Background
This is a library to implement Neural Networks in JavaScript. While not a comprehensive library to support deep learning, it supports most of the functionalities of a basic Artificial Neural Network.
- It supports any number of inputs.
- It supports any number of outputs.
- It supports any number of hidden layers and the number of nodes in each layer is configurable.
- It supports bias nodes on the input layer and the hidden layers.
In order to make it simple, the following two assumptions are made.
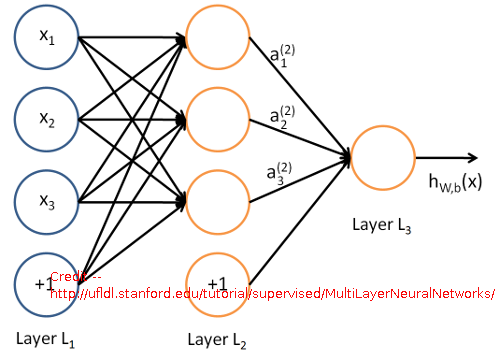
The basic Neural Network structure and algorithms have been very well studied over the years. I will not spend time here. You can refer to this link if you are not familiar with them.
The ANN Neural Network Library
For experiment and for fun, I implemented the neural network library for experimental purposes. Because it is written for experimental purposes, I wrote it in ES6 and tested it by Jest. After introducing the library, I will show you an example of how to train a neural network to perform the XOR operations.

The Network Structure
To create a neural network, we need to create a configuration instance, which defines the structure of the network.
export class config {
constructor(numOfInputs,
numberOfOutputs,
hiddenlayers,
activatorName,
learningRate) {
this.numOfInputs = numOfInputs;
this.numberOfOutputs = numberOfOutputs;
this.hiddenlayers = hiddenlayers;
this.activatorName = activatorName;
this.learningRate = learningRate? learningRate: 1;
}
}
There are two types of nodes in the network, namely normal nodes and bias nodes. The bias node has only the out entry that is always 1.
export class node {
constructor() {
this.sum = 0;
this.out = 0;
this.gradient = 0;
}
}
export class biasnode {
constructor() { this.out = 1; }
}
Based on the configuration, we have the information to build the network structure.
export class network {
constructor(config) {
this.config = config;
this.layers = [];
this.weights = [];
}
getOutput() {
let layers = this.layers;
let output = [];
if (!layers || layers.length < 1) {
return output;
}
let oLayer = layers[layers.length - 1];
let length = oLayer.length;
for (let i = 0; i < length; i++) {
output[i] = oLayer[i].out;
}
return output;
}
}
Each neural network has an array of layers and an array of weight matrices. We will talk about how to initiate the layers and the weights when we talk about the operations on the network.
The Activation Functions
Except the input nodes, all the outputs of the other nodes are the weighted sum of the outputs of the nodes in the previous layer going through an activation function.
export const activatorFactory = {
availableActivators: {
linear: {
value: function(x) {
return x;
},
prime: function(x) {
return 1;
}
},
signoid: {
value: function(x) {
return 1 / (1 + Math.exp(-1 * x));
},
prime: function(x) {
let v = this.value(x);
return v * (1 - v);
}
},
ReLU: {
value: function(x) {
return Math.max(0, x);
},
prime: function(x) {
return (x >= 0)? 1: 0;
}
}
},
getActivator: function(name) {
return this.availableActivators[name];
}
}
For simplicity, I only implemented linear, sigmoid, and ReLU functions. If you want to try other activation functions, you can add them here.
The Network Operations
To initiate the layers and weight matrices, we can use the networkInitiator object by passing in a network object that carries the configuration.
import {node, biasnode} from '../network/node';
export const networkInitiator = function() {
let initLayer = function(n, skipBias) {
let nodes = [];
for (let i = 0; i < n; i++) {
nodes[i] = new node();
}
if (! skipBias) { nodes[n] = new biasnode();}
return nodes;
};
let initWeight = function(ni, no) {
let w = [[]];
for (let i = 0; i < no; i++) {
let r = [];
for (let j = 0; j < ni; j++) { r[j] = Math.random(); }
r[ni] = Math.random();
w[i] = r;
}
return w;
};
let initLayers = function(conf) {
let ni = conf.numOfInputs;
let no = conf.numberOfOutputs;
let hl = conf.hiddenlayers;
let layers = [[]];
layers[0] = initLayer(ni);
let l = hl.length;
for (let i = 0; i < l; i++) {
layers[i + 1] = initLayer(hl[i]);
}
layers[l + 1] = initLayer(no, true);
return layers;
};
let initWeights = function(conf) {
let ni = conf.numOfInputs;
let no = conf.numberOfOutputs;
let hl = conf.hiddenlayers;
let w = [[]];
w[0] = initWeight(ni, hl[0]);
let l = hl.length;
for (let i = 1; i < l; i++) {
w[i] = initWeight(hl[i - 1], hl[i]);
}
w[l] = initWeight(hl[l - 1], no);
return w;
};
return {
initNetwork: function(nn) {
nn.layers = initLayers(nn.config);
nn.weights = initWeights(nn.config);
},
};
}();
- Because a bias node is added to each layer, the number of nodes in each layer is
n + 1, where n is the number of normal nodes defined in the configuration. - Because a bias node is added to each layer, each weight matrix is of dimension
m x (n + 1), where n is the number of the normal nodes in the previous layer, m is the number of the normal nodes in the next layer as defined in the configuration. The initial weights in the weight matrices are initiated randomly.
To perform the operations on the neural network, the networkOperator object is created.
import { internalOperations } from './internalOperations';
import { activatorFactory } from '../activations/activatorFactory';
export const networkOperator = {
forward: function(nn, input) {
let config = nn.config;
let layers = nn.layers;
let weights = nn.weights;
let activator = activatorFactory.getActivator(config.activatorName);
internalOperations.applyInput(layers[0], input);
for (let i = 0; i < weights.length; i++) {
internalOperations.applyWeight
(layers[i], weights[i], layers[i + 1], activator);
}
return nn.getOutput();
},
backward: function(nn, diff) {
let config = nn.config;
let layers = nn.layers;
let weights = nn.weights;
let activator = activatorFactory.getActivator(config.activatorName);
internalOperations.applyDiff(layers[layers.length - 1], diff, activator);
for (let i = layers.length - 1; i > 0; i--) {
internalOperations.applyGradient(layers[i - 1], weights[i - 1], layers[i],
activator, config.learningRate);
}
},
train: function(nn, data) {
let input = data[0];
let desired = data[1];
let diff = internalOperations.getDiff(this.forward(nn, input), desired)
this.backward(nn, diff);
return diff;
}
}
- Given the input of the neural network, we can use the
forward function to calculate the output. - To train the neural network, we can use the
train function. The data parameter should have both the input and the expected output for the training.
For documentation purposes and if you are interested, the detailed operations supporting the networkOperator is implemented in the internalOperations object.
export const internalOperations = {
applyInput: function(l, input) {
let length = input.length;
for (let i = 0; i < length; i++) {
let value = input[i];
l[i].sum = value;
l[i].out = value;
}
},
applyWeight: function(ll, w, lr, activator) {
let nr = w.length;
let nc = w[0].length;
for (let i = 0; i < nr; i++) {
let node = lr[i];
let sum = 0;
for (let j = 0; j < nc; j++) {
sum += w[i][j] * ll[j].out;
}
node.sum = sum;
node.out = activator.value(sum);
}
},
getDiff(actual, desired) {
let diff = [];
let length = actual.length;
for (let i = 0; i < length; i++) {
diff[i] = actual[i] - desired[i];
}
return diff;
},
applyDiff: function(l, diff, activator) {
let length = l.length;
for (let i = 0; i < length; i++) {
let node = l[i];
node.gradient = diff[i] * activator.prime(node.sum)
}
},
applyGradient(ll, w, lr, activator, lrate) {
let nr = w[0].length - 1;
let nc = w.length;
for (let i = 0; i < nr; i++) {
let node = ll[i];
let gradient = 0;
for (let j = 0; j < nc; j++) {
let wt = w[j][i];
let rgradient = lr[j].gradient;
gradient += wt * rgradient;
w[j][i] = wt - node.out * rgradient * lrate;
}
node.gradient = activator.value(node.sum) * gradient;
}
let bias = ll[nr];
for (let i = 0; i < nc; i++) {
let wt = w[i][nr];
let rgradient = lr[i].gradient;
w[i][nr] = wt - bias.out * rgradient * lrate;
}
}
};
The "ann.js"
Although you can use the network directly with the network operations to perform all the tasks on the neural network, it is recommended to go through the ann.js class which serves as a facade to make the library a lot easier to use.
import { network } from './network/network';
import { networkInitiator } from './network-operators/networkInitiator';
import { networkOperator } from './network-operators/networkOperator';
export class ann {
constructor() { this.nn = null; }
initiate(config) {
this.nn = new network(config);
networkInitiator.initNetwork(this.nn);
return this;
}
forward(data) {
return networkOperator.forward(this.nn, data);
}
train(data) {
return networkOperator.train(this.nn, data);
}
}
The XOR Example
This library is well tested. If you are interested in seeing all the unit tests, please feel free to checkout the Github repository. But in the note, I will only show you how to train a neural network to perform the XOR operations.
import { config } from '../ann/network/config';
import { ann } from '../ann/ann';
it('Nural network training Test', () => {
let conf = new config(2, 1, [4], 'ReLU', 0.01);
let nn = new ann().initiate(conf);
let data = [];
data.push([[0, 0], [0]]);
data.push([[1, 1], [0]]);
data.push([[0, 1], [1]]);
data.push([[1, 0], [1]]);
for (let i = 0; i < 10000; i++) {
for (let j = 0; j < data.length; j++) {
nn.train(data[j]);
}
}
let result = [];
for (let i = 0; i < data.length; i++) {
let r = nn.forward(data[i][0])[0];
result.push([...data[i][0], ...[r]])
}
console.log(result);
});
- The neural network is configured to have 2 inputs, 1 output, 1 hidden layer with 4 hidden nodes. It uses ReLU activation and the learning rate
0.01. - I performed 10000 times of training on the standard inputs to meet the desired outputs.
Because the program is written in ES6, to run the test, you need first issue the following command to install the node_modules. If you do not have npm on your computer, you will need to install it.
npm install
After the installation of the node_modules, you can use the following command to run the test.
npm run test
Discussions
The Overfitting Problem
With the XOR example, we can see that the neural network after training produced the exactly desired outputs for the corresponding inputs. But if you try a slightly different input such as [0.1, 0.9], you can see that the output differs from the desired output 1 significantly. This is the so called overfitting. In neural networks, overfitting is not desired, because it causes the networks fail to recognize the pattern from the data that is not used for training. To avoid overfitting, additional training data with noises are added for the training. In the XOR example, we can use the following training data.
data.push([[0, 0], [0]]);
data.push([[1, 1], [0]]);
data.push([[0, 1], [1]]);
data.push([[1, 0], [1]]);
data.push([[0.1, 0.1], [0]]);
data.push([[0.9, 0.9], [0]]);
data.push([[0.1, 0.9], [1]]);
data.push([[0.9, 0.1], [1]]);
After training with the additional data, the network should be able to recognize the XOR pattern even with slightly noisy inputs.
The Number of Hidden Layers
In the XOR example, I used 1 hidden layer, but you can try to use more hidden layers.
let conf = new config(2, 1, [4, 4], 'ReLU', 0.01);
With this configuration, you will have a network with 2 hidden layers. Each hidden layer has 4 nodes. By my experiment, I noticed that adding hidden layers does make the training harder. It requires smaller learning rate and more iterations. Because the weight matrices are randomly generated, it may fail to converge if the learning rate is not small enough for some initial weight values. In practice, if a smaller number of hidden layers can meet the requirement, it is better to use a smaller number of hidden layers.
The Initial Weight Matrices
In the XOR example, I used randomly generated initial weight matrices. When you try to use multiple hidden layers, you may notice that the training may not converge due to the initial random values. In practice, it is normally better to start with a simple network and a smaller set of training data. When we achieve the desired result on the training data, we can gradually increase the data set and the complexity of the network.
Points of Interest
- This is a library to implement Neural Networks in JavaScript.
- I hope you like my posts and I hope this note can help you one way or the other.
History
- 10th October, 2018: First revision
I have been working in the IT industry for some time. It is still exciting and I am still learning. I am a happy and honest person, and I want to be your friend.


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 





