Introduction
This application might not have any practical value, but it is great from a learning perspective. I wanted to learn about computer vision. Computer vision is one of the most exciting areas of modern computing. It is also a difficult area. What is simple and obvious for the human brain is very difficult for a computer. Many things are still impossible with the current level of IT progress.
This application is implemented using low level C++ because I wanted to learn how things work under the hood. If you’d like to start with a computer vision application, you should take an existing library (like OpenCV) and start from there. You can find several tutorials here on CodeProject. The webcam image gathering source code is from from Vadim Gorbatenko (AviCap CodeProject).
The webcam acquires one image at a time (a frame). The flow of frames gives the impression of motion. The next image explains what this application does within a webcam frame.

The numbers below the image are delays in milliseconds measured on my 2.8GHz PC with the webcam set to 640x480 pixels. The milliseconds show some interesting results. For example, the slowest step is the webcam image gathering. 100 ms means that you will get 10 frames per second. This is poor. Webcams are typically slow. You can make them faster on account of quality. A lower resolution makes the camera faster, but the image quality may become useless. Another surprise is why the conversion to black and white is so slow (12ms). On the other hand, what is expected to be slow is OCR and the solver. But those are surprisingly fast – only 7 ms. I will explain each step in detail and show how things could be improved. The source code function that invokes the above process is DoSomeImageProcessing().
How Conversion to Black and White Works
Thresholding
Every computer vision application starts with the conversion from color (or grayscale) to monochrome image. In the future, there will probably be some color-aware algorithms that will have some use of colors, but today, computer vision applications are all monochrome based (daltonists).
The simplest method to convert color to monochrome is “global thresholding”. Suppose you have a pixel with red intensity 200, green 200, and blue 200. Since the intensity goes from 0 to 255, this pixel is very intensive in light. The threshold between black and white is the middle: 256/2=128. The mean intensity of our pixel is (200+200+200)/3 = 200, which is above the threshold value 128, so it will be converted to white. But this simple global thresholding is not useful in real world applications. The next image shows that.
For a good conversion to monochrome, we will use adaptive thresholding. Adaptive thresholding doesn’t use the fixed thresholding value 128. Instead, it calculates the threshold value separately for each pixel. It reads 11x11 surrounding pixels and sums their intensity. Then the average mean value of sums becomes the threshold value for that pixel. The formula for the pixel is threshold = sum/121, where 121=11x11, and sum is the surrounding intensity summed. If the central pixel intensity is greater than the calculated mean threshold, it will become white, otherwise black. On the next image, we are thresholding the pixel marked red. The same calculation is required for all other pixels. This is the reason why this is so slow. The program needs width*height*121 pixel reads.
Integral Image
This can be optimized by using the “integral image”. Integral image is an array of integers int[image width*image height]. The concept is simple and powerful. The following image is an example. Suppose we have an image 12x12 pixels with all intensity values set to 1 for simplicity (in a real world application, the sample image won’t be that simple). The integral image is the sum of all the pixels from the top and from the left to that pixel.
The next image is an example of how the integral image can be useful. The goal is to calculate the sum of all the pixels in the gray rectangle.
The formula is: sum=D-C-B+A. In our case: 110-44-40+16 = 42 (try to count manually).
Instead of reading all the pixels from the gray rectangle (which can be much bigger than this example), we only need four memory reads. This is a significant optimization. But even with this optimization, the conversion to black and white is still one of the heaviest steps.
How to Detect Rotation
A webcam is not a scanner. A webcam picture is never perfectly aligned. We must expect the image to be skewed and rotated. To detect the angle of rotation, we will use the fact that the Sudoku picture always has some horizontal and vertical lines. We will detect the most expressive (strongest) line somewhere near the center of the picture. The most expressive line is not affected by the noise. The algorithm to detect lines in a monochrome image is called Hough transform.
How it works: You must recall the school math formula of the line: y = (x * cos(theta) + rho) / sin(theta).
Where theta is the angle of the line and rho is the distance of the line from the center coordinate (0, 0).
The important thing to note is that every line can be expressed with only two variables: theta and rho.
The program traverses through every pixel in the monochrome image. It skips white pixels. When on black pixel, it tries to draw all the possible lines passing through that pixel (virtual lines). It works with a resolution of 1 degree. This means that every pixel will have 180 virtual lines passing through it. Why not 360? Because the angles 180-360 are the copy of angles 0-180.
There is an array of virtual lines called an accumulator. The accumulator is a two-dimensional array with dimensions called theta and rho. The same theta and rho as in the line formula. Every virtual line represents one value in the accumulator. By the way, that is why this method is called transformation - it transforms the lines from [x, y] to [theta, rho] array. Every virtual line will increment a value in the accumulator, raising the probability that this virtual line is a real line. This is a kind of voting. The real lines will have majority of votes.
After all pixels and their 180 virtual lines have voted, we must find the biggest values in the accumulator. (By the way, why the name “accumulator”? Because it accumulates votes.) The winner is the most expressive (strongest) line. Its dimensions theta and rho can be used with the above line formula to draw it.
The next image is a simple example. On the left, we have a three pixel line. Your eye can see a diagonal line that goes from the upper-left to the lower-right corner, but this is not that obvious for the computer.
How the line detection works: Look at the above image. The Hough transform algorithm skips the white pixels. Every black pixel draws four green virtual lines (actually, it's 180 lines, but we take only four here for simplicity) passing through that pixel. The first pixel votes the lines A, B, C, and D. The second pixel votes E, B, G, H. The third pixel will vote the lines I, B, K, L. Note that line B is common for all three black pixels. It will get 3 votes. All other lines will get only one vote in the accumulator. Therefore, the virtual line B must be the winner - the real line.
The next image is a more complex example. On the left is the image of Sudoku grid lines. On the right is the accumulator array after the Hough transformation algorithm execution. The bright areas in the accumulator means there are many votes. Blackness means there is no chance to find a line there. Concentrate only on the brightest points. Each line (marked with letters A-U) has a bright point in the accumulator. You can see that all the lines are slightly rotated (approx. 6 degrees). Line A is less rotated than line K. Because the image is not only rotated but also skewed. Also, if you look deeper, you can see how lines A and B are closer than B and C. You can see both on the left and the right image.
Hough transformation is important to understand if you want to learn visual pattern recognition in general. The concept of virtual lines that can yield real lines by voting can be extended to any other geometrical shape. Like circles or rectangles. The line is the simplest geometrical shape, so it should be the simplest to understand.
If you need to locate the circle(s), you will need a three-dimensional accumulator with the dimensions: x, y, and r, where x, y are coordinates and r is the radius of the virtual circles. Again, the highest (lightest) votes in such an accumulator are the real circles on the image.
Hough transformation execution can be optimized by limiting the area and the angles of the original image. We don’t need all the lines from the source image. To detect the rotation angle, we only need a single line somewhere near the center of the image. From that line angle, we assume all other lines are rotated the same.
How to Detect Grid Lines
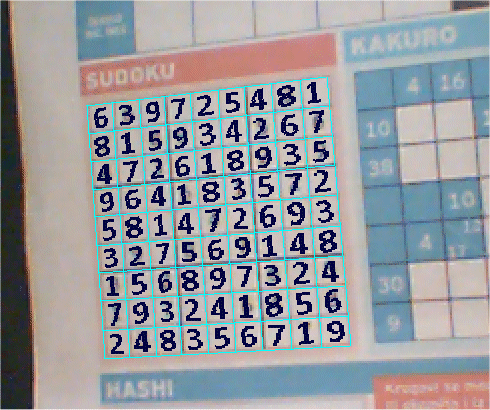
In order to extract the numbers from the grid, we need to precisely locate where a Sudoku grid starts and where it ends. This part is the simplest part for the human brain, but unexpectedly, this part is the most difficult for the computer. Why? Why not use the lines detected by the Hough transformation as described in the previous section? The answer is because there is a lot of noise. In most cases, a Sudoku grid printed in a magazine or newspaper is never alone. There are other grids and lines around it that makes the noise. For example, look at this one:
It is difficult to tell for the computer which lines are Sudoku lines and which are surrounding noise. Where is the end of one grid and start of another.
To solve that problem, we won’t detect black lines. Instead, we will detect the white areas around the Sudoku grid. On the next image, you can see how. The green line 1 is never interrupted with the black pixels from the Sudoku grid, while line 2 is interrupted at least 10 times. This means that line 1 has more probability to be outside the grid. By counting how many times any horizontal and vertical line is interrupted with the black pixels, we can conclude that the green lines on the next image are probably the boundaries of the Sudoku grid. Simple enough - just count how many transitions from the white to black pixels are under the line. You don’t need to run the lines at the resolution of 1 pixel. It’s good enough to skip every 3 pixels for speed.
After we detect the boundaries, we will run Hough transformation inside those boundaries to precisely detect the grid lines. So far, we didn’t care about the images skewing and other image imperfections. Only about coarse image rotation. This step will improve that. By running the Hough transformation on a limited area of the grid, we will get the precise position of all the grid lines. This will help to locate the digits in the cells.
TODO: This step could be improved to be more insensitive to noise. My plan for the next version is to combine the above method with “tilted Haar-like features” to detect the corners of the grid. I hope this could improve quality. The problem may be that Haar-like features are good with solid areas, but we deal with lines. Lines occupy smaller areas, so the difference between a light and dark rectangle is not so big.
I wonder what other options are to detect the 10x10 grid…
How OCR Works
After we locate the blobs inside the grid cells, we need to recognize them. We have a relatively easy task. Only numbers from 1 to 9. Not the entire alphabet.
Theory
Every recognition algorithm has these steps:
- Determine features
- Train (learning step)
- Classify (runtime recognition)
Determine features is a part of the application design. Features are for example: The number 1 is tall and thin. This is what it makes it different from others. The number 8 has two circles, one above the other, etc.
The feature definition can be a very hard and unintuitive job, depending on the things to recognize. For example, what features would you use to recognize somebody’s face? Not any face. The specific face.
Zone Features
In this application, we will use zone density features. The next step (that is already done in advance) is to train the application by providing training pictures of digits 1-9. You can see these pictures in the .\res folder. The pictures are resized to 5x5 pixels, normalized, and stored in the static array OCRDigit::m_zon[10][5][5], which looks like:
The resizing to 5x5 is called zoning. The above array is called density features.
Normalizing means that those 5x5 pictures have density values in the range 0 to 1024. Without normalizing, the zones would be incomparable.
What happens at run-time: When a blob is isolated from a webcam’s image, it’s resized to 5x5 pixels. Then these 25 pixels are compared, one by one, with the nine trained density feature arrays. The goal is to find the minimal difference in pixel intensity. Less difference means more similarity.
This method is insensitive to blob size scale, since we always use 5x5 zones. It is sensitive to rotation, but we already know what the rotation is and can adjust it. The problem is that it is sensitive to position offset and also it does not work with negative images (white on black) and with really rotated images (like upside down).
Width/Height Ratio Feature
Number 1 is a special case. Since it’s similar to 4 and 7, the above method is not reliable. The specific feature of number 1 is: If the blob’s width is less than 40% of the blob’s height, it must be number 1. No other digit is so thin. In addition to the above 25 zone features, this is the 26th feature we are checking.
For the classification step, we use the k-nearest neighbor with k=1, which means that we are detecting only one closest neighbor.
TODO
For the next version, the OCR quality can be improved by introducing other features. For example, the digits 5, 6, and 9 are very similar if used with zone features. To differentiate them, we could use profile features. The profile feature is the number of pixels (distance) between the bounding box of the blob and the edge of the blob.
In the next image, you can see that the right profiles are similar for 5 and 6, but are different for 9. The left profiles for 5 and 9 are similar, but are different for 6.
There are other possible improvements. Professional OCR engines use many different features. Some of them can be very exotic.
Fixing the OCR Result
After OCR is done, the results are logically corrected based on Sudoku rules. The same digit cannot be found in the same row, column, or 3x3 block. If this rule is broken, the OCR result must be wrong and needs a correction. We will replace the wrong result with the next probable result. For example, in Fig. 12 above, the result is 5 because the diff=5210, which is the smallest. The next probable result is 6. Because it has next diff=5508. So, we will replace result 5 with 6. To decide which of two conflicted digits needs correction, we take the one with the smallest difference between the first and the second diff. The source code is in SudSolver::Fixit().
How the Sudoku Solver Works
There are more different methods to solve the Sudoku puzzle. Here, we will use three simple methods working together and helping each other: naked singles, hidden single, and brute force.
Method 1. Brute Force
Also called backtracking. This is the most common method used by programmers and which always gives a solution, no matter how difficult it is. But brute force could be very slow, depending on the number of recursive iterations needed. You can never know in advance how much iteration is needed. Brute force is a “trial and error” method. It tries all the combinations of possible values 1-9 on all empty cells until all the cells are filled with consistent values. There could be more than one solution, but we are happy to find the first one only.
The first step is to prepare the table of candidates – possible values for each empty cell. The image below explains what the candidates are. They are in blue color. By Sudoku rules, the first cell can contain only 1, 4, or 8. For example, 3 cannot be there, because it is already present two cells below.
The brute force will try to combine all the little blue numbers until it finds a solution. See the first cell. The algorithm will start with the value 1, and then on the fifth cell, it will take number 3 and so on. If any of the selected numbers is not consistent with the other values, the algorithm will try with a different one. For example, the sixth cell from the left has also number 3 as a candidate, but since this is not consistent with the fifth cell, the algorithm will try with the next candidate, which is 4, etc.
Brute force can be very slow if the solution requires many iterations. For example, the next image is a “near worst case” puzzle for the brute force algorithm (source: Wiki). Because it tries with all the possible values and the correct one is the last candidate in the sequence of candidates. Fortunately, there is a solution to that problem - you should not start from the top left cell. Any other initial cell will get the solution faster. We will use this trick to speed up the brute force method.
There are other possible optimizations to make the brute force faster, like sorting the recursion sequence from the cells with the smallest number of candidates to the cells with the maximal number of candidates. But we don’t use such optimizations because they are only partial optimizations. They all have a “worst case” where they are not fast enough for real-time applications. Instead, we will use a time-boxed, three retries, random sequence optimization. The trick is to abort backtracking if it takes too long. Then re-sort randomly the sequence for recursion and try again from scratch.
Method 2. Naked Single Candidates
The image below explains this method. If a cell has a single candidate, we are 100% sure this is a valid value for that cell. After we set that value, the next step is to rebuild the list of candidates. The list of candidates gradually reduces until all the candidates are singles. This is an obvious and simple method for computers. Not that obvious for humans, though. Human players cannot keep a list of candidates in their head.
Method 3. Hidden Single
The image below explains this method. Look at the number 7. If you are a Sudoku player, you will probably instantly see that the number 7 must be there.
Even if this cell has four candidates: 4, 7, 8, 9 (see Fig. 15), the trick is that we search for a unique instance of candidates inside the 3x3 block, column, or row. This method probably cannot solve the entire puzzle, but works nicely together with method 2. When method 2 runs out of single candidates, method 3 can help.
Putting All Methods Together
For the webcam solver, the speed is very important. Brute force is not fast enough for our application. Therefore, we will use a combination of all three methods. The methods 2 and 3 are very fast, but can solve only simple puzzles. Since we get the input from a noisy webcam, we often get very hard or even unsolvable puzzles (because of OCR unreliability). We must assume the puzzles will often be very hard to solve. Even if the original puzzle is meant to be a simple one.
How to read the next diagram: On the left side, there are fast methods 2 and 3. Only if they are unsuccessful, we will jump to the right side, which is slow brute-force. Even if methods 2 and 3 are unsuccessful to solve, they do a great job of solving at least some cells, reducing the job for brute-force.
Only if methods 2 and 3 cannot solve it, the program falls down to the brute force method. And even then, the brute force is limited to 600000 iterations to keep the algorithm time-boxed. There will be three re-tries after which the program gives up. Between each retry, the recursion sequence is rearranged randomly with the hope that the new sequence will lead to a fast solution. If brute-force fails after three re-tries, it’s not a complete failure. We may have more luck with the next camera frame. The above diagram is implemented in SudSolver::SolveMe().
Buffering the Solution
When the solution is found, we keep track of the most recent solutions in an array of type SudResultVoter. Buffering is needed because the OCR is not 100% reliable and we get wrong solutions from time to time. To avoid a fluctuating solution, we will always show the strongest solution that has been found recently (among the last 12 solutions, to be precise). From time to time, the array is reset, forgetting the old solution and giving a chance to a new Sudoku that is currently in focus.
Video
TODO
Some ideas for the future:
- Rewrite the program for Android. I wonder how that would work on SmartPhones.
- Parallelize some functions to use multicore processors. PCs have at least dual-core processor. Normally, parallel tasking is used to improve performance. But here we don’t need more speed, we need more quality. The idea is that parallel tasks should perform the same operation on the same image frame but with different settings. After all tasks are joined, we will take the task with the best result and discharge others.
History
- 8th August, 2011 - First release

