For some applications, particularly those involving large-scale mathematics, a single computer won't provide adequate performance. In this case, you need a framework that makes it possible to run applications across multiple systems. You could look at cloud-based solutions like Amazon's Elastic Compute Cloud (EC2) or the Google Compute Engine, but if you want a free solution that you can install and configure yourself, I recommend the Message Passing Interface, or MPI.
MPI is a standard that defines C routines and tools for running applications across connected computers. The first version of the standard was released in 1994, and today, there are two main implementations: MPICH and OpenMPI. MPICH is older and more widely used, but I've read accounts claiming that OpenMPI is faster. Many corporations and universities have released derivatives of MPICH, including the following:
- MVAPICH - A free implementation of MPICH released under the BSD license
- Microsoft MPI - An implementation of MPICH designed for the Windows operating system
- Intel MPI - An Intel-specific implementation of MPICH targeting Intel processors
This article doesn't discuss the differences between MPI implementations. Instead, my goal is to explain the basics of MPICH programming and show how applications can be compiled and executed. In particular, this article focuses on the different methods of transferring data. But first, I'd like to present an analogy that compares an MPI application to a soccer game.
1. Analogy: MPI and Soccer
Despite a complete lack of coordination, I played soccer for many years. Before a match, the coach would assemble the team and discuss his plan. Most of the plan was non-specific: each player had to play a portion of the field and cover opposing players. Some instructions were position-specific: the forwards should take shots on goal and the goalie should prevent opposing players from scoring.
If the coach wrote his plan in pseudocode, it might look like the following:
if(position == COACH) {
present_game_plan();
keep_score();
}
else if(position == FORWARD) {
take_shots_on_goal();
}
else if(position == GOALIE) {
block_shots_on_goal();
}
else {
play_section_of_field(position);
cover_opposing_players();
}
Everyone on the team receives the same game plan, but they perform different roles according to their position. For regular players, the portion of the field they play depends on their position.
The purpose of MPI is to convert a set of networked computers into a united, functional unit similar to a soccer team. But MPI uses a different set of terms:
- The set of instructions is called an executable instead of a gameplan.
- The set of networked computers is called a communicator instead of a team.
- Each computer is called a processor instead of a player (or a coach).
- Each role performed by a processor is called a process instead of a position.
- Each process has a rank instead of a jersey number.
- Communication between processes is called message passing.
This analogy is fine at a high level, but it has (at least) four flaws:
- In a soccer game, each player can only have one position. In an MPI application, a processor can have multiple processes assigned to it.
- Soccer games don't permit sub-teams, but MPI applications can create communicators within the overall communicator.
- In a soccer game, coaches never play. In an MPI application, every process runs the executable.
- The number on a soccer jersey is essentially random. When MPI assigns ranks to processes, it starts at 0 and increments each successive rank by 1.
If you're still unclear on MPI's operation or terminology, don't be concerned. There are many helpful resources available, including a tutorial from Lawrence Livermore National Laboratory and a presentation from the Argonne National Laboratory.
2. A Simple Application
The MPI standard defines many functions and data structures, but four functions are particularly important:
MPI_Init(int *argc, char ***argv) - Receives command line arguments and initializes the execution environment (required)MPI_Comm_size(MPI_Comm comm, int *size) - Provides the number of processes in the communicator at the memory location identified by size. If the first argument is set to MPI_COMM_WORLD, it provides the total number of processes.MPI_Comm_rank(MPI_Comm comm, int *rank) - Provides the rank of the process executing the function at the memory location identified by rank. If the first argument is set to MPI_COMM_WORLD, it provides the rank of the process among all the processes.MPI_Finalize() - Halts MPI execution (required)
These functions, like all MPI functions, return an integer that represents the completion status. A function returns MPI_SUCCESS (0) if it completed successfully. If it returns a value greater than 0, it failed.
The code in hello_mpi.c shows how these four functions can be used in practice:
#include <stdio.h>
#include <mpi.h>
int main (int argc, char *argv[]) {
int rank, size;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
printf("This is process %d of %d\n", rank, size);
MPI_Finalize();
}
To compile a normal C application, you need to identify the locations of headers and libraries. But implementations of MPI provide an executable called mpicc (MPI C Compiler). This compiler knows where to find the MPI dependencies, so hello_mpi.c can be compiled with the following command:
mpicc -o hello_mpi hello_mpi.c
In addition to mpicc, the MPI standard defines a tool called mpiexec to launch MPI executables. mpiexec has two important flags:
n - the number of processes to generatehost - comma-separated list of hosts on which to run the executable
For example, the following command executes hello_mpi with two processes. This execution will be performed on the systems named castor and pollux.
mpiexec -n 2 -host castor,pollux hello_mpi
For this example, the following output will be printed:
This is process 0 of 2
This is process 1 of 2
When the executable runs, it's likely that one process will run on castor and the other will run on pollux. But different MPI implementations have different ways of assigning processes to hosts. As an example, OpenMPI uses a rank file to assign processes to processors.
Many implementations provide another tool for launching executables called mpirun. mpirun isn't defined by the MPI standard, so its usage depends on the implementation. For example, OpenMPI's mpirun has a loadbalance flag that uniformly distributes processes among the processors. Intel's mpirun has an iface flag that defines which network interface to use.
Note: Before an executable can be run across multiple systems, it must be copied to each system at the same location. If the executable relies on data/configuration files, the files must also be copied to the same locations on each system.
3. Point-to-Point Communication
In many MPI applications, one process distributes data to other processes and then collects the processed data. For example, the process with rank 0 might read an array of floats from a file and send the array to other processes (ranks > 0) for computation. When processing is finished, Process 0 collects the output floats and saves them to a file.
In MPI, the transfer of data from one process to another is called point-to-point communication. This works in two steps:
- The sending process calls
MPI_Send to express its intent to transfer data to a receiving process. - The receiving process calls
MPI_Recv to express its intent to receive data from a sending process.
The data transfer isn't finished until both functions complete their operations. The parameters of the two functions have a lot in common, as shown by their signatures:
int MPI_Send(const void* buff, int count, MPI_Datatype type, int dest, int tag, MPI_COMM comm)
int MPI_Recv(void* buff, int count, MPI_Datatype type, int source, int tag,
MPI_COMM comm, MPI_Status *status)
In each case, buff points to the data to be sent or the memory location where the received data should be stored. count and type specify the nature of the transferred data. That is, type identifies the primitive type of the transmitted data (MPI_FLOAT, MPI_DOUBLE, MPI_INT, MPI_UNSIGNED_SHORT, MPI_BYTE, and so on) and count identifies how many primitives should be transferred. For example, the following function sends 100 floats stored in float_array.
MPI_Send(float_array, 100, MPI_FLOAT, 3, 2, MPI_COMM_WORLD);
In this case, dest is set to 3 because the data is intended to be sent to the process whose rank is 3. The tag value serves as a unique identifier for the data transfer. If Process 3 wants to receive this data, it will set the tag to 3 in MPI_Recv, which is given as follows:
MPI_Recv(myfloats, 100, MPI_FLOAT, 3, 2, MPI_COMM_WORLD, &status);
The last argument points to an MPI_Status structure whose content is initialized by the function. This structure contains the sender's process number, the message's ID (tag), and the error code for the data transfer. If it's set to MPI_STATUS_IGNORE, the function won't provide the MPI_Status structure.
The code in p2p_example.c demonstrates how MPI_Send and MPI_Recv can be used. This application starts with Process 0 sending a float to every other process. The other processes add their rank to the float and send it back to Process 0, which collects the results into an array and prints its elements.
#include <stdio.h>
#include <stdlib.h>
#include "mpi.h"
#define INPUT_TAG 0
#define OUTPUT_TAG 1
int main(int argc, char **argv) {
int rank, size, i;
float* data;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
if(rank == 0) {
data = (float*)malloc((size-1) * sizeof(float));
for(i=1; i<size; i++) {
data[i-1] = 0.1 * i;
MPI_Send(&data[i-1], 1, MPI_FLOAT, i, INPUT_TAG, MPI_COMM_WORLD);
}
}
if(rank > 0) {
data = (float*)malloc(sizeof(float));
MPI_Recv(data, 1, MPI_FLOAT, 0, INPUT_TAG, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
data[0] += rank;
MPI_Send(data, 1, MPI_FLOAT, 0, OUTPUT_TAG, MPI_COMM_WORLD);
}
if(rank == 0) {
for(i=1; i<size; i++) {
MPI_Recv(&data[i-1], 1, MPI_FLOAT, i, OUTPUT_TAG, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
}
printf("Output: ");
for(i=1; i<size; i++) {
printf("%.1f ", data[i-1]);
}
printf("\n");
}
free(data);
MPI_Finalize();
return 0;
}
This application uses tags to distinguish transfers of data. When Process 0 distributes the input data, the transfer is identified with INPUT_TAG. When the other processes send the processed data, the transfer is identified with OUTPUT_TAG.
A drawback of using MPI_Send and MPI_Recv is that they force processes to wait for other processes. To make up for this, MPI provides alternative functions for point-to-point communication. For example, MPI_Isend and MPI_Irecv perform send/receive operations without halting either process. These functions are beyond the scope of this article, but you can read more about them here.
4. Collective Communication
In the preceding example, MPI_Send and MPI_Recv were called inside loops to transfer data between multiple processes. Communication involving multiple processes is called collective communication and MPI provides functions specifically for this purpose. Table 1 lists five of them and provides a description of each.
| Function Signature | Description |
| MPI_Bcast(void *buff, int count,
MPI_Datatype type, int root,
MPI_Comm comm)
| Transfers a chunk of data from one process to
every process in a communicator |
| MPI_Scatter(const void* src_buff,
int src_count, MPI_Datatype src_type,
void* dst_buff, int dst_count,
MPI_Datatype dst_type, int root,
MPI_Comm comm)
| Distributes successive chunks of data from one
process to every process in a communicator |
| MPI_Gather(const void* src_buff,
int src_count, MPI_Datatype src_type,
void* dst_buff, int dst_count,
MPI_Datatype dst_type, int root,
MPI_Comm comm)
| Collects chunks of data from multiple
processes into an array on one process |
| MPI_Allgather(const void src_buff,
int src_count, MPI_Datatype src_type,
void* dst_buff, int dst_count,
MPI_Datatype dst_type, MPI_Comm comm)
| Collects chunks of data from multiple
processes into an identical array on
every process |
| MPI_Alltoall(const void* src_buff,
int src_count, MPI_Datatype src_type,
void* dst_buff, int dst_count,
MPI_Datatype dst_type, MPI_Comm comm)
| Transfers data between multiple
processes in a transpose-like manner |
These functions not only simplify the source code, but usually perform better than loops of point-to-point transfers. This section discusses each of these five in detail.
4.1 Broadcast
Consider the following code:
if(rank == root) {
for(i=0; i<size; i++) {
MPI_Send(&data, 1, MPI_FLOAT, i, tag, MPI_COMM_WORLD);
}
}
MPI_Recv(&data, 1, MPI_FLOAT, root, tag, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
The for loop sends a float from one process to every process in the communicator. The call to MPI_Recv reads the float from the root process to each process (including root).
When one process transfers data to every process in the communicator, the operation is called a broadcast. This is performed by MPI_Bcast, the simplest of MPI's collective communication functions. For example, the following function call performs the same broadcast as the example code presented earlier.
MPI_Bcast(&data, 1, MPI_FLOAT, root, MPI_COMM_WORLD);
When you use MPI_Bcast, no calls to MPI_Recv are necessary. MPI_Bcast doesn't complete until all of the data has transferred from the root process to every process in the communicator. This explains why the function doesn't use a tag value to identify the transfer.
4.2 Scatter and Gather
A scatter operation is similar to a broadcast, but there are two important differences:
- A broadcast transfers the same data from the root to each process. A scatter divides the root's data into chunks and transfers different chunks to different processes according to their rank. The first chunk goes to Process 0, the second to Process 1, and so on.
- In a broadcast, the received data always has the same type, number, and memory reference as the sent data. For a scatter, these characteristics can be changed.
For example, suppose you want to transfer the first two ints of root's array to Process 0, the next two ints to Process 1, and so on. This can be accomplished with the following call to MPI_Scatter:
MPI_Scatter(input_array, 2, MPI_INT, output_array, 2, MPI_INT, root, MPI_COMM_WORLD);
The left side of Figure 1 clarifies how MPI_Scatter works by illustrating the preceding data transfer:
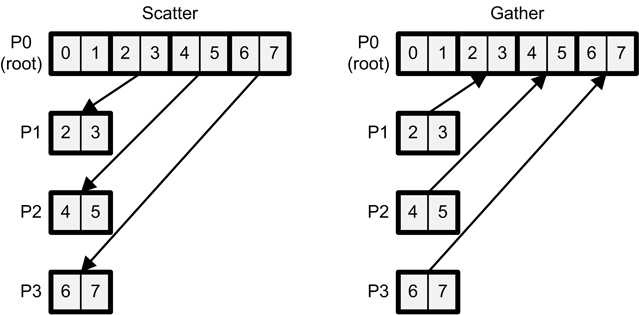
Figure 1: The MPI_Scatter and MPI_Gather Functions
As shown on the right side of the figure, a gather operation performs the inverse of a scatter operation. That is, instead of distributing chunks of data from one process to many, it combines chunks from multiple processes into an array on one process. As an example, the following function call collects three floats from each process into output_array on the root process:
MPI_Gather(input_array, 3, MPI_FLOAT, output_array, 3, MPI_FLOAT, root, MPI_COMM_WORLD);
As with MPI_Bcast, the receiving process or processes don't need to call MPI_Recv to complete the transfer. When MPI_Scatter or MPI_Gather complete, the data transfer has been accomplished.
4.3 AllGather
As discussed earlier, MPI_Gather collects chunks of data from multiple processes and transfers them to a single process as an array. The MPI_Allgather function performs a similar operation, but now the collected array is delivered to each process. In effect, MPI_Allgather performs multiple calls to MPI_Gather, using each process as root.
For example, the following code collects two ints from each process and combines them into an array. Then it delivers the array to every process in the communicator.
MPI_Allgather(input_array, 2, MPI_INT, output_array, 2, MPI_INT, MPI_COMM_WORLD);
It's important to note that each process receives an identical array containing the collected elements.
4.4 Alltoall
MPI_Alltoall accepts the same parameters as MPI_Allgather and performs a similar operation—it collects data from every process and transfers data to every process. But MPI_Alltoall doesn't transfer an identical array to each process. Instead, Process k receives the kth element from each process. That is, Process 0 receives an array containing each process's first element, Process 1 receives an array containing each process's second element, and so on.
If you think of Process k's data as the kth row of a matrix, then the operation performed by MPI_Alltoall is similar to a matrix transpose, also called a corner turn. Figure 2 shows what this looks like:

The a2a_example.c source file shows how MPI_Alltoall can be used in practice. Each process has an input array whose length equals the number of processes. The MPI_Alltoall function rearranges these values so that Process k receives the kth element from each process.
#include <stdio.h>
#include <stdlib.h>
#include "mpi.h"
int main(int argc, char **argv) {
int rank, size, i;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
int* input_array = (int*)malloc(size * sizeof(int));
int* output_array = (int*)malloc(size * sizeof(int));
for(i=0; i<size; i++) {
input_array[i] = rank * size + i;
}
MPI_Alltoall(input_array, 1, MPI_INT, output_array, 1, MPI_INT, MPI_COMM_WORLD);
printf("Process %d: ", rank);
for(i=0; i<size; i++) {
printf("%d ", output_array[i]);
}
printf("\n");
free(input_array);
free(output_array);
MPI_Finalize();
return 0;
}
In this code, the number of processes always equals the number of elements in each array. But this doesn't have to be the case. If the number of processes is greater than the array length, the extra processes' data will be set to zero.
5. Concluding Remarks
This article has discussed the basics of MPI coding and interprocess communication. But MPI provides many more capabilities than those discussed here. If you look through the list of functions, you'll see that MPI makes it possible to work with files, threads, windows, barriers and much more.
Using the Code
The code archive contains three files: hello_mpi.c, p2p_example.c, and a2a_example.c. After you've installed an implementation of MPI, you can compile them with mpicc, which works in much the same way as the popular GNU C Compiler (gcc). After an MPI executable is compiled and linked, you can launch it with mpiexec or mpirun.
History
I've been a programmer, engineer, and author for over 20 years.





