Click here for a free trial software download
Pubudu Silva, Senior Software Engineer, Machine Learning and Computer Vision, Intel Corporation
Artificial intelligence (AI)―the concept of intelligent machines that are able to perform tasks such as visual understanding, speech perception, language processing, and decision-making that otherwise require human intelligence―continues to be the next big thing, at least since the introduction of computers.
Machine learning is proving to be very effective in performing some of the key AI tasks. Artificial neural networks (ANNs), a loose model of the mammalian cerebral cortex neuronal structure, were especially promising for AI due to their ambitious design and general applicability to a wide variety of tasks. The strength of ANNs lies in their ability to learn and maintain hidden transient states (hidden nodes). This makes it possible for them to learn a wide range of mappings, from the input to the desired output, by cascading several nonlinear functions.
In a learned ANN, hidden layers represent the internal abstraction of the data in hierarchical stages, with deeper layers representing higher levels of abstraction. It is believed that mammalian brains also process information with multiple hierarchical processing layers (e.g., in primate visual systems, processing is done in a sequence of stages from edge detection, primitive shape detection, and moving up to gradually more complex visual shapes).1 Therefore, multilayer, "deeper" ANNs are naturally desired for AI research.
Networks that process data in a sequence of multiple stages with deep cascaded layers are typically called "deep networks." Most of the widely used machine learning algorithms―such as support vector machines (SVMs), mixture of Gaussian (MoG), k-nearest neighbors (kNN), principal component analysis (PCA), and kernel density estimation (KDE)―don’t contain more than three layers of processing. Hence, they can be considered "shallow" architectures. ANNs with two to three layers can be successfully trained. There were several unsuccessful attempts in training deeper ANNs during the last decades of the twentieth century. They faced two main issues:
- Vanishing gradient issues
- Over-fitting arising from the increased number of weights introduced by the additional layers
With the advances in computing, researchers were able to train machine learning algorithms with millions of data samples in a relatively shorter time, effectively resolving the over-fitting issues. Convolutional neural networks (CNNs) are deep networks with multiple layer types, but they contain many fewer weights (than a fully connected ANN of equivalent depth) due to their weight-sharing philosophy. Hence, CNNs are much easier to train than ANNs. With CNNs, theoretical best performance is only slightly worse than that of the ANNs. They have become very popular for supervised image learning tasks. Thanks to the breakthrough discovery of Hinton et al. in 2006,2 successful deep networks―such as deep belief networks and deep auto-encoders―also made their way to unsupervised learning.
In general, deep networks have outperformed almost all other machine learning algorithms in most AI-related tasks such as classification, regression, image captioning, and natural language processing. The stunning success of deep networks can be attributed to the way they autonomously learn feature hierarchies.
The key contrast between deep learning and traditional statistical learning methods is that the latter learns on human-engineered features of the data while the former learns on raw data itself. Deep networks autonomously generate the features best suited to a given task in their early levels as DNNs learn. This effectively removes the guesswork and human bias from the learning process, leaving the whole learning task to a cost function–based optimization process on the given original data.
Deep, layered structure allows learning hierarchies of features, where deeper levels learn higher-level features based on the lower-level features learned by prior levels of the network.
Figure 1 shows how an input image is transformed into gradually higher levels of representation in a deep network. The deeper the image goes into the network, the more and more abstract the representation becomes. For example, learned feature hierarchy, from initial layers to deeper ones, could be edges, shapes, parts of objects, total objects, the scene, etc. However, in practice, it is hard to speculate what the "right" feature vectors should be for each of these hierarchical layers of abstraction without going through the learning. This underscores the key issue in learning on human engineered features: generally, in deeper networks, the output layer gets to process very high-level features, enabling it to learn much higher-level concepts than is possible with shallower networks.
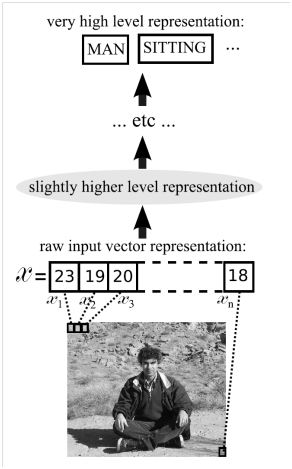
Figure 1. Deep network processing of an image input by transforming it to gradually higher levels of representation
Source: Yoshua Bengio, Learning Deep Architectures for AI, 2009
As the various deep learning techniques have become standard tools for developers, data scientists, and researchers, a number of deep learning frameworks (such as Caffe, Tensorflow*, Theano*, and Torch), and libraries (MatConvNet, CNTK, Pylearn2, and Deeplearning4j) have been developed to help easily train and score deep networks. These frameworks and libraries are immensely helpful in reducing tedious boilerplate work. The user can focus effort on the deep learning aspects rather than implementing the individual components.
Additionally, users have access to the codebase of most of the frameworks and libraries, since they are often launched as open source projects, with active contributions from the developer community. Since deep learning typically involves training on super-large data sets, for days and even weeks, performance optimization of the commonly used deep learning software is critical to the advancement of the technology in general.
Intel consistently contributes to the open source deep learning frameworks especially by optimizing them for Intel® architecture. Its machine learning site contains up-to-date information on Intel’s involvement in machine learning and deep learning. More information about the performance optimization tools and techniques can be found there. Some of the optimization efforts are published as case studies to guide software developers in their own deep learning applications and any frameworks or libraries they may use in the development cycle.
For example, the process followed in optimizing Caffe is presented in the case study Caffe Optimized for Intel® Architecture: Applying Modern Code Techniques. Intel® VTune™ Amplifier is a powerful profiling tool that provides valuable insights, which can be used as the initial guidance for performance optimization process, such as CPU and cache usage, CPU core utilization, memory usage, threading load balance, and thread locks. Libraries such as Intel® Math Kernel Library (Intel® MKL), Intel® Threading Building Blocks (Intel® TBB), and OpenMP* have proved to be very instrumental in optimizing deep learning software.
In order to accelerate the deep learning development and research, Intel recently announced the Intel® Deep Learning SDK, which is a free set of tools for data scientists and software developers to develop, train, and deploy deep learning solutions. The SDK is designed as a Web-based client connected to an Ubuntu*/CentOS server. The simple installation wizard installs the SDK with the popular deep learning frameworks that are optimized for Intel architecture on the server. The training tool of the SDK greatly simplifies the preparation of training data, model design, and model selection with its simple graphical user interface and advanced visualization techniques. Deployment tools can be used to optimize trained deep learning models to specific target devices via model compression and weight quantization techniques.
References
- Serre, T.; Kreiman, G.; Kouh, M.; Cadieu, C.; Knoblich, U.; and Poggio, T. 2007. "A quantitative theory of immediate visual recognition." Progress in Brain Research, Computational Neuroscience: Theoretical Insights into Brain Function, 165, 33–56.
- Hinton, G. E.; Osindero, S.; and Teh, Y. 2006. A fast learning algorithm for deep belief nets. Neural Computation, 18, 1527–1554.
- Bengio, Y. 2009. "Learning Deep Architectures for AI." Found. Trends Mach. Learn. 2, 1 (January), 1–127.
Your Path to Deeper Insight
Find up-to-date information on Intel-optimized deep learning frameworks, libraries, and exciting deep learning tools such as the Intel Deep Learning SDK at intel.com.
Learn more about Intel® Deep Learning SDK and other AI software tools
You may know us for our processors. But we do so much more. Intel invents at the boundaries of technology to make amazing experiences possible for business and society, and for every person on Earth.
Harnessing the capability of the cloud, the ubiquity of the Internet of Things, the latest advances in memory and programmable solutions, and the promise of always-on 5G connectivity, Intel is disrupting industries and solving global challenges. Leading on policy, diversity, inclusion, education and sustainability, we create value for our stockholders, customers and society.





