This article is hopefully a fun case study of how I iterated my implementation from a prototype to an over-the-top "production"piece. It covers some issues that we should all be conscious of when reworking prototype code, like: What is a Prototype? What is Production Code? When is Code Production Ready?
Introduction
Something short while I work on the next mega-article. :)
I recently had to write an algorithm that populates a tree from a collection of paths. The reason I ended up writing this algorithm is actually because I was mentoring someone who needed to implement this, but who is not quite proficient yet (but is a very quick learner) in C#, .NET, LINQ, etc., hence my mentoring. The algorithm is complicated enough that I wanted to work through the problem myself first and not look like a bumbling fool -- prep work is important! As it turns out, it makes for a good case study of code refactoring.
First, by "tree", I don't mean a TreeView necessarily, but something as simple as this model:
public class Node
{
public string Text { get; set; }
public List<Node> Nodes { get; protected set; }
public Node()
{
Nodes = new List<Node>();
}
}
With regards to a TreeView, there are some existing implementations out there. Ironically, I didn't even think of searching for an existing implementation first, and quite frankly, I'm glad I didn't because each of the examples from that SO page has the interesting feature that they walk the tree from its root every time when figuring out how to create the path. This is done either using the Nodes.Find method or, for each path, iterating from the root node until a missing node is found. As one reader commented: "I took your code, and it works very well, but I made just a little modification for improving the load speed when it is used with a large list of files it seems like find operation, and string operations generally are very slow."
Frankly, the idea of traversing from the root for each path that needs to be added simply didn't occur to me. Instead, it was clear to me from the beginning that this was a recursive algorithm. Granted, the "search from root" algorithms are all iterative -- no recursion required -- but they have the significant penalty of always having to walk the tree from the root and text for the existence of a child in the node collection at each level. Yuck!
So, this article is hopefully a fun case study of how I iterated my implementation from a prototype to an over-the-top "production" piece.
What is a Prototype?
I think we can all pretty much agree that a prototype is like the first draft of a book -- it's the first cut at the code and typically has one or more of the following features:
- It's probably not very efficient.
- It's probably not very language idiomatic -- as in, it doesn't necessarily take advantage of language features.
- It probably doesn't handle edge cases very well.
- It probably doesn't have any contract asserts or
try-catch blocks. - It might have debug/logging statements.
- It may fit into the category of "evolutionary prototype", meaning that the code has the potential of evolving into production code.
- It may fit into the category of "disposable prototype", meaning that once you've written it, you realize you could write the behavior so much better in a completely different way.
Ironically, the code presented here is "evolutionary", but the end result looks nothing like the first cut, so the initial prototype was disposed!
What is Production Code?
Production code implies a certain quality of code, and this is where there will be lots of disagreement. A few guidelines can be stated as "maybe it does this":
- Edge cases handled
- Some documentation
- Some unit tests
- Some contracts implemented
- Some exception handling implemented
Realistically, prototype code often ends up in a product without qualifying as "production" code.
Production Code Is Not the Same as Maintainable Code
The concept of "production code" is often entangled with "maintainable code", and the two need to be separated. As the list above shows, my concept of "production code" includes things that should fall under "maintainable code":
- documentation
- unit testing
- contracts
- exception handling
Wait a minute! The only thing that is left in the original list is "edge cases handled!" Yup. And even that is debatable.
When is Code Production Ready?
This, in my opinion, is the more important question, as it prevents dealing with the ambiguity and disagreements of what "quality" means. Simply stated:
- code is production ready when it does the intended job
The "intended job" of course has to be defined, but usually this means it passes some QA process. Not unit tests, not style consistency, not language idiomatic correctness, not documentation. The QA process is not the same as unit testing (that's a whole other subject!) and as long as the code passes QA (does what it's supposed to do, including one or more of: correct results, performance, and exception handling) then guess what, it's ready for production!
Here, your QA "functional" process should be a clear and separate process from internal code reviews which look at things QA doesn't. Anything else about the code falls under the category of maintainability and the programmer's desire to be language idiomatic ("cute", in other words.) So given that, let's begin.
Version 1
The algorithm looks like this:
Given a list of strings, where each string represents a path delimited by a forward slash ('/'):
- Convert the list of
strings into a list of path component strings - Get the distinct path components of the first component in each of the paths.
- Iterate each of the distinct components of the path.
- Create the child node.
- Get the collection of paths that match this distinct component as the first component in the path.
- Populate the paths whose first component matches the distinct component and that have additional components.
- Get the remaining components of those paths.
- Recurse the remainder for the distinct subnode we just added.
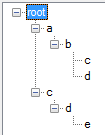
So in other words, if I have these paths:
a/b/c
a/b/d
c/d/e
I should get back a tree like this:
My first attempt looked like this:
static void ParsePaths1(Node node, List<string> paths)
{
List<string[]> splitPaths = new List<string[]>();
foreach (string str in paths)
{
splitPaths.Add(str.Split('/'));
}
var distinctItems = splitPaths.Select(p => p.First()).Distinct();
foreach (string p in distinctItems)
{
Node subNode = new Node() { Text = p };
node.Nodes.Add(subNode);
List<string> matchingFullPaths = new List<string>();
foreach (var match in splitPaths.Where(p2 => p2.First() == p && p2.Length > 1))
{
matchingFullPaths.Add(String.Join("/", match.Skip(1)));
}
ParsePaths1(subNode, matchingFullPaths);
}
}
The idea was not to start with too much LINQ, which can complicate debugging of the basic algorithm.
There's a few problems, one of which is glaring, with this code though:
- It's rather verbose, which can actually reduce readability.
- There's an instantiation and populating of a collection that is totally unnecessary.
- There is a hideous rejoining of
string components back into a single string!
Problem #3, where the component paths are re-joined is where this code really falls into the category of prototype -- it was a shortcut that I took so I could test the algorithm, as that was my focus.
Version 2
In the second version, I decided that, instead of fixing the most glaring problems, I actually wanted to tighten up the code with a better use of LINQ. It was more a "what do I want to work on first" decision rather than anything else. So version 2 looked like this:
static void ParsePaths2(Node node, List<string> paths)
{
var splitPaths = paths.Select(p => p.Split('/'));
foreach(var p2 in splitPaths.Select(p=>p.First()).Distinct())
{
Node subNode = new Node() { Text = p2 };
node.Nodes.Add(subNode);
ParsePaths2(subNode, splitPaths.Where(p3 => p3.First() == p2 && p3.Length > 1).
Select(p3 => String.Join("/", p3.Skip(1))).ToList());
}
}
There's less physical code, but there's now a new problem:
- Because the parser takes a
List<string>, I have to cast the result of the Select to a List. - When using LINQ, especially complex expressions, using variables like
p, p2, and p3 isn't really helpful when one is trying to understand the overall gestalt of the LINQ expression. - We still have that nasty re-joining of the path's components.
None-the-less, version 2 works just fine.
Version 3
Version 3 fixes all the remaining problems:
static void ParsePaths3(Node node, IEnumerable<IEnumerable<string>> splitPaths)
{
foreach (var distinctComponent in splitPaths.Select(path => path.First()).Distinct())
{
Node subNode = new Node() { Text = distinctComponent };
node.Nodes.Add(subNode);
ParsePaths3(subNode, splitPaths.Where
(pathComponents => pathComponents.First() == distinctComponent &&
pathComponents.Count() > 1).Select(pathComponents => pathComponents.Skip(1)));
}
}
Notice how I've changed the signature of the parser to IEnumerable<IEnumerable<string>> This eliminates the nasty ToList() call, and by working with a "list of lists", the re-joining of the string has been eliminated as well. A helper method lets use both styles:
static void ParsePaths3(Node node, List<string> paths)
{
ParsePaths3(node, paths.Select(p => p.Split('/')));
}
Version 4 - Inversion of Control
One thing that bothered me about version 3 is that it does one thing -- populates a tree of Node instances. That's great, but then something else has to take that model and do other things with it, like dump it to the console or populate an actual TreeView.
This is where that "going the last mile" argument with regards to code quality / maintainability most often arises. The implementation in Version 3 is probably just great for the requirements, and everyone that uses it totally gets that it creates a "model" and we now can do things with that model for whatever our "view" wants. That is after all the concept behind the somewhat defunct Model-View-Controller (MVC) pattern and the more alive and kicking Model-View-ViewModel (MVVM) pattern.
And for cases where there really is a physical model (like some database data) that is being represented, that is a fine approach, but quite frankly, this parser is not really creating a "model" in the same sense that MVC or MVVM thinks of a model. The parser is really just that -- in fact, it shouldn't even know or care about what it's constructing!
Enter Inversion of Control. In version 4, we pass in a Func that performs the desired operation, defined externally, and returns something (the parser doesn't care what) that is passed in during recursion.
public static void ParsePaths4<T>(
T node,
IEnumerable<IEnumerable<string>> splitPaths,
Func<T, string, int, T> action,
int depth = 0)
{
++depth;
foreach (var p2 in splitPaths.Select(p => p.First()).Distinct())
{
T ret = action(node, p2, depth);
ParsePaths4(ret, splitPaths.Where(p3 => p3.First() == p2 &&
p3.Count() > 1).Select(p4 => p4.Skip(1)), action, depth);
}
}
For demo reasons, I also snuck in a "depth" counter in this code. Notice how the method has become a generic method, where T has replaced representing the type of current node, and the action that we're passing in is expected to return something of type T as well, which typically would represent the child node.
In the three previous versions, I was calling the parser like this:
List<string> paths = new List<string>() { "a/b/c", "a/b/d", "c/d/e" };
Node root = new Node();
ParsePaths3(root, paths);
Now we have to pass in the function that implements the specific behavior that we want the parser to implement. This reproduces what versions 1-3 were doing:
ParsePaths4(root, paths, (node, text, depth) =>
{
Node subNode = new Node() { Text = text };
node.Nodes.Add(subNode);
return subNode;
});
But because we now have a general purpose parser that is decoupled from the implementation of the what we do with the path components, we can write an implementation that outputs the results to the Console window:
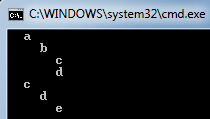
ParsePaths4<object>(null, paths, (node, text, depth) =>
{
Console.WriteLine(new String(' ', depth * 2) + text);
return null;
});
Notice something interesting here--since we're not really doing anything other than printing the string, we're passing in null for the "root node" and returning null, as we don't care. As a result, the type of T has to be explicitly specified, which in this case is object, as the type cannot be inferred from null.
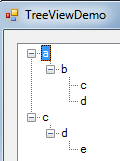
And here is an implementation that populates a TreeView control:
Program.ParsePaths4(tvDemo.Nodes, paths, (nodes, text, depth) =>
{
TreeNode childNode = new TreeNode(text);
nodes.Add(childNode);
return childNode.Nodes;
});
Now this gets a bit more complicated for the average programmer that may not be familiar or comfortable Action, Func, anonymous methods, etc. (though they should be somewhat comfortable if they're already using all that LINQ.) But I bring this up because there comes a point in the coding process where you can write code with elegance and maintainability in mind, but it requires a skilled developer to actually maintain the implementation, whereas a simpler implementation can be more easily handled by a more junior programmer, who will probably just copy & paste the code to change the behavior. And there, we have the tension between elegance, maintainability, re-usability, and skill.
Conclusion
Whilt this has a been a somewhat lightweight article, but I think it covers some issues that we should all be conscious of when reworking prototype code (and deciding whether to rework prototype code!) Hopefully, this case study has provided some food for thought, or at least was a fun read.
One thing I didn't think of, which someone in one of the SO implementations provided, is a default delimiter parameter that can be changed by the caller. Code improvement is a never ending process!
History
- 5th April, 2017: Initial version


 General
General  News
News  Suggestion
Suggestion  Question
Question  Bug
Bug  Answer
Answer  Joke
Joke  Praise
Praise  Rant
Rant  Admin
Admin 












