Introduction
This is a sample project developed using this tiny HTML Parser library. Its main purpose is to show the use of that library. However I have added some additional features to the lib. The project has support for UNICODE builds. The code warps the HTML tags to a tree model, exposing a function to retrieve a specific HTML element.
An HTML element is an individual component of an HTML document or "web page", once this has been parsed into the Document Object Model.
In the HTML syntax, most elements are written with a start tag and an end tag, with the content in between. An HTML tag is composed of the name of the element, surrounded by angle brackets. An end tag also has a slash after the opening angle bracket, to distinguish it from the start tag.
<p>In the HTML syntax, most elements are written ...</p>
Between the starting/ending tags, any number of other tags may exist. This project offers a way to search for a specific tag, and also specify an attribute with a value for that tag. Then extract the content of that element. It's a cheap alternative to Microsoft's MSHTML parser (full of leaks).
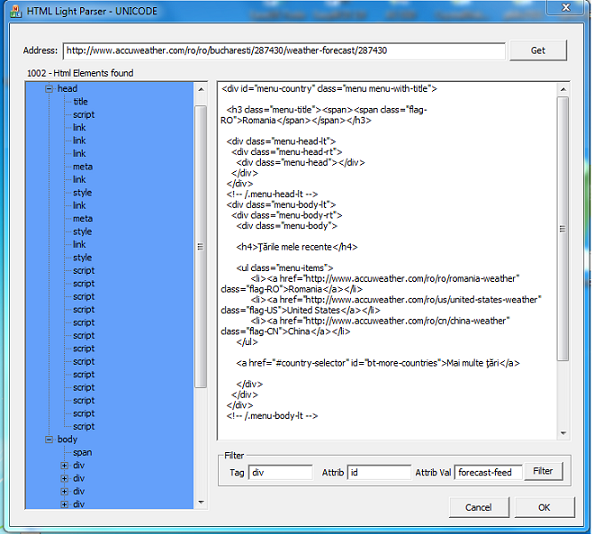
Using the Code
Add to your project the files form AClass directory.
Include some headers you may need like:
#include "AClass/LiteHTMLReader.h"
#include "AClass/HtmlElementCollection.h"
Instantiate the reader which will parse the HTML
string.
CLiteHTMLReader theReader;
CHtmlElementCollection theElementCollectionHandler;
theReader.setEventHandler(&theElementCollectionHandler);
If you want to get a specific set of tags with a specific attrib use:
theElementCollectionHandler.InitWantedTag(_T("style"), _T("id"),_T("sss"));
Call the parser function. At the end, the theElementCollectionHandler will be filled with the parsed structure.
theReader.Read(m_szHtmlPage)
Now start retrieving the elements' text to a CString var.
for (int i=0;i<theElementCollectionHandler.GetNumElementsFiltered();i++){
theElementCollectionHandler.GetOuterHtml(i, szTxt, 1);
}
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 






 i am looking at it as a learning project, i figured that i should just take some ideas from it, everything is nice except that tree structure!
i am looking at it as a learning project, i figured that i should just take some ideas from it, everything is nice except that tree structure!