of a hash is tiny anyway so the overhead of copying the data one more time is negligible.
DWORD w32_CHashObject::GetHashSize(void) {
return m_sizeofHash;
}
LSTATUS w32_CHashObject::GetHash(PBYTE buffer, ULONG bufferSize) {
if (!NT_SUCCESS(m_status))
return m_status;
if (bufferSize >= m_sizeofHash) {
memcpy_s(buffer, bufferSize, m_pbHash, m_sizeofHash);
return NO_ERROR;
}
else {
return STATUS_INVALID_PARAMETER;
}
}
Template Helper Functions
Adding input to the hash function is done via a BYTE buffer of a given length. However, that's not really convenient in most cases. Depending on your use case, you may need to add a double, a bool, a DWORD, ... and doing all those conversions manually in your code is tedious and errorprone. Thankfully, C++ has the possibility to work with template functions. I assume most people reading this article have some notion of template programming.
For those who are new to template programing, it's a method of programming a function that acts on a variable of a given type, but you only supply the actual type at compile time. The compiler will then take the generic template function, and create a version for each datatype for which you use said function.
In our case, the template function looks like this:
template<class T>
LSTATUS AddDataToHash(w32_CHashObject& hash, const T& data) {
return hash.AddData((PBYTE) & data, sizeof(T));
}
Without caring about the actual type just yet, we call the AddData method with the memory address of the data variable as buffer pointer, and the size of the data variable as the number of bytes. This function works well for any discrete type because the compiler has all the information it needs at compile time. If the code does this:
AddDataToHash(hashObject, double(1.23));
Then the compiler will create a version of that function that looks like this (pseudo code, not actual compiler code).
STATUS AddDataToHash<double>(w32_CHashObject& hash, const double& data) {
return hash.AddData((PBYTE) & double, sizeof(double));
}
No matter how many datatypes you use, the compiler will create them as needed, and you only need to provide a single implementation. That said, C++ also allows us to define certain of those specializations ourselves in cases where a certain datatype needs to be handled in a specific manner.
The two specializations that I am needing for my own purposes involve string and wstring objects. Obviously, it would be meaningless to take a pointer to a string object, and use the size of the string object. Given that the string object uses dynamic buffers internally, a memory snapshot of the string object would be meaningless. We want our template function to act on the data of the string itself.
template<>
LSTATUS AddDataToHash<string>(w32_CHashObject& hash, const string& data);
template<>
LSTATUS AddDataToHash<string>(w32_CHashObject& hash, const string& data) {
if (data.size() <= 0)
return hash.GetStatus();
PUCHAR input = (PUCHAR)(data.c_str());
ULONG numBytes = (ULONG)(data.length() * sizeof(data[0]));
return hash.AddData(input, numBytes);
}
The string class conveniently has a method for getting a buffer pointer to the data that it represents, and we can use that buffer to feed the data into our hash object.
There is one more case that warrants special attention. In many cases, we already have a buffer that we can stream into the hash object. While it is possible to call the AddData method directly, I have provided a template function as well for the sake of consistency.
template<class T>
LSTATUS AddDataToHash(w32_CHashObject& hash, T* data, ULONG numBytes) {
return hash.AddData((PBYTE) data, numBytes);
}
Every use of a buffer should involve the buffer size as well. The second one is the only one that should be used when a buffer pointer is supplied
Using the CHashObject Class
For the purpose of demonstrating, let's start with hashing the wstring L"Test123". We can do this in several ways:
{
cout << "Hashing Test123 as wstring." << endl;
w32_CHashObject hashObject;
AddDataToHash(hashObject, wstring(L"Test123"));
hashObject.Finish();
PrintHash(hashObject);
}
{
cout << "Hashing Test123 as individual unicode characters" << endl;
w32_CHashObject hashObject;
AddDataToHash(hashObject, L'T');
AddDataToHash(hashObject, L'e');
AddDataToHash(hashObject, L's');
AddDataToHash(hashObject, L't');
AddDataToHash(hashObject, L'1');
AddDataToHash(hashObject, L'2');
AddDataToHash(hashObject, L'3');
hashObject.Finish();
PrintHash(hashObject);
}
In all both cases, the result is 5952584f93d2b9ec353dadfff6e2796671f4c62bafc8cf0a83f7ff5a0e7c9e4.
We can also hash a bunch of different datatypes one after another.
{
cout << "Hashing double (1.23), int (42), bool(true)" << endl;
w32_CHashObject hashObject;
AddDataToHash(hashObject, double(1.23));
AddDataToHash(hashObject, int(42));
AddDataToHash(hashObject, bool(true));
hashObject.Finish();
PrintHash(hashObject);
}
This combination of data produces the hash 8de7143fc6ddbf2cecc904c88119f55d12b4293cda5ef7afaddcff16944efd.
Some Caveats
There are several caveats when hashing data which you need to watch out for.
0 Termination
Earlier when we hashed the text L"Test123" as a wstring and as individual characters. So what happens if we hash it as a C style string?
{
cout << "Hashing Test123 as wchar_t*" << endl;
w32_CHashObject hashObject;
wchar_t arr[] = L"Test123";
int arrbytes = sizeof(arr);
AddDataToHash(hashObject, arr, arrbytes);
hashObject.Finish();
PrintHash(hashObject);
}
The hash is not 8de7143fc6ddbf2cecc904c88119f55d12b4293cda5ef7afaddcff16944efd but 4359ed1fea1128f56778cb2a68fe64eb39fc79b90b5a34ac7edc8de3d93fe25.
Upon investigation, we find that sizeof(arr) == 16. The reason is that a C style string has a 0 termination at the end which is accounted for in the buffer itself and therefore 2 more bytes are hashed than in the earlier examples. If we want to make it equivalent, we have to make sure we hash only the data and not the termination.
{
cout << "Hashing Test123 as wchar_t* including 0 termination" << endl;
w32_CHashObject hashObject;
wchar_t arr[] = L"Test123";
int arrbytes = sizeof(arr) - sizeof(whcar_t);
AddDataToHash(hashObject, arr, arrbytes);
hashObject.Finish();
PrintHash(hashObject);
}
This creates the hash 8de7143fc6ddbf2cecc904c88119f55d12b4293cda5ef7afaddcff16944efd. So keep in mind when you are hashing data: if you rely on the output to be repeatable, you have to know exactly what you are hashing and how you provide the input. Things like including the 0 termination or not may not spring to mind immediately but are critically important if the specific result of the hash matters.
Structure Padding
Let's take the earlier example where we hashed a double, an int and a bool, put the same variables into a struct and repeat this exercise. Then we get this situation:
struct TestStruct1 {
double d;
int i;
bool b;
};
{
cout << "Hashing TestStruct1 d = 1.23, i = 42, b = true" << endl;
w32_CHashObject hashObject;
TestStruct1 ts1;
ts1.d = 1.23;
ts1.i = 42;
ts1.b = true;
AddDataToHash(hashObject, ts1);
hashObject.Finish();
PrintHash(hashObject);
}
At first glance, you might think this is going to be a repeat of the previous hash. Instead, it results in 17b345a6bc1f28b9b3a3f57d6a6bb934a1704ebe6b95128cdd339ef6a92316.
The reason is that we hashed more data. If we look at the size of the individual members (8 + 4 + 1), you'd expect that TestStruct1 is 13 bytes big whereas in reality sizeof(ts1) equates to 16. There are 3 bytes of padding. The reason is that the compiler wants to align each variable on a memory boundary that is a multiple of the size of that member. It is much faster for the CPU to access, e.g., a 4 byte integer that is placed at an address that is a multiple of 4. A double is places at an 8 byte boundary. So what happens if we reorder the members?
struct TestStruct2 {
bool b;
double d;
int i;
};
This structure has a size of 24. There 7 bytes of padding between b and d. So you might expect 1 + 7 + 8 + 4 = 20. But if we create an array of these structures, then arr[1].b would be placed at offset 20, and arr[1].d would be placed at offset 28. 28 is not an aligned memory address for a double so performance goes down the drain. Instead, the compiler adds 4 more bytes at the end of the structure so that every member in an array becomes aligned.
Whether those padding bytes are zeroed or not depends on the compiler so you cannot even assume that a struct with the same member values will hash to the same value unless:
- you know the compiler explicitly zeroes structs or
- you zero them yourself.
Additionally, the compiler may be instructed via compiler options or a pragma to change alignment and packing behavior to eliminate or reduce padding, at the cost of performance or even hardware exceptions on certain CPU architectures. So that is something to keep in mind as well. You cannot assume the padding behaviour unless it was explicitly defined.
Endinanness
Even after considering data formats, termination, and hidden padding, there is still an issue that may trip you up: endianness. If you are unfamiliar with endianness, you can find a good explanation here. In short, variables that are more than 1 byte big can be placed in physical in many different ways.
The two most common ways are little endian (least significant byte first) or big endian (most significant byte first). There are other, more exotic variations but those two are the main ones. In general, you never need to worry about them except for situations where
- your data is accessed by other processors such as a chip on a PCI board, or
- your data is otherwise used on a byte-by-byte basis.
If our program performs a hash of TestStruct1 on an Intel CPU, then even if we account for padding initialization or alignment, that same operation may yield different results on an Apple computer with an older Motorola CPU for example.
This is generally not an issue you need to worry about if you work on a given platform and stay there but if your use case involves other CPU architectures, you may need to account for these differences as well in your code.
A Better Template Implementation
We've already seen that supplying a struct or class as input can have unpredictable results that depend on compiler options. And we can also predict that passing a pointer to the AddHashData function will not do what we expect. The value of the pointer itself would be hashed which is meaningless. We could make a template specialization of overload for pointer types but that would be equally meaningless because:
- it would still not fix the issues with padding, and
- it would not help with arrays of things.
So when we get down to it, we have two main requirements for the template functions:
- The
AddHashData should only accept arithmetic parameters (int, float, bool, double, ...) which have a fixed size and which can be copied from memory, OR - which derive from a base class that has an interface that can provide a buffer with a known and predictable layout.
In the past, these restrictions could be implemented via Template Meta programming and SNIFAE which can get very complex very quickly, and which creates horrible compiler errors if you'd try to use the wrong type. But in C++20, this can be implemented via a new language feature known as concepts, which make the resulting templates much easier to understand, and create very clean compiler errors.
Arithmetic Parameter Support
This is the easiest option to implement.
template<typename T>
concept HashableType = is_arithmetic<T>::value && not is_pointer<T>::value;
template<HashableType T>
LSTATUS AddDataToHash(w32_CHashObject& hash, const T& data) {
return hash.AddData((PBYTE)&data, sizeof(T));
}
template<HashableType T>
LSTATUS AddDataToHash(w32_CHashObject& hash, T* data, ULONG numBytes) {
return hash.AddData((PBYTE)data, numBytes);
}
We implement a concept 'HashableType' which is defined as any type which is an arithmetic type and which is not a pointer. That concept can then be used as a type identifier in a template function. The template will then only accept types for which the concept evaluates as true. And if we try to use the function with a type for which it equates to false, we get a clean and simple compiler error 'C7602 the associated constraints are not satisfied' or 'C2672 no matching overloaded function found'.
double d = 1.23;
double *p = &d;
AddDataToHash(hashObject, d); AddDataToHash(hashObject, p);
This template will also not accept structs or classes so we don't risk unexpected behavior.
Support for Hashable Classes / Structs
This requires a bit more work because we need to have a sensible base class.
class w32_CHashDataProviderIF {
virtual PBYTE Buffer() = 0;
virtual ULONG Size() = 0;
};
template<typename T>
concept HashableClass = derived_from<T, w32_CHashDataProviderIF>;
template<HashableClass T>
LSTATUS AddDataToHash(w32_CHashObject& hash, T& data) {
return hash.AddData(data.Buffer(), data.Size());
}
template<HashableClass T>
LSTATUS AddDataToHash(w32_CHashObject& hash, T* data) {
return hash.AddData(data->Buffer(), data->Size());
}
We implement a concept HashableClass which is defined as any type which derives from w32_CHashDataProviderIF. What used to be very complex to implement is now made trivial via concepts. Class can now be implemented to derive from that bas class, and the AddDataToHash function will then call those methods. It is up to the class implementor to then define exactly how the class memberdata is streamed into the hash.
I've provided a default base class which does some memory management and which can be used as a base class for simple derived classes. I won't go into the implementation because it's trivial and boring, but for the sake of this argument, I've created test class that represents the three structure we used earlier with the a double, int and bool data member.
class TestClass3 : public w32_CHashDataProvider {
public:
double d;
int i;
bool b;
PBYTE Buffer() {
Allocate(Size());
PBYTE buffer = m_Buffer; *(double*)buffer = d;
buffer += sizeof(double); *(int*)buffer = i;
buffer += sizeof(int); *(bool*)buffer = b;
return m_Buffer;
}
ULONG Size() {
return sizeof(double) + sizeof(int) + sizeof(bool);
}
};
It should come as no surprise that if we are going to manually manage a buffer and determine where in the buffer the data is written, we use some pointer arithmetic for the offsets. This way, we don't run into things like padding or alignment.
If we now run this code:
{
cout << "Hashing TestClass3 d = 1.23, i = 42, b = true" << endl;
w32_CHashObject hashObject;
TestClass3 tc3;
tc3.d = 1.23;
tc3.i = 42;
tc3.b = true;
AddDataToHash(hashObject, tc3);
hashObject.Finish();
PrintHash(hashObject);
}
We get the hash output of 8de7143fc6ddbf2cecc904c88119f55d12b4293cda5ef7afaddcff16944efd which is identical to what we got when hashing the individual data values separately.
Points of Interest
That's it! We now have a nice way to hash data in a reliable and predictable manner, using templates and the Win32 API. Note that my project has C++20 support enabled for the concepts. It will compile without that support, but you won't have those nice template functions to play with. I briefly considered including my original template functions, but that would mean allowing the use cases where unexpected behaviour may occur and I didn't want that.
The test application is included as well as the source code. Everything is licensed under the MIT license.

History
- 26th August, 2022: V1 - First version of this article
I am a former professional software developer (now a system admin) with an interest in everything that is about making hardware work. In the course of my work, I have programmed device drivers and services on Windows and linux.
I have written firmware for embedded devices in C and assembly language, and have designed and implemented real-time applications for testing of satellite payload equipment.
Generally, finding out how to interface hardware with software is my hobby and job.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





