Introduction
Parallel processing has always been an interesting method to improve program performance. Lately, there are more computers with multi processors or multi-core CPUs thus making parallel processing available to the masses. However, having multiple processing units on the hardware does not make existing programs take advantage of it. Programmers must take the initiative to implement parallel processing capabilities to their programs to fully utilize the hardware available. OpenMP is a set of programming APIs which include several compiler directives and a library of support functions. It was first developed for use with Fortran and now it is available for C and C++ as well.
Types of Parallel Programming
Before we begin with OpenMP, it is important to know why we need parallel processing. In a typical case, a sequential code will execute in a thread which is executed on a single processing unit. Thus, if a computer has 2 processors or more (or 2 cores, or 1 processor with HyperThreading), only a single processor will be used for execution, thus wasting the other processing power. Rather than letting the other processor sit idle (or process other threads from other programs), we can use it to speed up our algorithm.
Parallel processing can be divided into two groups, task based and data based.
- Task based: Divide different tasks to different CPUs to be executed in parallel. For example, a Printing thread and a Spell Checking thread running simultaneously in a word processor. Each thread is a separate task.
- Data based: Execute the same task, but divide the work load on the data over several CPUs. For example, to convert a color image to grayscale. We can convert the top half of the image on the first CPU, while the lower half is converted on the second CPU (or as many CPUs as you have), thus processing in half the time.
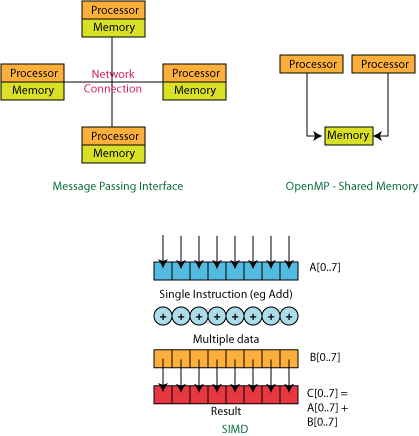
There are several methods to do parallel processing:
- Use MPI: Message Passing Interface - MPI is most suited for a system with multiple processors and multiple memory. For example, a cluster of computers with their own local memory. You can use MPI to divide workload across this cluster, and merge the result when it is finished. Available with Microsoft Compute Cluster Pack.
- Use OpenMP: OpenMP is suited for shared memory systems like we have on our desktop computers. Shared memory systems are systems with multiple processors but each are sharing a single memory subsystem. Using OpenMP is just like writing your own smaller threads but letting the compiler do it. Available in Visual Studio 2005 Professional and Team Suite.
- Use SIMD intrinsics: Single Instruction Multiple Data (SIMD) has been available on mainstream processors such as Intel's MMX, SSE, SSE2, SSE3, Motorola's (or IBM's) Altivec and AMD's 3DNow!. SIMD intrinsics are primitive functions to parallelize data processing on the CPU register level. For example, the addition of two unsigned char will take the whole register size, although the size of this data type is just 8-bit, leaving 24-bit in the register to be filled with 0 and wasted. Using SIMD (such as MMX), we can load 8 unsigned chars (or 4 shorts or 2 integers) to be executed in parallel on the register level. Available in Visual Studio 2005 using SIMD intrinsics or with Visual C++ Processor Pack with Visual C++ 6.0.
Getting Started
Setting Up Visual Studio
To use OpenMP with Visual Studio 2005, you need:
- Visual Studio 2005 Professional or better
- A multi processor or multi core system to see speed improvement
- An algorithm to parallelize!
Visual Studio 2005 uses OpenMP standard 2.0 and is located in the vcomp.dll (Located in Windows>WinSxS> (ia64/amd64/x86)Microsoft.VC80.(Debug)OpenMP.(*) directory) dynamic library.
To use OpenMP, you must do the following:
- Include
<omp.h> - Enable OpenMP compiler switch in Project Properties
- That's all!

Understanding the Fork-and-Join Model
OpenMP uses the fork-and-join parallelism model. In fork-and-join, parallel threads are created and branched out from a master thread to execute an operation and will only remain until the operation has finished, then all the threads are destroyed, thus leaving only one master thread.
The process of splitting and joining of threads including synchronization for end result are handled by OpenMP.
How Many Threads Do I Need?
A typical question is how many threads do I actually need? Are more threads better? How do I control the number of threads in my code? Are number of threads related to number of CPUs?
The number of threads required to solve a problem is generally limited to the number of CPUs you have. As you can see in the Fork-and-Join figure above, whenever threads are created, a little time is taken to create a thread and later to join the end result and destroy the threads. When the problem is small, and the number of CPUs are less than the number of threads, the total execution time will be longer (slower) because more time has been spent to create threads, and later switch between the threads (due to preemptive behaviour) then to actually solve the problem. Whenever a thread context is switched, data must be saved/loaded from the memory. This takes time.
The rule is simple, since all the threads will be executing the same operation (hence the same priority), 1 thread is sufficient per CPU (or core). The more CPUs you have, the more threads you can create.
Most compiler directives in OpenMP use the Environment Variable OMP_NUM_THREADS to determine the number of threads to create. You can control the number of threads with the following functions:
int iCPU = omp_get_num_procs();
omp_set_num_threads(iCPU);
Of course, you can put any value for iCPU in the code above (if you do not want to call omp_get_num_procs), and you can call the omp_set_num_threads functions as many times as you like for different parts of your code for maximum control. If omp_set_num_threads is not called, OpenMP will use the OMP_NUM_THREADS Environment Variable.
Parallel for Loop
Let us start with a simple parallel for loop. The following is a code to convert a 32-bit Color (RGBA) image to 8-bit Grayscale image.
omp_set_num_threads(threads);
#pragma omp parallel for
for(int z = 0; z < height*width; z++)
{
pDest[z] = (pSrc[z*4+0]*3735 + pSrc[z*4 + 1]*19234+ pSrc[z*4+ 2]*9797)>>15;
}
The #pragma omp parallel for directive will parallelize the for loop according to the number of threads set. The following is the performance gained for a 3264x2488 image on a 1.66GHz Core Duo system (2 Cores).
Thread(s) : 1 Time 0.04081 sec
Thread(s) : 2 Time 0.01906 sec
Thread(s) : 4 Time 0.01940 sec
Thread(s) : 6 Time 0.02133 sec
Thread(s) : 8 Time 0.02029 sec
As you can see, by executing the problem using 2 threads on a dual-core CPU, the time has been cut by half. However, as the number of threads is increased, the performance does not due to increased time to fork and join.
Parallel double for Loop
The same problem above (converting color to grayscale) can also be written in a double for loop way. This can be written like this:
for(int y = 0; y < height; y++)
for(int x = 0; x< width; x++)
pDest[x+y*width] = (pSrc[x*4 + y*4*width + 0]*3735 +
pSrc[x*4 + y*4*width + 1]*19234+ pSrc[x*4 + y*4*width + 2]*9797)>>15;
In this case, there are two solutions.
Solution 1
We have made the inner loop parallel using the parallel for directive. As you can see, when 2 threads are being used, the execution time has actually increased! This is because, for every iteration of y, a fork-join operation is performed, and at the end contributed to the increased execution time.
for(int y = 0; y < height; y++)
{
#pragma omp parallel for
for(int x = 0; x< width; x++)
{
pDest[x+y*width] = (pSrc[x*4 + y*4*width + 0]*3735 +
pSrc[x*4 + y*4*width + 1]*19234+ pSrc[x*4 + y*4*width + 2]*9797)>>15;
}
}
Thread(s): 1 Time 0.04260 sec
Thread(s): 2 Time 0.05171 sec
Solution 2
Instead of making the inner loop parallel, the outer loop is the better choice. Here, another directive is introduced - the private directive. The private clause directs the compiler to make variables private so multiple copies of a variable do not execute. Here, you can see that the execution time did indeed get reduced by half.
int x = 0;
#pragma omp parallel for private(x)
for(int y = 0; y < height; y++)
{
for(x = 0; x< width; x++)
{
pDest[x+y*width] = (pSrc[x*4 + y*4*width + 0]*3735 +
pSrc[x*4 + y*4*width + 1]*19234+ pSrc[x*4 + y*4*width + 2]*9797)>>15;
}
}
Thread(s) : 1 Time 0.04039 sec
Thread(s) : 2 Time 0.02020 sec
Get to Know the Number of Threads
At any time, we can obtain the number of OpenMP threads running by calling the function:
int omp_get_thread_num();
Summary
By using OpenMP, you can gain performance on multi-core systems for free, without much coding other than a line or too. There is no excuse not to use OpenMP. The benefits are there, and the coding is simple.
There are several other OpenMP directives such as firstprivate, critical sections and reductions which are left for another article. :)
Points of Interest
You can also perform similar operation using Windows threads, but it will be more difficult to implement, because of issues such as synchronization and thread management.
Additional Notes
The original RGB to Grayscale formula is given as Y = 0.299 R + 0.587 G + 0.114 B.
References
- Parallel Programming in C with MPI and OpenMP (1st ed.), Michael J. Quinn, McGraw Hill, 2004
- Scientific Parallel Computing, L. Ridgway Scott, Terry Clark, Babak Bagheri, Princeton University Press, 2005
- Introduction to Parallel Computing: A Practical Guide with Examples in An W.P. Petersen, P. Arbenz, Oxford University Press, 2004.
- Digital Color Imaging Handbook, Gaurav Sharma, CRC Press, 2003
History
- June 6, 2007 - Added - MPI capabilities available with Microsoft Compute Cluster Pack
- June 6, 2007 - Initial article (This is my first article on CodeProject!)

