Introduction
I would like to present a concept & implementation about lock-free, thread based log buffer instrumentation in multi-threaded applications. Please post your feedback on comments, if any.
Background
When multiple threads work on a single process, certain scenarios will occur, which we term as race condition. During race condition, the output of execution turns unpredictable and most importantly, these race conditions are always inconsistent.
Due to the inconsistent nature for race conditions, debugging becomes much tougher and challenging.
The most traditional way to deal with such situations is to log relevant details to a log file, which can be examined after some time, or, do a live debugging.
Live debugging can be done, only if you guys are lucky :-) . Mostly, bugs due to race conditions are hard to reproduce and difficult to find root-cause.
In case of issues, raised from production site, engineers have less chances to keep their hands-on the problematic site.
With the provided opportunities, somehow, the puzzle has to be solved.
With the learnings, that I got from, support experience, I would like to share a novel way with which we can log the debugging information, that too for a high performance, race conditions.
Problems with Traditional Methods
File logging - This is one of the easiest & simplest methods. But file I/O will significantly add lot of delay. A delay even in the range of milli seconds, will impact the race condition, so that, the problematic scenario won't even occur.
Common log structure logging - This is much dev approach, where-in, a global log buffer, is used to log relevant details to that buffer. However, this buffer again becomes a shared resource b/w threads. So obviously there has to be a mutex to guard the shared resource. When you bring in mutual exclusion, then you are breaking the parallelism. This again, brings in latency, introduced by locking & unlocking of mutexes, thereby forcing the race-condition, not to occur at all.
Concept & Implementation
As you can guess, the problem with common log-structure logging is the presence of shared mutex lock.
As long as one or more threads, is using the same resource, lock is necessary. So we have to break this common resource.
If all the working threads are having their buffer to log, what they do currently and if there is a global place in the process which will connect all these unique buffers, then that will exactly serves the purpose.
That's the idea behind this article. This can be achieved in 2 ways. Dynamically allocate a buffer to the incoming thread [as threads can be spawned dynamically] or keep the thread id as index of global buffers. While the first option is most scalable option, the second option can be opted, if the latency introduced by attaching a buffer to the thread is also crucial for your scenario.
The following figure will give you a bird's eye view of the logic.
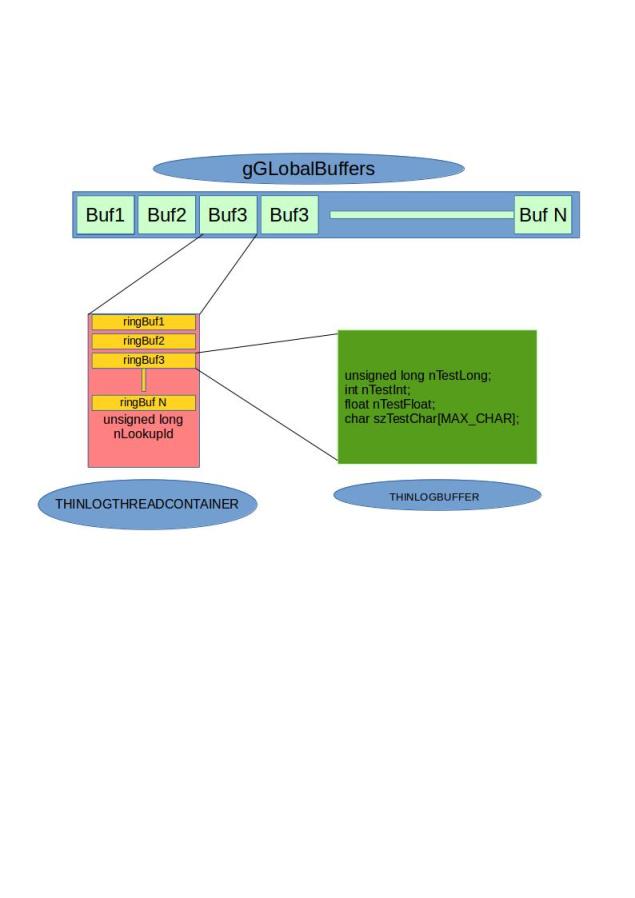
gGLobalBuffers is the array of log buffers, indexed by thread ids. Here you can ask about the wastage of buffers for unused threads. My argument would be, this is not going to be a feature or customer deliverable. We can do anything that it takes to solve a customer issue. So sacrificing some memory to find the root-cause is still a good attempt.
Every buffer is a type of THINLOGTHREADCONTAINER, which contains another array of the log buffer of type THINLOGBUFFER and the thread id index to the globalBuffer.
There are chances that the same thread is being called by multiple callers [consider worker threads]. In such case, if every thread has only single buffer, then the next caller of same thread will over-write the information, that was recorded by the previous caller for same thread. We don't want that to happen, do we :-). That's the reason for tagging multiple log buffers to a single thread container.
Special container - Thread 0
First container is special. Obviously, you will not have a thread 0. So this is used as a overflow container. For example, you had estimated that, for your application, you are going to have only 100 threads. So 100 containers might be enough for you. But during run time, another thread pokes-in [like customer had changed the config during run-time]. Thread 0 container, comes for rescue at that time. The presence of data on container 0 tells that you need to revisit your resource settings.
Using the Code
Step 1 - Define your own instrumentation info in THINLOGBUFFER struct in thinLoggerMT.h.
struct thinLogBuffer
{
unsigned long nTestLong;
int nTestInt;
float nTestFloat;
char szTestChar[MAX_CHAR];
unsigned long nClockTicks;
};
typedef struct thinLogBuffer THINLOGBUFFER;
Try to live with primitives. The instrumentation logic, simply uses memcpy(). So copying the pointer, will not copy the actual pointee. But again, you can override the doInstrumentation() to perform a deep copy.
Step 2 - Define your total container size & number of buffers per container
#define MAX_BUFFERS_PER_THREAD 5
#define MAX_THREADS_PER_PROCESS 7000
The above snippet will make 7000 containers [which will cater for threads whose IDs fall between 0 - 7000] and each thread can save 5 callers information simultaneously.
Important Note
In case of Solaris, the threads start from thread 1 and go on. In case of Linux, there is no concept of threads / lwp. These are simple processes, but with shared address spaces. So in case of Linux, the thread ids will keep increasing depending on the number of processes running during that time. If you are using this solution in Linux, you should be increasing the number of containers, as the lwp id of each thread will be used as index to global buffers. You can also maintain a application specific logic of mapping a short integers to lwps and give that short integer as a index to globalBuffers. But again, this may introduce latency. If your application is not that much real-time, then you can go for it.
Step 3 - Use the APIs init() & doInstrumentation
Init the library using init():
int nRet = init();
if(nRet < 0)
{
printf("\n Unable to init the library");
return;
}
Create a local THINLOGBUFFER, fill the values and do the instrumentation.
THINLOGBUFFER myBuffer;
struct timeval tp;
gettimeofday(&tp, NULL);
unsigned long ms = tp.tv_sec * 1000 + tp.tv_usec / 1000;
myBuffer.nClockTicks = ms;
myBuffer.nTestFloat = (676.56 + rand());
myBuffer.nTestInt = rand();
myBuffer.nTestLong = rand() + myBuffer.nTestFloat;
strcpy(myBuffer.szTestChar, "Viswaaaaaa");
int nRet = doInstrumentation(nThreadID, &myBuffer);
if(nRet < 0)
{
printf("Instrumentation failed");
}
Note: You can call this doInstrumentation() for upto MAX_BUFFERS_PER_THREAD times from the same thread. You can still call N number of times, just that, it will overwrite the buffers and when it overflows the MAX_BUFFERS_PER_THREAD limit.
Reading the Buffers in Post-mortem Debugging
As you can rightly guess, these buffers are in global location of process. If a problem / crash happens in site, and if the customer provides the core / crashdump from the site, with this instrumentation, then debugging will be as easy, like this:
(gdb) print gGLobalBuffers[5313]
$6 = {
nLookupId = 0,
theRingBuffers = {{
nTestLong = 2138875903,
nTestInt = 1957747793,
nTestFloat = 1.71463757e+09,
szTestChar = "Viswaaaaaa\000\267\224\337w\267", '\000'
<repeats 12 times>, "\330`]\267", '\000' <repeats 13 times>, "`y\267",
nClockTicks = 3084490601
}, {
nTestLong = 0,
nTestInt = 0,
nTestFloat = 0,
szTestChar = '\000' <repeats 47 times>,
nClockTicks = 0
}, {
nTestLong = 0,
nTestInt = 0,
nTestFloat = 0,
szTestChar = '\000' <repeats 47 times>,
nClockTicks = 0
}, {
nTestLong = 0,
nTestInt = 0,
nTestFloat = 0,
szTestChar = '\000' <repeats 47 times>,
nClockTicks = 0
}, {
nTestLong = 0,
nTestInt = 0,
nTestFloat = 0,
szTestChar = '\000' <repeats 47 times>,
nClockTicks = 0
}}
}
(gdb) print gGLobalBuffers[5314]
$7 = {
nLookupId = 0,
theRingBuffers = {{
nTestLong = 3485982825,
nTestInt = 846930886,
nTestFloat = 1.80429005e+09,
szTestChar = "Viswaaaaaa", '\000' <repeats 37 times>,
nClockTicks = 3084490601
}, {
nTestLong = 0,
nTestInt = 0,
nTestFloat = 0,
szTestChar = '\000' <repeats 47 times>,
nClockTicks = 0
}, {
nTestLong = 0,
nTestInt = 0,
nTestFloat = 0,
szTestChar = '\000' <repeats 47 times>,
nClockTicks = 0
}, {
nTestLong = 0,
nTestInt = 0,
nTestFloat = 0,
szTestChar = '\000' <repeats 47 times>,
nClockTicks = 0
}, {
nTestLong = 0,
nTestInt = 0,
nTestFloat = 0,
szTestChar = '\000' <repeats 47 times>,
nClockTicks = 0
}}
}
Points of Interest
ThinloggerMT is a simple ringle-buffer implementation, where the buffers are indexed with the thread-id. i.e Each thread has its own log buffer and these buffers are in-turn related to each other.
Since each thread has its own buffer, these threads don't depend on each other. Hence there is no need for the threads to wait for a lock, thereby increasing the log-time of the threads.
These buffers are maintained in global state. As of now, if process core-dumps, then these buffers could be examined from the core-file. Future works have been planned, to dump the instrumentation on-demand basis or shared memory. This buffer has been provided in a static lib format.
I had posted the code in my github page, where I had planned to develop this project as a full-fledged diagnostic library. Feel free to contact, if you like & contribute.
History
- Ver 1 - Static library format

