Introduction
JavaScript and the DOM, in conjunction with ASP.NET, offer a good environment to leave some of the work of finding text to the client, cutting down on server calls and producing a faster experience. The technique used here is to locate and highlight text in a page, when possible using JavaScript, and when it can't be found, to go back to the server to see if it can find it. I haven't come across other examples of using the DOM for highlighting search results, and thought others might find it a helpful technique or maybe just a starting point for using the DOM. This article is only intended to cover the client end (JavaScript and DOM).
Background
Even nowadays, many financial systems (and others) produce long 80 and 132 column reports that various people have to trawl through checking this and that. There are many ways of getting VB and others to locate lines of text in a report to pass out over the web, and that is not the main concern in this article. My aim is to give the end user fast response and keep the number of calls to the server to a minimum. Because the end users are logged into a business specific system, I was able to guarantee IE6 or Firefox as browsers, and this project made no allowance for DOM deficient browsers.
Using the code
This code was all developed in Visual Studio 2003, and uses JavaScript to interface with an existing ASP.NET application that serves lines from a text file. It works on Firefox and IE6 and IE7. It may work on other DOM compliant(ish) browsers, but I have not tested it. The HTML is close to being XHTML 1.1 compliant, but my brain and ASP.NET 1.1 between them ensure that it is not strict! The demo provided comprises an ASPX and aspx.vb file. You will need to hard code a filename in the .vb file as I have replaced the mechanism that actually gets the file and reads it with something rather cruder. Note that this is not production code - for clarity, quite a lot of error checking has been pulled - in particular, there is no checking of the input search for reserved characters.
Where are we looking?
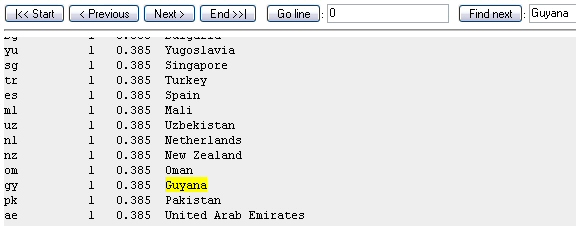
The server is going to fill the literal control currentLines with lines from the report to which it has added br tags to the end of every line and replaced spaces with the special character. The Literal control is in a div block, preDiv. An alternative here would be to wrap the Literal in a pre block, which would remove the need for the special characters, but in this instance, the original file was from a mainframe and had enough odd characters in it to require fiddling with at the server-end anyway! It is the preDiv div that we will do most of the work with. preDiv is in turn nested in the reportLines div, which will control the display and placing of the text.
<div id="reportLines"
style="overflow: auto; width: 100%; font-family: 'courier new', sans-serif;
position: relative; height: 425px; background-color: #eeeeee">
<div id="preDiv">
<asp:literal id="currentLines"
runat="server" EnableViewState="False"></asp:literal>
</div>
</div>
How do we find it?
We will be looking for a string of text supplied by the user in a textbox ...
<input id="searchFor" type="text"
name="searchText" runat="server" />
... and we want to look in the contents of preDiv. JavaScript provides us with the method indexOf, and the DOM provides us with the place to look: document.getElementById('preDiv').innerHTML. The variable pos will save the position for us. We also have a global variable lastPos which will record how far we have already searched, so that when we come to search for the next occurrence, we know where to start looking from. lastPos's initial value will be zero - i.e., the start.
searchText = document.createTextNode(
document.getElementById('searchFor').value.replace(new RegExp(/ /g),' '))
searchTextLength=searchText.length
preDivText=document.getElementById('preDiv').innerHTML
if (document.getElementById('<%= caseSensitive.clientId %>').checked){
pos= preDivText.indexOf(
document.getElementById('searchFor').value.replace(
new RegExp(/ /g),' '),lastPos);
}
else{
preDivTextLower= preDivText
preDivTextLower=preDivTextLower.toLowerCase()
searchForLow=document.getElementById('searchFor').value
searchForLow=searchForLow.toLowerCase()
pos= preDivTextLower.indexOf(searchForLow.replace(new RegExp(/ /g),' '),lastPos);
}
We have also added a few lines to enable the user to select whether they want their search to be case sensitive, in which case, they will have checked the caseSensitive ASP checkbox. The replace statements are required, because (as mentioned above) we have converted all spaces to non-breaking space characters. So we now have a JavaScript variable pos with the start position of our string, and another searchTextLength with the length of the string.
Highlighting the text
Now we want to highlight the text (assuming we have found it), which we will do by splitting preDiv into three divs. toLeft will contain everything before the found text, foundDiv will contain the found text, and toRight will contain everything after it. Thanks to the DOM, this is pretty straightforward, and requires only a small adjustment to work on IE6 (and rather surprisingly, IE7 - but it's not finished yet!). So first, we define our found text as a TextNode for use later.
foundText=document.createTextNode(preDivText.substring(
pos,pos+searchTextLength).replace(new RegExp(/ /g),' '))
(Yes - we're still replacing those spaces!) Next, we create our toLeft div using a substring from the beginning to the start of our found text (remember that in JavaScript, the second parameter is the stop point, not the length of the sub string) ...
lastPos=pos+1
toLeft=document.createElement('div')
toLeft.id='toLeft'
toLeft.innerHTML=preDivText.substring(0,pos)
toLeft.style.display='inline'
... and our toRight div starting from the end of our found text (no second parameter, meaning 'all that is left').
toRight=document.createElement('div')
toRight.id='toRight'
toRight.innerHTML=preDivText.substring(pos+searchTextLength)
toRight.style.display='inline'
For our foundDiv, we need just a little more work as we are going to add an onclick event so that when the user clicks on the highlighted text, the search will jump to the next occurrence. It will do this by raising the click event for the search button (findNext). Sadly, IE doesn't cope very well with the setAttribute method, so we will use attachEvent, which Firefox doesn't like at all (which is why we can't just do them both).
foundDiv=document.createElement('div')
foundDiv.id='foundArea'
foundDiv.appendChild(foundText)
foundDiv.style.backgroundColor='#ffff00'
foundDiv.style.display='inline'
foundDiv.style.cursor='pointer'
foundDiv.title='Click to go to next occurrence'
if (navigator.userAgent.toLowerCase().indexOf('msie')>0)
{ foundDiv.attachEvent("onclick",
function(){document.getElementById("findNext").click()})
}
foundDiv.setAttribute('onClick','document.getElementById("findNext").click()')
That's them all defined, so now, we will fill preDiv with them (after we get rid of what it already has). The last line in this section will make the reportLines div scroll down to display the foundDiv at the top.
document.getElementById('preDiv').innerHTML=""
document.getElementById('preDiv').appendChild(toLeft)
document.getElementById('preDiv').appendChild(foundDiv)
document.getElementById('preDiv').appendChild(toRight)
document.getElementById('reportLines').scrollTop=foundDiv.offsetTop
What we have so far will work fine - but only once. The next time we come to search preDiv, we will have real problems because our toLeft, toRight, and foundDiv are already in preDiv. Our finished function will need to account for this by checking the content of preDiv and if necessary, setting it back to its original content. We use the baseLines variable to keep our original content. So, at the start of the function, we have:
if(document.getElementById('foundArea')){
document.getElementById('preDiv').removeChild(toLeft)
document.getElementById('preDiv').removeChild(foundDiv)
document.getElementById('preDiv').removeChild(toRight)
document.getElementById('preDiv').innerHTML =baseLines
}
else{
baseLines=document.getElementById('preDiv').innerHTML
}
Note that we use the removeChild method, and do not just set innerHTML to an empty string, which would have produced unpredictable results.
Putting the JavaScript together
All we need to do now is check that if there is any point in doing any of it before we start. We check that our searchFor box actually has some text to search for, and check the value of pos to see if we found anything. Now we have our function which we will call findNextText(). We don't want the server to be called if we find the text in the page, so we will return false if we find in page and true if we don't:
function findNextText(){
if(!document.getElementById('searchFor').value==''){
if(document.getElementById('foundArea')){
document.getElementById('preDiv').removeChild(toLeft)
document.getElementById('preDiv').removeChild(foundDiv)
document.getElementById('preDiv').removeChild(toRight)
document.getElementById('preDiv').innerHTML =baseLines
}
else{
baseLines=document.getElementById('preDiv').innerHTML
}
searchText=document.createTextNode(document.getElementById(
'searchFor').value.replace(new RegExp(/ /g),' '))
searchTextLength=searchText.length
preDivText=document.getElementById('preDiv').innerHTML
if (document.getElementById('<%= caseSensitive.clientId %>').checked){
pos= preDivText.indexOf(document.getElementById(
'searchFor').value.replace(new RegExp(/ /g),' '),lastPos);
}
else{
preDivTextLower= preDivText
preDivTextLower=preDivTextLower.toLowerCase()
searchForLow=document.getElementById('searchFor').value
searchForLow=searchForLow.toLowerCase()
pos= preDivTextLower.indexOf(searchForLow.replace(new RegExp(/ /g),' '),lastPos);
}
if (pos<0){
lastPos=0
return true
}
else
{
foundText=document.createTextNode(
preDivText.substring(pos,pos+searchTextLength).replace(new RegExp(/ /g),' '))
lastPos=pos+1
toLeft=document.createElement('div')
toLeft.id='toLeft'
toLeft.innerHTML=preDivText.substring(0,pos)
toLeft.style.display='inline'
toRight=document.createElement('div')
toRight.id='toRight'
toRight.innerHTML=preDivText.substring(pos+searchTextLength)
toRight.style.display='inline'
foundDiv=document.createElement('div')
foundDiv.id='foundArea'
foundDiv.appendChild(foundText)
foundDiv.style.backgroundColor='#ffff00'
foundDiv.style.display='inline'
foundDiv.style.cursor='pointer'
foundDiv.title='Click to go to next occurrence'
if (navigator.userAgent.toLowerCase().indexOf('msie')>0)
{ foundDiv.attachEvent("onclick",
function(){document.getElementById("findNext").click()})
}
foundDiv.setAttribute('onClick','document.getElementById("findNext").click()')
document.getElementById('preDiv').innerHTML=""
document.getElementById('preDiv').appendChild(toLeft)
document.getElementById('preDiv').appendChild(foundDiv)
document.getElementById('preDiv').appendChild(toRight)
document.getElementById('reportLines').scrollTop=foundDiv.offsetTop
return false
}
}
}
Well, that's the JavaScript part - the rest is perhaps more familiar ASP territory. When the text is not found on the page when we have clicked the findNext button, we want the browser to ask the server for more. So, let's have a look at the findNext button in our HTML.
<asp:button id="findNext" runat="server" Text="Find next" ></asp:button>
In ASP.NET 2.0, we would also have the onClientClick attribute available, but in 1.0, we must code behind to ensure that when the button is clicked, it runs our findNextText script. We do this in the Page_Load.
findNext.Attributes.Add("onclick", "return findNextText();")
Because findNextText() returns false if the text was found in the page, findNext will not postback if the text was found. If the text is found, findNextText returns true and the postback goes ahead. The findNext.Click event is raised, and your code on the server can return a page full of text starting at the located line, or a message saying that no matching lines where found.
And there you have it. A fast and bandwidth efficient way to enable users to search through large text files by sharing the load between the client and the server. Trials I have done suggest that between 50 and 200 132 character lines strike a good balance between response and server effort saved - it all depends on the nature of the report you are searching.
Points of interest
IE 7 not handling the setAttribute was a disappointment, but it is still only beta, so hopefully that one will get cleaned up soon. You'll notice lots of style attributes and no class attributes, for which I apologize, but it was a quick method for anonymising the code!
This member has not yet provided a Biography. Assume it's interesting and varied, and probably something to do with programming.





