In this article, we will show additional optimizations, examples of use and testing of a thread-safe pointer developed with an optimized shared mutex contfree_safe_ptr. At the end, we will show the comparative graphs of our thread-safe-pointer tests and some of the best lock-free algorithms from libCDS on Intel Core i5 / i7, Xeon, 2 x Xeon processors.
Three related articles:
- We make any object thread-safe
- We make a std::shared_mutex 10 times faster
- Thread-safe
std::map with the speed of lock-free map
Introduction
Examples of Use and Testing of a Thread-Safe Pointer and Contention-Free Shared-Mutex
In this article, we will show additional optimizations, examples of use and testing of a thread-safe pointer developed by us with an optimized shared mutex contfree_safe_ptr<T> - this is equivalent to safe_ptr<T, contention_free_shared_mutex<>>.
In the end, we will show the comparative graphs of our thread-safe-pointer tests and some of the best lock-free algorithms from libCDS on Intel Core i5 / i7, Xeon, 2 x Xeon processors.
You can find libCDS using the link: https://github.com/khizmax/libcds.
In all benchmarks in this article used this commit of libCDS https://github.com/khizmax/libcds/tree/5e2a9854b0a8625183818eb8ad91e5511fed5898.
Background
Different Granularity of Locks
First, we’ll show how you can optimally use shared-mutex, by the example of work with a table (array of structures). Let’s get down to the experience of industrial RDBMS. For example, MSSQL RDBMS use locks of different granularity: locking of one or more rows, a page, an extent, one section of a table, an index, the whole table, the entire database. Lock Granularity and Hierarchies
Indeed, if we work with one row for a long time and it is important for us to have the row not changed by another thread at that time, then it is not necessary to lock the whole table all the time - it is enough just to lock 1 row.
- Lock the whole table with a shared lock
- Look for the desired row or several rows
- Then lock the found row
- Unlock the table
- And work with the locked row
Then other threads can work in parallel with the rest of the rows.
So far, we have used only a lock at the table level, i.e., we locked one or more tables.
Or all the tables used in the expression were automatically locked, until it was fully completed.
(*safe_map_1)["apple"].first = "fruit";
safe_map_1->at("apple").second =
safe_map_1->at("apple").second * 2;
safe_map_1->at("apple").second =
safe_map_2->at("apple").second*2;
In other cases, we manually locked one or more tables by using the RAII lock objects until the block scope of these locks expired (until they were destroyed):
{
std::lock_guard< decltype(safe_map_1) > lock(safe_map_1);
(*safe_map_1)["apple"].first = "fruit";
safe_map_1->at("apple").second =
safe_map_1->at("apple").second * 2;
}
{
lock_timed_any_infinity lock_all(safe_map_1, safe_map_2);
safe_map_1->at("apple").second =
safe_map_2->at("apple").second*2;
safe_map_1->at("potato").second =
safe_map_2->at("potato").second*2;
}
Let's consider an example, in which we randomly select an index for insertion, then we randomly select one of the four operations (insert, delete, update, read) and execute it in relation to a thread-safe object with the contfree_safe_ptr<std::map> type.
Example: [37] http://coliru.stacked-crooked.com/a/5b68b65bf2c5abeb
In this case, we will make the following locks in relation to the table:
Insert - eXclusive lockDelete - eXclusive lockUpdate - eXclusive lockRead - Shared lock
For Update or Read operations, we do the following:
- Lock the whole table (
xlock for Update, slock for Read) - Search for the necessary row, read or change it
- Unlock the table
The code of one iteration in our example-1:
int const rnd_index = index_distribution(generator); int const num_op = operation_distribution(generator);
switch (num_op) {
case insert_op: {
safe_map->emplace(rnd_index,(field_t(rnd_index, rnd_index))); }
break;
case delete_op: {
size_t erased_elements = safe_map->erase(rnd_index); }
break;
case update_op: {
auto x_safe_map = xlock_safe_ptr(safe_map); auto it = x_safe_map->find(rnd_index);
if (it != x_safe_map->cend()) {
it->second.money += rnd_index; }
}
break;
case read_op: {
auto s_safe_map = slock_safe_ptr(safe_map); auto it = s_safe_map->find(rnd_index);
if (it != s_safe_map->cend()) {
volatile int money = it->second.money; }
}
break;
default: std::cout << "\n wrong way! \n"; break;
}
Now we will make the actions that provide locking of the table during the Update operation by means of a read lock (shared), but not by locking the change (exclusive). This will greatly speed up the Update operations upon using our “write contention free shared mutex”, which we have developed earlier.
In this case, multiple threads can simultaneously perform Update and Read operations in relation to one table. For example, one thread reads one row, and the other thread changes another row. But if one thread tries to change the same row that is being read by another thread, then, to avoid Data-races, we have to lock the row itself upon reading and changing it.
Example: [38] http://coliru.stacked-crooked.com/a/89f5ebd2d96296d3
Now for Update or Read operations, we do the following:
- Lock the whole table with a shared lock
- Look for the desired row or several row
- Then lock the found row (
xlock for Update, slock for Read) - And work with the locked row (X / S-lock) and the locked table (S-lock)
- Unlock the row
- Unlock the table
Diff (that we have changed):
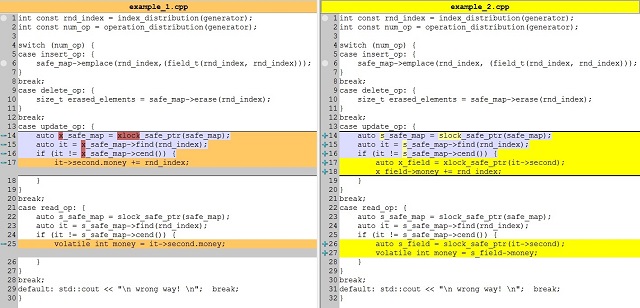
The code of one iteration in our example-2:
int const rnd_index = index_distribution(generator); int const num_op = operation_distribution(generator);
switch (num_op) {
case insert_op: {
safe_map->emplace(rnd_index, (field_t(rnd_index, rnd_index))); }
break;
case delete_op: {
size_t erased_elements = safe_map->erase(rnd_index); }
break;
case update_op: {
auto s_safe_map = slock_safe_ptr(safe_map); auto it = s_safe_map->find(rnd_index);
if (it != s_safe_map->cend()) {
auto x_field = xlock_safe_ptr(it->second);
x_field->money += rnd_index; }
}
break;
case read_op: {
auto s_safe_map = slock_safe_ptr(safe_map); auto it = s_safe_map->find(rnd_index);
if (it != s_safe_map->cend()) {
auto s_field = slock_safe_ptr(it->second);
volatile int money = s_field->money; }
}
break;
default: std::cout << "\n wrong way! \n"; break;
}
Here, for thread-safe work with the row, we used safe_obj. Inside safe_obj<T>, there is an object of T type, but not a pointer to it as in safe_ptr<T>. Therefore, when using safe_obj, you do not need to allocate memory separately for the object itself and change the atomic reference count, as it is required in safe_ptr. Therefore, the Insert and Delete operations are much faster with safe_obj than with safe_ptr.
It is worth noting that during copying safe_obj, it is not the pointer that is copied to the object, but it is the object itself being copied. There, the source and the final safe_obj is pre-locked.
Note: Strictly speaking, we do not lock the whole row, but we lock all the fields of the row, except for the index of the row, by using which we perform searching. So, we called our object as “field”, but not as “row”. And also, to emphasize that in this way we can lock not only one row, but even individual fields in one row, if we place them in separate safe_obj-objects. This would allow different threads to lock different fields and work with them in parallel.
Now we use the following locks for different operations:

This example is very fast for a large number of short-term operations. But we still hold the read lock (shared) on the table while changing or reading the row (field). And if we have rare, but very long operations on the rows of the table, then the lock on the whole table will be kept for all this long time.
However, if in terms of the logic of your task, it does not matter that a row can be deleted by one thread, while another thread reads or changes the same row, then it’s enough to lock the table only for the time of searching the row. And to avoid accessing the freed memory (when another thread deleted the row), we need to use std::shared_ptr<T> - the pointer with an atomic thread-safe reference count. In this case, the memory will be freed only when no threads have pointers to this row.
Instead of safe_obj, we will use safe_ptr to protect the row. This will allow us to copy the pointer to the row and use a thread-safe reference count in std::shared_ptr<T> that is contained in safe_ptr.
Example: [39] http://coliru.stacked-crooked.com/a/f2a051abfbfd2716
Now, for Update or Read operations, we do the following:
- Lock the whole table with a shared lock
- Look for the desired row or several rows
- Then lock the found row (
xlock for Update, slock for Read) - Unlock the table
- And work with the locked row (X / S-lock) for as long as required
- Unlock the row
Diff (that we have changed):
Example-3:
int const rnd_index = index_distribution(generator); int const num_op = operation_distribution(generator); safe_ptr_field_t safe_nullptr;
switch (num_op) {
case insert_op: {
safe_map->emplace(rnd_index, (field_t(rnd_index, rnd_index))); }
break;
case delete_op: {
size_t erased_elements = safe_map->erase(rnd_index); }
break;
case update_op: {
auto pair_result = [&]() {
auto s_safe_map = slock_safe_ptr(safe_map); auto it = s_safe_map->find(rnd_index);
if (it != s_safe_map->cend()) return std::make_pair(it->second, true); else return std::make_pair(safe_nullptr, false); }();
if(pair_result.second) {
auto x_field = xlock_safe_ptr(pair_result.first); x_field->money += rnd_index; } }
break;
case read_op: {
auto pair_result = [&]() {
auto s_safe_map = slock_safe_ptr(safe_map); auto it = s_safe_map->find(rnd_index);
if (it != s_safe_map->cend()) return std::make_pair(it->second, true); else return std::make_pair(safe_nullptr, false); }();
if(pair_result.second) {
auto s_field = slock_safe_ptr(pair_result.first); volatile int money = s_field->money; } }
break;
default: std::cout << "\n wrong way! \n"; break;
}
Well-designed multithreaded programs use short calls to the shared objects. That is why in the future, we will use the penultimate example for short read operations, but not the last one.
Disadvantages of the Execute Around Idiom
Let’s consider possible problems and criticize our code.
In the previous chapter, we have considered a fairly convenient and high-performance example, explicitly specifying the type of locking for the Update and Read operations by using the functions:
slock_safe_ptr() - read-onlyxlock_safe_ptr() - for reading and changing
Here, the lock is held until the end of the lifetime of the lock_obj object returned by these functions: auto lock_obj = slock_safe_ptr (sf_p);
However, implicit locks were used for Insert and Delete operations. Our safe_ptr<std::map> object was automatically locked by using the Execute Around Pointer idiom and was unlocked immediately after termination of the Insert or Delete operation.
Example: [40] http://coliru.stacked-crooked.com/a/89f5ebd2d96296d3
But you can forget to use explicit locks in the Update or Read operations. In this case, safe_ptr<std::map> will be unlocked immediately after completion of search operation, and then you continue to use:
- the found iterator, which can be invalidated by another thread
- or a found element that can be deleted by another thread
To partially solve this problem, instead of safe_ptr<> and safe_obj<>, you can use safe_hide_ptr<> and safe_hide_obj<> - they do not use the Execute Around Pointer and you can access the class members only after explicit locking:
safe_hide_obj<field_t, spinlock_t=""> field_hide_tmp;
auto x_field = xlock_safe_ptr(field_hide_tmp); x_field->money = 10; </field_t,></field_t,>
Example: [41] http://coliru.stacked-crooked.com/a/d65deacecfe2636b
Earlier, you could make a mistake and write the following - an error code:
auto it = safe_map->find(rnd_index); if (it != s_safe_map->cend())
volatile int money = it->second ->money;
but now, such a request is not compiled and will require explicit locking of objects - the correct code:
auto s_safe_map = slock_safe_ptr(safe_map); auto it = s_safe_map->find(rnd_index);
if (it != s_safe_map->cend()) {
auto s_field = slock_safe_ptr(it->second);
volatile int money = s_field->money; }
However, you still have the danger of using locks as temporary objects - not correct:
auto it = slock_safe_ptr(safe_map)->find(rnd_index); if (it != s_safe_map->cend()) {
volatile int money = slock_safe_ptr(it->second)->money; }
You have a choice:
- To use
safe_ptr and safe_obj in order to be able to explicitly or automatically (Execute Around Idiom) lock your object - Or to use
safe_hide_ptr and safe_hide_obj, leaving only the ability to explicitly lock your object
It’s up to you what to choose:
- to use convenient automatic locking (Execute Around Idiom)
- or slightly to reduce the possibility of an error by explicitly locking an object
In addition, the following functions are planned to be included into C++17 standard for std::map<>:
insert_or_assign() - if there is an element, then assign; if not, then pastetry_emplace() - if there is no element, then create itmerge() - merge 2 map into 1extract() - get the element and remove it from map
Introduction of such functions allows performing frequently used compound operations without use of iterators - in this case, the use of Execute Around Idiom will always guarantee the thread-safety of these operations. In general, avoiding iterators for all containers (except arrays std::array and std::vector) is a great help in development of multithreaded programs. The less frequently you use iterators, the fewer chances there are for you to address an iterator invalidated by either thread.
But whatever you choose: to use Execute Around Idiom, to use explicit locks for safe_hide_ptr, to discard them and to use standard std::mutex locks ... or to write your own lock-free algorithms - you always have many opportunities to make an error.
Improve Performance by Partitioning the Table
Let's go back to the experience of industrial relational databases. For example, in RDBMS, table partitioning can be used to improve performance. In this case, instead of the whole table, you can only block the partition used: https://technet.microsoft.com/en-us/library/ms187504(v=sql.105).aspx
Although the whole table is not usually locked for the Delete and Insert operations in RDBMS (and this is always true for the Delete operations), but for the Insert operations, it is possible to perform very fast loading of data into a table, the mandatory condition of which is exclusive locking of the table:
- MS SQL
(dbcc traceon (610, -1)): INSERT INTO sales_hist WITH (TABLOCKX) - Oracle:
INSERT /*+ APPEND */ INTO sales_hist
https://docs.oracle.com/cd/E18283_01/server.112/e17120/tables004.htm#i1009887
Locking Considerations with Direct-Path INSERT
During direct-path INSERT, the database obtains exclusive locks on the table (or on all partitions of a partitioned table). As a result, users cannot perform any concurrent insert, update, or delete operations on the table, and concurrent index creation and build operations are not permitted. Concurrent queries, however, are supported, but the query will return only the information before the insert operation.
Because our task is to create the fastest multithreaded container, we also locked the container entirely in the Insert / Delete operations. But now let’s try to lock only part of our container.
Let’s try to realize our own partitioned ordered associative array partitioned_map and see how much the performance will increase. We will lock only the section, which is necessary at the moment.
According to the context, it is std::map< safe_ptr<std::map<>> >.
Here, the first std::map will be constant and will contain sections (sub-tables).
This will be a very simplified example, where the number of sections is specified in the constructor and does not change further.
Each of the sections is a thread-safe associative array safe_ptr<std::map<>>.
In order to provide the maximum performance, the number of sections and their ranges should be such that the probability of access to each section is the same. If you have a range of keys from 0 to 1000000, and the probability of the read/update/insert/delete calls to the beginning of the range is greater than to the end of the range, then the number of sections with a small key value should be greater, and their ranges should be smaller. For example, 3 sections: [0 - 100000], [100001 - 400000], [400001 - 1000000].
But in our examples, we will assume that the query keys have a uniform distribution.
The ranges of sections can be assigned in two ways:
safe_map_partitioned_t<std::string, int> safe_map { "a", "f", "k", "p", "u" };
// assign the sections limits
safe_map_partitioned_t<int, int> (0, 100000, 10000);
// assign the values limits 0 – 100000 and a step for each section 10000
If, when accessing the container, the key goes beyond the limits of the sections, the query will refer to the nearest section, i.e., the program will work correctly.
Example: [42] http://coliru.stacked-crooked.com/a/fc148b08eb4b0580
Also, for maximum performance, it is necessary to use the “contention-free shared-mutex” that we have earlier realized inside safe_ptr<>. By sense, this is: std::map<contfree_safe_ptr<std::map<>> >
Let's take the code from the previous example and add the contfree_safe_ptr code from the previous chapter.
Replace: safe_map_partitioned_t<std::string, std::pair<std::string, int>>
with: safe_map_partitioned_t<std::string, std::pair<std::string, int>,contfree_safe_ptr>
Example: [43] http://coliru.stacked-crooked.com/a/23a1f7a3982063a1
We created this safe_map_partitioned_t<> class “Just for fun”, i.e., it is not recommended to use it in real programs. We just showed an example of realization of your own algorithms based on the contfree_safe_ptr<> pointer and contention_free_shared_mutex<> lock.
Using the Code
How to Use
At first, you should download file - safe_ptr.h:
And include it to your cpp-file: #include "safe_ptr.h"
As optimal usage, we will stop at example-2 shown above - is simple and high-performance.
struct field_t {
int money, time;
field_t(int m, int t) : money(m), time(t) {}
field_t() : money(0), time(0) {}
};
typedef safe_obj<field_t, spinlock_t> safe_obj_field_t;
contfree_safe_ptr< std::map<int, safe_obj_field_t > > safe_map_contfree;
bool success_op;
switch (num_op) {
case insert_op:
slock_safe_ptr(test_map)->find(rnd_index); test_map->emplace(rnd_index, field_t(rnd_index, rnd_index));
break;
case delete_op:
slock_safe_ptr(test_map)->find(rnd_index); success_op = test_map->erase(rnd_index);
break;
case read_op: {
auto s_safe_map = slock_safe_ptr(test_map); auto it = s_safe_map->find(rnd_index);
if (it != s_safe_map->cend()) {
auto x_field = xlock_safe_ptr(it->second);
volatile int money = x_field->money; x_field->money += 10; }
}
break;
default: std::cout << "\n wrong way! \n"; break;
}
Insert and delete - modification of map: Because our shared-lock slock_safe_ptr() is the fastest, then before the modification (insert_op or delete_op), we are finding for the item that we need to delete or the nearest item to the insertion, using the fast shared-lock, which is unlocked immediately after the find(). We do not use the found item ourselves. But thus, this tells the CPU which data is desirable to cache in L1 for subsequent map modification. Then we do test_map->emplace() for insertion or test_map->erase() for deletion and it automatically calls an exclusive-lock. Insert/delete happens quickly, because all data is already cached in CPU-L1, and we do not need to upgrade the shared-lock to an exclusive-lock (this would greatly increase the likelihood of a deadlock - freezing program).
Read and update - reading or modification of item: What we call reading (read_op) is the change of one item in the map (one row of map). So before reading, we do shared-lock slock_safe_ptr() on the map, so that the other thread can not delete or replace this item. And holding the shared-lock while there is an object s_safe_map, then we impose an exclusive-lock xlock_safe_ptr() on only one found item, then read this item and change it. After that, when leaving the block scope {}, the x_field object is destroyed first and the exclusive-lock of item is removed, and the next object is destroyed s_safe_map and the shared-lock of map is removed.
Compiler allows you to do any operations on test_map - read and write and call to any methods of test_map - in this case, exclusive-lock is automatically applied.
But compiler allows you to only read an object and call only const methods of slock_safe_ptr(test_map) , for example slock_safe_ptr(test_map)->find();, but not slock_safe_ptr(test_map)->emplace();some_ptr (where auto const& some_ptr = test_map;) for example some_ptr->find() - in this case, shared-lock is automatically applied.
All of this and even more - detailed and strictly considered in the first article.
Comparison of the Performance of the Received safe_ptr Realizations
Let us summarize the intermediate results. Let's see the level of improvement of performance due to our optimizations.
Here are the performance graphs - the number of millions of operations per second (MOps), with a different percentage of modification operations 0 - 90%. During modifying, one of three operations will be performed with equal probability: insert, delete, update (although the Update operation does not change the std::map tree itself, but only changes one of its lines). For example, with 15% of modifications, the following operations are involved: 5% insert, 5% delete, 5% update, 85% read. Compiler: g ++ 4.9.2 (Linux Ubuntu) x86_64
To compile in compiler Clang++ 3.8.0 on Linux, you should change Makefile.
Here is an example of testing on 16 threads for a single server CPU Intel Xeon E5-2660 v3 2.6 GHz. First of all, we are interested in the orange line: safe<map, contfree>&rowlock
If you have several Xeon CPUs on the same motherboard, you can reproduce the result of this test by running it as follows:
numactl --localalloc --cpunodebind=0 ./benchmark 16
Performance on 16 threads, MOps - millions operations per second
Conclusion:
- As a matter of interest, our shared contfree-lock in
contfree_safe_ptr<map> works much faster than the standard std::shared_mutex in the safe_ptr <map, std :: shared_mutex> - It is also interesting that starting with 15% of the changes,
std::mutex is faster than std::shared_mutex (namely, safe_ptr<map, std::mutex> are faster than safe_ptr<map, std::shared_mutex>) - It is also curious that starting with 30% of changes, the performance of
std:map-1thread is higher than the performance of contfree_safe_ptr<map>&rowlock. But real tasks do not consist only of operations with an associative array and synchronization of threads. Usually, inter-thread data exchange is only a small part of the task, and the main part is well parallelized to multiple cores. - The partitioned associative array
safe_map_partitioned<,,contfree_safe_ptr> shows good performance, but it should be used only as “Just-for-fun” - if the required number of sections and their ranges are known in advance. - For 15% of modifications – our shared-mutex (as part of
«contfree_safe_ptr<map> & rowlock») shows performance 8.37 Mops, that is 10 times faster than standard std::shared_mutex (as part of «safe_ptr<map, std::shared_mutex>») that shows only 0.74 Mops.
Our lock «contention-free shared-mutex» works for any number of threads: for the first 70 threads as contention-free, and for the next threads as exclusive-lock. As can be seen from the graphs – even exclusive-lock «std::mutex» works faster than «std::shared_mutex» for 15% of modifications. The number of threads 70 for the contention-free-locks is specified by the template parameter, and can be changed.
Besides, we'll show the median-latency graph (in microseconds), i.e., half of the requests have latency less than this value.
In the test code main.cpp, you should to set: const bool measure_latency = true;
Median latency on 16 threads, microseconds
- It is interesting that
std::map & std::mutex ranges around safe_ptr<map, std::mutex>. That is to say that in general, using safe_ptr<> does not cause any additional overhead costs and does not reduce the performance. - Besides, it is interesting that beginning with 60% of changes,
contfree_safe_ptr<map>&rowlock shows more latency, than contfree_safe_ptr<map>. But from the previous graph, we learn that overall performance is still higher for contfree_safe_ptr<map>&rowlock for any percentage of modification operations.
Performance comparison of contfree_safe_ptr<std::map> and containers from CDS-lib on different desktop-CPU.
Performance comparison on different desktop-CPU by using all the cores.
Performance, MOps - millions operations per second
- It is interesting that for laptops and desktops,
contfree_safe_ptr<map> shows the highest performance among the lock-free-map containers from CDS-lib. - Our “Just-for-fun” version of the associative container with a constant number of sections
safe_map_partitioned<,,contfree_safe_ptr> shows an average performance gain of 1.7 times.
Performance comparison of contfree_safe_ptr<std::map> and containers from CDS-lib on the server-CPU.
Performance comparison of different multithread associative arrays on one server-CPU by using different number of threads.
To compile in compiler Clang++ 3.8.0 on Linux, you should change Makefile.
If you have several Xeon CPUs on the same motherboard, you can reproduce the result of this test by running it as follows:
numactl --localalloc --cpunodebind=0 ./benchmark 16
Performance on 1 - 16 threads, MOps - millions operations per second
- As you can see, if you use 16 or more parallel threads on one CPU, or if you use more than two CPUs, then the lock-free containers from CDS-lib show performance better than that of
contfree_safe_ptr<map>. That is to say, in case of strong competition, lock-free containers are better. But even if you have more than 16 threads, but no more than 8 threads access the container at a time, then contfree_safe_ptr<map> will be faster than lock-free containers. - Besides, the “Just-for-fun” container with a constant number of
safe_map_partitioned<,,contfree_safe_ptr> sections shows better performance for any number of threads, but it should be used only if the required number of sections and their ranges are known in advance.
Median latency is the time, in comparison with which 50% of queries were faster.
In the test code main.cpp, you should to set: const bool measure_latency = true;
Median latency on 1 - 16 threads, microseconds
Median latency for contfree_safe_ptr<map> is also almost equal to the latency of the lock-free containers with up to 8 simultaneously competing threads, but worse in case of 16 competing threads.
Real Applications Performance
Real applications do not consist only of data exchange between threads. The main work of real applications is performed in each thread separately and only occasionally, there is data exchange between the threads.
To simulate the real work of an application, we add a non-optimizable cycle for(volatile int i = 0; i <9000; ++ i); between each access to a thread-safe container. At the beginning of the test, we will perform this cycle for 100,000 times and measure the average execution time of this cycle. In the CPU Intel Xeon E5-2686 v4 2.3 GHz, this simulation of real work takes about 20.5 microseconds.
To compile in compiler Clang++ 3.8.0 on Linux, you should change Makefile.
We will perform test on a dual-processor server: 2 x Intel Xeon E5-2686 v4 2.3 GHz (Broadwell) with the total number of cores: 36 physical cores and 72 logical cores (Hyper Threading).
To build and test on Linux do:
cd libcds
make
cd ..
make
./benchmark
Performance on 1 - 64 threads, MOps - millions operations per second
- Usage of standard mutexes -
std::mutex and std::shared_mutex - for protection of std::map provides the performance close to that of the lock-free-map containers up to 16 threads. But later, the performance of std::mutex & std::map and std::shared_mutex & std::map begins to lag, and after 32 threads starts to reduce. - Usage of our optimized thread-safe pointer
contfree_safe_ptr<std::map<>> has a performance almost equal to the performance of the lock-free-map containers from the libCDS library (for any number of threads from 1 to 64). This is true provided that in real Applications, the exchange between threads occurs on average once every 20 microseconds or more rarely.
To measure median latency – in the test code main.cpp, you should to set:
const bool measure_latency = true;
And simply start benchmark on Linux: ./benchmark
Median latency on 1 - 64 threads, microseconds
- It is interesting that with 64 threads,
std::mutex has both higher performance and a greater median latency than std::shared_mutex - Our optimized thread-safe pointer
contfree_safe_ptr<std::map<>> has the same latency as the lock-free-map containers from libCDS for any number of threads from 1 to 64. This is also true provided that in real applications the exchange between the threads occurs every 20 microseconds or more rarely - For 64 threads, the latency is 30 usec, of which 20 usec is delay of application and 10 usec is multithreaded latency. So even if multithreaded latency is 30% of total latency, then our thread safe smart pointer
contfree_safe_ptr<T> has the same performance (MOps and median-latency) as lock-free map containers of libCDS
The simpler lock-free and wait-free containers (queue, stack ...) from libCDS have a noticeably less latency than their implementations on any locks.
Points of Interest
Issues Covered by These Articles
In these articles, we considered in detail the sequence of execution of C++ language constructions in one thread by using the Execute Around Pointer Idiom as an example. And we also considered the sequence of performing read and write operations in multithreaded programs by using the Contention-free shared-mutex as an example. And we gave examples of high-performance use of lock-free algorithms from libCDS and lock-based algorithms developed by us.
Result of our work - safe_ptr.h:
Conclusion
- If you have a strong competition of threads in relation to the same container (i.e., at a time, more than 8 threads access the container), then the best solution is to use containers from the libCDS library: https://github.com/khizmax/libcds
- If the libCDS has the thread-safe container, which you need, then use it.
- If your program executes something else, but not only exchanging the data between threads, and the exchange between the threads takes no more than 30% of the total time, then even if you use several tens of threads, our
contfree_safe_ptr<> pointer will be faster than map-containers from libCDS. - If you use your own container or your own data structure (which is not located in libCDS) for the data exchange between the threads, then
contfree_safe_ptr<T> will be a quick and easy solution. This is much easier than writing a lock-free realization of methods for work with your own data structure.
If you want to know how to build HPC systems of hundreds of CPUs, GPUs and FPGAs, then you can look at this article: http://www.alexeyab.com/2017/04/the-fastest-interconnect-for-hundreds.html.
Would you like to see the algorithms analyzed in this article in a modified form as part of the boost library?
History
- 24th April, 2017 - Initial version
- 1st May, 2017 - Added link to GitHub
The author of the YOLOv7/YOLOv4 - the best neural network for object detection.
I use modern C++ and modern CPU/GPU processors to solve tasks that require high performance, which can only be solved now.
I'm interested in HPC, Computer Vision and Deep Learning.
Preferably languages: C++11/14, CUDA C++, Python, SQL


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 




